PAT : 团体程序设计天梯赛-练习集 L2 答案
2019/03/18 完成01-02
2019/03/19 完成03
2019/03/20 完成04
2019/03/21 完成05(unordered_set)
2019/03/22 完成05(手写哈希),06
2019/03/23 完成07
2020/07/30 完成08,09
2020/07/31 补充08标准解法:Manacher算法
L2-001 紧急救援(C++11)
#include
#include
#include
using namespace std;
using intpair = pair;
const int INF{0x3f3f3f3f};
int main(int argc, char *argv[])
{
cin.sync_with_stdio(false);
int N, M, S, D;
cin >> N >> M >> S >> D;
vector vec(N);
for (int i = 0; i != N; ++i)
cin >> vec[i];
vector> road(N);
for (int i = 0; i != M; ++i)
{
int mbeg, mend, mvel;
cin >> mbeg >> mend >> mvel;
road[mbeg].push_back({mend, mvel});
road[mend].push_back({mbeg, mvel});
}
vector dijkstra(N, INF), mov(N), cross(N), mins(N);
vector known(N, false);
dijkstra[S] = 0;
mov[S] = vec[S];
cross[S] = -1;
mins[S] = 1;
while (1)
{
int minval{INF}, minindex{-1};
for (int i = 0; i != N; ++i)
{
if (known[i] == false && dijkstra[i] != INF && dijkstra[i] < minval)
{
minindex = i;
minval = dijkstra[i];
}
}
if (minindex == -1)
break;
known[minindex] = true;
for (const auto &i : road[minindex])
{
if (dijkstra[minindex] + i.second < dijkstra[i.first])
{
dijkstra[i.first] = dijkstra[minindex] + i.second;
mov[i.first] = mov[minindex] + vec[i.first];
cross[i.first] = minindex;
mins[i.first] = mins[minindex];
}
else if (dijkstra[minindex] + i.second == dijkstra[i.first])
{
if (mov[minindex] + vec[i.first] > mov[i.first])
{
mov[i.first] = mov[minindex] + vec[i.first];
cross[i.first] = minindex;
}
mins[i.first] += mins[minindex];
}
}
}
cout << mins[D] << ' ' << mov[D] << endl;
stack ST;
int tD{D};
ST.push(D);
while (cross[tD] != -1)
{
ST.push(cross[tD]);
tD = cross[tD];
}
bool fis = true;
while (!ST.empty())
{
if (fis)
fis = false;
else
cout << ' ';
cout << ST.top();
ST.pop();
}
cout << endl;
return EXIT_SUCCESS;
} Dijkstra算法
L2-002 链表去重(C++11)
#include
#include
using namespace std;
using intpair = pair;
int main(int argc, char *argv[])
{
int beginnode, cnt;
scanf("%d%d", &beginnode, &cnt);
vector LinkNode(100000);
vector book(100001);
while (cnt--)
{
int beg, val, next;
scanf("%d%d%d", &beg, &val, &next);
LinkNode[beg] = {val, next};
}
int disp{-1}, dispold{beginnode}, temp{-1}, temp2{-1};
while (beginnode != -1)
{
if (book[abs(LinkNode[beginnode].first)])
{
if (disp == -1)
disp = temp = beginnode;
else
{
LinkNode[temp].second = beginnode;
temp = beginnode;
}
}
else
{
if (temp2 != -1)
LinkNode[temp2].second = beginnode;
temp2 = beginnode;
book[abs(LinkNode[beginnode].first)] = true;
}
beginnode = LinkNode[beginnode].second;
}
LinkNode[temp2].second = LinkNode[temp].second = -1;
beginnode = dispold;
if (beginnode != -1)
{
printf("%05d %d", beginnode, LinkNode[beginnode].first);
beginnode = LinkNode[beginnode].second;
while (beginnode != -1)
{
printf(" %05d\n%05d %d", beginnode, beginnode, LinkNode[beginnode].first);
beginnode = LinkNode[beginnode].second;
}
printf(" -1\n");
}
beginnode = disp;
if (beginnode != -1)
{
printf("%05d %d", beginnode, LinkNode[beginnode].first);
beginnode = LinkNode[beginnode].second;
while (beginnode != -1)
{
printf(" %05d\n%05d %d", beginnode, beginnode, LinkNode[beginnode].first);
beginnode = LinkNode[beginnode].second;
}
printf(" -1\n");
}
return EXIT_SUCCESS;
} 考察数组模拟链表;上面的实现的稍有麻烦,完全修正了链表地址,分开了两个链表;然而根据题目输出要求,这是没有必要的!可以直接开两个vector存储下两个链表的地址,如下。
#include
#include
using namespace std;
using intpair = pair;
intpair LinkNode[100000];
int book[100001]{0};
int main(int argc, char *argv[])
{
int beginnode, cnt;
scanf("%d%d", &beginnode, &cnt);
while (cnt--)
{
int beg, val, next;
scanf("%d%d%d", &beg, &val, &next);
LinkNode[beg] = {val, next};
}
vector a, b;
while (beginnode != -1)
{
if (book[abs(LinkNode[beginnode].first)])
b.push_back(beginnode);
else
{
a.push_back(beginnode);
book[abs(LinkNode[beginnode].first)] = true;
}
beginnode = LinkNode[beginnode].second;
}
if (!a.empty())
{
printf("%05d %d", a[0], LinkNode[a[0]].first);
for (decltype(a.size()) i = 1; i != a.size(); ++i)
printf(" %05d\n%05d %d", a[i], a[i], LinkNode[a[i]].first);
printf(" -1\n");
}
if (!b.empty())
{
printf("%05d %d", b[0], LinkNode[b[0]].first);
for (decltype(b.size()) i = 1; i != b.size(); ++i)
printf(" %05d\n%05d %d", b[i], b[i], LinkNode[b[i]].first);
printf(" -1\n");
}
return EXIT_SUCCESS;
} L2-003 月饼
#include
#include
#include
using namespace std;
using mypair = pair;
bool mypaircompare(const mypair &a, const mypair &b)
{
return a.second > b.second;
}
int main(int argc, char *argv[])
{
int cnt, need;
scanf("%d%d", &cnt, &need);
vector vec(cnt);
for (int i = 0; i < cnt; ++i)
scanf("%lf", &vec[i].first);
for (int i = 0; i < cnt; ++i)
{
double temp;
scanf("%lf", &temp);
vec[i].second = temp / vec[i].first;
}
sort(vec.begin(), vec.end(), mypaircompare);
double cost{0.0};
for (int i = 0; i < cnt; ++i)
{
if (need >= vec[i].first)
{
need -= vec[i].first;
cost += vec[i].first * vec[i].second;
if (!need)
break;
}
else
{
cost += need * vec[i].second;
break;
}
}
printf("%.2lf\n", cost);
return EXIT_SUCCESS;
} 简单的贪心;老题目了,需要注意库存量和总售价都是浮点数,样例输入是整数具有迷惑性…哈哈
L2-004 这是二叉搜索树吗?
#include
#include
#include
using namespace std;
int array[1001]{0};
vector T;
bool mir;
bool buildtree(int beg, int ed)
{
if (beg > ed)
return true;
int root{array[beg]}, mid;
int temp{beg + 1};
if (mir)
{
while (temp <= ed && array[temp] >= root)
++temp;
mid = temp - 1;
while (temp <= ed && array[temp] < root)
++temp;
}
else
{
while (temp <= ed && array[temp] < root)
++temp;
mid = temp - 1;
while (temp <= ed && array[temp] >= root)
++temp;
}
if (temp != ed + 1)
return false;
bool re = buildtree(beg + 1, mid) && buildtree(mid + 1, ed);
T.push_back(root);
return re;
}
int main(int argc, char *argv[])
{
int cnt;
scanf("%d", &cnt);
for (int i = 1; i <= cnt; ++i)
scanf("%d", &array[i]);
mir = false;
bool isp{true};
if (!buildtree(1, cnt))
{
mir = true;
T.clear();
isp = buildtree(1, cnt);
}
if (isp)
{
printf("YES\n");
for (auto i = T.begin(); i != T.end(); ++i)
{
if (i != T.begin())
putchar(' ');
printf("%d", *i);
}
putchar('\n');
}
else
printf("NO\n");
return EXIT_SUCCESS;
} 根据二叉搜索树的前序遍历,输出后序遍历。因为只需要输出后序遍历,所以我们并不需要真正的建树,按照左子树、右子树、根节点的次序把后序遍历存储下来就可以啦。
基础题上加了个花样,即可能是“镜像二叉搜索树”;先假定不是镜像的,遍历一次;如果遍历失败,就假定是镜像的,再尝试一次,两次都失败输出“NO”,成功就输出存储后序遍历的vector。
L2-005 集合相似度
#include
#include
#include
#include
#include
using namespace std;
int main(int argc, char *argv[])
{
int cnt;
scanf("%d", &cnt);
vector> SET(cnt);
for (int i = 0; i != cnt; ++i)
{
int ind;
scanf("%d", &ind);
while (ind--)
{
int temp;
scanf("%d", &temp);
SET[i].insert(temp);
}
}
scanf("%d", &cnt);
while (cnt--)
{
int a, b;
scanf("%d%d", &a, &b);
--a, --b;
int sum{0};
for (const auto &i : SET[a])
if (SET[b].find(i) != SET[b].end())
++sum;
printf("%.2lf%%\n", (sum * 1.0) / (SET[a].size() + SET[b].size() - sum) * 100.0);
}
return EXIT_SUCCESS;
} 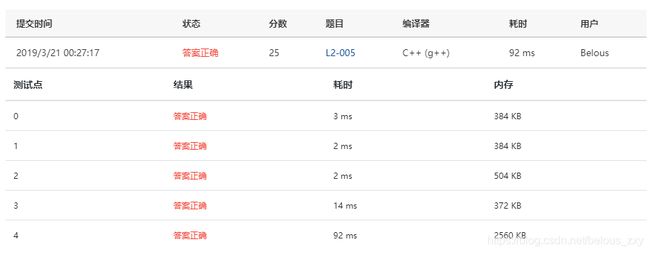
这是专门为STL库准备的题啊?…元素数目较多,且不需要顺序排列,选用哈希构造的 unordered_set ! 最后一个测试点耗时仅需92ms。
emmm,这道题的本意应该是考察哈希表,如果语言标准库里没有的话得自己写;端正学习态度后,头铁一波……
自写哈希表,采用平方探测法/装填因子保证在0.33 。
#include
#include
#include
#include
#include
using namespace std;
struct SThash
{
int *hash;
int hmax, cnt;
};
bool isprime(int num)
{
if (num < 2)
return false;
for (int i = 2; i <= (int)sqrt(num); ++i)
if (num % i == 0)
return false;
return true;
}
int NextPrime(int num)
{
while (!isprime(num))
++num;
return num;
}
SThash *buildhash(int cnt)
{
cnt = NextPrime(cnt * 3);
SThash *T = (SThash *)malloc(sizeof(SThash));
T->hash = (int *)malloc(cnt * sizeof(int));
T->hmax = cnt;
T->cnt = 0;
memset(T->hash, -1, cnt * sizeof(int));
return T;
}
void insert(SThash *T, int value)
{
int temp{value % T->hmax}, base{0};
while (T->hash[temp] != -1)
{
if (T->hash[temp] == value)
return;
temp += ((++base) << 1) - 1;
if (temp >= T->hmax)
temp -= T->hmax;
}
T->hash[temp] = value;
++T->cnt;
return;
}
bool find(SThash *T, int value)
{
int temp{value % T->hmax}, base{0};
while (T->hash[temp] != -1 && T->hash[temp] != value)
{
temp += ((++base) << 1) - 1;
if (temp >= T->hmax)
temp -= T->hmax;
}
if (T->hash[temp] == value)
return true;
return false;
}
int getdigit(void)
{
int temp{0};
char ch;
while (1)
{
ch = getchar();
if (ch == ' ' || ch == '\n' || ch == EOF)
return temp;
temp = temp * 10 + ch - '0';
}
return -1;
}
int main(int argc, char *argv[])
{
int cnt{getdigit()};
SThash *HashTable[50];
for (int i = 0; i != cnt; ++i)
{
int ind{getdigit()};
HashTable[i] = buildhash(ind);
while (ind--)
{
int temp{getdigit()};
insert(HashTable[i], temp);
}
}
cnt = getdigit();
while (cnt--)
{
int a{getdigit()}, b{getdigit()};
--a, --b;
int sum{0};
for (int i = 0; i != HashTable[a]->hmax; ++i)
if (HashTable[a]->hash[i] != -1 && find(HashTable[b], HashTable[a]->hash[i]))
++sum;
printf("%.2lf%%\n", (sum * 1.0) / (HashTable[a]->cnt + HashTable[b]->cnt - sum) * 100.0);
}
return EXIT_SUCCESS;
} 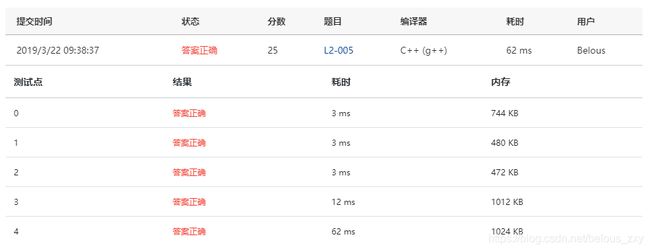
性能和 unordered_set 差不多。
L2-006 树的遍历
#include
#include
#include
using namespace std;
struct node
{
int left, right;
};
node tree[35];
vector a, b;
int buildtree(int left1, int right1, int left2, int right2)
{
if (left1 > right1)
return -1;
int root{a[right1]}, i;
for (i = left2; i <= right2; ++i)
if (root == b[i])
break;
int lenl{i - left2 - 1}, lenr{right2 - i - 1};
--right1;
tree[root].left = buildtree(left1, left1 + lenl, left2, i - 1);
tree[root].right = buildtree(right1 - lenr, right1, i + 1, right2);
return root;
}
void BFS(int root)
{
queue Q;
Q.push(root);
printf("%d", root);
while (!Q.empty())
{
root = Q.front();
if (tree[root].left != -1)
{
Q.push(tree[root].left);
printf(" %d", tree[root].left);
}
if (tree[root].right != -1)
{
Q.push(tree[root].right);
printf(" %d", tree[root].right);
}
Q.pop();
}
putchar('\n');
return;
}
int main(int argc, char *argv[])
{
int cnt;
scanf("%d", &cnt);
for (int i = 0; i != cnt; ++i)
{
int temp;
scanf("%d", &temp);
a.push_back(temp);
}
for (int i = 0; i != cnt; ++i)
{
int temp;
scanf("%d", &temp);
b.push_back(temp);
}
BFS(buildtree(0, cnt - 1, 0, cnt - 1));
return EXIT_SUCCESS;
} 建树;写的并不熟练,需要加强这方面的练习。
L2-007 家庭房产
#include
#include
#include
using namespace std;
using intpair = pair;
int unions[10000];
intpair spunions[10000];
struct ans
{
int index, number;
double Ecnt, Esum;
};
bool sortcompare(const ans &a, const ans &b)
{
if (a.Esum == b.Esum)
return a.index < b.index;
return a.Esum > b.Esum;
}
int DSUfind(const int &num)
{
if (unions[num] <= -1)
return num;
return unions[num] = DSUfind(unions[num]);
}
void DSUunion(const int &a, const int &b)
{
int spa{DSUfind(a)}, spb{DSUfind(b)};
if (spa != spb)
{
if (spa < spb)
{
unions[spa] += unions[spb];
spunions[spa].first += spunions[spb].first;
spunions[spa].second += spunions[spb].second;
unions[spb] = spa;
}
else
{
unions[spb] += unions[spa];
spunions[spb].first += spunions[spa].first;
spunions[spb].second += spunions[spa].second;
unions[spa] = spb;
}
}
}
int main(int argc, char *argv[])
{
fill(begin(unions), end(unions), -1);
int cnt;
scanf("%d", &cnt);
while (cnt--)
{
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
if (b != -1)
DSUunion(a, b);
if (c != -1)
DSUunion(a, c);
int cntt;
scanf("%d", &cntt);
while (cntt--)
{
int child;
scanf("%d", &child);
DSUunion(a, child);
}
scanf("%d%d", &b, &c);
int temp{DSUfind(a)};
spunions[temp].first += b;
spunions[temp].second += c;
}
vector ANS;
for (int i = 0; i < 10000; ++i)
{
if (unions[i] < -1 || (unions[i] == -1 && spunions[i].first))
{
ans temp;
temp.index = i;
temp.number = -unions[i];
temp.Ecnt = spunions[i].first / (double)temp.number;
temp.Esum = spunions[i].second / (double)temp.number;
ANS.push_back(temp);
}
}
sort(ANS.begin(), ANS.end(), sortcompare);
printf("%llu\n", ANS.size());
for (const auto &i : ANS)
printf("%04d %d %.3lf %.3lf\n", i.index, i.number, i.Ecnt, i.Esum);
return EXIT_SUCCESS;
} 考察并查集。合并操作的同时注意合并房产套数和总面积,之后再计算平均值,按要求排序后输出。
L2-008 最长对称子串
#include
#include
#define STR_MAXN 1001
int main(void)
{
char strIn[STR_MAXN] = {0};
unsigned strKey[STR_MAXN] = {0};
int i = 0;
while (strIn[i] = getchar(), strIn[i] != EOF && strIn[i] != '\n')
{
if (i)
{
if (strKey[i - 1] && i - strKey[i - 1] && strIn[i - strKey[i - 1] - 1] == strIn[i])
strKey[i] = strKey[i - 1] + 2;
else
{
int j = 0;
if (strKey[i - 1])
j = i - strKey[i - 1] + 1;
bool loop = true;
while (true)
{
if (strIn[j] == strIn[i])
{
int k = i - 1, h = j + 1;
while (h < k)
{
if (strIn[h] != strIn[k])
break;
++h, --k;
}
if (h >= k)
loop = false;
}
if (!loop)
break;
++j;
}
if (i != j)
strKey[i] = i - j + 1;
}
}
++i;
}
int maxKey = 1;
for (int k = 0; k != i; ++k)
if (strKey[k] > maxKey)
maxKey = strKey[k];
printf("%d\n", maxKey);
return 0;
} 求最长对称子串,两个直接了当的方法,一个是遍历对称轴(容易编写,在输入字符串存在许多对称子串时速度缓慢,O(n^2)复杂度),另一个是上面给出的不断计算包含当前字符的字符子串的最大长度,在找到目标最大子串对称轴前,寻找速度缓慢,找到目标对称轴后,速度很快,O(n^2)复杂度)。
但是这两个办法都不是最优解,它们互有优劣,但都是O(n^2)复杂度。标准解答是Manacher算法(马拉车算法),复杂度可达到O(n),远甚于上述两种办法。
下面给出用Manacher算法解题的程序。
#include
#define MAX(a, b) ((a) > (b) ? (a) : (b))
#define MIN(a, b) ((a) < (b) ? (a) : (b))
#define STR_MAXN (1000 + 1)
char str[STR_MAXN], strx[STR_MAXN << 1];
unsigned dp[STR_MAXN << 1];
unsigned manacherInit(void)
{
unsigned i = 0;
strx[i++] = 1;
for (unsigned j = 0; str[j]; ++j)
{
strx[i++] = 2;
strx[i++] = str[j];
}
strx[i++] = 2;
strx[i] = 0;
return i;
}
unsigned manacher(unsigned len)
{
unsigned maxn = 0, right = 0, ds = 0;
for (unsigned i = 1; i != len; ++i)
{
if (i < right)
dp[i] = MIN(right - i, dp[(ds << 1) - i]);
else
dp[i] = 1;
while (strx[i - dp[i]] == strx[i + dp[i]])
++dp[i];
if (i + dp[i] > right)
right = i + dp[i], ds = i, maxn = MAX(maxn, dp[i] - 1);
}
return maxn;
}
int main(void)
{
scanf("%[^\n]", str);
printf("%d\n", manacher(manacherInit()));
return 0;
} Manacher算法十分巧妙,首先采用在原字符串中穿插相同的间隔字符,以保证修正后的字符串是奇数个字符,这样所有对称子串的对称轴都将是其中一个字符,而不是两个字符中间。
之后依次计算修正字符串中的每个字符为对称轴时,最大的对称子串半轴长度,存放在 dp 数组内。最关键的是如何利用之前的 dp 数组内的数据,减少重复性计算?
如果不减少重复性计算,那么就是遍历每个字符,左右比较是否相等,计算出以这个字符为对称轴的最长子串的半轴长度。所有字符的半轴长度取最大值后 -1 就是原字符串的最大对称子串长度。
如:原串【1】,修正串【#1#】,最大半径长度2,原串最大对称字串长度2-1=1
如:原串【22】,修正串【#2#2#】,最大半径长度3,原串最大对称字串长度3-1=2
【减少重复性计算的操作】:实时记录当前所有已遍历过的字符的最长子串的最右字符位置(right)和这个字符的位置(ds)!
- 最右字符位置,这是啥? 设字符位置为 i ,以此字符为对称轴找到的最长子串半轴长度为 dp[ i ],最右字符位置是 i + dp[ i ],也就是这个最长子串的最右边的字符的位置。
- 每遍历一个字符就检查这个字符的最长子串的右边界是否超出了先前记录的位置,如果超出则:ds = i,right = i + dp[ i ]
如果当前遍历的字符在这个字符的左侧,那么意味着它处于先前已经查找过对称子串的范围中,它的对称字符位置就是 ds * 2 - i,如果这个字符的最长子串是在对称轴 ds 的最长子串内的,那么 dp[ i ] = dp[ ds*2 -i ],但如果并不是被包含在 ds 的最长子串内的话,dp[ i ] = right - i,只能认可在 ds 最长子串内的长度( right - i )。继承先前已经确定的对称半径后,还需要继续向右扩张,以确定它的最长子串长度。
【其他】:可以采用设置前后两个不同的哨兵字符,以便于子串的扩张不越界。
如果以上描述并未完全理解,推荐阅读这篇专门介绍Manacher算法的文章,图文并茂,易于理解。
L2-009 抢红包
#include
#include
#define ARR_MAXN 10000
struct member
{
int ID, money,cnt;
}arr[ARR_MAXN];
int qsortCompare(const void *a,const void *b)
{
const struct member *sa=(const struct member *)a,*sb=(const struct member *)b;
if(sa->money==sb->money)
if(sa->cnt==sb->cnt)
return sa->ID-sb->ID;
else
return sb->cnt-sa->cnt;
return sb->money-sa->money;
}
int main(void)
{
int N;
scanf("%d",&N);
for(int i1=0;i1!=N;++i1)
arr[i1].money=0,arr[i1].ID=i1+1,(arr+i1)->cnt=0;
for(int i1=0;i1!=N;++i1)
{
int M;
scanf("%d",&M);
while(M--)
{
int k,w;
scanf("%d%d",&k,&w);
arr[k-1].money+=w,++(arr+k-1)->cnt,arr[i1].money-=w;
}
}
qsort(arr,N,sizeof(struct member),qsortCompare);
for(int i1=0;i1!=N;++i1)
printf("%d %.2f\n",arr[i1].ID,arr[i1].money/100.0);
return 0;
}
一道简单的模拟题。
L2-010 排座位
L2-011 玩转二叉树
L2-012 关于堆的判断
L2-013 红色警报
L2-014 列车调度
L2-015 互评成绩
L2-016 愿天下有情人都是失散多年的兄妹
L2-017 人以群分
L2-018 多项式A除以B
L2-019 悄悄关注
L2-020 功夫传人
L2-021 点赞狂魔
L2-022 重排链表
L2-023 图着色问题
L2-024 部落
L2-025 分而治之
L2-026 小字辈
L2-027 名人堂与代金券
L2-028 秀恩爱分得快
L2-029 特立独行的幸福
L2-030 冰岛人
L2-031 深入虎穴
L2-032 彩虹瓶
END