导语 | 在金融场景下,银行等机构有强烈愿望和其他数据拥有方合作建模,但出于商业和合规方面的考虑,又不愿共享核心数据,导致行业内大规模数据共享迟迟无法推动。本文将从经典警匪影片情节出发,从技术角度探讨如何解决这一困境,希望与大家一同交流。文章作者:王礼斌,腾讯云大数据研发工程师。
一、引言
银行等金融机构拥有用户历史行为数据,例如是否违约诈骗等,但缺乏数据去对新用户进行判断。而运营商、卡组织(如银联、VISA)等拥有大量数据的机构,有意愿跟金融机构合作建模。
但是,因为金融机构与数据拥有方都有商业保密和政策合规的需要,因此无法把数据给对方来执行传统建模程序。
针对这一现象,腾讯神盾-联邦计算,把两个最常用的算法,梯度提升树(GBDT)和逻辑回归(LR)的计算过程进行重新组织。
将其中部分环节使用同态加密进行改造,从而做到在双方数据都不需要给对方的情况下也能合作建模。解决了金融行业既需要数据合作来改善业务,但同时又必须对数据保密这一矛盾。
二、同态加密与机器学习的结合
1. 互不信任,但需要相互合作
笔者近来观看了一部经典香港警匪片——《线人》,该电影讲述了张家辉扮演的刑事情报科督察李沧东与线人收取情报,最终破获案件的惊险过程。
抛开电影场景下险象环生、步步惊心的剧情,其本质跟引言处提到的困境有异曲同工之处,那就是在互不信任,但又需要互相合作的情况下,如何兼顾双方的权益。
下文将以电影中的情景出发,解析在信息不对称的场景下,联邦算法的信息加密与解密原理。(注:本文所有关于警匪博弈内容,仅限对电影剧情本身的讨论)。
如果你也喜欢看警匪片,可能对以下经典的情节印象深刻:帅气的探长对案件束手无策,要找凶手如大海捞针,于是偷偷联系上了线人。这线人混迹江湖多年,三教九流认识一大票,掌握了不少小混混的信息,以此换取情报费。
例如,辖区发生了劫杀案,线人能提供辖区内小混混们最近买毒品的数量,探长就能优先去调查那些买毒品多,手头紧,更容易起歪念去打劫生财的人。
可探长并不知道线人手上的情报是否真实,所以需要先打探个虚实。同时,线人也担心信息提供出去就收不到钱了,毕竟也不是合法生意,因此双方往往构成僵局。

电影《线人》截图
2. 用技术打破僵局:同态加密
电影中,警探和线人都有自己的立场,在情报收取过程中,也因为立场的对立和信息传达的矛盾导致了一些无法挽回的严重后果。但如果从技术角度来看,信息交换本不必如此麻烦。
假如探长不但查案了得,还精通密码学和统计学,他就可以把问题解决得更加优雅一些:先让线人把小混混们按照过往购毒量分成高低两组,他自己也根据过往的档案把小混混们归类为犯案者和守法者。
如果线人手上信息可靠,那高低两组的犯案者比例应当明显地不同,高购毒量一组犯案占比更大。
回顾一下我们的场景限制,线人并不愿意把信息直接给探长,探长更不能把信息直接给线人(不能把答案供出去了),于是探长使用了同态加密技术。
所谓同态加密是什么呢?我们把原来人能看懂的有意义的信息叫做明文(例如犯案者和守法者标记),密文就是把明文经过加密后得到的,人看上去没有意义的信息。这个同态加密妙就妙在,把密文相加后再解密的结果,和直接对明文相加的结果是一样的。
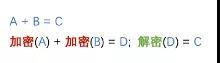
同态加密的基本性质
首先我们来想一下,不用密码的情况下,我们是怎样去计算两组人的犯罪者比例差异的呢?
我们会去数一个组里有总共有多少人,然后数里面有多少个犯罪者。如果是犯罪者,那就是犯罪者总数+1,如果不是犯罪者,那就是犯案者总数+0。
所以,我们把犯罪者标记为1,不是犯罪者标记为0,把这些1和0全部加总在一起,就知道了犯罪者总数,然后除以某组的总人数就知道了犯罪者比例。
我们用同态加密把上面这些1和0掩藏成线人看上去没有意义的信息,既能算出每一个分组犯罪者比例,同时线人也不知道探长手上拿着的具体是什么信息。
总结起来就是,探长先把犯案者记为1,守法者记为0,然后把所有的1和0做同态加密,发给线人。后者则按探长指示把高低两组小混混的密文分别求和,然后把加总好的两组“密文的和”发还给探长。
探长经过解密,得到值就是各组犯案者的数量,除以每组的人数,就可以知道两组当中犯案者的比例。如果有明显差异,就可以放心给钱,得到最有可能犯罪的小混混清单了。
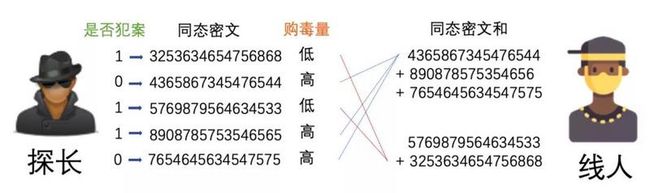
在这个过程中,探长的信息(谁是犯案者,谁是守法者)没有泄漏给线人,线人只得到了密文。线人手上的信息(哪些小混混买毒买得多)也没有泄漏给探长,探长只知道两组小混混的犯案者比例而并不知道每一组有哪些小混混。

通过同态加密进行线索区分度验证
3. 现实生活中:风控和骗徒
上述场景看似有点和现实生活脱节,但真实世界当中这样的故事每天都在发生。
现实中会统计学的“探长们”不在警察局,而是在银行和贷款的公司风控部门当中,一般被称为金融风控分析师。而现实中的线人,则是拥有银行所没有数据的其它组织,例如电信运营商(如移动、联通),卡组织(如银联、VISA)或者政府部门等。
风控部门需要去识别,哪些贷款申请人实际上是骗徒或者老赖,把他们剔除掉,以免银行的钱被骗走。
在这个过程中,由于银行和数据提供方都需要保护自己的客户隐私和商业机密,所以也跟探长与线人一样,需要在不泄漏真实数据的情况下共同完成这个识别工作。
而同态加密正是用到的其中一种方法,腾讯神盾-联邦计算把同态加密和机器学习算法结合起来,就成了当前最常见的联邦学习算法。

银行和数据拥有方,既要合作,又要保密
神盾-联邦计算通过提供一站式联邦学习平台,在金融机构和数据提供方合作当中作为联通数据的桥梁,分析师们无需关注算法底层密码学和机器学习改造的底层细节,鼠标简单点击即可完成联邦机器学习建模流程,同时又能确保双方数据都不泄漏,保障数据安全。
三、联邦梯度提升树和联邦逻辑回归
基于前文所述,通过同态加密来验证数据区分能力的基本原理,神盾-联邦计算对最常用的决策树类算法梯度提升树(XGBoost/GBDT)和线性模型类算法逻辑回归(Logistic Regression)分别进行了改造。下面我们来看看改造是怎么进行的。
1. 联邦决策树算法:多个线索组合起来
让我们再次回到探长与线人的故事中来。线人现在只提供了一个线索,也就是小混混们的购毒量,并且高低两组的犯案者比例确实是有明显差异的。
但是探长还不是很满意,因为高低低组的犯案者比例分别是:30%/5%,也就是说即使拿到购毒量大的小混混清单,里面也有70%不会犯罪。
探长想再精确一点,一抓一个准,让线人再提供一个线索。线人挠挠头说:行,我还知道他们最近打零工的收入。探长大喜,但还是要留个心眼,先验证一下吧。
按照之前使用同态加密的办法,探长让线人根据购毒量和零工收入两个线索组合起来,分成了4个组,然后按照之前用同态加密的方法进行验证分别得到了四组小混混的犯案者比例:10%/5%/80%/30%。
购毒量大且零工收入低的这组混混,有80%可能犯罪,近乎能一抓一准。探长满意了。

多条线索组合计算更精确的犯罪率
这里其实还遗留了几个问题:
第一,购毒量和零工收入有效,这是探长根据经验所得知的。在线人所了解的诸多线索当中,如果没有探长的经验,就只能用机器,通过上述同态加密的方法逐个去试,从而找到两组犯案者比例差异最大的线索,这里称为联邦决策树当中的变量搜索。
第二,这里把小混混划分成高低两组,但到底多少是高,多少是低,划分点在哪其实也需要机器一个个可能性去试,这里称为联邦决策树中的分裂点搜索。
第三,现在只是两个线索的两两组合,共有四个组合。如果有1000条线索选三个来组合呢,那就有1000X1000X1000,即一百万种组合需要计算的,这计算量太多了,需要算很久很久。
有个取巧的方法是,先做变量搜索找到最有区分度的第一层变量,然后固定住第一层(如购毒量)再去搜索第二层变量。如此类推,这样就只需要1000+1000X2+1000X4(第一层1节点,第二层2节点,第三层四节点),即7000种组合需要计算,比100万少多了。
这种办法叫做贪心搜索,就是每一层最佳的变量和分裂点选定后就不变了。
总结来看,通过同态加密的方法进行变量和分裂点的贪心搜索,在找到最能区分犯案者和守法者的条件组合的同时,保护探长和线人的信息都不透露给对方。这就是联邦决策树算法。
在现实中,如果每一个变量和每一个分裂点都完整进行同态加密,发送,求和,返回,解密,计算比例六步这整个流程,就需要在探长和线人中往返很多次,速度难以接受。
由于我们使用贪心算法,所以在探长发送完同态密文给线人后,让线人把所有线索按照所有可能分割点都先统一进行求和后再返回给探长一次性解密,探长再从中选出比例差异最大的变量和分割点。这个所有线索按照所有可能分割点都先统一进行求和,得到的结果叫做同态密文梯度直方图。

联邦决策树算法
上述就是联邦决策树的建模过程,如果我们再往前一步,把多棵树联合起来,就能得到不同的集成模型(Ensemble)用以提升效果。
例如使用相同一份梯度同态密文多次反复对特征和样本取样来建立多棵决策树,然后把多棵决策树的结果取平均,就有了联邦随机森林模型(Random Forest)。
另外一个集成方向是每建立一棵树就用这个树的结果来更新梯度密文,后一棵树以上一棵树的结果为基础来训练,这就有了梯度提升树(GBDT),其中著名的实现就有XGBoost等。
2. 联邦逻辑回归:另一种可能性
神盾-联邦计算改造了的另一个常用算法则是逻辑回归。
上文提到过,同态加密的特性是明文加密之后求和再解密,等价于明文直接求和。把这条性质衍生一下,那明文乘以密文再加密,等价于明文乘以明文。
例如 3*密文,其实就是等于 密文+密文+密文。我们利用这个性质可以帮助探长和线人构建另一种模型:逻辑回归。
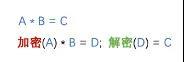
同态加密基本性质的衍生
前文所述的通过条件组合,如购毒量高且零工收入高,这种方式来组合多个线索,就得到了树模型。
那能否换一种线索组合的方式,例如:犯案可能性 = 购毒量线索的权重x购毒量+零工收入的权重x零工收入。我们把这样的组合方式称为线性模型,其中最常用的就是逻辑回归。由于这种模型是把多个线索的得分加起来预测犯案可能性,所以又叫做评分卡。
这里联邦算法唯一需要做的事便是确定每一项线索的权重,这里我们可以用瞎猜的办法。线人随便指定权重,计算得出每个人的犯案可能性,然后发给探长,探长再答复线人猜得有多准。
当然,这样子不知道要到何年何月才能猜出足够好的一组权重了,所以科学家想出了很多让这个猜测过程更快的办法,其中一种就叫做梯度下降法。

逻辑回归
线人先瞎猜一组权重,然后告诉探长结果。探长想了想,如果我直接回复他哪些小混混猜准了,哪些没猜准,他多猜几次不就把我的档案资料摸清楚了,所以不能直接给他。我能不能直接告诉他每一个权重是多了还是少了,应该加多少或者减多少,这样就不会泄漏到底猜对了还是猜错了。
探长这里所想到的每一个权重值应该加多少或者减多少,其实就是所谓的梯度。通过减梯度值来尽快猜出一个最佳的权重值,这种方法就叫做梯度下降法。
其中最简单的梯度就是“线索的值”X“猜测的犯罪可能性与真实是否犯罪的差值”。这公式的推导需要微积分,但理解却不难。
前者是因为线索的值越大,对最终结果的影响越大,所以变化幅度要越大;后者则是变化的方向,猜多了要减一点,猜少了要加一点,差得远加减的幅度也要越大。
但是探长不能直接给出“猜测的犯罪可能性与真实是否犯罪的差值”,因为这样会让线人很快摸清档案真实情况。
探长心生一计,他把这个差值做了同态加密,发给线人,让线人使用所掌握的“线索的值”计算出梯度的密文,也就是 “线索的值”X“猜测的犯罪可能性与真实是否犯罪的差值的密文”,然后发还给探长进行解密。最后探长就可以只把梯度告诉线人,而不需要把猜测正确与否泄漏出去了。

联邦逻辑回归梯度计算流程
把上面这个过程反复进行,直到猜来猜去准确性都没什么提升了,就停止不猜了,被称为“收敛”了。
结语
在本文中,我们从电影中探长与线人的博弈场景延伸展开,探讨如何在双方都不透露具体数据给对方的情况下进行数据合作。
借此介绍了同态加密的技术,而同态加密的特点是对密文求和再解密等价于对明文直接求和。同时介绍了神盾-联邦计算在此基础之上,对经典的梯度提升树算法(GBDT)和逻辑回归算法(LR)进行了改造,从而让双方数据都不泄漏的情况下训练模型。
目前这两个算法已融入腾讯神盾体系,成为其中重要的能力,帮助促进金融行业的信息共享合作。同时,神盾也在安全性、效率和算法的丰富性完整性方面投入研发,取得了成效,例如:
- 同态加密算法:神盾通过自研的RIAC同态加密系统替代传统的Paillier系统,让算法整体计算速度提升70%。
- 逻辑回归算法:神盾通过重新设计算法协议,剔除了可信第三方这个不安全设定,同时彻底免除了近似计算误差,使联邦逻辑回归效果跟传统逻辑回归完全一致。
- 决策树算法:神盾通过矩阵计算优化,将同态密文的梯度直方图计算速度提升70%以上,使整体计算时间减少50%。
- 非对称联邦技术:通过掺入假样本保护金融机构的客户ID列表,同时不影响模型训练效果。
未来,神盾-联邦计算将继续致力于联通数据孤岛,让数据发挥更大价值的同时,助力业务发展。