初识爬虫2(详解)---所有图片+多进程
初识爬虫—爬下所有图片+多进程
初学者学习网站:
requests的详细教程
https://segmentfault.com/a/1190000021725063
BeautifulSoup具体教程
https://wiki.jikexueyuan.com/project/python-crawler-guide/beautiful-soup.html
python多进程教程
https://cuiqingcai.com/3335.html
有些代码是沿用的我上一个博客,所以新进来的小伙伴可以花5分钟浏览一下我的上一篇文章初识爬虫
废话不多说先展示一下成果
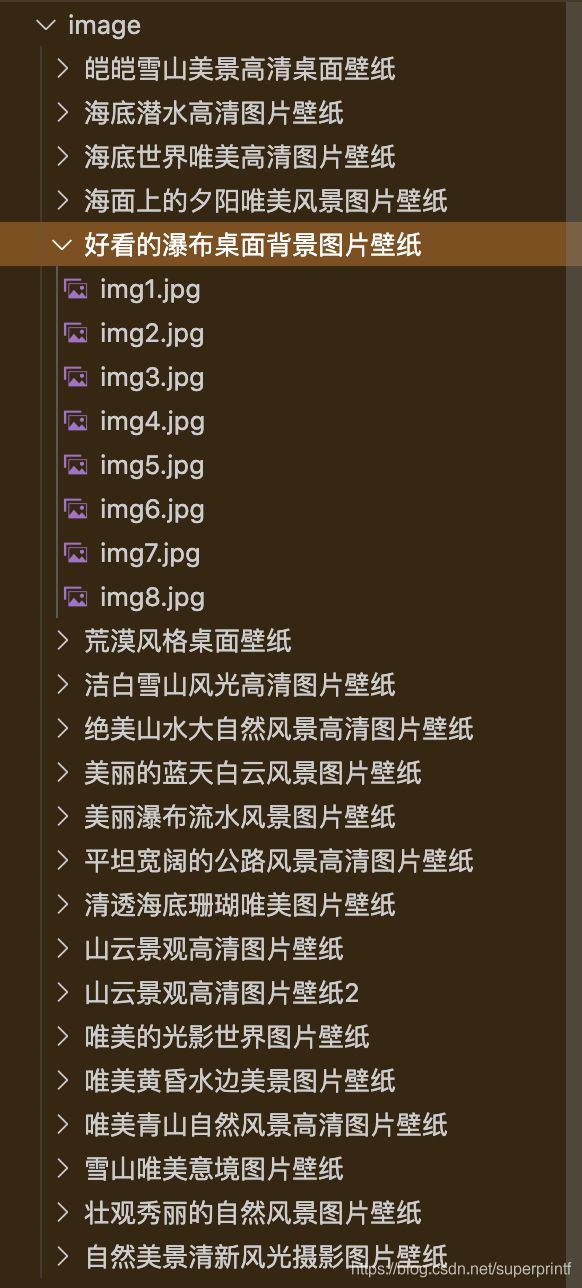
这些是不到10秒钟机器完成的!!
一. 咱们先理清一下思路然后再上代码
首先http://desk.zol.com.cn/fengjing/这个网站第一页有21个主题,每行3种主题一共7行,我们需要找到这21个主题图片
然后进去每一个主题下载其中第一张大图片,然后翻页下载第二张大图片,直到这个主题下载完成
并且我们也需要第二页的21主题,第三页的21主题等等,于是也需要翻页
好,思路有了那就开始行动
先上代码
import requests
from bs4 import BeautifulSoup
import re
import os
from multiprocessing import Process
import time
os.makedirs('./image/', exist_ok=True)
def urllib_download(url, Dir, i): #下载图片到特定目录
r = requests.get(url)
with open(Dir+'img'+str(i)+'.jpg', 'wb') as f:
f.write(r.content)
def spider_every_theme(target): #每一个主题壁纸
Dir=''
picNum=1
while True:
content = requests.get(url=target)
html = BeautifulSoup(content.text)
bigImg = html.find_all(
'img', width=960, height=600) # id='bigImg',这是大图的特定属性
Next = html.find_all('a', id='pageNext') #显示为下一张图片的a标签
if picNum == 1: # 从页面找标题
title = html.find_all('a', id='titleName')[0].string
Dir = './image/'+title+'/'
os.makedirs(Dir, exist_ok=True)
urllib_download(bigImg[0].get('src'), Dir, picNum)
if Next[0].get('href') == 'javascript:;':
break
else:
picNum = picNum+1
target = 'http://desk.zol.com.cn'+Next[0].get('href')
def spider(target): #总爬行
while True: #按ctrl + c停下来
content = requests.get(url=target)
html = BeautifulSoup(content.text)
main = html.find_all('ul', class_='pic-list2 clearfix')
for child in main[0].descendants: # 每张大页面共21个主题图片
if child.name == 'img':
t = 'http://desk.zol.com.cn' + \
child.parent.get('href') # 找到图片对应的a标签(父标签)的href,去每个主题下搜索图片
Process(target=spider_every_theme, args=(t,)).start() #多进程
time.sleep(2)
target = 'http://desk.zol.com.cn' + \
html.find_all('a', id='pageNext')[0].get('href') # 搜集21个主题后翻页,右下角的下一页的地址
if __name__ == "__main__":
target = 'http://desk.zol.com.cn/fengjing/'
spider(target)
二. 代码分析
代码分为两大部分
spider(): 函数用来爬取所有内容
spider_every_theme(): 用来对于每个主题进行爬取,同时也是进程调用函数,一个进程对应一个主题
1.我们先分析spider(): 函数
在这之前需要先学会查找页面元素
右键找到检查元素类似字样,点击会变成这样(我是chrome浏览器,其他浏览器自行百度)
点击序号1然后鼠标放在左侧,被蓝色覆盖的部分就是我们需要关注的图片部分,点击蓝色部分后序号2颜色会加重,记住这个标签的名字叫做ur,class属性叫pic-fix2 clearfix,这两个信息帮助我们过滤页面内容,暂且叫做main,主页面。
main = html.find_all('ul', class_='pic-list2 clearfix')
接下来遍历main[0]的所有子孙节点(descendants是BeautifulSoup的语法文章开头有链接)
for child in main[0].descendants: # 每张大页面共21个主题图片
如果是图片就去找他的父节点(a标签),并且获取其中的href属性
if child.name == 'img':
t = 'http://desk.zol.com.cn' + \
child.parent.get('href') # 找到图片对应的a标签(父标签)的href,去每个主题下搜索图片

然后跳转到主题下去下载图片,一个进程对应一个主题的图片,这里为什么是用多进程而不是多线程可以参考文章https://cuiqingcai.com/3325.html
Process(target=spider_every_theme, args=(t,)).start() #多进程
time.sleep(2)
最下面的这句是主页面翻页
target = 'http://desk.zol.com.cn' + \
html.find_all('a', id='pageNext')[0].get('href') # 搜集21个主题后翻页,右下角的下一页的地址


2.分析spider_every_theme():函数
spider_every_theme()函数是为了下载主题的所有图片的所以先进入主题
首先仔细的对比观察发现所有大图片的img标签的id=“bigImg”,并且width=“960” height=“600”,这是大图片独有的特点,我们先用后者来区分大图和其他无关的图片吧
bigImg = html.find_all(
'img', width=960, height=600) # id='bigImg',这是大图的特定属性
图片找到了就可以下载下来了,每个主题一个名字,按照上面的原理找到id='titleName’的a标签里面有这个主题的名字,然后建立文件夹存储图片,哪个urllib_download上一个文章有讲到,就是下载图片并且保存用的
if picNum == 1: # 从页面找标题
title = html.find_all('a', id='titleName')[0].string
Dir = './image/'+title+'/'
os.makedirs(Dir, exist_ok=True)
urllib_download(bigImg[0].get('src'), Dir, picNum)
好了,下载第一张图片下载下了,我们需要这个主题的第二张

看到哪个箭头了吗,我们要找到他的a标签定位到下一张图片,他的id=‘pageNext’
Next = html.find_all('a', id='pageNext') #显示为下一张图片的a标签
然后重复上述步骤就可以一直下载了,但是有个问题,这个主题下载完了没有pageNext了怎么办,这就需要思考了,没有pageNext的页面有什么特点,然后根据这个特点结束
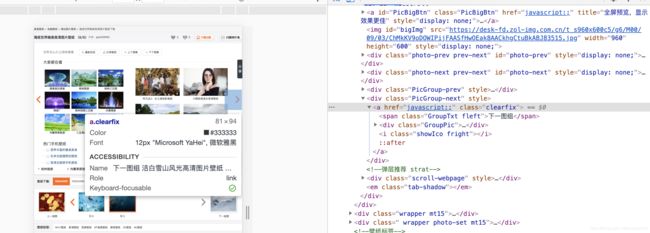
这是最后一张页面,我们发现他的pageNext变成了"javascript:;",好了,就以他为结束
if Next[0].get('href') == 'javascript:;':
break
以上就是全部的代码讲解了,如果有不会的部分先去开头链接学习一遍(你点他并不会跳转到开头,信我)