弱标签(一):Learning from Semi-Supervised Weak-Label Data 从半监督的弱标签数据中学习
弱标签(一):Learning from Semi-Supervised Weak-Label Data 从半监督的弱标签数据中学习
最近需要学习一些 w e a k − l a b e l weak-label weak−label的知识,因此打算看几篇论文并记录一下:
摘要
多标签学习同时处理与多个标签相关联的数据对象。以前的研究通常假设,对于每个实例,都给出了与每个训练实例相关联的完整的相关标签集,然而,在许多应用程序(如图像注释)中,通常很难为每个实例获取完整的标签集,有的时候甚至只能获得部分或甚至空的相关标签集(因为图像标注实在是太麻烦了)。我们把这种问题称为“半监督弱标签学习”问题。在这项工作中,我们提出了SSWL( S e m i − S u p e r v i s e d W e a k − L a b e l Semi-Supervised Weak-Label Semi−SupervisedWeak−Label,即半监督弱标签)方法来解决这个问题。我们同时考虑了实例相似度和标签相似度来补充缺失标签。利用多模型的集成,提高了标签信息不足时的鲁棒性。我们用一个有效的块坐标下降算法将目标表示为一个双凸优化问题。实验验证了SSWL的有效性。
介绍
传统的监督学习通常假设每一个实例都与唯一的一个标签相关联,然而在许多实际任务中,一个实例通常拥有多个标签,例如,在文本分类中,若对文档进行分类,奥运会同时属于商业和体育;在图像注释中,巴黎场景中的图像同时与塔和天空联系在一起。传统的基于单实例单标签的监督学习已经超出了它处理这个问题的能力,而处理与一组标签相关的实例的多标签学习(Zhang和Zhou 2014)已经受到了很多关注。
在以往的多标签研究中,训练数据的基本假设是每个训练实例的所有相关标签都是已知的,然而,在许多应用中,这种假设很难成立,因为很难获得所有相关的标签,而且通常只能观察到部分甚至是空的标签集。例如,假设一个训练图像与概念汽车、道路、人类和建筑物相关,在实际情况中,用户可能只对小车、道路进行标签化训练,而忽略了对人、建筑物的标签化。更糟糕的是由于资源有限,用户可能没有选择训练凸显进行标注,因此观察到的图像相关的标签甚至是一个空集
由于弱标签学习和半监督多标签学习都不能很好地解决这一问题。例如,弱标记学习忽略了许多可能非常有用的未标记实例的使用;半监督多标签学习假设所有相关标签都可用于已标记的实例,但在我们的情况下并非如此。注意,本文的数据场景研究与以往的多标签研究有很大的不同。我们把这种多标记问题称为半监督弱标记学习。我们在图1中演示了本文的学习场景与以前的多标签学习框架之间的区别。
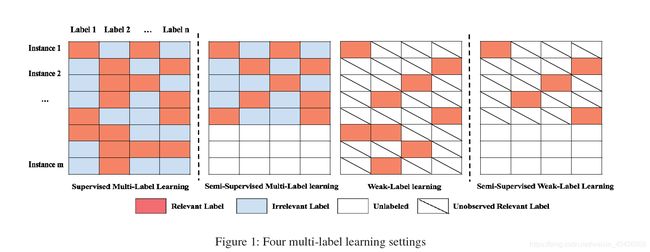 在此图当中我们可以看到,传统的监督多标签学习中每一个示例都有相对应的标签,并且标签值全都给出来了,而半监督多标签学习中有部分示例未给出标签,但是给出标签值的示例对应的所有标签都能给出,而弱标签学习则会给出所有示例对应的标签,但是很明显,标签数量不完全,可能给出一小部分;而半监督弱标签学习则结合了半监督学习和弱标签学习,只给出部分示例的标签,并且示例的标签也不完全,因此在这种情况下难度相对而言就比较大。
在此图当中我们可以看到,传统的监督多标签学习中每一个示例都有相对应的标签,并且标签值全都给出来了,而半监督多标签学习中有部分示例未给出标签,但是给出标签值的示例对应的所有标签都能给出,而弱标签学习则会给出所有示例对应的标签,但是很明显,标签数量不完全,可能给出一小部分;而半监督弱标签学习则结合了半监督学习和弱标签学习,只给出部分示例的标签,并且示例的标签也不完全,因此在这种情况下难度相对而言就比较大。
本文研究了半监督弱标签学习问题,提出了半监督弱标签学习方法
(Semi-Supervised Weak-Label)方法,基本假设是,实例和标签的相似性都有助于弥补缺失的标签,此外,当标签信息不足时,多个模型的集成通常比单个模型表现出更强的鲁棒性,具体来说,我们首先构建一个基于平滑度假设的正则化术语,即相似实例的标签集合中应该有相似的概念组合(就比如,一张图是山水图,那么标签值为山和水,若另一个实例与此图相似,则可以判断标签值为山和水的概率很大),这就要求最终的预测同时与实例的平滑度和标签的相似度相一致。我们分别为标记实例和未标记实例构建模型,通过斜正则化(co-regularization)框架利用不同的模型,我们提出了一个双凸公式,并提供了一个有效的块坐标下降的解决方案。实验验证了该方法的有效性。
相关工作
弱标签学习研究线是在过去几年提出的。Sun等人(2010)提出了基于实例相似性由一组低秩相似矩阵确定的假设的WELL方法。Bucak等人(2011)提出了MLRGL方法,该方法使用群lasso来调节训练错误。近年来,许多学习方法都试图克服弱标签问题。例如,基于标签共现的方法(Wu, Jin, and Jain 2013;Zhu, Yan, and Ma 2010),稀疏重建(Lin et al. 2013),低秩矩阵完成(Xu, Jin, and Zhou 2013)等。弱标签问题也出现在其他学习场景中,如多实例多标签学习(Yang, Jiang, and Zhou 2013)。然而,弱标记学习方法并不能很好地处理半监督的弱标记数据,因为它们忽略了对大量已知非常有用的未标记实例的利用。
半监督多标签学习可分为两类。一种是转换性多标签学习,假设测试实例来自未标记的实例,Liu等人(2006)假设标签空间中的相似性与特征空间中的相似性密切相关,从而利用特征空间中的相似性来指导缺失标签赋值的学习,从而得到约束的非负矩阵因子分解优化;另一种是纯半监督多标签学习,可以对任何不可见的实例进行多标签预测,赵等人(2015)将多标签关联与多标签预测相结合,以互惠的方式提高多标签预测性能,詹等人(2017)提出了一种归纳式协同训练风格方法来解决这一问题。他们通过对特征空间进行二分化和多样性最大化来处理多标签数据,生成了两种分类模型,然后对未标记数据进行两两排序预测,并通过迭代的方式进行交流以进行模型细化。然而,尽管半监督多标签学习考虑了相关标签的不完全性,但它仍然假设有完整的相关标签可用于已标记的实例,而这种假设不适用于半监督弱标签数据。
提出的方法
问题的陈述与符号
在原始的监督多标签设置中,我们得到一个训练数据集 { ( x i , y i ) } i = 1 m \{(x_{i},y_{i})\}_{i=1}^{m} { (xi,yi)}i=1m,一共有 m m m个实例。其中实例 x i x_{i} xi表示一个 d d d维实值向量,标签 y i y_{i} yi表示一个 n n n维二进制的标签向量,为1时则表示该实例属于与维相对应的概念,反之则为- 1。也就是当 y i = 1 y_{i}=1 yi=1时,则此标签 y i y_{i} yi与此实例 x i x_{i} xi相关联。所有标签都由标签空间组成 y 1 = { 1 , − 1 } n y^1=\{1,-1\}^{n} y1={ 1,−1}n,换句话说,我们有一个示例矩阵 X = [ x 1 , x 2 , . . . , x m ] ′ X=[x_{1},x_{2},...,x_{m}]^{'} X=[x1,x2,...,xm]′,对于这个矩阵来说,每一行都对应一个示例,和一个全标签矩阵 Y ϵ { 1 , − 1 } m × n Y\epsilon _{}^{}\{1,-1\}^{m\times n} Yϵ{ 1,−1}m×n,则有 m m m行 n n n列,行数为实例的个数,列数为标签的个数,在这个矩阵中, Y i j = 1 Y_{ij=1} Yij=1表示第 i i i个实例拥有第 j j j个标签, Y i j = − 1 Y_{ij=-1} Yij=−1表示第 i i i个实例没有第 j j j个标签。我们让 S i = { j ∣ Y i j = 1 , j = 1 , . . . , n } S_{i}=\{j|Y_{ij}=1,j=1,...,n\} Si={ j∣Yij=1,j=1,...,n}表示实例 x i , ∀ i = 1 , . . . , m x_{i},\forall i=1,...,m xi,∀i=1,...,m的全部相关标签.
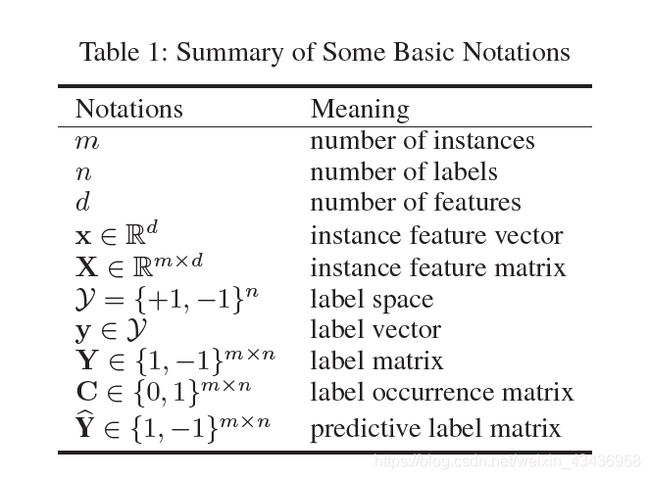
表1中是一些基本符号的总结,如下表格所示:
| 符号 | 解释 |
|---|---|
| m m m | 实例的个数 |
| n n n | 标签的个数 |
| d d d | 特征的个数 |
| x ϵ R d x\epsilon \mathbb{R}^{d} xϵRd | 实例特征向量 |
| X ϵ R m × d X\epsilon \mathbb{R}^{m \times d} XϵRm×d | 实例特征矩阵 |
| y 1 = { 1 , − 1 } n y^1=\{1,-1\}^{n} y1={ 1,−1}n | 标签空间 |
| y ϵ y 1 y \epsilon y^1 yϵy1 | 标签向量 |
| Y ϵ { 1 , − 1 } m × n Y\epsilon _{}^{}\{1,-1\}^{m\times n} Yϵ{ 1,−1}m×n | 标签矩阵 |
| C ϵ { 0 , 1 } m × n C\epsilon _{}^{}\{0,1\}^{m\times n} Cϵ{ 0,1}m×n | 标签出现的矩阵 |
| Y ^ ϵ { 1 , − 1 } m × n \hat{Y}\epsilon _{}^{}\{1,-1\}^{m\times n} Y^ϵ{ 1,−1}m×n | 预测标签矩阵 |
在半监督弱标签学习设置中,我们有相同的实例矩阵 X X X,然而,全标签矩阵 Y Y Y是不可获得的(因为部分标签得不到标注),我们只能得到一个标签出现矩阵 C ϵ { 0 , 1 } m × n C\epsilon _{}^{}\{0,1\}^{m\times n} Cϵ{ 0,1}m×n,在矩阵中 C i j = 1 C_{ij}=1 Cij=1表示第 i i i个实例有第 j j j个标签(与 Y i j = 1 Y_{ij}=1 Yij=1相同),然而 C i j = 0 C_{ij}=0 Cij=0时,标签空间中的 Y i j Y_{ij} Yij有两个可能的值,一种是 Y i j = 1 Y_{ij}=1 Yij=1,也就意味着第 i i i个实例有第 j j j个标签但是没有被观察到,另一种是 Y i j = − 1 Y_{ij}=-1 Yij=−1,意味着第 i i i个实例没有第 j j j个标签,且第 j j j个标签是不知道的。而且,在半监督弱标签学习中,对于每个实例观察到的相关标签的数量没有进一步的限制。具体来说,让 S ^ = { j ∣ C i j = 1 , j = 1 , . . . , n } \hat{S}=\{ j|C_{ij}=1,j=1,...,n\} S^={ j∣Cij=1,j=1,...,n}表示实例 x i , ∀ i = 1 , . . . , m x_{i},\forall i=1,...,m xi,∀i=1,...,m的相关标签的观测集, S ^ \hat{S} S^可能是全相关标签集 S i S_{i} Sid的子集,或者甚至为一个空集。我们的目标是从 X , C {X,C} X,C(也就是{实例矩阵,标签出现的矩阵})学习一个预测标签矩阵 Y ^ ϵ { 1 , − 1 } m × n \hat{Y}\epsilon _{}^{}\{1,-1\}^{m\times n} Y^ϵ{ 1,−1}m×n能够近似为 Y Y Y
问题公式化
处理半监督弱标签设置的直接策略是将任务分解成n个独立的二分类问题,每个问题对应一个标签,对于每个标签,现有的一些二进制半监督学习算法,如标签传播和半监督SVM能够被运用,然而,这种策略忽略了标签的相关性,标签之间的相关性是非常有用的,并经常导致次优问题。为了考虑到标签之间的相关性,本文提出了利用实例相似性和标签相似性来补充缺失的相关标签,具体来说,我们引入了一个基于平滑度假设的正则化术语,即相似实例的标签集合中应该有相似的概念组合,这就要求最终的预测同时与实例的平滑度和标签的相似度相一致。
形式化地,让 G I G_{I} GI表示为一个有标记和无标记实例的加权邻域图,在 G I G_{I} GI上的每一个点都代表一个实例 x i x_{i} xi,并且 x i x_i xi和 x p x_p xp之间的一条边意味着, x i x_i xi是 x p x_p xp的k近邻或者 x p x_p xp是 x i x_i xi的k近邻,我们定义一个稀疏矩阵(大小为 m × m m\times m m×m) S S S,来表示相邻实例之间的相似性:
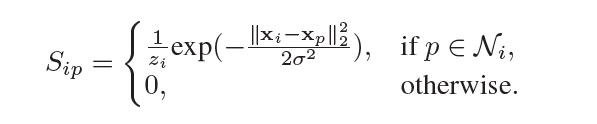
其中 N i N_i Ni表示第 i i i个实例的 k k k近邻的实例集,且
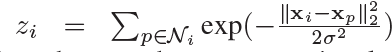
在这里
![]()
上述公式的意思主要如下: S i p S_{ip} Sip的意思是,找到对每一个实例 x i x_i xi(一共有m个实例)来讲它的k近邻实例集 N i N_i Ni,然后先对 N i N_i Ni里面的每一个实例 x p x_p xp都计算一下到 x i x_i xi的距离,同时我们可以获得对实例 x i x_i xi所有的k近邻实例的所有距离 z i z_{i} zi,然后得出每一个相邻实例的近似值,也就是两个示例之间越相似,则 S i p S_{ip} Sip越大。最终 S S S矩阵里面包含的就是每个实例之间的相似度大小。
为了减少标记实例和未标记实例之间k近邻搜索的计算量,我们使用了kd-tree
来有效地搜索每个实例的近似k近邻,并使用多标签降维方法来减少维数的影响
在半监督弱标签学习中,观察到的实例的相关标签集是不完整的。我们不能直接计算标签相似度矩阵 L L L,因此需要学习它。为了讨论的简单性,我们首先假设标签相似矩阵 L L L是给定的。
为了估计预测标签矩阵 Y ^ \hat {Y} Y^,从平滑度假设的角度来看,主要有两种方法。首先,从实例相似度的角度出发,可以由实例的近邻派生出实例的相关标签集,例如:
![]() 此公式的意思是:我们要获得第i个实例的第j个标签的预测值,我们可以获得第i个实例和其每一个k近邻p实例之间的相似度和此p实例对第j个标签的预测值的乘积
此公式的意思是:我们要获得第i个实例的第j个标签的预测值,我们可以获得第i个实例和其每一个k近邻p实例之间的相似度和此p实例对第j个标签的预测值的乘积
其次,从标签相似性的角度出发,可以通过相邻标签的赋值来推导出某一特定标签在训练实例上的赋值
![]() 此公式的意思是:我们要获得第i个实例的第j个标签的预测值,我们可以获得第i个标签和所有与j标签k近邻的标签q的预测值和标签q与标签j之间相似度的乘积.
此公式的意思是:我们要获得第i个实例的第j个标签的预测值,我们可以获得第i个标签和所有与j标签k近邻的标签q的预测值和标签q与标签j之间相似度的乘积.
在里面 N ^ j \hat {N}_j N^j是第 j j j个标签的 k k k个近邻的标签集合,显然,预测标签矩阵不仅与实例相似度有关,还与标签相似度有关。这促使我们同时描述实例相似性和标签相似性的平滑性
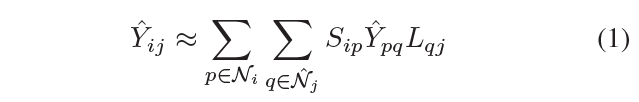
因此最终对第i个示例的第j个标签的预测值,就是对i实例的所有k近邻p实例,和对标签j的所有k近邻q标签来说,计算i实例和p实例之间的相似度,计算p实例与q标签的预测值,计算q标签和j标签之间的相似度.
因此,我们得到一个新的正则化项:
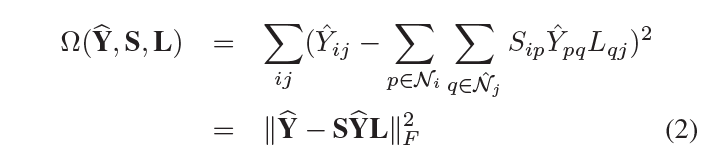
其中 ∣ ∣ M ∣ ∣ F 2 = t r ( M M ′ ) ||M||^2_{F}=tr(MM^{'}) ∣∣M∣∣F2=tr(MM′)且 t r ( ⋅ ) tr(\cdot) tr(⋅)是矩阵的迹,也就是对角线相加,在正则化项中,将预测
利用新的正则化项,我们的目标是在半监督弱标集中得到一个有前途的预测标 Y ^ \hat{Y} Y^,我们采用了集成学习,它比单一模型更健壮,尤其是在标签信息不足的情况下,具体来说,我们首先用新的正则化术语分别构建两个模型,分别用于标记和未标记的实例,然后通过协正则化框架(Sindhwani、Niyogi和Belkin)利用不同的模型得出一个稳健的预测结果.
形式上,让 X W XW XW和 X W ˉ X\bar{W} XWˉ表示两个线性多标签模型,其中 W , W ˉ ϵ R d × n W,\bar{W}\epsilon \mathbb{R}^{d\times n} W,WˉϵRd×n是系数矩阵,初始化第一个模型 X W XW XW,预测能观察到的相关标签,即 C i j = 1 C_{ij}=1 Cij=1的元素,目标表述为 ∣ ∣ ( X W ) ∘ C − C ∣ ∣ F 2 ||(XW)\circ C-C||^2_{F} ∣∣(XW)∘C−C∣∣F2,其中 ∘ \circ ∘是Hadamard乘积(也就是矩阵相对应位置相乘,m x n矩阵A = [aij]与矩阵B = [bij]的Hadamard积),初始化第二个模型,预测标签出现矩阵C中的不确定元素,即, C i j = 0 C_{ij}=0 Cij=0的元素,目标表述为 ∣ ∣ ( X W ˉ ) ∘ ( E − C ) + ( E − C ) ∣ ∣ F 2 ||(X\bar{W})\circ (E-C)+(E-C)||^2_{F} ∣∣(XWˉ)∘(E−C)+(E−C)∣∣F2,其中 E m , n E_{m,n} Em,n是全1矩阵,很明显,这两个模型是不同的,但不够强大,然后我们利用它们通过有前途的协正则化框架,得出一个稳健的预测结果,其思想是使两个模型在对标签出现矩阵C中的不确定元素的预测上变得一致,我的理解是第一个模型能够精确的预测出来对应的能观察到的标签值为1的情况下,然后能够得到对其他位置的预测值,第二个模型预测不确定标签的值,然后让两个模型的值趋近一致,目标是 ∣ ∣ ( X ( W − W ˉ ) ∘ ( E − C ) ∣ ∣ F 2 ||(X(W-\bar{W})\circ (E-C)||^2_{F} ∣∣(X(W−Wˉ)∘(E−C)∣∣F2,综上所述,我们的目标是找到W, W ˉ \bar{W} Wˉ和标签相似矩阵 L L L,这样就可以最小化以下目标
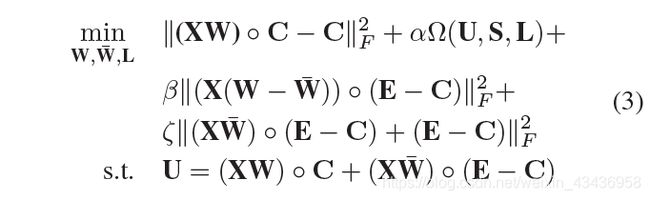
U U U是两个模型的综合预测,等式3一边考虑实例和标签相似性的平滑度,另一方面,它吸收集成学习以获得健壮的结果。值得注意的是,经典的标签传播技术可以作为我们建议的一个特例来实现。

块坐标下降算法
公式3中的目标函数涉及到W, W ^ \hat{W} W^和L,同时对所有变量进行优化并不容易,在这种情况下,我们在这里扩展了一个有效的块坐标下降算法,具体来说,我们首先对目标函数进行优化, W ^ \hat{W} W^和 L L L是固定的,然后对变量 W ^ \hat{W} W^和 L L L进行优化,最后在前两个变量固定的时候对变量L进行优化。这三个子例程重复执行,直到收敛为止。算法1总结了我们建议的伪代码。更具体地说,我们首先介绍一些符号:
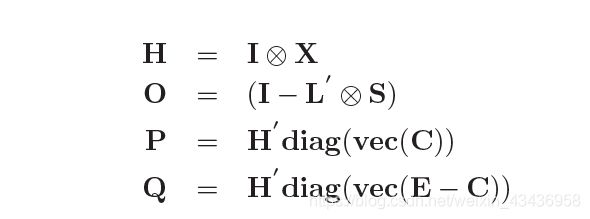
这里vec(M)是矩阵M的向量化,diag(v)与向量v 是一个对角矩阵的对角元素,⊗是克罗内克积
更新W 固定 W ^ \hat{W} W^和L
当 W ^ \hat{W} W^和L固定后,我们得到如下等式,通过设置方程3的导数让W为0
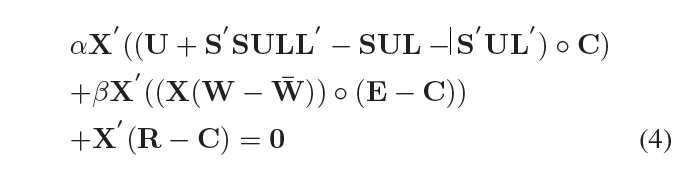
其中 R = ( X W ) ∘ C R=(XW)\circ C R=(XW)∘C,我们能得到:
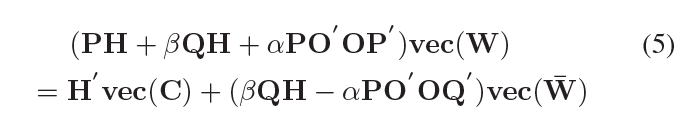
这是一个简单的和正常的线性方程,我们采用共轭梯度算法(Møller 1993),称为计算有效的算法求解线性方程
更新 W ^ \hat{W} W^固定W和L
当W和L固定后,我们得到如下等式,通过设置方程3的导数让 W ^ \hat{W} W^为0
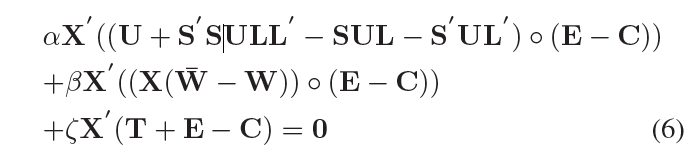
其中 T = ( X W ˉ ) ∘ ( E − C ) T=(X \bar{W})\circ (E-C) T=(XWˉ)∘(E−C),能写为:

利用高效共轭梯度算法求解上述线性方程组。
更新L,固定W和 W ^ \hat{W} W^
当W和 W ^ \hat{W} W^固定后,我们得到如下等式,通过设置方程3的导数让L下降为0
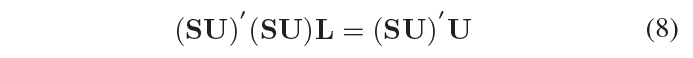
我们有下面这个L的封闭解,它是有效更新的,
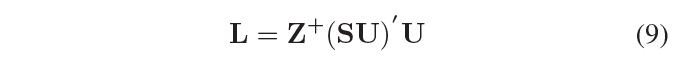
其中 Z = ( S U ) ′ ( S U ) Z=(SU)^{'}(SU) Z=(SU)′(SU)且 Z + Z^{+} Z+表示Z的伪逆矩阵,我们使用公式3的优化解作为最终的 L L L。在得到系数矩阵W之后,我们需要对预测标签矩阵进行离散化,如果 [ X W ] i j > 0 [XW]_{ij}>0 [XW]ij>0,我们设置 Y ^ i j = 1 \hat{Y}_{ij}=1 Y^ij=1,否则设置为-1