多标签分类(六):Fine-Grained Lesion Annotation in CT Images with Knowledge Mined From Radiology Reports
细粒病灶注释在CT图像与知识挖掘从放射学报告
文章来自2019年CVPR
摘要
在放射科医师的日常工作中,一个主要的任务是阅读医学图像,例如CT扫描,发现重要的病变,并在放射学报告中写下句子来描述它们,在本文中,我们研究了在计算机辅助诊断(CAD)中,病灶描述或标注问题的一个重要步骤。给定一幅病变图像,我们的目标是预测多个相关标签,如损伤的身体部位、类型和属性。为了解决这个问题,我们基于RadLex定义了一组145个标签来描述DeepLesion数据集中的大量病变。我们直接从放射学报告中病变的对应句子中挖掘训练标签,这需要最少的人工工作,并且很容易推广到大数据和标签集,在此基础上,提出了一种针对多尺度结构和噪声损耗的图像的多标签卷积神经网络。
1、介绍
病变的检测和分类是计算机辅助诊断(CAD)的重要研究课题。现有的病灶分类研究一般侧重于身体某些部位(如皮肤和肝脏),对病灶类型进行分类(如肝脏囊肿、转移和血管瘤),在这篇文章中,我们处理一个更普遍的问题来模拟放射科医师,当一个有经验的放射科医生阅读医学图像,如计算机断层扫描(CT),他或她可以发现身体不同部位的各种病变,并告诉病变的详细身体部位、类型和属性,我们旨在开发一种算法来预测这些特征,前提是假设已检测到病变或在图像上手动标记了病变,简而言之,我们希望计算机能全面了解病变,并回答“是什么”的问题。我们称它为损伤标注,因为它类似于计算机视觉中的多标签图像标注问题。我们期望这将是迈向全自动CAD系统的重要一步。
这项任务的主要挑战是缺乏培训标签。现有的病变分类研究一般需要专业人员手工对病变进行标记,这种方法准确但繁琐,且无法进行分级,一些研究者利用了放射学报告中包含的丰富信息,但是图像和文本之间没有损伤-级别的对应关系,因此提取的标签不能准确地映射到特定的病变。另一种研究直接根据整体图像生成报告,并通过注意机制在病变之间进行切换,我们没有探索这个方向,因为很难评估计算机生成的报告的可用性,因为它们的质量对于实际使用来说似乎很低。相反,如果我们可以准确地预测描述关键字的病变,则创建高质量(结构化)报告的过程将非常简单。
为了找到病变级别的标签,我们利用了最近发布的DeepLesion数据集,DeepLesion在CT图像中包括身体各部位超过30K的病灶。超过20K的人在报告中有相应的句子以超链接的方式显示出来。病变图像和句子示例见图3:
我们收集了一个基于RadLex lexicon[7]的细粒度标签列表,从包含超链接的句子中提取这些标签,作为病变图像的标签,这个过程完全是数据驱动的,几乎不需要人工,因此可以很容易地用于构建具有丰富词汇量的大型数据集。为了提高标签列表的覆盖范围,我们基于RadLex添加了每个标签的同义词。 还标注了标记之间的等级关系,并用于扩展每个病变的标记集(例如,扩张前:肺结节;扩张后:肺结节,肺,结节,胸部)。然后采用多标签卷积神经网络(CNN)来同时预测每个病变的所有标签。 由于不同的标签可能最好由不同级别的特征建模,因此我们修改了CNN的结构以促进多尺度特征融合,改进了损失函数,以平衡稀有标签和减轻标签噪声的影响。实验结果表明,我们的病灶注释器能够高精度地预测各种病灶的细粒度体部、类型和属性
2.从报告中挖掘标签
我们使用DeepLesion数据集及其伴随的放射学报告来学习我们的模型。在医院,放射科医生有时会在图像上标记明显的病变,并在报告中插入超链接、尺寸测量或切片编号(称为书签),使用这些书签,我们可以将病变区域与描述它的句子链接起来,从而获得病变级别的标签注释,为了挖掘标签,我们首先对包含病变书签的句子进行标记,然后使用NLTK对句子中的单词进行分解以获得它们的基本形式。RadLex v3.15被用作我们的词典。 我们从RadLex中提取了所有标签及其同义词。 由于RadLex中的大多数标签都是名词,因此我们手动添加了一些形容词同义词,例如,“ hepatic”是“ liver”的同义词。 在对句子进行全词匹配并融合了同义词之后,我们在测试集中保留了超过5个出现次数的标签(1,872个样本),从而产生了145个标签的列表。
标签可以分为三类:1.标签的种类。身体部位(共95个标签),包括粗鳞身体部位(如胸部、腹部)、器官(肺、淋巴结)、细粒器官亚部位(右下叶、腹膜后淋巴结)和其他身体部位(肝门、椎管旁);2.发现/类型(24种标记),包括粗粒(结节、肿块)和更具体的(肝肿块、毛玻璃样混浊)。3.属性(26个标签),描述病灶的强度、形状、大小等(低衰减、棘状、大)。这是一套全面的标签。标签之间存在层次关系,如肺结节属于肺,结节属于肺。因此,我们进一步从RadLex中提取标签的父-子关系,然后手工修正。这种关系的子图如图1所示。
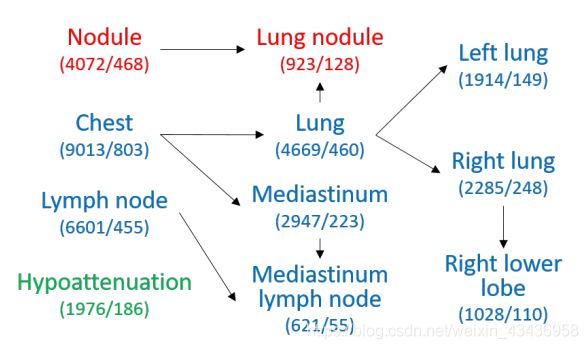
图1表示带有关系的示例标签。箭头从父标签指向子标签。蓝色、红色和绿色分别表示身体部位、类型和属性。每个标签下面的数字是训练样本和测试样本的数量。
用关系图扩展病灶的标记集,如果一个子标签为真,那么它的所有父标签都应该为真,然后,我们可以为每个病变构建一个标记向量 y y y。当且仅当标签 i i i在扩展标签集中时, y i = 1 y_i = 1 yi=1。应当指出的是,在自由文本报告中,用于描述病变的标签通常不完整且细节级别各不相同,例如,“左上叶结节”可以简单地描述为“肺结节”。 标签中缺少信息是很常见的。 但是,我们发现我们的算法实际上可以与嘈杂的训练标签配合使用,并且可以通过应用将在下一节中介绍的噪声鲁棒损失函数来进一步改进
3.病变注释CNN
我们的目标是预测145种标签中每一种的置信度.这是一个多标签分类问题。所提CNN的结构如图2所示。我们首先调整了轴向CT图像的大小,将间距规格化为1毫米/像素,然后以病灶为中心切取固定尺寸120mm×120mm的补片,为了编码3D信息,我们使用3个相邻的切片(以2mm的切片间隔插值)来组成一个3通道的图像。图像被发送到一个批量归一化的vgg16 CNN (vgg16比AlexNet和ResNet50精度更高)

图2表示提出的用于病变标注的多尺度多标签CNN的架构
这项任务的一个挑战是,不同的标签可能最好由不同层次的特征来建模,例如,在预测强度和形状属性时,较低级别的特征更合适。在预测身体部位时,病变周围的背景是重要的,它包含在更高层次的特征中,因此,我们结合vgr -16的5个阶段的特征来得到一个多尺度的表示。由于病变的大小不同,我们采用感兴趣区域(region of interest, ROI)池化层将特征图分别池化到5×5×通道。对于conv1-conv3, ROI是斑块内病变的包围盒,用于聚焦病变的细节,对于conv4和5,ROI是整个斑块来捕捉病变的背景,每个汇集的特征图然后通过一个完全连接层(FC)连接在一起。网络输出的是145个独立分数,经过另一个FC层和一个sigmoid函数。
另一个挑战来自不同类别中阳性标签的数量极不平衡.在19,992个训练病灶中,最常见的标记(胸部)有9013个阳性标记,而最罕见的标记(髂内淋巴结)只有6个阳性标记,一般来说,粗粒的身体部位和类型出现得比较频繁。如果我们只是对每个标签学习一个交叉熵损失,那么模型将很少对稀有标签进行学习,并且总是为它们生成较低的分数,一个简单的解决方案是通过分配不同的权重来平衡每个标签中的正面和负面案例,如式1和式2,其中 w c , p o s , w c , n e g w_{c,pos},w_{c,neg} wc,pos,wc,neg是标签 c c c的阳性和阴性病例的损失权重, N c , p o s , N c , n e g N_{c,pos},N_{c,neg} Nc,pos,Nc,neg是标签 c c c的阳性和阴性训练病例的数量.
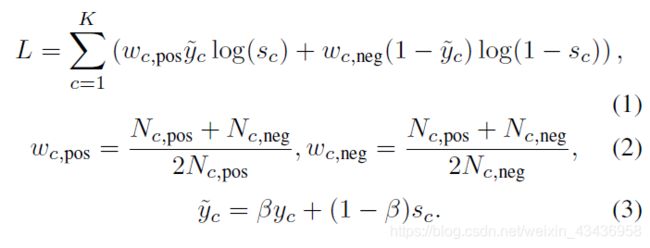
简单的来说,就是将阳性损失权重定义为(阳性样本+阴性样本)/2*阳性,然后加入交叉熵损失函数中
我们的训练标签包含噪音,因为它们是从自由文本报告中提取的,如第2节所述,某些句子中缺少标签。 此外,某些句子中的少量标签与所提及的病变无关。 为了处理标签噪声,我们用软自举损失(soft bootstrapping loss)代替了标准的交叉熵损失。 基本思想是基于模型的当前预测来修改训练标签
等式1中显示了我们模型对一个样本的总体损失函数.其中 K K K是标签总数, y c ~ \tilde{y_c} yc~是自举标签, s c ∈ [ 0 , 1 ] s_c∈[0,1] sc∈[0,1]是网络预测的标签 c c c的分数。在Eq. 3中,bootstrap标签定义为原始标签 y c y_c yc和预测得分 s c s_c sc的加权和,我们根据经验将权重设置为0.9。如果原标签不正确,而预测的结果接近实际正确的标签,bootstrap的损失会小于原标签的损失,以减轻标签噪声的影响.
4.实验
我们从DeepLesion中提取了19,992个病变句对进行训练,另外从1,872对中进行测试。 两组之间没有患者水平的重叠。 手动检查测试语句,以删除与相应病变无关的标签。 但是,可能仍然缺少标签,这需要大量的人工才能完成。 在这方面,我们认为此测试集上的结果不是实际准确性的完美替代,但是是一种合理的替代。
提出的CNN是随机初始化的。采用随机梯度下降训练15个epoch,初始学习率为0.01,在epoch 12时降低到0.001。我们计算了测试集上每个标签的AUC,即受试者工作特征曲线下的面积。表1显示了不同方法的结果:

在第一行中,我们通过使用BatchNorm将全局平均池化层和FC层直接附加到VGG -16之后来评估基线方法,从而预测145个标签。然后将损失权重加入式2中.从第二行可以看出,AUC显著增加。在稀有标签上的改进更大,我们进一步应用了图2中的多尺度结构,结果显示在表1的第三行。病变类型和属性的预测精度得到了提高,因为它们更多地依赖于病变的中、低级特征所包含的细节。最后,我们进一步实现了Eq. 3中的噪声鲁棒自举损耗。病变属性的准确性得到了最大的提高,可能是因为报告中有许多缺失的属性,因为放射科医生通常不会在报告中描述一个病变的所有属性。此外,有些属性可能是主观的。虽然缺少标签也是细颗粒器官子部分的一个问题,但它们并不影响准确性。这是因为器官亚部分外观相对稳定,容易学习。
为了详细说明表1中的结果,我们在表2中显示了一些特定标记的AUC。淋巴结遍布全身,并且具有可变的上下文外观。 因此,其AUC低于其子标签,腹膜后淋巴结,其外观相对稳定。 肝门和脊髓旁等身体部位也具有稳定的外观和较高的AUC。 同样,粗大的病变类型(例如肿块和结节)具有可变的外观并具有主观性,而细小的病变类型(例如肝脏块和毛玻璃样混浊)则更稳定,这说明了它们在AUC中的差异。 一些属性是主观或微妙的,例如 “大”和“低衰减”,因此属性的平均AUC低于类型和身体部位。

定性结果如图3所示。在第一个示例中,我们的算法准确地预测了细小身体部位和肺结节的类型。 在第二个中,正确地预测了纵隔淋巴结。 标签“上纵隔”被认为是假阳性,但实际上是缺失的真实标签。 在第三个示例中,我们确定了病变的身体部位:左肾上腺。 肾脏得分较高,因为它靠近肾上腺,有时会使模型混淆。 假阴性标签的存在可能是由于它们的变量(结节,肿瘤)或微妙的(低衰减)外观。

图3表示病灶图像,报告句以及我们在测试集上带有分数(仅基于图像)的预测标签的示例。 图像中的边界框和直径标记了病变。 报告中的“ BOOKMARK”是我们用来定位句子的超链接。我们将病变的145个预测得分中的前5位视为其预测标签。 前5个中的真实标签为真阳性(TP,绿色),前5个中的错误标签为假阳性(FP,红色),不在前5个中的真实标签为假阴性(FN,蓝色) 。 p r e c e s i o n = T P / ( T P + F P ) , r e c a l l = T P / ( T P + F N ) precesion = TP/(TP+FP),recall = TP/(TP+FN) precesion=TP/(TP+FP),recall=TP/(TP+FN)
5.结论
在本文中,我们从自由文本报告中挖掘出细粒度的损伤级别描述,并将其与损伤图像链接起来,构建一个全面的损伤标注算法。我们未来的工作包括使用自然语言处理算法来减少报告中的标签噪音,以及提高硬标签和稀有标签的预测精度