作者|Orhan Gazi Yalçınv
编译|VK
来源|Towards Datas Science
你可能对不同的神经网络结构有点熟悉。你可能听说过前馈神经网络,CNNs,RNNs,这些神经网络对于解决诸如回归和分类之类的监督学习任务非常有用。
但是,在无监督学习领域,我们面临着大量的问题,如降维、特征提取、异常检测、数据生成、增强以及噪声抑制等。对于这些任务,我们需要特殊的神经网络的帮助,这些神经网络是专门为无监督学习任务而开发的。
因此,他们必须能够在不需要监督的情况下训练出来。其中一种特殊的神经网络结构是自编码器。
自编码器
什么是自编码器?
自编码器是一种神经网络结构,它由两个子网络组成,即编码和解码网络,它们之间通过一个潜在空间相互连接。
自编码器最早由杰弗里·辛顿(Geoffrey Hinton)和PDP小组在20世纪80年代开发。Hinton和PDP小组的目标是解决“没有教师的反向传播”问题,即无监督学习,将输入作为教师。换句话说,他们只是简单地将特征数据用作特征数据和标签数据。让我们仔细看看自编码器是如何工作的!
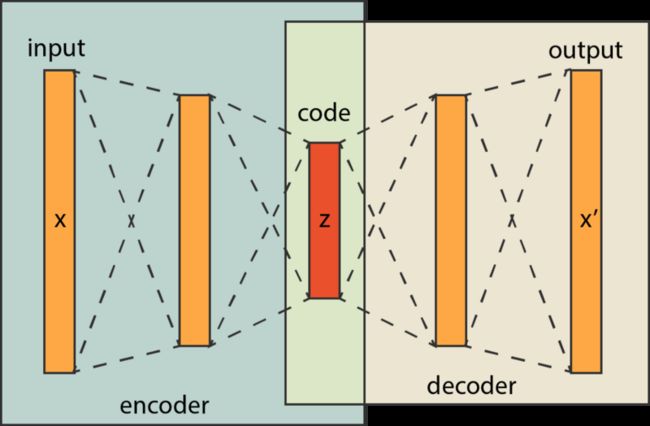
自编码器体系结构
自编码器由一个编码器网络组成,该网络接收特征数据并对其进行编码以适应潜在空间。解码器使用该编码数据(即代码)将其转换回特征数据。在编码器中,模型学习的是如何有效地编码数据,以便解码器能够将其转换回原始数据。因此,自编码器训练的关键是生成一个优化的潜在空间。
现在,要知道在大多数情况下,潜在空间中的神经元数量要比输入层和输出层小得多,但不一定要这样。有不同类型的自编码器,如欠完备、过完备、稀疏、去噪、压缩和变分自编码器。在本教程中,我们只关注用于去噪的欠完备自编码器。
自编码器中的层
构建自编码器时的标准做法是设计一个编码器并创建该网络的反向版本作为该自编码器的解码器。因此,只要编码器和解码器网络之间存在反向关系,你就可以自由地向这些子网络添加任何层。例如,如果你处理的是图像数据,你肯定需要卷积和池层。另一方面,如果要处理序列数据,则可能需要LSTM、GRU或RNN单元。这里重要的一点是,你可以自由地构建任何你想要的东西。

现在,你已经有了可以构建图像降噪的自编码器的想法,我们可以继续学习教程,开始为图像降噪模型编写代码。在本教程中,我们选择使用TensorFlow的官方教程之一《Autoencoders简介》[1],我们将使用AI社区成员中非常流行的数据集:Fashion MNIST。
下载Fashion MNIST数据集
Fashion MNIST由德国柏林的欧洲电子商务公司Zalando设计和维护。Fashion MNIST由60000个图像的训练集和10000个图像的测试集组成。每个例子是一个28×28的灰度图像,与来自10个类的标签相关联。
Fashion MNIST包含服装的图像(如图所示),被设计为MNIST数据集的替代数据集,MNIST数据集包含手写数字。我们选择Fashion MNIST仅仅是因为MNIST在许多教程中已经被过度使用。
下面的行导入TensorFlow和load Fashion MNIST:
import tensorflow as tf
from tensorflow.keras.datasets import fashion_mnist
# 我们不需要y_train和y_test
(x_train, _), (x_test, _) = fashion_mnist.load_data()
print('Max value in the x_train is', x_train[0].max())
print('Min value in the x_train is', x_train[0].min())现在,让我们使用数据集中的示例生成一个网格,其中包含以下行:
import matplotlib.pyplot as plt
fig, axs = plt.subplots(5, 10)
fig.tight_layout(pad=-1)
plt.gray()
a = 0
for i in range(5):
for j in range(10):
axs[i, j].imshow(tf.squeeze(x_test[a]))
axs[i, j].xaxis.set_visible(False)
axs[i, j].yaxis.set_visible(False)
a = a + 1 我们的输出显示了测试数据集的前50个样本:

处理Fashion MNIST数据
为了提高计算效率和模型可靠性,我们必须对图像数据应用Minmax规范化,将值范围限制在0到1之间。由于我们的数据是RGB格式的,所以最小值为0,最大值为255,我们可以使用以下代码进行最小最大规格化操作:
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.我们还必须改变NumPy数组维度,因为数据集的当前形状是(60000,28,28)和(10000,28,28)。我们只需要添加一个单一值的第四个维度(例如,从(60000,28,28)到(60000,28,28,1))。
第四维几乎可以证明我们的数据是灰度格式的。如果我们有彩色图像,那么我们需要在第四维中有三个值。但是我们只需要一个包含单一值的第四维度,因为我们使用灰度图像。以下几行代码可以做到这一点:
x_train = x_train[…, tf.newaxis]
x_test = x_test[…, tf.newaxis]让我们通过以下几行来看看NumPy数组的形状:
print(x_train.shape)
print(x_test.shape)输出:(60000,28,1)和(10000,28,28,1)
给图像添加噪声
记住我们的目标是建立一个模型,它能够对图像进行降噪处理。为了做到这一点,我们将使用现有的图像数据并将它们添加到随机噪声中。
然后,我们将原始图像作为输入,噪声图像作为输出。我们的自编码器将学习干净的图像和有噪声的图像之间的关系,以及如何清除有噪声的图像。
因此,让我们创建一个有噪声的版本。
对于这个任务,我们使用tf.random.normal方法。然后,我们用一个噪声系数乘以随机值,你可以随意使用它。以下代码为图像添加噪声:
noise_factor = 0.4
x_train_noisy = x_train + noise_factor * tf.random.normal(shape=x_train.shape)
x_test_noisy = x_test + noise_factor * tf.random.normal(shape=x_test.shape)我们还需要确保数组项的值在0到1的范围内。为此,我们可以使用 tf.clip_by_value方法。clip_by_value是一种TensorFlow方法,它将“最小值-最大值”范围之外的值剪裁并替换为指定的“最小值”或“最大值”。以下代码剪辑超出范围的值:
x_train_noisy = tf.clip_by_value(x_train_noisy, clip_value_min=0., clip_value_max=1.)
x_test_noisy = tf.clip_by_value(x_test_noisy, clip_value_min=0., clip_value_max=1.)现在,我们已经创建了数据集的规则化和噪声版本,我们可以查看它的外观:
n = 5
plt.figure(figsize=(20, 8))
plt.gray()
for i in range(n):
ax = plt.subplot(2, n, i + 1)
plt.title("original", size=20)
plt.imshow(tf.squeeze(x_test[i]))
plt.gray()
bx = plt.subplot(2, n, n+ i + 1)
plt.title("original + noise", size=20)
plt.imshow(tf.squeeze(x_test_noisy[i]))
plt.show()
正如你所见,在嘈杂的图像中几乎不可能理解我们所看到的。然而,我们的自编码器将神奇地学会清洁它。
建立我们的模型
在TensorFlow中,除了顺序API和函数API之外,还有第三种方法来构建模型:模型子类化。在模型子类化中,我们可以自由地从零开始实现一切。
模型子类化是完全可定制的,使我们能够实现自己的定制模型。这是一个非常强大的方法,因为我们可以建立任何类型的模型。但是,它需要基本的面向对象编程知识。我们的自定义类是tf.keras.Model对象。它还需要声明几个变量和函数。
另外请注意,由于我们处理的是图像数据,因此构建一个卷积式自编码器更为有效,如下所示:

要构建模型,我们只需完成以下任务:
- 创建一个扩展keras.Model的对象
- 创建一个函数来声明两个用顺序API构建的独立模型。在它们中,我们需要声明相互颠倒的层。一个Conv2D层用于编码器模型,而一个Conv2DTranspose层用于解码器模型。
- 使用__init__ 方法创建一个call函数,告诉模型如何使用初始化的变量来处理输入
- 我们需要调用以图像为输入的初始化编码器模型
- 我们还需要调用以编码器模型(encoded)的输出作为输入的初始化解码器模型
- 返回解码器的输出
我们可以通过以下代码实现所有这些目标:
from tensorflow.keras.layers import Conv2DTranspose, Conv2D, Input
class NoiseReducer(tf.keras.Model):
def __init__(self):
super(NoiseReducer, self).__init__()
self.encoder = tf.keras.Sequential([
Input(shape=(28, 28, 1)),
Conv2D(16, (3,3), activation='relu', padding='same', strides=2),
Conv2D(8, (3,3), activation='relu', padding='same', strides=2)])
self.decoder = tf.keras.Sequential([
Conv2DTranspose(8, kernel_size=3, strides=2, activation='relu', padding='same'),
Conv2DTranspose(16, kernel_size=3, strides=2, activation='relu', padding='same'),
Conv2D(1, kernel_size=(3,3), activation='sigmoid', padding='same')])
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded让我们用一个对象调用来创建模型:
autoencoder = NoiseReducer()配置我们的模型
对于这个任务,我们将使用Adam优化器和模型的均方误差。我们可以很容易地使用compile函数来配置我们的自编码器,如下所示:
autoencoder.compile(optimizer='adam', loss='mse')最后,我们可以在10个epoch下通过输入噪声和干净的图像运行我们的模型,这将需要大约1分钟的训练。我们还使用测试数据集进行验证。以下代码用于训练模型:
autoencoder.fit(x_train_noisy,
x_train,
epochs=10,
shuffle=True,
validation_data=(x_test_noisy, x_test))
用我们训练过的自编码器降低图像噪声
我们现在就可以开始清理噪音图像了。注意,我们可以访问编码器和解码器网络,因为我们在NoiseReducer对象下定义了它们。
所以,首先,我们将使用一个编码器来编码我们的噪声测试数据集(x_test_noise)。然后,我们将编码后的输出输入到解码器,以获得干净的图像。以下代码完成这些任务:
encoded_imgs=autoencoder.encoder(x_test_noisy).numpy()
decoded_imgs=autoencoder.decoder(encoded_imgs)让我们绘制前10个样本,进行并排比较:
n = 10
plt.figure(figsize=(20, 7))
plt.gray()
for i in range(n):
# 显示原始+噪声
bx = plt.subplot(3, n, i + 1)
plt.title("original + noise")
plt.imshow(tf.squeeze(x_test_noisy[i]))
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 显示重建
cx = plt.subplot(3, n, i + n + 1)
plt.title("reconstructed")
plt.imshow(tf.squeeze(decoded_imgs[i]))
bx.get_xaxis().set_visible(False)
bx.get_yaxis().set_visible(False)
# 显示原始
ax = plt.subplot(3, n, i + 2*n + 1)
plt.title("original")
plt.imshow(tf.squeeze(x_test[i]))
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()第一行用于噪声图像,第二行用于清理(重建)图像,最后,第三行用于原始图像。查看清理后的图像与原始图像的相似性:

结尾
你已经构建了一个自编码器模型,它可以成功地清除非常嘈杂的图像,这是它以前从未见过的(我们使用测试数据集)。
显然有一些未恢复的变形,例如右起第二张图片中缺少拖鞋的底部。然而,如果考虑到噪声图像的变形程度,我们可以说我们的模型在恢复失真图像方面是相当成功的。
在我的脑子里,你可以比如说——考虑扩展这个自编码器,并将其嵌入照片增强应用程序中,这样可以提高照片的清晰度和清晰度。
参考
[1] Intro to Autoencoders, TensorFlow, available on https://www.tensorflow.org/tu...
原文链接:https://towardsdatascience.co...
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/