利用TensorFlow2.0为胆固醇、血脂、血压数据构建时序深度学习模型(python完整源代码)
背景数据描述
胆固醇、高血脂、高血压是压在广大中年男性头上的三座大山,如何有效的监控他们,做到早发现、早预防、早治疗尤为关键,趁着这个假期我就利用TF2.0构建了一套时序预测模型,一来是可以帮我预发疾病,二来也可以体验下TF2.0的特性。
先来看下数据结构:

-
date表示的是测量日期
-
cholesterol代表胆固醇数值
-
blood_fat代表血脂
-
blood_pressure代表血压
整个的建模思路就是将这三个数值一起构建时序模型,因为这三个指标不能独立来看,他们是相互有影响的,互为特征和目标值。
代码详解
废话不多说,我们先看下完整的代码,代码比较长,我把整个代码分为数据探查、网络构建、模型训练、模型保存和预测这4个模块进行拆分并讲解,可以参见代码中的注释进行模块区分。环境使用的是python3.7、TensorFlow2.0版本。(完整代码见文末)
1 数据探查
在数据探查模块使用了pandas将数据读取进来,然后用diff函数构建了时序数据的增长率曲线图,因为做时序数据预测,更多地是去看数据的增长或者降低趋势。通过matplotlib可以把数据的成长曲线画出来:
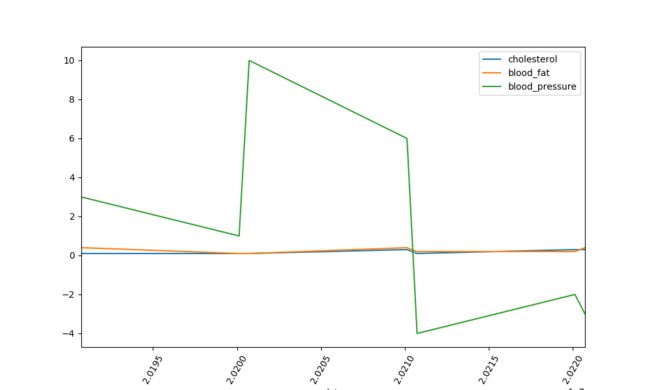
2 网络结构构建
使用的是标准的lstm网络结构,可以通过model.summary函数将深度学习网络结构打印出来,如下图所示:

3 模型训练
在模型训练环节主要是构建了收敛函数MSPE,MSPE是一种残差收敛算法,具体计算公式比较简单:
(y_true - y_pred)**2/(tf.maximum(y_true**2,1e-7))
4 模型存储和预测
第四部分先使用model.save这个TF的官方模型保持函数将模型保存到本地,建议尽量使用这种官方的模型保持方案。
然后load模型对象,用model.predict函数对下一阶段的3个指标数据做一个预测。最终的预测结果存放在arr_predict对象中,预测结果为:
[[0.26552328,0.33151102,0]]
以上预测的是数据的增长率,假设最后一阶段的三个指标的数据分别为4.5、3.2、119,那么最终下一阶段的预测值就是:
[[4.5+0.26552328,3.2+0.33151102,119+0]]
完整代码如下,有兴趣的同学可以跑一跑玩一玩。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import models,layers,losses,metrics,callbacks
import os
import datetime
#1.数据探查-------------------------------------
df = pd.read_csv("/Users/garvin/Downloads/data.txt",sep = "\t")
print(df)
dfdata = df.set_index("date")
dfdiff = dfdata.diff(periods=1).dropna()
dfdiff = dfdiff.reset_index("date")
dfdiff.plot(x = "date",y = ["cholesterol","blood_fat","blood_pressure"],figsize=(10,6))
plt.xticks(rotation=60)
dfdiff = dfdiff.drop("date",axis = 1).astype("float32")
plt.show()
WINDOW_SIZE = 1
def batch_dataset(dataset):
dataset_batched = dataset.batch(WINDOW_SIZE,drop_remainder=True)
return dataset_batched
ds_data = tf.data.Dataset.from_tensor_slices(tf.constant(dfdiff.values,dtype = tf.float32)) \
.window(WINDOW_SIZE,shift=1).flat_map(batch_dataset)
ds_label = tf.data.Dataset.from_tensor_slices(
tf.constant(dfdiff.values[WINDOW_SIZE:],dtype = tf.float32))
#We put all data into one batch for better efficiency since the data volume is small.
ds_train = tf.data.Dataset.zip((ds_data,ds_label)).batch(38).cache()
#2.构建网络结构-------------------------------------
class Block(layers.Layer):
def __init__(self, **kwargs):
super(Block, self).__init__(**kwargs)
def call(self, x_input,x):
x_out = tf.maximum((1+x)*x_input[:,-1,:],0.0)
return x_out
def get_config(self):
config = super(Block, self).get_config()
return config
tf.keras.backend.clear_session()
x_input = layers.Input(shape = (None,3),dtype = tf.float32)
x = layers.LSTM(3,return_sequences = True,input_shape=(None,3))(x_input)
x = layers.LSTM(3,return_sequences = True,input_shape=(None,3))(x)
x = layers.LSTM(3,return_sequences = True,input_shape=(None,3))(x)
x = layers.LSTM(3,input_shape=(None,3))(x)
x = layers.Dense(3)(x)
x = Block()(x_input,x)
model = models.Model(inputs = [x_input],outputs = [x])
model.summary()
#Customized loss function, consider the ratio between square error and the prediction
class MSPE(losses.Loss):
def call(self,y_true,y_pred):
err_percent = (y_true - y_pred)**2/(tf.maximum(y_true**2,1e-7))
mean_err_percent = tf.reduce_mean(err_percent)
return mean_err_percent
def get_config(self):
config = super(MSPE, self).get_config()
return config
#3.模型训练-------------------------------------
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
model.compile(optimizer=optimizer,loss=MSPE(name = "MSPE"))
stamp = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
logdir = os.path.join('data', 'autograph', stamp)
tb_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
#Half the learning rate if loss is not improved after 100 epoches
lr_callback = tf.keras.callbacks.ReduceLROnPlateau(monitor="loss",factor = 0.5, patience = 100)
#Stop training when loss is not improved after 200 epoches
stop_callback = tf.keras.callbacks.EarlyStopping(monitor = "loss", patience= 200)
callbacks_list = [tb_callback,lr_callback,stop_callback]
history = model.fit(ds_train,epochs=10,callbacks = callbacks_list)
#4.模型保存和预测-------------------------------------
model.save('tf_model_savedmodel', save_format="tf")
print('export saved model.')
dfresult = dfdiff[["cholesterol","blood_fat","blood_pressure"]].copy()
dfresult.tail()
#print(dfresult.values[-1:,:])
arr_predict = model.predict(tf.constant(tf.expand_dims(dfresult.values[-1:,:],axis = 0)))
print(arr_predict)