Faster-RCNN全面解读(手把手带你分析代码实现)---完结篇
代码连接:https://github.com/xiguanlezz/Faster-RCNN
一、反向传播
因为Faster-RCNN的loss值是包含两部分的,第一部分是先验框即anchors和对应anchors_target的loss;第二部分是建议框即proposals和对应的proposals_target的loss。
1、anchors的loss
其实就是先剔除掉在图片外面的先验框,然后根据IOU来创建标签,在__call___函数里计算了回归值以及标签信息。
import numpy as np
from utils.util import calculate_iou, get_inside_index, box2loc
class AnchorTargetCreator:
def __init__(self,
n_sample=256,
pos_iou_thresh=0.7,
neg_iou_thresh=0.3,
pos_ratio=0.5):
"""
function description: AnchorTargetCreator构造函数
:param n_sample: 256, target的总数量
:param pos_iou_thresh: 和boxes的iou的阈值,超过此值为"正"样本, label会置为1
:param neg_iou_thresh: 和boxes的iou的阈值,低于此之为"负"样本, label会置为0
:param pos_ratio: target总数量中"正"样本的比例
"""
self.n_sample = n_sample
self.pos_iou_thresh = pos_iou_thresh
self.neg_iou_thresh = neg_iou_thresh
self.pos_ratio = pos_ratio # target总数量中"正"样本,如果正样本数量不足,则填充负样本
def __call__(self, boxes, anchors, img_size):
"""
function description: 得到先验框对应的回归值和的labels
:param boxes: 图片中真实框左上角和右下角的坐标, 维度: [boxes_num, 4]
:param anchors: 根据featuremap生成的所有anchors的坐标, 维度: [anchors_num, 4]
:param img_size: 原图的大小, 用来过滤掉出界的anchors
:return:
anchor_locs: 最终的坐标, 维度为[inside_anchors_num ,4]
anchor_labels: 最终的标签, 维度为[inside_anchors_num]
"""
img_width, img_height = img_size
inside_index = get_inside_index(anchors, img_width, img_height)
# 根据index取到在图片内部的anchors
inside_anchors = anchors[inside_index]
# 返回维度都为[inside_anchors_num]的每个先验框对应的iou最大的真实框的索引及打好的标签
argmax_ious, labels = self._create_label(inside_anchors, boxes)
# 计算inside_anchors和对应iou最大的boxes的回归值
locs = box2loc(inside_anchors, boxes[argmax_ious])
anchors_num = len(anchors)
# 把inside_anchors重新展开回原来所有的anchors方便计算第一部分关于先验框的loss
anchor_labels = np.empty((anchors_num,), dtype=labels.dtype)
anchor_labels.fill(-1)
anchor_labels[inside_index] = labels
# 利用broadcast重新展开locs方便计算第一部分关于先验框的loss
anchor_locs = np.empty((anchors_num,) + locs.shape[1:], dtype=locs.dtype)
anchor_locs.fill(0)
anchor_locs[inside_index, :] = locs
return anchor_locs, anchor_labels
def _create_label(self, inside_anchors, boxes):
"""
function description: 为每个inside_anchors创建一个label, 其中1表示正样本, 0表示负样本, -1则忽略
所有打标签的情况:
1、与真实框的iou最高的先验框的分配为正样本;
2、与真实框的iou大于pos_iou_thresh的分配为正样本;
3、与真实框的iou小于neg_iou_thresh的分配为负样本
:param inside_anchors: 在图片内的先验框(anchors), 维度为: [inside_anchors_num, 4]
:param boxes: 图片中的真实标注框, 维度为: [boxes_num, 4]
:return:
argmax_ious: 每个先验框对应的iou最大的真实框的索引, 维度为: [inside_anchors_num]
label: 为每个inside_anchors创建的label, 维度为: [inside_anchors_num]
"""
# 对于每个在图片内的anchor都生成一个label
label = np.empty((len(inside_anchors)), dtype=np.int32)
# 先将label初始化为-1, 默认为忽略的label
label.fill(-1)
# argmax_ious, max_ious, gt_argmax_ious维度都为: [inside_anchors_num]
argmax_ious, max_ious, gt_argmax_ious = self._calculate_iou(inside_anchors, boxes)
# 将与真实框的iou重叠最大的anchors设置为正样本(分配每个真实框至少对应一个先验框); 对应情况(a)
label[gt_argmax_ious] = 1
# 大于正样本的阈值则设置为正样本即将label设置为1; 对应情况(b)
label[max_ious >= self.pos_iou_thresh] = 1
# 小于负样本的阈值就设置为负样本即将label设置为0; 对应情况(c)
label[max_ious < self.neg_iou_thresh] = 0
# 下面的代码都是平衡正负样本,保持总数量为256(忽略-1的锚点)
pos_standard = int(self.pos_ratio * self.n_sample)
pos_num = np.where(label == 1)[0]
if len(pos_num) > pos_standard:
# replace=False表示随机选择索引的时候不会重复
disable_index = np.random.choice(pos_num, size=(len(pos_num) - pos_standard), replace=False)
label[disable_index] = -1
neg_standard = self.n_sample - np.sum(label == 1) # 非正样本的个数
neg_num = np.where(label == 0)[0]
if len(neg_num) > neg_standard:
disable_index = np.random.choice(neg_num, size=(len(neg_num) - neg_standard), replace=False)
label[disable_index] = -1
return argmax_ious, label
def _calculate_iou(self, inside_anchors, boxes):
"""
function description: 从二维iou张量中获得每个先验框对应的iou最大的真实框的索引以及相应iou的值
:param inside_anchors: 在图片内的先验框(anchors)
:param boxes: 图片中的真实框
:return:
argmax_ious: 每个inside_anchor对应所有boxes中的最高iou的索引, 维度为: [inside_anchors_num]
max_ious: 每个inside_anchor对应所有boxes中的最高iou, 维度为: [inside_anchors_num]
gt_argmax_ious: 每个box对应所有inside_anchors中的最高iou的索引, 维度为: [inside_anchors_num]
"""
# 第一个维度是先验框的个数(inside_anchors_num), 第二个维度是真实框的个数(boxes_num)
ious = calculate_iou(inside_anchors, boxes)
argmax_ious = ious.argmax(axis=1) # 维度为:[inside_num]
# 取到每个先验框对应的真实框最大的iou
# TODO 将第一个维度从np.arange(len(inside_anchors))改为np.arange(len(ious))
max_ious = ious[np.arange(len(ious)), argmax_ious]
gt_argmax_ious = ious.argmax(axis=0) # 维度为:[boxes_num]
# 取到每个真实框对应的先验框最大的iou
gt_max_ious = ious[gt_argmax_ious, np.arange(ious.shape[1])]
gt_argmax_ious = np.where(ious == gt_max_ious)[0]
return argmax_ious, max_ious, gt_argmax_ious
2、proposals的loss
这个部分主要逻辑就是保持正负样本的均衡性,在__call___函数里计算了回归值并将rois打上相应的标签信息。
import numpy as np
from utils.util import calculate_iou, box2loc
class ProposalTargetCreator:
def __init__(self,
n_sample=128,
pos_ratio=0.25,
pos_iou_thresh=0.5,
neg_iou_thresh_hi=0.5,
neg_iou_thresh_lo=0.0):
"""
function description: 采样128正负样本个传入FastRCNN的网络
:param n_sample: 需要采样的数量
:param pos_ratio: 正样本比例
:param pos_iou_thresh: 正样本阈值
:param neg_iou_thresh_hi: 负样本最大阈值
:param neg_iou_thresh_lo: 负样本最低阈值
:return:
sample_rois: 采样后的感兴趣区域
gt_roi_labels: boxes的标签
gt_roi_locs: sample_rois和boxes的线性回归值
"""
self.n_sample = n_sample
self.pos_ratio = pos_ratio
self.pos_iou_thresh = pos_iou_thresh
self.neg_iou_thresh_hi = neg_iou_thresh_hi
self.neg_iou_thresh_lo = neg_iou_thresh_lo
def __call__(self,
rois,
boxes,
labels,
loc_normalize_mean=(0., 0., 0., 0.),
loc_normalize_std=(0.1, 0.1, 0.2, 0.2)):
"""
function description: 得到采样后的rois, 及其对应的labels和回归值
:param rois: rpn输入的rois
:param boxes: 一幅图的位置标注
:param labels: 一幅图的类别标注
:param loc_normalize_mean: 均值
:param loc_normalize_std: 标准差
:return:
"""
n_bbox, _ = boxes.shape
# 取到正样本的个数(四舍五入)
pos_num = np.round(self.n_sample * self.pos_ratio)
ious = calculate_iou(rois, boxes)
gt_assignment = ious.argmax(axis=1) # 返回维度为[rois_num]
max_iou = ious.max(axis=1)
gt_roi_labels = labels[gt_assignment] # 返回维度为[rois_num]
# 筛选出其中iou满足阈值的部分
pos_index = np.where(max_iou >= self.pos_iou_thresh)[0]
pos_num_for_this_image = int(min(pos_num, pos_index.size))
if pos_index.size > 0:
pos_index = np.random.choice(pos_index, size=pos_num_for_this_image, replace=False)
# 筛选出其中iou不满足阈值的部分
neg_index = np.where((max_iou < self.neg_iou_thresh_hi) & (max_iou >= self.neg_iou_thresh_lo))[0]
neg_num = self.n_sample - pos_num_for_this_image
neg_num_for_this_image = int(min(neg_index.size, neg_num))
if neg_index.size > 0:
neg_index = np.random.choice(neg_index, size=neg_num_for_this_image, replace=False)
keep_index = np.append(pos_index, neg_index)
gt_roi_labels = gt_roi_labels[keep_index]
gt_roi_labels[pos_num_for_this_image:] = 0 # 背景标记为0, pos_num_for_this_image及之后的索引都标为0
sample_rois = rois[keep_index]
gt_roi_locs = box2loc(sample_rois, boxes[gt_assignment[keep_index]])
return sample_rois, gt_roi_labels, gt_roi_locs
3、总loss
先来看一下论文中对总loss公式的定义:

至于代码中的实现相当于是加了不同的权重,总的loss值主要是第二部分loss中的,而且只计算label中为正样本的loss值(因为label为0表示背景,会略背景的loss计算)。
def smooth_l1_loss(x, t, in_weight, sigma):
"""
function description: 计算L1损失函数
:param x: 输出的位置信息
:param t: 标注的位置信息
:param in_weight: 筛选矩阵, 非正样本的地方为0
:param sigma:
:return:
"""
sigma2 = sigma ** 2
diff = in_weight * (x - t)
abs_diff = diff.abs()
flag = (abs_diff.data < (1. / sigma2)).float()
# TODO loss的计算
y = (flag * (sigma2 / 2.) * (diff ** 2) + (1 - flag) * (abs_diff - 0.5 / sigma2))
return y.sum()
def loc_loss(pred_loc, gt_loc, gt_label, sigma):
"""
function description: 仅对正样本进行loc_loss值的计算
:param pred_loc: 输出的位置信息
:param gt_loc: 标注的位置信息
:param gt_label: 标注的类别
:param sigma:
:return:
"""
in_weight = torch.zeros(gt_loc.shape).cuda()
# 用作筛选矩阵, 维度为[gt_label_num, 4]
in_weight[(gt_label > 0).view(-1, 1).expand_as(in_weight)] = 1
loc_loss = smooth_l1_loss(pred_loc, gt_loc, in_weight.detach(), sigma)
loc_loss /= ((gt_label >= 0).sum().float())
return loc_loss
二、Faster-RCNN代码
可以将上篇文章中的网络再看看,这里就是将之前讲过的网络组合起来,并计算一个loss。
from torch import nn
import torch.nn.functional as F
from nets.vgg16 import decom_VGG16
from nets.rpn import RPN
from nets.anchor_target_creator import AnchorTargetCreator
from nets.proposal_target_creator import ProposalTargetCreator
from nets.fast_rcnn import FastRCNN
from utils.util import loc_loss
from collections import namedtuple
import torch
from utils.util import loc2box, non_maximum_suppression
import numpy as np
from configs.config import class_num, device_name
LossTuple = namedtuple('LossTuple',
['rpn_loc_loss',
'rpn_cls_loss',
'roi_loc_loss',
'roi_cls_loss',
'total_loss'
])
device = torch.device(device_name)
class FasterRCNN(nn.Module):
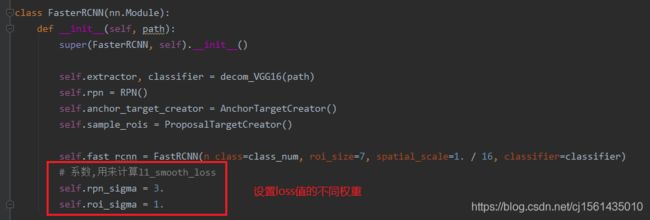
def __init__(self, path):
super(FasterRCNN, self).__init__()
self.extractor, classifier = decom_VGG16(path)
self.rpn = RPN()
self.anchor_target_creator = AnchorTargetCreator()
self.sample_rois = ProposalTargetCreator()
self.fast_rcnn = FastRCNN(n_class=class_num, roi_size=7, spatial_scale=1. / 16, classifier=classifier)
# 系数,用来计算l1_smooth_loss
self.rpn_sigma = 3.
self.roi_sigma = 1.
def forward(self, x, gt_boxes, labels):
# -----------------part 1: feature 提取部分----------------------
h = self.extractor(x)
# -----------------part 2: rpn部分(output_1)----------------------
img_size = (x.size(2), x.size(3))
# rpn_locs维度为: [batch_size, w, h, 4*k], 类型是pytorch的张量
# rpn_scores维度为: [batch_size, w, h, k], 类型是pytorch的张量
# anchors维度为: [batch_size, w*h*k, 4], 类型是numpy数组
# rois维度为: [w*h*k ,4]
rpn_locs, rpn_scores, anchors, rois = self.rpn(h, img_size)
# gt_anchor_locs维度为: [anchors_num, 4], gt_anchor_labels维度为:[anchors_num]
# gt_anchor_labels这个labels如果为1表示先验框内有物体, 0表示先验框内没有物体
gt_anchor_locs, gt_anchor_labels = self.anchor_target_creator(gt_boxes[0].detach().cpu().numpy(),
anchors,
img_size)
# ----------------part 3: roi采样部分----------------------------
# gt_roi_labels这个labels表示rois所属类别
sample_rois, gt_roi_labels, gt_roi_locs = self.sample_rois(rois,
gt_boxes[0].detach().cpu().numpy(),
labels[0].detach().cpu().numpy())
# ---------------part 4: fast rcnn(roi)部分(output_2)------------
# roi_cls_locs维度为: [batch_size, 4], roi_scores维度为:[batch_size, 1]
roi_locs, roi_scores = self.fast_rcnn(h, sample_rois)
# RPN LOSS
gt_anchor_locs = torch.from_numpy(gt_anchor_locs).to(device)
gt_anchor_labels = torch.from_numpy(gt_anchor_labels).long().to(device)
# rpn_scores[0]维度为[batch_size, w*h*k, 2], 且第三个维度为0表示不包含object的置信度, 1表示包含object的置信度
rpn_cls_loss = F.cross_entropy(rpn_scores[0], gt_anchor_labels, ignore_index=-1) # label值为-1的不参与loss值的计算
rpn_loc_loss = loc_loss(rpn_locs[0], gt_anchor_locs, gt_anchor_labels, self.rpn_sigma)
# ROI LOSS
gt_roi_labels = torch.from_numpy(gt_roi_labels).long().to(device)
gt_roi_locs = torch.from_numpy(gt_roi_locs).float().to(device)
roi_cls_loss = F.cross_entropy(roi_scores, gt_roi_labels)
n_sample = roi_locs.shape[0] # batch_size
roi_cls_locs = roi_locs.view(n_sample, -1, 4)
roi_locs = roi_cls_locs[torch.arange(0, n_sample).long(), gt_roi_labels]
roi_loc_loss = loc_loss(roi_locs.contiguous(), gt_roi_locs, gt_roi_labels, self.roi_sigma)
losses = [rpn_loc_loss, rpn_cls_loss, roi_loc_loss, roi_cls_loss]
losses = losses + [sum(losses)]
return LossTuple(*losses)
@torch.no_grad()
def predict(self, x):
# 设置为测试模式, 改变rpn网络中n_post_nms的阈值为300
self.eval()
# -----------------part 1: feature 提取部分----------------------
h = self.extractor(x)
img_size = (x.size(2), x.size(3))
# ----------------------part 2: rpn部分--------------------------
rpn_locs, rpn_socres, anchors, rois = self.rpn(h, img_size)
# ------------------part 3: fast rcnn(roi)部分-------------------
# 先经过Roi pooling层, 在经过两个全连接层
roi_locs, roi_scores = self.fast_rcnn(h, np.asarray(rois))
n_sample = roi_locs.shape[0]
# --------------------part 4:boxes生成部分-----------------------
roi_cls_locs = roi_locs.view(n_sample, -1, 4)
rois = torch.from_numpy(rois).to(device)
rois = rois.view(-1, 1, 4).expand_as(roi_cls_locs)
boxes = loc2box(rois.cpu().numpy().reshape((-1, 4)), roi_cls_locs.cpu().numpy().reshape((-1, 4)))
boxes = torch.from_numpy(boxes).to(device)
# 修剪boxes中的坐标, 使其落在图片内
boxes[:, [0, 2]] = (boxes[:, [0, 2]]).clamp(min=0, max=img_size[0])
boxes[:, [1, 3]] = (boxes[:, [1, 3]]).clamp(min=0, max=img_size[1])
boxes = boxes.view(n_sample, -1)
# roi_scores转换为概率, prob维度为[rois_num, 7]
prob = F.softmax(roi_scores, dim=1)
# ----------------part 5:筛选环节------------------------
raw_boxes = boxes.cpu().numpy()
raw_prob = prob.cpu().numpy()
final_boxes, labels, scores = self._suppress(raw_boxes, raw_prob)
self.train()
return final_boxes, labels, scores
def _suppress(self, raw_boxes, raw_prob):
# print(raw_prob.shape)
score_thresh = 0.7
nms_thresh = 0.3
n_class = class_num
box = list()
label = list()
score = list()
for i in range(1, class_num):
box_i = raw_boxes.reshape((-1, n_class, 4))
box_i = box_i[:, i, :] # 维度为: [rois_num, k, 4]
prob_i = raw_prob[:, i] # 维度为: [rois_num]
mask = prob_i > score_thresh
box_i = box_i[mask]
prob_i = prob_i[mask]
order = prob_i.argsort()[::-1]
# 按照score值从大到小进行排序
box_i = box_i[order]
box_i_after_nms, keep = non_maximum_suppression(box_i, nms_thresh)
box.append(box_i_after_nms)
label_i = (i - 1) * np.ones((len(keep),))
label.append(label_i)
score.append(prob_i[keep])
box = np.concatenate(box, axis=0).astype(np.float32)
label = np.concatenate(label, axis=0).astype(np.int32)
score = np.concatenate(score, axis=0).astype(np.float32)
return box, label, score
三、数据集部分
1、生成txt文件
写了两种生成txt文件的代码。
① 数据集给的是txt标注
第一种基于的前提是数据集给的是txt标注,那可以用下面的函数生成4个txt并生成对应的xml文件。
from lxml import etree as ET
import glob
import cv2
import random
from configs.config import classes_for_label, xml_root_dir, img_root_dir, txt_root_dir, pic_format
import numpy as np
from PIL import Image
def write_xml(filename, saveimg, typename, boxes, xmlpath):
"""
function description: 将txt的标注文件转为xml
:param filename: 图片名
:param saveimg: opencv读取图片张量
:param typename: 类名
:param boxes: 左上角和右下角坐标
:param xmlpath: 保存的xml文件名
"""
# 根节点
root = ET.Element("annotation")
# folder节点
folder_node = ET.SubElement(root, 'folder')
folder_node.text = 'kitti'
# filename节点
filename_node = ET.SubElement(root, 'filename')
filename_node.text = filename
# source节点
source_node = ET.SubElement(root, 'source')
database_node = ET.SubElement(source_node, 'database')
database_node.text = 'kitti Database'
annotation_node = ET.SubElement(source_node, 'annotation')
annotation_node.text = 'kitti'
image_node = ET.SubElement(source_node, 'image')
image_node.text = 'flickr'
flickrid_node = ET.SubElement(source_node, 'flickrid')
flickrid_node.text = '-1'
# owner节点
owner_node = ET.SubElement(root, 'owner')
flickrid_node = ET.SubElement(owner_node, 'flickrid')
flickrid_node.text = 'muke'
name_node = ET.SubElement(owner_node, 'name')
name_node.text = 'muke'
# size节点
size_node = ET.SubElement(root, 'size')
width_node = ET.SubElement(size_node, 'width')
width_node.text = str(saveimg.shape[1])
height_node = ET.SubElement(size_node, 'height')
height_node.text = str(saveimg.shape[0])
depth_node = ET.SubElement(size_node, 'depth')
depth_node.text = str(saveimg.shape[2])
# segmented节点(用于图像分割)
segmented_node = ET.SubElement(root, 'segmented')
segmented_node.text = '0'
# object节点(循环添加节点)
for i in range(len(typename)):
object_node = ET.SubElement(root, 'object')
name_node = ET.SubElement(object_node, 'name')
name_node.text = typename[i]
pose_node = ET.SubElement(object_node, 'pose')
pose_node.text = 'Unspecified'
# 是否截断
truncated_node = ET.SubElement(object_node, 'truncated')
truncated_node.text = '1'
difficult_node = ET.SubElement(object_node, 'difficult')
difficult_node.text = '0'
bndbox_node = ET.SubElement(object_node, 'bndbox')
xmin_node = ET.SubElement(bndbox_node, 'xmin')
xmin_node.text = str(boxes[i][0])
ymin_node = ET.SubElement(bndbox_node, 'ymin')
ymin_node.text = str(boxes[i][1])
xmax_node = ET.SubElement(bndbox_node, 'xmax')
xmax_node.text = str(boxes[i][2])
ymax_node = ET.SubElement(bndbox_node, 'ymax')
ymax_node.text = str(boxes[i][3])
tree = ET.ElementTree(root)
tree.write(xmlpath, pretty_print=True)
def split_dataset_byTXT():
"""
function description: 根据总训练集标注的txt文件将其数据集切分为训练集, 验证集以及测试集, 并且写入相应的xml作为标注
"""
trainval = open(txt_root_dir + 'trainval.txt', 'w')
train = open(txt_root_dir + 'train.txt', 'w')
val = open(txt_root_dir + 'val.txt', 'w')
test = open(txt_root_dir + 'train_test.txt', 'w')
list_anno_files = glob.glob(train_label_path + "*")
random.shuffle(list_anno_files)
index = 0
for anno_file in list_anno_files:
with open(anno_file) as file:
boxes = []
typename = []
anno_infos = file.readlines()
for anno_item in anno_infos:
anno_new_infos = anno_item.split(" ")
# 去掉杂项和不关心这俩类别
if anno_new_infos[0] == "Misc" or anno_new_infos[0] == "DontCare":
continue
else:
box = (int(float(anno_new_infos[4])), int(float(anno_new_infos[5])),
int(float(anno_new_infos[6])), int(float(anno_new_infos[7])))
boxes.append(box)
typename.append(anno_new_infos[0])
filename = anno_file.split("\\")[-1].replace(".txt", pic_format)
xmlpath = xml_root_dir + filename.replace(pic_format, ".xml")
imgpath = img_root_dir + 'training/' + filename
print(imgpath)
saveimg = cv2.imread(imgpath)
write_xml(filename, saveimg, typename, boxes, xmlpath)
index += 1
if index > len(list_anno_files) * 0.9:
test.write(filename.replace(pic_format, "\n"))
else:
trainval.write(filename.replace(pic_format, "\n"))
if index > len(list_anno_files) * 0.7:
val.write(filename.replace(pic_format, "\n"))
else:
train.write(filename.replace(pic_format, "\n"))
trainval.close()
train.close()
val.close()
test.close()
② 数据集的标注直接是xml文件
第二种基于的前提是数据集的标注直接是xml文件,那直接根据文件名生成txt文件就OK了。
def split_dataset_byXML():
"""
function description: 根据总训练集的XML标注文件将其切分为训练集, 验证集以及测试集
"""
trainval = open(txt_root_dir + 'trainval.txt', 'w')
train = open(txt_root_dir + 'train.txt', 'w')
val = open(txt_root_dir + 'val.txt', 'w')
train_test = open(txt_root_dir + 'train_test.txt', 'w')
list_anno_files = glob.glob(xml_root_dir + "*")
random.shuffle(list_anno_files)
index = 0
for anno_file in list_anno_files:
filename = anno_file.replace(".xml", pic_format)
index += 1
if index > len(list_anno_files) * 0.9:
train_test.write(filename.replace(pic_format, "\n"))
else:
trainval.write(filename.replace(pic_format, "\n"))
if index > len(list_anno_files) * 0.7:
val.write(filename.replace(pic_format, "\n"))
else:
train.write(filename.replace(pic_format, "\n"))
trainval.close()
train.close()
val.close()
train_test.close()
2、实现Dataset的类
因为考虑到真正的测试集是没有标注这么一说的,所以__getitem__函数返回的内容也应该不是一样的。对于测试集和训练集想要最大程度地复用代码,在所以在构造函数里面传了一个标记位,用来区分是train还是test。而且Faster-RCNN训练所需要图片的尺寸是有要求的,最小的边必须超过600px,否则在Roi pooling的时候会出现问题,但是预测不准确,所以我在代码里面还是用了reshape函数。
注意:对于训练集直接reshape那就大错特错了,你需要在缩放图片的同时等比例缩放标注框的位置!下面给的代码都实现了,都是直接将张量和标注拉到内存,所以占用的内存空间会很大。
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import os
from data.process_data import parse_xml, reshape
import numpy as np
from PIL import Image
from configs.config import pic_format
class ImageDataset(Dataset):
def __init__(self, xml_root_dir, img_root_dir, txt_root_dir, txt_file, isTest=False, transform=None):
"""
class description: 这个类已经将最小边缩放到600px了, 同时将训练集中标注的位置也等比例修改了
:param xml_root_dir: xml标注文件的根路径
:param img_root_dir: img图片的根路径
:param txt_root_dir: txt文件的根路径
:param txt_file: txt文件名
:param isTest: 标志是否是测试集
:param transform: 变换
"""
super(ImageDataset, self).__init__()
self.xml_root_dir = xml_root_dir
self.img_root_dir = img_root_dir
self.txt_root_dir = txt_root_dir
self.txt_file = txt_file
self.isTest = isTest
if transform == None:
self.transform = transforms.Compose([
# TODO BUG的根源... 为了适配vgg16的输入
# transforms.Resize((int(224), int(224))),
transforms.ToTensor(),
transforms.Normalize(
[0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
if self.isTest == False:
boxes, labels, images = self.load_txt(self.txt_file)
self.boxes = boxes
self.labels = labels
self.images = images
elif self.isTest == True:
self.images = self.load_txt(self.txt_file)
id_list_files = os.path.join(txt_root_dir, txt_file)
self.ids = [id_.strip() for id_ in open(id_list_files)]
def load_txt(self, filename):
"""
function description: 加载txt文件中的信息并放到numpy数组中, numpy可以直接在list中再次添加可变list
:param filename: txt文件名
"""
print('-------------the file name is ', filename)
boxes = []
labels = []
images = []
print(os.path.join(self.txt_root_dir, filename))
with open(os.path.join(self.txt_root_dir, filename), mode='r') as f:
lines = f.readlines()
# index = 0
for line in lines:
line = line.strip()
if self.isTest == False:
box, label, image = self.load_xml(line + ".xml")
boxes.append(box)
labels.append(label)
# index += 1
elif self.isTest == True:
image = (line + pic_format)
# image = line.replace("\n", ".jpg")
images.append(image)
if self.isTest == False:
print('the length of boxes is ', len(boxes))
print('the length of labels is ', len(labels))
print('the length of images is ', len(images))
return boxes, labels, images
elif self.isTest == True:
return images
def load_xml(self, filename):
"""
function description: 加载xml文件中需要的属性并将最小边缩放为600
:param filename: xml文件名
"""
path = os.path.join(self.xml_root_dir, filename)
if not os.path.exists(path):
return
boxes, labels = parse_xml(path)
img_name = filename.replace(".xml", pic_format)
images, boxes = reshape(Image.open(self.img_root_dir + img_name), boxes)
return np.stack(boxes).astype(np.float32), \
np.stack(labels).astype(np.int32), \
images
def __len__(self):
return len(self.images)
def __getitem__(self, index):
if self.isTest == False:
id = self.ids[index]
box, label, image = self.load_xml('{0}.xml'.format(id))
img_tensor = self.transform(image)
# [channel, height, width] -> [channel, width, height]
img_tensor = img_tensor.permute(0, 2, 1)
return {
"img_name": id + pic_format,
"img_tensor": img_tensor,
"img_classes": label,
"img_gt_boxes": box
}
elif self.isTest == True:
img = Image.open(self.img_root_dir + self.images[index])
img_tensor = self.transform(img)
img_tensor = img_tensor.permute(0, 2, 1)
return {
"img_name": self.images[index],
"img_tensor": img_tensor,
}
四、测试部分
下图是我kitti数据集在我代码上面跑了一个epoch之后进行预测的结果。


效果还是不错的。