USYD悉尼大学DATA1002 详细作业解析Module3
Module 3: Text processing and data cleaning
- 前言
- Question 1: Strip it!
- Question 2: Filter
- Question 3: Vowel words
- Question 4: Words with all vowels
- Question 5: Stem it!
- 总结
前言
我尽可能做详细,每个步骤讲清楚。答案不止一种,有大神可以留言。其他章节在我的主页可以查看。
第三章我们将集中讨论文本处理领域中的两个重要概念:转换和过滤。这两个任务通常应用于数据清理和数据挖掘,因此对我们而言,重要的是要理解这些概念背后的基本思想。
文中空行和#注释不算讲解的代码行数,查代码行数的时候可以直接跳过。
Question 1: Strip it!
For text processing and analysis, it is often irritating to have the carriage return (\n) character at the end of each line. Luckily, there is a way to remove this character!
Your task is to read in the file pride_and_prejudice.txt and transform each word such that the carriage return character is removed. Then print out the transformed word.
When you run your program, this is what the first few lines of the output should look like:
By removing the carriage return character, there should be no empty lines between the words.
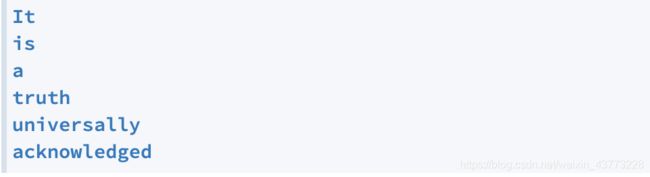
要求 :把给的文本 pride_and_prejudice.txt(文本在grok里)每行打印出来。
#答案
for word in open('pride_and_prejudice.txt'):
word1=word.strip()
print(word1)
line1 : 遍历循环文件,将数据文件中的每一行分配给循环变量word 。
line2: word1一个新的变量,.strip()方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
链接: .strip()函数详细用法
line3: 打印新的变量
Question 2: Filter
Statistics show that “e” is the most common letter in the English language, with a frequency of about 11.1%, according to a study by Oxford Dictionaries. And in fact, about 44% of the words in our novel contain this letter.
Your task is to filter out words that contain the letter “e”. Using the supplied text file called pride_and_prejudice.txt, write a program that prints out every word which does not contain the letter “e”, or we could say instead: every word which has an “e” in it is not printed.
For the provided file, these are the words that your program should print out:
Strip the carriage return character from each word such that there are no blank lines between the words.
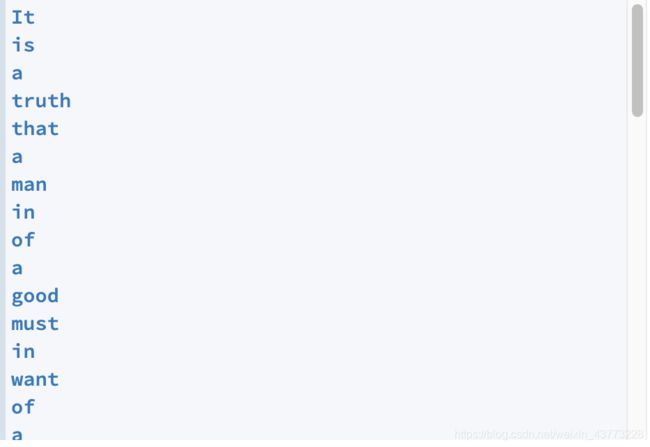
要求:给的文件pride_and_prejudice.txt 让把所有带e的单词去掉,然后从每个单词中删除回车符,以使单词之间没有空行。
#我的方法:
for word in open("pride_and_prejudice.txt"):
letter="e"
if not letter in word:
word1=word.strip()
print(word1)
#老师的方法:
for word in open("pride_and_prejudice.txt"):
if "e" not in word:
print(word.rstrip("\n"))
我的写复杂了仅供参考,用老师的方法
line1 : 遍历循环文件,将数据文件中的每一行分配给循环变量word。
line2: 条件判断e是不是在这个循环变量里。
line3: 打印注意代码缩进。.rstrip()删除 string 字符串末尾的指定字符(默认为空格),"\n"就是一个换行符,每次循环换一行。
链接: rstrip()函数使用方法
Question 3: Vowel words
We know that “e” is the most common letter in our alphabet, yet this letter is rarely found at the beginning of a word.
Your task is to filter the provided text file such that every word which does not start with the letter e is removed. For the words that do start with “e”, print out the length.
The output of your program should look like this:

要求: 打开文本文件pride_and_prejudice.txt过滤出e开头的字母,然后打印出来并且求出单词的长度。
#答案
for word in open('pride_and_prejudice.txt'):
if word.startswith('e'):
length = len(word.rstrip("\n"))
print(length)
line1: 遍历循环文件,将数据文件中的每一行分配给循环变量 word 。
line2: 条件判断startswith()是否单词以e开头。
line3: 求长度函数 len()方法返回对象(字符、列表、元组等)长度或项目个数。rstrip()和"\n"上面有详细讲解。
链接: len()函数的使用方法
line4: 打印新变量,注意代码块缩进。
Question 4: Words with all vowels
Compound filtering allows us to filter using many conditions at the same time. Your task is to apply a compound filter in order to find the words that contain all five vowels.
In English, the five vowels are the letters a, e, i, o, and u.
You can solve this problem either using nested if-statements or by using the logical operator and. After filtering, print out the words that remain.
For the supplied pride_and_prejudice.txt file, the output of your program should look like this:
Before you print the words, remove the carriage return character so that your program doesn’t print blank lines.

要求: 打开文本 pride_and_prejudice.txt然后过滤出带有元音’a’ , ‘e’ , ‘i’ , ‘o’ ,‘u’ 的所有单词,不分位置只要单词有这些元音就打印出来,然后不要忘了在打印单词之前,请删除回车符,以使程序不会打印空行。
#方法1
for word in open("pride_and_prejudice.txt"):
if 'a' in word:
if 'e' in word:
if 'i' in word:
if 'o' in word:
if 'u' in word:
print(word.rstrip("\n"))
#方法2
for word in open('pride_and_prejudice.txt'):
if 'a' in word and 'e' in word \
and 'i' in word and 'o' in word \
and 'u' in word:
print(word.rstrip("\n"))
方法1
line1: 遍历循环文件,将数据文件中的每一行分配给循环变量word。
line2–line6 : if条件判断每一个判断项目是不是在这个文本里,如果在就直接进行最后一行打印输出,如果不在就进行下一轮条件判断,直到所有的判断进行完毕为止。
line7: 打印输出,注意代码的缩进。
方法2
line1: 遍历循环打开文本文件。
line2–line4: if条件判断一次,每一个判断项目是否在word循环里,每一项用and保留字连接,\ 反斜杠表示跨行输入。
line5: 打印输出,注意代码缩进。
Question 5: Stem it!
In the context of information extraction from text-based data, it is crucial to be able to identify words that belong to the same semantic group. For example, the following words,
organise - organising - organisation - organiser
are all derived from the word organise. This is commonly referred to as “root” or “stem” of the word. The process of reducing words to their stem is called Stemming and is widely used in e.g. natural language processing or information retrieval. The Google Search engine also makes use of stemming to increase the range of the search.
Your task is to write a program that uses a simple suffix-stripping algorithm as described below to stem each word in the provided pride_and_prejudice.txt file.
Your program should remove the following suffixes:
- ing
- ed
- ly
Ignore the words that don’t end up in either of these suffixes. For the ones that do, remove the suffix and print out the new word.
this is what the output of your program should look like:
Remember \n!
For this exercise it is important to keep in mind that every line you read from a file ends with the carriage return (\n) character. Make sure you either include “\n” in your condition or you strip it off right away. Your program should not print any empty lines between the words.

要求: 打开文本文件 provided pride_and_prejudice.txt,过滤出以ing,ed和ly结尾的单词,然后将ing,ed和ly后缀去掉,最后打印输出单词。
#方法1
for word in open('pride_and_prejudice.txt'):
word_s = word.rstrip('\n')
if word_s.endswith('ing'):
print(word_s.rstrip('ing'))
elif word_s.endswith('ed'):
print(word_s.rstrip('ed'))
elif word_s.endswith('ly'):
print(word_s.rstrip('ly'))
#方法2
for word in open('pride_and_prejudice.txt'):
word_s = word.rstrip('\n')
if word_s.endswith('ing'):
print(word_s[:-3])
elif word_s.endswith('ed'):
print(word_s[:-2])
elif word_s.endswith('ly'):
print(word_s[:-2])
主要讲解方法1,方法2用了索引切片。在后面的章节里我会细讲,现在可以先看看
line1: 遍历循环文件,将数据文件中的每一行分配给循环变量word。
line2: 获取新的变量word_s,用函数.rstrip(’\n’) 获取新的一行。
line3–line8: 多层条件判断语句,if语句endswith()判断单词是否以ing结尾,如果为TRUE打印输出,并且用.rstrip()分离后缀。第二层用elif判断,最后一层用else判断。
链接: if-elif-else的用法
总结
以上就是今天要讲的内容,本文仅仅简单介绍了过滤文本的使用,而后面更多的知识提供了大量能使我们快速便捷地处理数据的函数和方法。
有错误在所难免,但我会尽力去做好。希望各位大佬能提出意见,找出不足,我再去改进。