DBAF-Net:多分辨率遥感图像的双分支注意力融合分割网络
目录
- 论文下载地址
- 论文作者
- 模型讲解
-
- [背景介绍]
- [模型解读]
-
-
- [ACO-SS:自适应中心偏移采样策略]
-
-
- [检测纹理,确定其有效区域]
- [根据不同比例的纹理,确定每个像素的邻域范围]
- [割成三种固定大小切片]
-
- [DBAF-Net:双分支注意力融合网络]
-
-
- [SA空间注意力模块、CA通道注意力模块]
- [双分支注意力融合深层网络]
-
-
- [结果分析]
-
-
- [数据集]
- [参数设置]
- [消融实验]
-
论文下载地址
[论文地址]
论文作者
模型讲解
[背景介绍]
如今,随着地球空间信息技术的发展和先进装备技术的支持,可以同时获取同一场景中不同分辨率的图像。自这一目标无法实现由单一传感器同时获取,而是当前的星载被动地球观测系统可以共同获得同一场景的两幅图像,一个高空间分辨率的全色(PAN)图像但包含较少的光谱信息,一个低空间分辨率的多光谱(MS)图像,但包含更多的光谱信息。与原始的单一分辨率图像相比,这些不同分辨率的多分辨率图像的融合,能够同时获得更高的空间和光谱信息。MS图像有助于土地植被的识别,而PAN图像对于准确描述图像中物体的形状有很大贡献。因此,PAN和MS图像之间的内在互补性为多分辨率图像分割任务提供了重要的潜力。
[模型解读]
作者设计了一种用于多分辨率分类的双分支注意融合深度网络(DBAF-Net)。其目的是将特征级融合和分割集成到端到端网络中。在建立训练样本库的过程中,传统的切片大小是固定、以像素为中心的采样策略不同,作者提出了一种自适应中心偏移采样策略(ACO-SS),该策略允许每个切片通过寻找待分类像素的纹理结构自适应地确定其邻域范围。而邻域范围与该像素不对称,希望捕捉到更有利于其分割的邻域信息。在网络结构上,以ACO-SS捕获的切片为基础,对PAN图像设计了空间注意模块(SA-module),对MS图像设计了通道注意模块(CA-module),分别突出了PAN图像的空间分辨率优势和MS数据的多通道优势。
[ACO-SS:自适应中心偏移采样策略]
训练样本集的质量是非常重要的,它直接影响网络模型的性能,因此,如何获得有效的样本是首先要解决的问题。在遥感像像素级分类分类任务中,训练样本一般是以像素为中心的图像切片。切片为中心像素提供邻域信息来确定该中心像素的类别。与自然图像不同,大场景的遥感图像通常有许多不同尺度,因此将切片设置为固定大小来提取特征是不合理的。
作者提出了一种自适应中心-偏移采样策略(ACO-SS),可以根据要分类像素的纹理结构自适应地确定每个切片的范围。该策略将原始切片像素中心(即要分类的像素)移动到纹理结构上,以形成具有均匀性的相邻像素,从而为该像素提供更多正反馈,从而为分类器提供了更多的正反馈相邻像素信息。
[检测纹理,确定其有效区域]
这里作者选择纹理结构主要是因为容易获得和稳定。最稳定的纹理结构可以通过高斯空间的归一化拉普拉斯算子( s − L o G : σ 2 ▽ 2 G s-LoG: \sigma^2\triangledown^2G s−LoG:σ2▽2G)检测。但在本文中,由于 D o G DoG DoG是 s − L o G s-LoG s−LoG( D o G ≈ ( k − 1 ) σ 2 ▽ 2 G DoG\approx(k-1)\sigma^2\triangledown^2G DoG≈(k−1)σ2▽2G)的近似,易于计算,所以作者使用高斯( D o G DoG DoG)尺度空间来捕获纹理结构。 D o G DoG DoG函数可以表示为:
D o G = G ( x , y , σ 1 ) − G ( x , y , σ 2 ) = 1 2 π σ 1 2 e − x 2 + y 2 2 σ 1 2 − 1 2 π σ 2 2 e − x 2 + y 2 2 σ 2 2 \begin{aligned}DoG &=G\left(x, y, \sigma_{1}\right)-G\left(x, y, \sigma_{2}\right) \\ &=\frac{1}{2 \pi \sigma_{1}^{2}} e^{-\frac{x^{2}+y^{2}}{2 \sigma_{1}^{2}}}-\frac{1}{2 \pi \sigma_{2}^{2}} e^{-\frac{x^{2}+y^{2}}{2 \sigma_{2}^{2}}} \end{aligned} DoG=G(x,y,σ1)−G(x,y,σ2)=2πσ121e−2σ12x2+y2−2πσ221e−2σ22x2+y2
其中 σ 1 \sigma_1 σ1是当前尺度空间的尺度, σ 2 = k σ 1 \sigma_2=k\sigma_1 σ2=kσ1,表示领域尺度空间的尺度。
D o G DoG DoG与 s − L o G s-LoG s−LoG的横截面如下图左侧所示。可以看出,通过计算两个最大点之间的欧式距离,可以捕获该漏斗形纹理结构的大小(表示为 D E D_E DE)。因此,对 D o G DoG DoG求导得到 D E D_E DE的表示:
{ D E = 2 x 2 + y 2 ∂ D o G ∂ D E ≜ 0 → D E = 32 k 2 σ 1 2 ln k k 2 − 1 \left\{\begin{array}{l} D_{E}=2 \sqrt{x^{2}+y^{2}} \\ \frac{\partial DoG}{\partial D_{E}} \triangleq 0 \\ \rightarrow D_{E}=\sqrt{\frac{32 k^{2} \sigma_{1}^{2} \ln k}{k^{2}-1}} \end{array}\right. ⎩⎪⎨⎪⎧DE=2x2+y2∂DE∂DoG≜0→DE=k2−132k2σ12lnk
在本文中,作者设置 k = 2 1 3 k=2^{\frac{1}{3}} k=231, D E = 9.5 σ 1 D_E=9.5\sigma_1 DE=9.5σ1。可以通过检测其中心极点来捕获 D o G DoG DoG尺度空间中的纹理结构,因为它可以提供有关位置和当前尺度 σ 1 \sigma_1 σ1的信息来确定相应的 D E D_E DE。
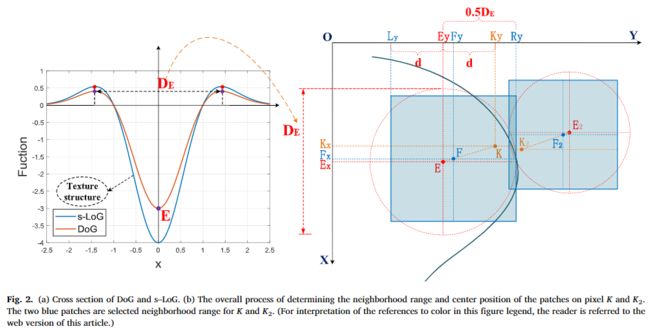
[根据不同比例的纹理,确定每个像素的邻域范围]
对于某个像素,其周围可能有多个候选纹理,所选纹理结构在空间距离上应该最接近该像素,并确保与该像素处于同一区域。因此,作者用泰森多边形法分区所有极值点,每个泰森多边形中只有一个极值点。任何一个泰森多边形的最近纹理为改区域像素的纹理。
确定邻域范围和中心位置的整体过程如上图右侧所示。假设 K K K和 K 2 K_2 K2为欧氏距离非常近但属于不同类别的两个像素点, E E E和 E 2 E_2 E2分别为对应纹理的中心极值点。通过空间关系的转换,可以计算出新的中心位置 F F F和 F 2 F_2 F2,以及对应的邻域范围(两个具有自适应邻域范围的蓝色斑块)。与以像素为中心的采样策略相比,采用该策略的两个蓝色切片没有过多地重复邻域信息。
以点K为例,空间关系的具体计算如下:
s.t. { ∣ K y − E y ∣ ≥ ∣ K x − E x ∣ ; K ∈ ⊙ E ; F ∈ E K ∣ E y − L y ∣ ≜ ∣ K y − E y ∣ ≜ d ∣ R y − E y ∣ = 0.5 D E ∣ F y − L y ∣ = ∣ R y − F y ∣ = ∣ R y − L y ∣ 2 \text { s.t. }\left\{\begin{array}{l} \left|K_{y}-E_{y}\right| \geq\left|K_{x}-E_{x}\right| ; K \in \odot E ; F \in E K \\ \left|E_{y}-L_{y}\right| \triangleq\left|K_{y}-E_{y}\right| \triangleq d \\ \left|R_{y}-E_{y}\right|=0.5 D_{E} \\ \left|F_{y}-L_{y}\right|=\left|R_{y}-F_{y}\right|=\frac{\left|R_{y}-L_{y}\right|}{2} \end{array}\right. s.t. ⎩⎪⎪⎨⎪⎪⎧∣Ky−Ey∣≥∣Kx−Ex∣;K∈⊙E;F∈EK∣Ey−Ly∣≜∣Ky−Ey∣≜d∣Ry−Ey∣=0.5DE∣Fy−Ly∣=∣Ry−Fy∣=2∣Ry−Ly∣ → ∣ R y − L y ∣ = ∣ R y − E y ∣ + ∣ E y − L y ∣ = 0.5 D E + d ∣ F y − E y ∣ = ∣ F y − L y ∣ − ∣ E y − L y ∣ = 0.5 D E − d 2 → F y = 3 E y − K y + K y − E y ∣ K y − E y ∣ 0.5 D E 2 → F x = K x − E x K y − E y ( F y − E y ) + E x \begin{array}{c} \rightarrow\left|R_{y}-L_{y}\right|=\left|R_{y}-E_{y}\right|+\left|E_{y}-L_{y}\right|=0.5 D_{E}+d \\ \left|F_{y}-E_{y}\right|=\left|F_{y}-L_{y}\right|-\left|E_{y}-L_{y}\right|=\frac{0.5 D_{E}-d}{2} \\ \rightarrow F_{y}=\frac{3 E_{y}-K_{y}+\frac{K_{y}-E_{y}}{\left|K_{y}-E_{y}\right|} 0.5 D_{E}}{2} \\ \rightarrow F_{x}=\frac{K_{x}-E_{x}}{K_{y}-E_{y}}\left(F_{y}-E_{y}\right)+E_{x} \end{array} →∣Ry−Ly∣=∣Ry−Ey∣+∣Ey−Ly∣=0.5DE+d∣Fy−Ey∣=∣Fy−Ly∣−∣Ey−Ly∣=20.5DE−d→Fy=23Ey−Ky+∣Ky−Ey∣Ky−Ey0.5DE→Fx=Ky−EyKx−Ex(Fy−Ey)+Ex
其中 L y L_y Ly和 R y R_y Ry是所选切片的边界,所以切片的大小 S q = ∣ R y − L y ∣ S_q=| R_y-L_y| Sq=∣Ry−Ly∣。这里,如果 ∣ K y − E y ∣ < ∣ K x − E x ∣ |K_y-E_y|<|K_x- E_x| ∣Ky−Ey∣<∣Kx−Ex∣,则交换 x x x和 y y y,如果 K ∉ ⊙ E K\notin \odot E K∈/⊙E,则认为 K K K周围没有明显的纹理结构,因此遵循传统的以像素为中心的采样策略,为 K K K设置一个固定的邻域大小 S f i x S_{fix} Sfix。从上式可以看出,确定的像素 K K K,切片的大小 S q S_q Sq取决于其纹理结构的规模( D E D_E DE)和极值像素点到纹理结构的欧氏距离( d d d),这邻域信息可以根据不同大小的对象自适应捕获的范围。此外,在保留其部分独特的邻域信息的同时,作者将原始切片中心偏移到纹理结构的中心,以捕获更多与原始中心像素同质的邻域信息,有利于特征提取。
[割成三种固定大小切片]
在进入网络之前,为了有效地训练网络,我们最终将所有的切片切割成三个固定大小,为:
S = { S 1 , S p ≤ S 1 S f i x , S 1 < S p ≤ S f i x S 3 , S 2 < S p ≤ S 3 S ~ 3 , S p > S 3 S=\left\{\begin{array}{ll} S_{1}, & S_{p} \leq S_{1} \\ S_{f i x}, & S_{1}
其中 S x S_x Sx, S f i x S_{fix} Sfix与 S 3 S_3 S3三个阈值为常数, S ~ 3 \widetilde S_{3} S 3意味着对 S p S_p Sp的切片resize为 S 3 S_3 S3,而不是直接设置为 S 3 S_3 S3,以确保原始邻域信息的完整性,然后这些切片用作后续网络的输入。
[DBAF-Net:双分支注意力融合网络]
[SA空间注意力模块、CA通道注意力模块]
PAN图像的空间分辨率高于MS图像,因此作者希望设计一个基于空间的注意模块,为PAN图像的特征图添加权重。MS图像有更多的通道信息,作者设计一个通道注意模块。
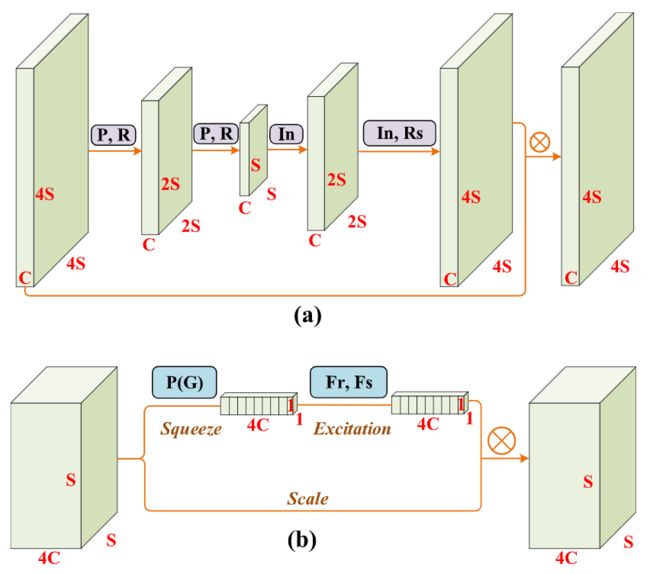
上图中,两种不同类型的注意机制模块。其中,P为最大池化操作,P(G)为全局平均池化操作,R为卷积、批处理归一化(BN)、ReLU等多个非线性结构的组合。除最后的激活函数为Sigmoid外,其他都是ReLU。 F r F_r Fr表示降维的全连接层FC与ReLU, F s F_s Fs表示增维全连接层与Sigmoid。⊗是逐元素相乘。(a)自下而上自上而下的注意模块(b)SE注意模块。
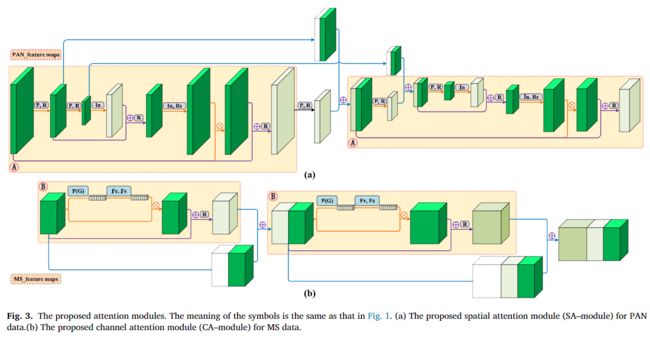
[①SA空间注意力]
在一个注意力模块中,每次上采样后的特征图都与下采样过程中的特征图进行逐像素相加,保持原有的特征,减弱过度注意力的情况发生,同时可以防止梯度爆炸。更好的反向传播。
假设 x t x_t xt为第 t t t层的输入, y T y_T yT为第 T T T层的输出 ( T > t ) (T>t) (T>t)。 F i ( ⋅ ) F_i(\sdot) Fi(⋅)是第 i i i层的特征函数,包含池化、卷积、BN、ReLU等操作。 w i w_i wi表示第 i i i层的权重。因此,此过程可以表示为:
y T = F T ( ( x t + ∏ i = t T − 1 F i ( x i , w i ) ) , w T ) y_T=F_T((x_t+\prod _{i=t}^{T-1}F_i(x_i,w_i)),w_T) yT=FT((xt+i=t∏T−1Fi(xi,wi)),wT)
在反向传播过程中,按照以下步骤计算从第 T T T层到第 t t t层的梯度误差 E E E:
∂ E ∂ x t = ∂ E ∂ y T ⋅ ∂ y T ∂ x t = ∂ E ∂ y T ⋅ ∂ F ∂ x t ( 1 + ∂ ∂ x t ∏ i = t T − 1 F ( x i , w i ) ) \frac{\partial E}{\partial x_{t}}=\frac{\partial E}{\partial y_{T}} \cdot \frac{\partial y_{T}}{\partial x_{t}}=\frac{\partial E}{\partial y_{T}} \cdot \frac{\partial F}{\partial x_{t}}\left(1+\frac{\partial}{\partial x_{t}} \prod_{i=t}^{T-1} F\left(x_{i}, w_{i}\right)\right) ∂xt∂E=∂yT∂E⋅∂xt∂yT=∂yT∂E⋅∂xt∂F(1+∂xt∂i=t∏T−1F(xi,wi))
[②CA通道注意力]
与上面的SA同理,CA主要在于通道的注意力,每次都会将获得的特征图与输入特征图及进行通道叠加,使得最初的特征保留。
y T = f s ( x t ) + ∏ i = t T − 1 F i ( x i , w i ) y_T=f_s(x_t)+\prod _{i=t}^{T-1}F_i(x_i,w_i) yT=fs(xt)+i=t∏T−1Fi(xi,wi)
个人认为这里作者的表达式比较混乱,但是流程图是十分清楚的,搞懂流程图就基本可以了。
[双分支注意力融合深层网络]
[①预处理]
PAN图像与MS图像的尺寸之比为4:1,输入网络之前都会经过一个R的操作,包括卷积、BN、ReLU。
[②基于注意力的特征提取]
如下图所示,我们使用三个SA模块在PAN分支上形成堆叠的SA网络,使用三个CA模块在MS分支上形成堆叠的CA网络。在这个过程中,两个分支的权重不共享。所提取的特征进一步增强了各图像数据类型的原始信息优势。注意力的结果主要抑制图像背景等不重要的信息,随着网络的深化,逐渐增强感兴趣的重要信息。
[③特征融合与分类]
为了有效地融合两个分支的特征,作者将按照以下操作进行第三模块的输出。假设第三模块的输入PAN图像为 A i , c a A^a_{i,c} Ai,ca,输出的注意力图像为相同大小的 α i , c \alpha_{i,c} αi,c,对准的MS图像输入为 B i , c b B_{i,c}^b Bi,cb,对应相同大小的注意力输出为 β i , c \beta_{i,c} βi,c, c c c表示通道 i i i表示空间位置。融合后的特征为 Y i , c f Y_{i,c}^f Yi,cf可以表示为:
Y i , c f = f s ( F ( B i , c b ) ) + F ( N ( α i , c ⋅ A i , c a + F ( β i , c ⋅ B i , c b ) ) + A i , c a ) Y_{i,c}^f=f_s(F(B_{i,c}^b))+F(N(\alpha_{i,c}\sdot A_{i,c}^a+F(\beta_{i,c}\sdot B_{i,c}^b))+A_{i,c}^a) Yi,cf=fs(F(Bi,cb))+F(N(αi,c⋅Ai,ca+F(βi,c⋅Bi,cb))+Ai,ca)
其中 N ( ⋅ ) N(·) N(⋅)表示归一化函数, F ( ⋅ ) F(·) F(⋅)和 f s ( ⋅ ) f_s(·) fs(⋅)表示与上述公式相同的含义。
由于ACO-SS的输入切片有三种不同的大小,作者在全连接层之前插入一个空间金字塔池化层(SPP),从而得到固定维数的向量。本文利用1x1、2x2、4x4池化建立了三层的金字塔池化。因此,图4中带有 S × S × 4 C S\times S\times 4C S×S×4C的特征应转化为 ( 1 × 1 × 4 C + 2 × 2 × 4 C + 4 × 4 × 4 C ) (1\times 1\times 4C+2\times 2\times 4C+4\times 4\times 4C) (1×1×4C+2×2×4C+4×4×4C)维向量。将所有特征串联并通过几个完全连通的层后,最终估计出这对切片的分类概率。本文采用交叉熵误差作为最终损失函数,定义如下:
E = − 1 n b ∑ i = 1 n b [ y i log ( y ^ i ) + ( 1 − y i ) log ( 1 − y ^ i ) ] E=-\frac{1}{n_{b}} \sum_{i=1}^{n_{b}}\left[y_{i} \log \left(\hat{y}_{i}\right)+\left(1-y_{i}\right) \log \left(1-\hat{y}_{i}\right)\right] E=−nb1i=1∑nb[yilog(y^i)+(1−yi)log(1−y^i)]
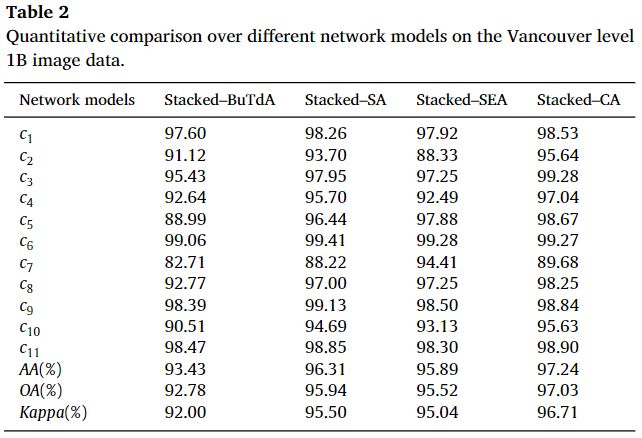
[结果分析]
[数据集]
在本节中,作者使用四个数据集来验证所提方法的鲁棒性和有效性。前两个数据集由2016年IEEE GRSS数据融合竞赛官方提供。数据集分别于2015年3月31日和2015年5月30日从加拿大温哥华的DEIMOS-2卫星采集。包括1 m分辨率的平移图像和4 m分辨率的MS图像(RGB,NIR),如下图所示,其中数据是经过校准和放射测量校正的。MS图像为3249x 2928x4像素,PAN图像为12996 x 11712像素。数据分为11类,包括植被、四类建筑、船只、道路、港口、桥梁、树木和水。

如下图所示,其中数据是经过人工校正后再重新采样的产品,并经过校准和辐射测量校正。MS图像包括1311 x873x4像素,而PAN图像包括5244 x3492像素。数据分为8类,包括植被、三种建筑、船、路、树和水域。

接下来的两组数据来自2008年5月30日在中国西安的Ouickbird卫星。每个数据集包括0.61 m分辨率的PAN图像和2.44 m分辨率的MS图像(RGB和近红外),如下图所示为西安市近郊区域,覆盖西安市西南角。PAN图像由6600 x 6200像素组成,MS图像由1650x 1550x 4像素组成。将场景划分为8类,包括两种植被、四种建筑区域、道路和土地。
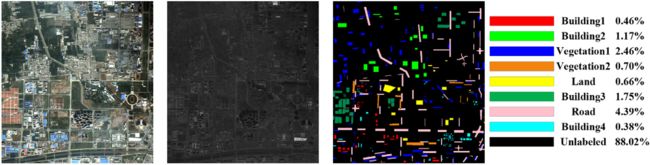
如下图所示为西安市区,包括西安东部。PAN图像为3200 x 3320像素,MS图像为800 x 830 x 4像素。该场景被划分为6类,分别是建筑、道路、树木、土壤、平地、水和阴影。平地代表除土壤以外的所有土地。对于温哥华和西安的数据集,请注意实际上有四个相对独立的图像数据集,只有两个地方可以捕捉图像。因此,实验中的训练样本和测试样本属于同一图像数据集。不同的数据集不会相互影响。

[参数设置]

[消融实验]