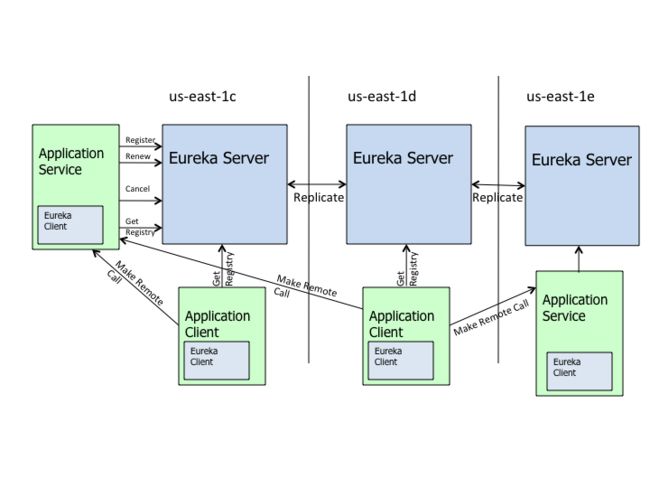
在 SpringCloud 的众多组件中,Eureka 功能的重要性不言而喻,也许断路器可以不需要,配置中心也可以不需要,服务网关也可以不需要, 但 Eureka 不可或缺。所以,重点在于 Eureka。上图有 3 个角色:Serve,Client,Service(Provider)。这些角色的任务都是不同的,我们将一个一个的分析关键源码,对疑点进行探究。
0. 本文的关注点
Client 功能:
- 可以注册到 EurekaServer
- 可以从 EurekaServer 获取列表
- 可以根据实例列表中负载均衡调用服务
1. 如何注册到 EurekaServer
我们在使用 Client 的时候,需要使用 @EnableDiscoveryClient 表示自己是一个 Client ,也就是说,这个注解一定有很大的作用,我们通过追踪该注解,会看到注解上的注释:
Annotation to enable a DiscoveryClient implementation.
可以知道,这个注解和 DiscoveryClient 绑定了。
进入这个类查看。该类果然有一个 register 方法。关键代码如下:
/**
* Register with the eureka service by making the appropriate REST call.
*/
boolean register() throws Throwable {
EurekaHttpResponse httpResponse = eurekaTransport.registrationClient.register(instanceInfo);
return httpResponse.getStatusCode() == 204;
}
注释说道:通过适当的REST调用来注册eureka服务。
这个 registrationClient 有很多实现,默认的实现是 SessionedEurekaHttpClient。当返回 204 的时候,表示注册成功。
同时,这个register方法也是维持心跳的方法。通过定时任务默认 30 秒调用一次。
2. 如何从 EurekaServer 获取列表
同样,在 DiscoveryClient 类中,我们发现有一个 getApplications 方法,该方法代码如下:
@Override
public Applications getApplications() {
return localRegionApps.get();
}
而这个 localRegionApps 从哪里获取数据呢?我们使用 IDEA 发现该变量有几个地方可以 set 数据,其中关键方法 getAndStoreFullRegistry, 该方法被 2 个地方使用 :

一个是更新,一个是从注册中心获取,该方法主要逻辑为:
private void getAndStoreFullRegistry() throws Throwable {
Applications apps = null;
EurekaHttpResponse httpResponse = clientConfig.getRegistryRefreshSingleVipAddress() == null
? eurekaTransport.queryClient.getApplications(remoteRegionsRef.get())
: eurekaTransport.queryClient.getVip(clientConfig.getRegistryRefreshSingleVipAddress(), remoteRegionsRef.get());
if (httpResponse.getStatusCode() == Status.OK.getStatusCode()) {
apps = httpResponse.getEntity();
}
if (fetchRegistryGeneration.compareAndSet(currentUpdateGeneration, currentUpdateGeneration + 1)) {
localRegionApps.set(this.filterAndShuffle(apps));
}
}
使用 HTTP 请求从EurekaServer 获取数据,其中最重要的数据就是 Applications,然后,使用 CAS 更新版本,将数据进行打乱(防止使用相同的实例接受启动过程中的流量),最后放进 Applications 中。
同时,使用 CacheRefreshThread 每 30 秒(默认)更新一次。
3. 如何根据实例列表中负载均衡 Call 提供者
当我们调用一个被 @FeignClient 注解标识的远程方法时,和普通的 RPC 一样,SpringCloud 也是使用的 JDK 的动态代理,这个动态代理的的拦截类则是 HystrixInvocationHandler, 核心方法 invoke 代码如下:
HystrixInvocationHandler.this.dispatch.get(method).invoke(args);
SpringCloud 通过 Future 的 get 方法阻塞等待结果。可以看到,SpringCloud 默认是有断路器的。是否开启根据 feign.hystrix.enable 属性决定是否开启。
这行代码最后调用的是 SynchronousMethodHandler 的 invoke 方法,代码如下:
public Object invoke(Object[] argv) throws Throwable {
RequestTemplate template = buildTemplateFromArgs.create(argv);
Retryer retryer = this.retryer.clone();
while (true) {
try {
return executeAndDecode(template);
} catch (RetryableException e) {
retryer.continueOrPropagate(e);
if (logLevel != Logger.Level.NONE) {
logger.logRetry(metadata.configKey(), logLevel);
}
continue;
}
}
}
该方法会进行重试——如果重试失败的话。可以看得出来, executeAndDecode 方法就是真正的 RPC 调用。
那么,SpringCloud 是如何进行负载均衡选择对应的实例的呢?
在上面的executeAndDecode 方法中,会调用 LoadBalancerFeignClient 的 execute 方法。最终会调用 ZoneAwareLoadBalancer 负载均衡器的 chooseServer 方法, 该方法内部代理了一个 IRule 类型的的负载均衡策略。而默认的策略则是轮询,看看这个 choose 方法的实现:
/**
* Get a server by calling {@link AbstractServerPredicate#chooseRandomlyAfterFiltering(java.util.List, Object)}.
* The performance for this method is O(n) where n is number of servers to be filtered.
*/
@Override
public Server choose(Object key) {
ILoadBalancer lb = getLoadBalancer();
Optional server = getPredicate().chooseRoundRobinAfterFiltering(lb.getAllServers(), key);
if (server.isPresent()) {
return server.get();
} else {
return null;
}
}
/**
* Choose a server in a round robin fashion after the predicate filters a given list of servers and load balancer key.
*/
public Optional chooseRoundRobinAfterFiltering(List servers, Object loadBalancerKey) {
List eligible = getEligibleServers(servers, loadBalancerKey);
if (eligible.size() == 0) {
return Optional.absent();
}
return Optional.of(eligible.get(nextIndex.getAndIncrement() % eligible.size()));
}
上面的两个方法就是 SpringCloud 负载均衡的策略了,从代码中可以看到,他使用了一个 nextIndex 变量取余实例的数量,得到一个 Service。
在 AbstractLoadBalancerAwareClient 的 executeWithLoadBalancer 方法中得到轮询到的 Server 后,执行 FeignLoadBalancer的 executer 方法。
最后,使用 feign 包下的 Client接口的默认实现类 Default 执行 convertResponse方法,使用 Java BIO 进行请求并返回数据。
4. 总结
通过今天的代码分析,我们知道了几点:
Client 如何注册,当启动的时候,会调用
DiscoveryClient的register方法进行注册,同时,还有一个 30 秒间隔的定时任务也可能(当心跳返回 404)会调用这个方法,用于服务心跳。Client 如何获取服务列表,Client 也是通过
DiscoveryClient的getAndStoreFullRegistry方法对服务列表进行获取或者更新。Client 如何负载均衡调用服务,Client 通过使用 JDK 的动态代理,使用
HystrixInvocationHandler进行拦截。而其中的负载均衡策略实现不同,默认是通过一个原子变量递增取余机器数,也就是轮询策略, 而这个类就是ZoneAwareLoadBalancer。
当然,由于 SpringCloud 代码是在很多,本文也没有做到逐行剖析,但是,我们已经了解了他的主要代码在什么地方以及设计,这对于我们理解 SpringCloud 以及排查问题是有帮助的。
good luck!!!