1、MongoDB复制集(副本集)简介
复制集模式(replicaSet mode),也叫副本集模式,指两个及以上的mongo实例组合在一起,其中一个主节点可以读写,剩下的节点可能是备节点、仲裁节点、隐藏节点等等。一般生产环境部署为3个实例组成一个复制集,常见的有PSS(主备备)模式和PSA(主备仲裁)模式。备节点不承担写任务,可以承担读任务。当主节点挂掉时,mongo的选举机制会在该复制集中的其他备节点中选出主节点。
2、复制集部署
部署复制集的方法很简单,可以采用mlaunch工具自动安装MongoDB复制集,也可以根据实际需求拉起mongo进程,然后配置复制集。在生产环境中一般会采用后者。下面我们就一起动手操作下,大致思路为:首先启动所有成员的mongo的进程,然后使用rs.initiate命令将这些进程根据配置组成一个复制集。
(1)启动所有的成员服务器,需加上-replSet参数指定复制集名称
nohup ./mongod --port 30011 --dbpath /data/db/mongodb/shard1/data1 --bind_ip 127.0.0.1,172.16.0.2 -replSet shard1 &
nohup ./mongod --port 30012 --dbpath /data/db/mongodb/shard1/data2 --bind_ip 127.0.0.1,172.16.0.2 -replSet shard1 &
nohup ./mongod --port 30013 --dbpath /data/db/mongodb/shard1/data3 --bind_ip 127.0.0.1,172.16.0.2 -replSet shard1 &
注:nohup和&的作用是拉起mongo进程后不退出。由于笔者只有一台虚拟机,所以只能通过不同的端口和目录来启动mongo进程作为演示。在真实生产环境中,一个mongod数据进程应该独占一台虚拟机。
执行上述命令后,我们得到三个mongo进程,指定的复制集名字叫“shard1”:
(2)配置复制集
①进入上述任意mongo实例
./mongo --port 30011
②定义复制集配置
var config={_id:"shard1", members:[{_id:1, host:"172.16.0.2:30011"}, {_id:2, host:"172.16.0.2:30012"}, {_id:3, host:"172.16.0.2:30013"}]}
注:配置中的_id字段就是启动mongo进程时的replSet指定的复制集名称。
③复制集初始化
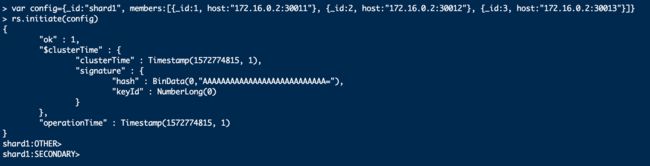
rs.initiate(config)
注:只需对复制集内一个成员调用rs.initiate就可以了,该命令会自动将配置同步到其他members。复制集初始化以后,这些成员会根据配置自动选出一个主节点,然后就可以正常处理业务了。如下图所示,复制集初始化完成后,当前实例由单节点变为了SECONDARY:
(3)修改复制集配置的方法
如果要修改复制集的配置,可以使用rs.reconfig()来重新加载配置(覆盖原来的配置),原理和rs.initiate()类似。
如果是添加成员和删除成员,可以使用rs.add()和rs.remove(),当然也可以使用rs.reconfig()来实现。
(4)查看复制集信息
通过rs.status()可以查看当前复制集所有成员信息以及状态。
3、复制集选举机制和成员角色
3.1 选举机制
复制集中很重要的一个概念是“大多数(majority)原则”:选择主节点时需要由大多数节点同意;写操作备复制到大多数成员时这个写操作才是安全的。大多数被定义为“复制集中一半以上的成员”,如果复制集中有些成员挂了或者是不可用,并不会影响到“大多数”,因为大多数是基于复制集的配置来计算的。例如三个节点组成的复制集中,如果两个节点同时挂掉了,剩余的一个节点无法成为主,只能是备节点,无法承接写操作的业务。
MongoDB复制集采用大多数原则是为了防止“脑裂”,即防止少数的节点由于网络原因与大多数节点失联,然后自己选出了一个主,这样复制集就出现了双主情况,都可以写入数据,复制集的数据就会发生混乱。
每个成员在复制集中都有自己的选举权重,权重越高越容易被选为主节点。成员的权重在加入复制集时由priority参数设置。
通过思考复制集的选举规则,我们可以推理出一下两个部署MongoDB复制集时的两个基本策略:
(1)一个复制集的成员个数最好是奇数,防止两个成员拿到相同的票数而迟迟选不出主;
(2)一个复制集的最高选举权重成员最好有多个,且权重相等,防止故障恢复后又发生主备切换。比如说某权重最大的节点故障修复后重新加入到复制集,它发起了选举请求,由于它的选举权重最大,就变成了主节点,这样就多了一次主备切换,对业务会有些影响。
3.2 主节点降备
有时候为了维护,需要将主节点降备。有多种方式可以将主降为备。注意,我们无法强制将某个成员变为主节点,除非对复制集做适当的配置。
主节点降级为备节点的命令为:rs.stepDown(),不指定时间即默认为60s,在60s内该节点不能再次选为主节点。
根据之前的描述来看,可以总结出复制集发生主备切换的触发条件有:
(1)主节点上执行了rs.stepDonw()降备;
(2)主节点挂掉或失联,剩余大多数节点重新选出新主;
(3)优先级更高的节点加入了复制集中。
3.3 复制集其他成员角色
MongoDB复制集除了主节点和备节点外,还可以存在其他角色。
(1)仲裁者
仲裁者的作用就是参与选举,并不保存数据,也会成为主,也不会为客户端提供服务,它一般只是为了凑够奇数个节点,可以部署在配置较差的服务器上。如果可能,应该将仲裁节点部署在单独的故障域中,这样它就可以以“外部视角”来看待复制集中的成员了。
启动仲裁者与启动普通mongod进程的方式相同,然后使用rs.addArb()将仲裁者添加到复制集中:
rs.addArb("server-4")
也可以在成员配置中指定arbiterOnly选项,例如:
rs.add({_id:3, host:"server-4", arbiterOnly:true})
成员一旦以仲裁者身份加入到复制集中,它就永远只能是仲裁者。一个复制集内最多只能有一个仲裁者。如果有条件,尽可能在复制集中使用奇数个数据不成员,而不要使用仲裁者。例如用PSS部署模式代替PSA模式。这对于生产环境的可靠性和运维有着很重要的作用。
(2)隐藏者
为了隐藏某个服务器,可以在配置中指定hidden:true,只有选举权重为0的实例才能被掩藏。
客户端不会向隐藏成员请求数据,隐藏成员也不会作为复制源。因此,可以将不够强大的服务器隐藏起来。隐藏成员有着该复制集的全量数据,当复制集内其他成员的数据文件都被破坏了,可以通过隐藏成员上保存的数据进行环境修复。
(3)延迟复制者
数据可能会因为操作错误而遭受毁灭性破坏,可能有人在主节点上执行了误删除命令,或者刚上线的应用代码包含了致命bug,污染了所有mongo数据。为了防止这类问题,可以使用slaveDelay设置一个延迟复制者。延迟复制者的数据会比主节点延迟指定的时间,如果主节点的数据受到了破坏或者污染,可以通过延迟复制者将数据恢复到指定时间之前。
同样的,延迟复制者的选举权重必须设置为0。
(4)不创建索引者
有时,备份节点并不需要与主节点拥有相同的索引,甚至可以没有索引,可以在成员配置中指定buildIndexs:false。主要使用场景为只做数据备份或者是离线的批量任务。
同样的,不创建索引者的选举权重必须设置为0。
4 复制集数据同步
4.1 oplog简介
MongoDB复制集内成员的数据同步复制是通过一个日志来存储写操作的,这个日志就叫做oplog。oplog记录了主节点上的每一次写操作,它是一个固定集合(Capped Collection),其他节点通过查询该集合就可以同步数据。每个数据成员维护着自己的oplog,也可以作为同步源给其他成员使用。
下面是查看oplog的例子,其中op:"i"表示这是一个插入操作,是向test.foo集合中插入了一条数据。
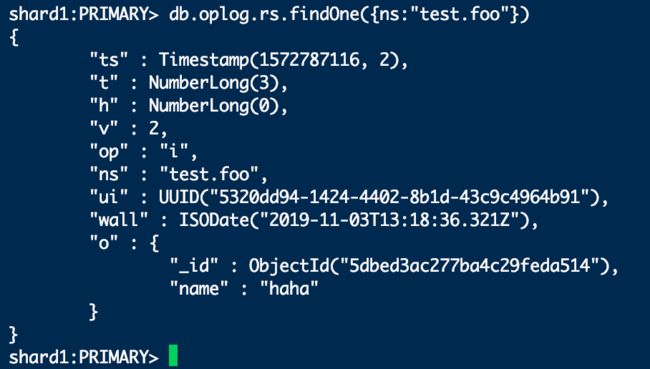
oplog重要字段说明如下表所示:
| 字段 | 含义 |
|---|---|
| ts | 8字节的时间戳,由4字节unix timestamp + 4字节自增计数表示。这个值很重要,在选举新primary时,会选择ts最大的那个secondary作为新的primary。 |
| op | 1字节的操作类型,可以是如下几种情形之一: i,表示insert; u,表示update; d,表示delete; c,表示command; n,表示no op,即空操作,其会定期执行以确保时效性。 |
| ns | 操作所在namespace,由数据库名+集合名构成 |
| o | 操作所对应的document,即当前操作的内容,比如说更新操作时要更新的字段和值。 |
| o2 | 仅限于update操作时,表示更新条件。 |
4.2 oplog的增长速度
oplog是固定大小的,它只能保存特定数据的操作日志,oplog使用空间的增长速度跟系统处理写请求的速度相当。如果单次操作影响了多个文档(比如说删除了多个文档或者更新了多个文档),则oplog就会产生多条操作日志。如果存在大批量的操作,oplog有可能很快会被写满。
在生产环境中,需要根据实际业务需求设置oplog的大小。若一个复制集上的业务量预估会很大,则需要在第一次部署生产环境的时候就将oplog设置大一些。因为后期再调整其大小会比较麻烦。一般将oplog大小设置成能够存储一天的写操作较为合理,若条件有限,至少应该保证oplog大小能够保存10小时以上的写操作。当出现数据丢失问题时,可以通过分析oplog找回数据。或者需要对复制集内某数据成员进行运维时,可以将备节点以单节点方式启动单独运维,再次加入到复制集中可以继续增量同步,不会因为主节点的oplog的时间窗口过段而被老化,防止走初始化同步消耗大量时间。
4.3 复制集数据同步过程
primary节点写入数据产生oplog,secondary通过读取primary的oplog得到复制信息,开始复制数据并且将数据写入到自己的oplog中。如果某个操作失败(只有当同步源的数据损坏或者数据与主节点不一致时才可能发生),则备节点停止从当前数据源复制数据。如果某个备节点重启了,会从上次自己最后一个oplog去主找同步点。
oplog很重要的一个特性是幂等性,即一条oplog执行多次与执行一次的效果是相等的。
4.4 复制集初始化同步
限于篇幅,此处不再赘述,大家可参考阿里专家张友东的博客:MongoDB同步原理解析。
初始化同步的注意事项有:
(1)如果要跟踪初始化同步过程,最好的方法是查询服务器日志。
(2)初始化同步操作简单,但是速度太慢,远不如从备份中恢复。
(3)克隆可能损坏同步源的工作集。实际部署后会有一个频繁使用的数据子集在内存中,执行初始化同步会强制将当前成员的所用数据分页加载到内存中,者会导致热点数据不能常驻内存,进而导致数据库请求变慢。不过对于较小的数据集合性能比较好的服务器,初始化同步是个简单易用的选项。
(4)初始化同步如果耗时太长,新成员就会与同步源脱节,导致新成员的数据同步速度赶不上同步源的变化速度。这个问题没有好的解决办法,只能在不忙的时候执行初始化同步。这是就可以看到让主节点使用足够大的oplog保持足够多的操作是很有必要的!
4.5 回滚
如果主节点执行了一次写请求后挂了,但是备节点还没有来得及复制这次操作,那么新选举出来的主节点就会漏掉这次写操作,这时就会执行回滚过程。
如果回滚的数据大于300MB,或者要回滚30分钟以上的操作,回滚就是失败。对于回滚失败的节点,必须要重新同步。这种情况最常见的原因是备节点远远落后于主节点,而这时主节点却挂了,落后很久的备节点升为了主。为了防止这种情况,要保证复制集内各个数据节点之间的网络要好,并且磁盘要足够好。
5 复制集的好处
(1)可靠性
引入复制集最开始的初衷是通过数据冗余来解决故障中断,提供不间断的数据库服务,提高产品可靠性。当主节点挂掉时,复制集剩余成员可以很快地重新选出主节点,继续提供服务。所以复制集有着与生俱来的可靠性特点。
(2)读写分离
为了防止复制集内主节点的压力过大,可以将业务中对时效性要求不高的查询业务放在备节点上执行。特别是比较复杂的聚合操作和报表统计操作,这些操作往往很耗时,放在备节点操作是个很好的选择。
(3)功能隔离
MongoDB的备份(不管采用dump方式还是拷贝原始数据文件的方式),我们可以在备节点上执行,减少主节点的压力(cpu、内存、磁盘IO等);
复制集可以让我们很方便的对生产环境进行运维。比如说将对一个非常大的表建立索引,若以阻塞方式建立索引,那势必会阻塞正常业务;若以非阻塞方式建立索引,那建立完索引可能需要持续很长的时间。有了复制集我们就可以这样做:①将一个备节点从复制集中移除;②以单节点模式启动该节点,然后以阻塞方式快速建立完索引;③将该节点再以复制集方式启动,加入到原复制集中;④依次对所有备节点都执行这样的操作;⑤对主节点进行降备,然后再执行同样的操作。
(4)跨地区分发
复制集可以将数据分布在不同的地区,这为异地容灾提供了很便捷的方法。比如说两地三中心容灾架构,我们就可以将复制集内两个节点放在一个地区,将另一个节点放到另一个地区中。
这样部署方式要注意网络带宽,并且需考虑两地实际距离。因为一次请求往返一次,那么每增加150公里就会多1毫秒的延迟。
(5)oplog便于运维
复制集内的oplog存储了数据库最近时间段内的所有写操作,当业务出现数据异常时,通过分析oplog很可能就得到了答案,并且根据oplog也可以修复一定的数据。
6 尾声
本文给大家介绍了MongoDB复制集的安装部署、成员角色、选举机制、同步原理、特点优势等,相信大家有了一个基本的了解。在下一章我们一起学习MongoDB的分片(sharding)功能,然后搭建一个分片集群,大家可以领略到MongoDB极强的水平扩展能力。