单变量线性回归实验分析
1 实验目的
实现线性回归,预测该城市人口对应的利润。
2 数据集描述
现有一个数据集命名为ex1data1.txt,里面包含两个属性,即城市人口和利润。
3 使用工具
Pycharm python3
4 实验步骤
- 导入数据,并给每列数据命名一个名称Population,Profit
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 导入数据并查看
path="ex1data1.txt"
# 给每列数据命名一个名称Population,Profit
data=pd.read_csv(path,header=None,names=('Population','Profit'))
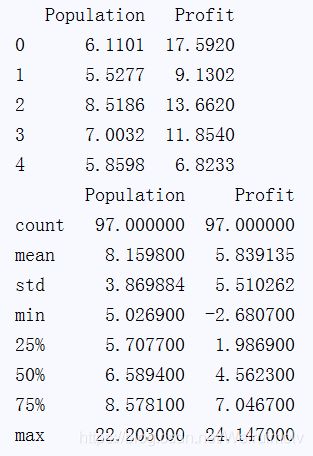
- 查看数据的前五行,和数据描述:
print(data.head())
print(data.describe())
输出结果图:
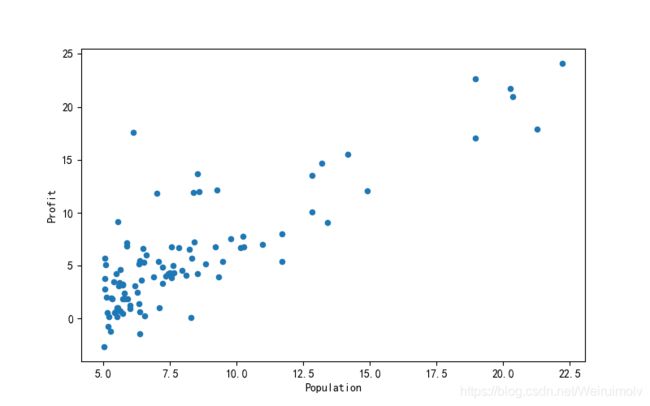
- 将所有数据用散点图表示:
# 可视化数据
data.plot(kind='scatter',x='Population',y='Profit',figsize=(8,5))
plt.show()
输出结果
4. 使用梯度下降实现线性回归,最小化代价函数,代价函数假设为
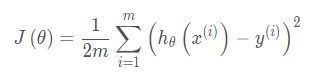
![]()
计算代价函数:
# 计算代价函数J(theta)
def computeCost(X,y,theta):
inner=np.power(((X*theta.T)-y),2)
return np.sum(inner)/(2*len(X))
在训练集中添加一列,以便使用向量化的方法来计算代价和梯度。
# 在训练集中第0列添加一列数字1,命名为Ones
data.insert(0,'Ones',1)
取最后一列为 y,其余为 X
# 取最后一列为y,其余为X
# 列数
cols=data.shape[1]
# 取前cols-1列,即输入向量
X=data.iloc[:,0:cols-1]
# 取最后一列,即目标向量
y=data.iloc[:,cols-1:cols]
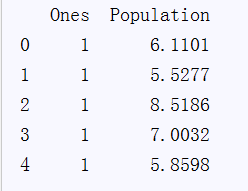
观察下 X (训练集) 是否正确
print(X.head())
输出结果:
转换X和Y,初始化theta。
# 转换X和y,初始化theta
X=np.matrix(X.values)
y=np.matrix(y.values)
theta=np.matrix([0,0])
计算初始代价函数的值,theta初始值为0
# 计算初始代价函数的值 (theta初始值为0).
print(computeCost(X, y, theta))
# 32.072733877455676
批量梯度下降
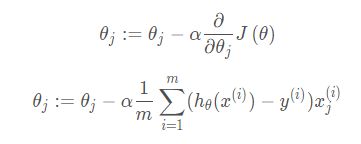
def gradientDescent(X, y, theta, alpha, epoch):
temp=np.matrix(np.zeros(theta.shape)) # 初始化一个 θ 临时矩阵(1, 2)
parameters=int(theta.flatten().shape[1]) # 参数 θ的数量
cost=np.zeros(epoch) # 初始化一个ndarray,包含每次epoch的cost
m=X.shape[0] # 样本数量m
for i in range(epoch):
# 利用向量化一步求解
temp=theta - (alpha / m) * (X * theta.T - y).T * X
theta=temp
cost[i]=computeCost(X, y, theta)
return theta, cost
初始化一些附加变量 - 学习速率α和要执行的迭代次数。
alpha=0.01
epoch=1000
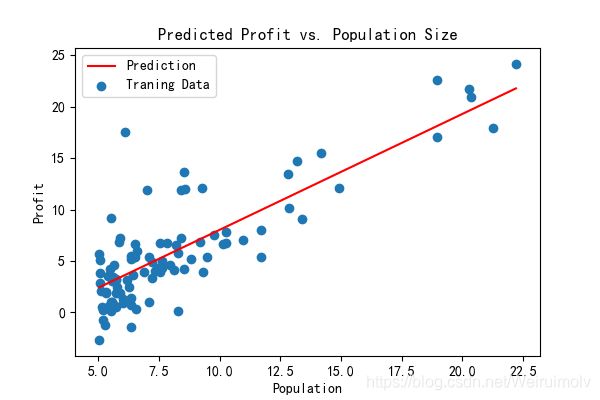
画出拟合图像:
# 运行梯度下降算法来将我们的参数θ适合于训练集。
final_theta, cost = gradientDescent(X, y, theta, alpha, epoch)
# 使用我们拟合的参数计算训练模型的代价函数(误差)。
computeCost(X, y, final_theta)
# 绘制线性模型以及数据,直观地看出它的拟合。
x = np.linspace(data.Population.min(), data.Population.max(), 100) # 横坐标
f = final_theta[0, 0] + (final_theta[0, 1] * x) # 纵坐标,利润
fig, ax = plt.subplots(figsize=(6,4))
ax.plot(x, f, 'r', label='Prediction')
ax.scatter(data['Population'], data.Profit, label='Traning Data')
ax.legend(loc=2) # 2表示在左上角
ax.set_xlabel('Population')
ax.set_ylabel('Profit')
ax.set_title('Predicted Profit vs. Population Size')
plt.show()
运行结果:
- 画出代价随迭代次数变化的曲线图
# 每个训练迭代中输出一个代价的向量
fig, ax = plt.subplots(figsize=(8,4))
ax.plot(np.arange(epoch), cost, 'r') # np.arange()返回等差数组
ax.set_xlabel('Iterations')
ax.set_ylabel('Cost')
ax.set_title('Error vs. Training Epoch')
plt.show()
运行结果图:
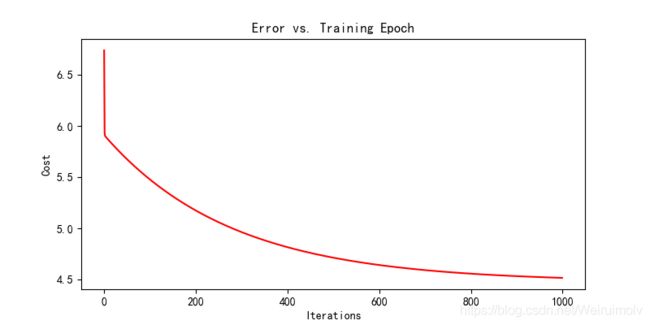
由图可知,随着迭代的次数增加,代价越来越小,即误差越来越小,函数逐渐收敛。
参考链接:吴恩达机器学习作业