【论文阅读】多粒度特征融合的维度语音情感识别方法
- 陈婧, 李海峰, 马琳, et al. 多粒度特征融合的维度语音情感识别方法[J]. 信号处理, 2017(3).
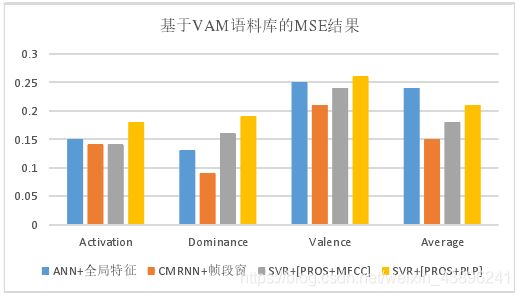
主要内容:针对传统维度语音情感识别系统采用全局统计特征造成韵律学细节信息丢失以及特征演化规律缺失的问题,提出了一种基于不同时间单元的多粒度特征提取方法,提取短时帧粒度、中时段粒度和长时窗粒度特征,并提出了一种可以融合多粒度特征的基于认知机理的循环神经网络CIRNN,使用不同时间单元的特征参与网络训练,实现多层级信息融合。本文在VAM维度语料库上进行实验,得到平均相关系数0.66,优于传统的ANN和SVR识别结果。
收获:了解了连续语音识别中多粒度特征提取方法,实验评价方法与指标。
文章的主要工作
- 针对全局统计特征引起时序信息丢失的问题,研究了合适的情感表达时长,提出基于不同时间单元的多粒度情感特征提取方法。
- 提出了可以融合多粒度特征的基于认知机理的循环神经网络(CMRNN)。
- 在VAM语料库上评估模型的性能。
多粒度语音情感特征提取方法
文章认为短时帧特征太过于关注语义信息,而全局统计特征有可能导致情感韵律细节信息丢失,因此提出语段粒度特征和情感认知窗粒度特征两个粒度特征。
帧粒度特征提取
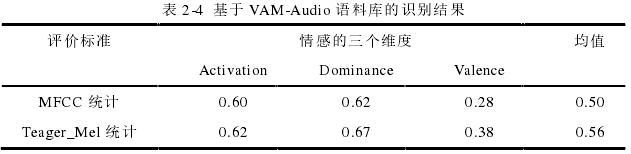
使用25ms汉明窗,帧移10ms对语音进行分帧处理,然后提取96维特征并进行归一化。本文的一个创新点是,使用Teager_Mel特征代替MFCC特征,并通过实验验证了该特征的有效性,可在后续的研究中作为参考。

其中,Teager_Mel特征的理论基础是:一个完整的语音是由线性和涡流区域的非线性模块构成,涡流部分会对语音信号产生影响。提取过程如图所示:

TEO变换为![]() ,它的优点是更加突出语音信号能量在不同频段上的偏差,从而使得情感能量在不同情绪下的偏移更为明显。
,它的优点是更加突出语音信号能量在不同频段上的偏差,从而使得情感能量在不同情绪下的偏移更为明显。
作者为验证Teager_Mel的有效性,与MFCC相对比,每种特征提取了共273维的统计特征,如图所示:

然后使用相关系数作为评价指标,在VAM语料库上进行实验,实验结果如图所示,从而证明了Teager_Mel的有效性。
段粒度特征提取
- 分段
以“帧/段”为单位衡量段长,分别取10帧/段、20帧/段、……、200帧/段共20种情况进行实验。语段划分方法与交叠分帧方法类似,使用矩形窗,段移为段长的一半。分段后,对段内帧特征进行统计,取19种统计函数,从而得到19×96=1824维的段特征。选取的统计函数如图所示。


- 确定最优段长
使用Elman的SRN(简单循环神经网络)做分类器,分别在Activation、Valence和Dominance三个维度拟合,使用相关系数评价拟合效果。
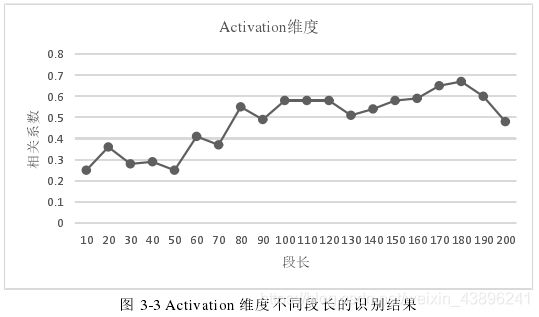


实验结果表明不同段长划分对系统的结果影响较大,且随段长的增长拟合效果并未明显提高,综合来看,段长取80帧/段时得到最优的拟合效果。
窗粒度特征提取
人的情感表达分为酝酿阶段、充分表达阶段和收尾阶段,其中在收尾阶段中,语气、语调都相应降低,因此文章采用高斯函数拟合这一过程,即在多个语段特征上加载高斯函数,提取过程和具体算法如图所示。



XN表示语段特征,G(·)为高斯函数,wi是第i段对应高斯函数的位置,由于高斯函数有效值服从3![]() 原则,因此S是
原则,因此S是![]() ,M是3
,M是3![]() 区间长度。
区间长度。
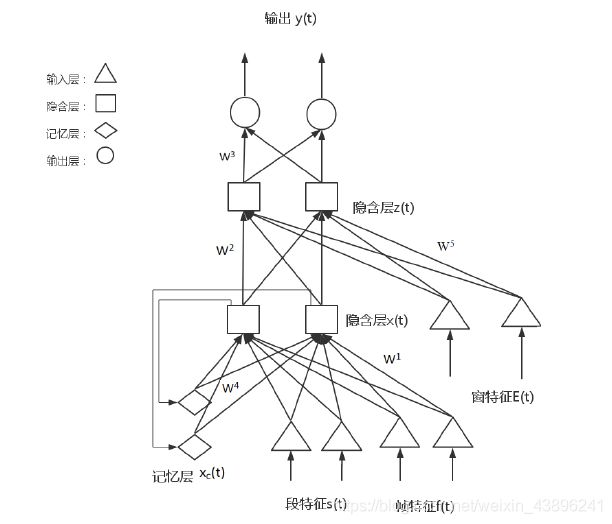
网络结构

在RNN的基础上增加输入层和隐含层得到CMRNN。因此,CMRNN包含2个输入层、2个隐含层、1个记忆层和1个输出层共6层。其中,z(t)由x(t)和e(t)都加权并使用sigmoid函数激活得到的。然后使用误差反向传播算法更新权重。
为了融合多粒度特征进行识别,输入层u(t)是由帧粒度特征和段粒度特征构成,窗粒度特征则作为另一个输入单独进入网络,如图所示。
实验
数据集——VAM语料库
VAM数据库的情感标注在情感的空间,分别在Activation、Dominance、Valence 三个维度。它是通过德国的电视访谈节目录制的信息,由三个子研究方向的库组成:VAM-Video、VAM-Audio 和VAM-Faces 三个数据库。其中VAM-Video 数据库保存着这些对话的视频信息;VAM-Audio 数据库保存着这些对话的音频信息;VAM-Faces 是从VAM-Video中提取出这些图像的面部情感信息。文章使用VAM-Audio 语料库进行实验。VAM-Audio 语料库共有 12 小时的时长。语料库由 47 个话语者(11 名男性/36 名女性)进行录制的,每个实验人员平均录制22 条语句。最终这些语料被 17 个标注者进行标注,分别标签在情感的三个维度:效价度、激活度和控制度,标注值在-1和1之间。VAM-Audio语料库共有947条情感语句。将语料库随机10等分,九份作为训练集,采用10折交叉验证。
实验设置
1. 对比实验
3层ANN:输入层为1824个神经元,隐含层为50个神经元,输出层包含3个节点,分别对应3个维度。
CMRNN:输入为(1824维段特征+96维帧特征)和1824维窗特征。隐含层和记忆层均包括50个节点,输出层3个节点对应3个维度。
2. 评价指标:相关系数CC和均方误差MSE。
3. 其他说明:
- 训练或测试阶段,当输入一个语料的最后一段特征时,将最后一段输入的特征得到的神经网络输出结果作为该语料的识别结果;
- 在训练或者测试阶段,按照特征的时序信息进行输入,对属于同一个语料的记忆层信息需要进行保留;对于不同的语料,需要在输入本样本的第一个时序特征之前将记忆层的数值置为零,这样使得两个独立样本之间不会受到影响;
- 在训练阶段,对于同一语料样本的特征输入,网络的误差要累积到最后一个特征输入,进行一次神经网络的权值修改,但是不同的语料样本,误差信息不会累计
实验结果
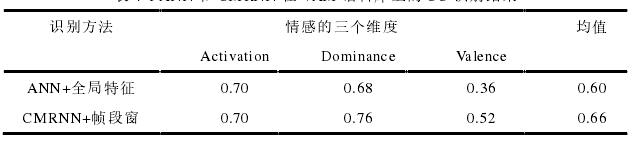
相关系数结果:
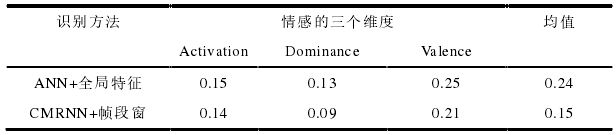
均方误差结果:
另外,文章还与使用SVR的方法比较,得到了如下结果: