【源码分享】用Java写的网页图片、CSS、JavaScript分类下载器
前段时间老师让我们要做一个JavaEE项目,是一个电子商务网站--中国鲜花网,前台模板就用这个网站的,但是用浏览器直接下载来的图片和样式表等文件全在一个文件夹,需要给它批量替换,最要命的是浏览器的这个功能不能够下载样式表中的背景图片,所以很多网页都会显示不正常,鉴于此,自己花了几个小时研究了一下正则表达式写了这个工具,基本上一般网页下载都没什么问题,就是碰到有些网页是需要登录的,比如说用户中心,你直接把地址敲进去下载下来的一般都是登录页面,所以后来又做了个替换“浏览器保存的网页”中的图片和样式表、JavaScript文件的小工具,就是背景图片的功能还没做(要做也不难),这个程序代码放教室了,以后有时间也贴上来。
名字随便取的,叫“网页资源分类下载器”,界面如下:
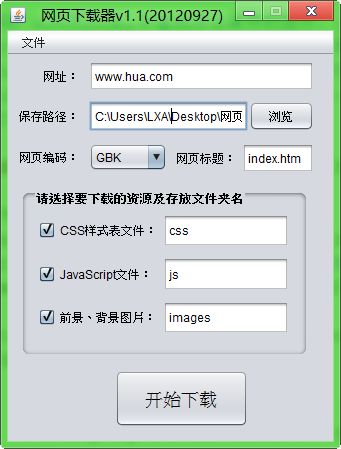
下载后的文件夹形式如下:
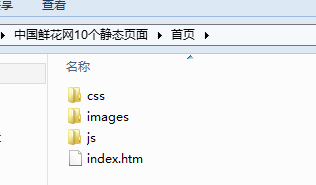
原理简要分析一下(不分析估计大部分都清楚):就是首先把网页html下载下来,然后用正则表达式遍历其中的图片、样式表、JavaScript文件,匹配出来的文件再和网址拼接出真正的下载地址(比如碰到../要退一层目录等),然后下载到指定文件夹,保存网页的html之前还要将各个资源的地址批量替换成新的地址。下载这样下载下来的一般只有前景图片,背景图片还没法下载,所以再遍历下载下来的样式表文件,用background-image匹配出符合条件的背景图片,再根据样式表文件的网页相对地址和整个网页的地址拼接出背景图片的真实地址,然后下载下来。
目前测试中国鲜花网的几个页面都没什么问题,所有资源都能正常下载,当然肯定还有很多Bug,有兴趣的可以看一下源代码。
源码下载地址:http://vdisk.weibo.com/s/fyFYx/1350100334
主要代码如下(界面的代码就省掉了):
public String html="";//存放网页HTML源代码 public int cssCount=0;//下载成功的样式表文件个数 public int jsCount=0;//下载成功的JavaScript文件个数 public int normalImageCount=0;//普通图片数量 public int backgroundImageCount=0;//背景图片数量 /** * 开始下载 */ public void startDownload() { buttonStart.setText("正在下载……"); buttonStart.setEnabled(false); File savePath=new File(txtSavePath.getText()); //计数清零 cssCount=0; jsCount=0; normalImageCount=0; backgroundImageCount=0; //创建必要的一些文件夹 if(!savePath.exists()) savePath.mkdir();//如果文件夹不存在,则创建 File css=new File(savePath+"/"+txtCss.getText()); File js=new File(savePath+"/"+txtJs.getText()); File images=new File(savePath+"/"+txtImages.getText()); if(!css.exists()) { css.mkdir(); System.out.println("css文件夹不存在,已创建!"); } if(!js.exists()) { js.mkdir(); System.out.println("js文件夹不存在,已创建!"); } if(!images.exists()) { images.mkdir(); System.out.println("images文件夹不存在,已创建!"); } //下载网页html代码 System.out.println("开始下载网页HTML源代码!"); String url=txtUrl.getText(); if(!url.startsWith("http://")) url="http://"+url; html=getHTML(url, comboBoxEncode.getSelectedItem().toString()); System.out.println("网页HTML下载成功!"); if(checkBoxCss.isSelected()) { System.out.println("开始下载样式表文件!"); regx("<link.*type=\"text/css\".*>", "href=\"", url,txtCss.getText()); } if(checkBoxJs.isSelected()) { System.out.println("开始下载JavaScript文件!"); regx("<script.*javascript.*>", "src=\"", url, txtJs.getText()); } if(checkBoxImages.isSelected()) { System.out.println("开始下载网页前景图片文件!"); regx("<img.*src.*>", "src=\"", url, txtImages.getText()); } //保存网页HTML到文件 try { File newFile=new File(savePath.toString()+"/"+txtTitle.getText()); newFile.createNewFile(); OutputStreamWriter writer=new OutputStreamWriter(new FileOutputStream(newFile), comboBoxEncode.getSelectedItem().toString()); BufferedWriter bw=new BufferedWriter(writer); bw.write(html); bw.close(); writer.close(); } catch (IOException e) { e.printStackTrace(); } String result="恭喜,全部资源下载完毕!"; result+="累计下载css文件"+cssCount+"个;\n"; result+="累计下载JavaScript文件"+jsCount+"个;\n"; result+="累计下载前景图片"+normalImageCount+"张;\n"; result+="累计下载背景图片"+backgroundImageCount+"张。\n"; System.out.println(result); JOptionPane.showMessageDialog(null, result,"下载结束",JOptionPane.INFORMATION_MESSAGE); buttonStart.setText("开始下载"); buttonStart.setEnabled(true); } /** * 最核心的代码,从网页html中查找符合条件的图片、css、js等文件并批量下载 * @param regx 检索内容的一级正则表达式,结果是含开始、结束标签的整个字符串,例如:<script.*javascript.*> * @param head 已经检索出的标签块中要提取的字符的头部,包含前面的双引号,如:src=" * @param url 要下载的网页完整地址,如:http://www.hua.com * @param folderName 文件夹名,如:css */ public void regx(String regx,String head,String url,String folderName) { //下载某种资源文件 Pattern pattern=Pattern.compile(regx);//新建一个正则表达式 Matcher matcher=pattern.matcher(html);//对网页源代码进行查找匹配 while(matcher.find())//对符合条件的结果逐条做处理 { Matcher matcherNew=Pattern.compile(head+".*\"").matcher(matcher.group()); if(matcherNew.find()) { //对于CSS匹配,查找出的结果形如:href="skins/default/css/base.css" rel="stylesheet" type="text/css" String myUrl=matcherNew.group(); myUrl=myUrl.replaceAll(head, "");//去掉前面的头部,如:href:" myUrl=myUrl.substring(0,myUrl.indexOf("\""));//从第一个引号开始截取真正的内容,如:skins/default/css/base.css String myName=getUrlFileName(myUrl);//获取样式表文件的文件名,如:base.css html=html.replaceAll(myUrl, folderName+"/"+myName);//替换html文件中的资源文件 myUrl=joinUrlPath(url, myUrl);//得到最终的资源文件URL,如:http://www.hua.com/skins/default/css/base.css //System.out.println("发生地健康:"+myUrl); //去掉文件名不合法的情况,不合法的文件名字符还有好几个,这里只随便举例几个 if(!myName.contains("?")&&!myName.contains("\"")&&!myName.contains("/")) { downloadFile(myUrl, txtSavePath.getText()+"/"+folderName+"/"+myName);//开始下载文件 System.out.println("成功下载文件:"+myName); if(regx.startsWith("<img"))//如果是下载前景图片文件 normalImageCount++; if(regx.startsWith("<script"))//如果是下载JS文件 jsCount++; if(regx.startsWith("<link"))//如果是下载css文件 { cssCount++; //将刚刚下载的CSS文件实例化 File cssFile=new File(txtSavePath.getText()+"/"+folderName+"/"+myName); String txt=readFile(cssFile,"gb2312");//读取CSS文件的内容,这里用默认的gb2312编码 //开始匹配背景图片 Matcher matcherUrl=Pattern.compile("background:url\\(.*\\)").matcher(txt); while (matcherUrl.find()) { //去掉前面和后面的标记,得到的结果如:../images/ico_4.gif String temp=matcherUrl.group().replaceAll("background:url\\(", "").replaceAll("\\)", ""); //拼接出真正的图片路径,如:http://www.hua.com/skins/default/images/ico_4.gif String backgroundUrl=joinUrlPath(myUrl, temp); //获取背景图片的文件名,如:ico_4.gif String backgroundFileName=getUrlFileName(backgroundUrl); //背景图片要保存的路径,如:c:/users\lxa\desktop\网页\images\ico_4.gif String backgroundFilePath=txtSavePath.getText()+"/"+txtImages.getText()+"/"+backgroundFileName; if(!new File(backgroundFilePath).exists())//如果不存在同名文件 { if(downloadFile(backgroundUrl, backgroundFilePath))//开始下载背景图片 { backgroundImageCount++;//计数加1 System.out.println("成功下载背景图片:"+backgroundFileName); } } else { System.out.println("指定文件夹已存在同名文件,已为您自动跳过:"+backgroundFilePath); } } } } } } } /** * 根据指定的URL下载html代码 * @param pageURL 网页的地址 * @param encoding 编码方式 * @return 返回网页的html内容 */ public String getHTML(String pageURL, String encoding) { StringBuffer pageHTML = new StringBuffer(); try { URL url = new URL(pageURL); HttpURLConnection connection = (HttpURLConnection) url.openConnection(); connection.setRequestProperty("User-Agent", "MSIE 9.0");//设置客户的浏览器为IE9 BufferedReader br = new BufferedReader(new InputStreamReader(connection.getInputStream(), encoding)); String line = null; while ((line = br.readLine()) != null) { pageHTML.append(line); pageHTML.append("\r\n"); } connection.disconnect(); } catch (Exception e) { e.printStackTrace(); } return pageHTML.toString(); } /** * 根据URL下载某个文件 * @param fileURL 下载地址 * @param filePath 存放的路径 */ public boolean downloadFile(String fileURL,String filePath) { try { File file=new File(filePath); file.createNewFile(); StringBuffer sb = new StringBuffer(); URL url = new URL(fileURL); HttpURLConnection connection = (HttpURLConnection) url.openConnection(); connection.setRequestProperty("User-Agent", "MSIE 9.0");//设置客户的浏览器为IE9 byte[] buffer = new byte[1024]; InputStream is = connection.getInputStream(); FileOutputStream fos = new FileOutputStream(file); int len = 0; while ((len = is.read(buffer)) != -1) fos.write(buffer, 0, len); fos.close(); is.close(); connection.disconnect(); return true; } catch (IOException e) { System.out.println("该文件不存在:"+fileURL); return false; } } /** * 读取某个文本文件的内容 * @param file 要读取的文件 * @param encode 读取文件的编码方式 * @return 返回读取到的内容 */ public String readFile(File file,String encode) { try { InputStreamReader read = new InputStreamReader (new FileInputStream(file),encode); BufferedReader bufread=new BufferedReader(read); StringBuffer sb=new StringBuffer(); String str=""; while ((str = bufread.readLine()) != null) sb.append(str+"\n"); String txt=new String(sb); return txt; } catch (Exception e) { e.printStackTrace(); return null; } } /** * 获取URL中最后面的真实文件名 * @param url 如:http://www.hua.com/bg.jpg * @return 返回bg.jpg */ public String getUrlFileName(String url) { return url.split("/")[url.split("/").length-1]; } /** * 获取URL不带文件名的路径 * @param url 如:http://www.hua.com/bg.jpg * @return 返回 http://www.hua.com */ public String getUrlPath(String url) { return url.replaceAll("/"+getUrlFileName(url), ""); } /** * 拼接URL路径和文件名,注意:以../或者/开头的fileName都要退一层目录 * @param url 如:http://www.hua.com/product/9010753.html * @param fileName 如:../skins/default/css/base.css * @return http://www.hua.com/skins/default/css/base.css */ public String joinUrlPath(String url,String fileName) { //System.out.println("url:"+url); //System.out.println("fileName:"+fileName); if(fileName.startsWith("http://")) return fileName; //如果去掉“http://”前缀后还包含“/”符,说明要退一层目录,即去掉当前文件名 if(url.replaceAll("http://","").contains("/")) url=getUrlPath(url); if(fileName.startsWith("../")||fileName.startsWith("/")) { //只有当前URL包含多层目录才能后退,如果只是http://www.hua.com,想后退都不行 if(url.replaceAll("http://","").contains("/")) url=getUrlPath(url); fileName=fileName.substring(fileName.indexOf("/")+1); } //System.out.println("return:"+url+"/"+fileName); return url+"/"+fileName; }