摘要
视觉识别需要丰富表达,从高到低的层,从小到大的尺度,从细到粗的分辨率。尽管在卷积网络有深度特征,但是孤立的层还是不够:复合和聚合这些表达可以改进"what"和"where"的推断。架构工作正在探索网络骨干的方方面面,设计更深的网络或者更宽的架构,但是如果如果更好地聚合网络的层和块值得进一步关注。虽然已经结合跳跃连接来组合层,但是这些连接本身比较"浅",而且仅需要简单的一步操作来融合。我们用更深聚合来扩增标准架构,以更好地融合层的信息。我们的深层聚合结构迭代和分层地聚合特征层次,使得网络更深的精度和更少的参数。实验表明深层聚合结构能够提高识别和分辨率。
1.介绍
如何连接层和模块需要进一步探索。更深的网络层提取更多的语义和更加全局的特征。但是并不能表明最后一层就是任务的最终表示。实际上,跳跃连接已被证明对分类和回归以及结构化任务是有效的。深度和宽度的聚合,是架构关键的维度。
我们研究如何聚合层以更好地融合语义和空间信息一进行识别和定位。扩展当前方法的“浅层”跳跃连接,我们聚合架构更多深度和共享。我们介绍两种深度聚合(DLA)结构:迭代深度聚合(IDA)和分层深度聚合(HDA)。这些结构通过架构框架表达,不决取于网络主干的选择,能够兼容现有已经未来的网络结构。IDA主要进行分辨率和尺度的融合,而HDA主要融合各种模组和通道的特征。IDA根据基础网络结构,逐级提炼分辨率和聚合尺度(类似参差网络)。HDA整合其自身的树状连接结构,并将各个层级聚合为不同等级的表征(空间尺度的融合,类似与FPN)。本文的策略可以通过混合使用IDA和HDA来共同提升效果。
本文通过实验将现有的ResNet和ResetNeXt网络结构采用DLA架构,来进行大尺度图像分类,细粒度识别,语义分割和边界检测任务。本文的结果显示DLA的使用可以在现有的ResNet、ResNetXt、DenseNet 网络结构的基础上再提升模型的性能、减少参数数量以及显存开销。DLA达到了目前分类任务中紧凑模型的最佳精度。不需要通过更多的结构变更,同样的网络能在多个细粒度识别任务就能达到最佳精度。通过标准技术对标准化输出进行重塑,DLA在cityscapes的语义分割任务中实现了最高类间精度,并在PASCAL Boundaries数据集上的边界检测任务中达到最佳精度。DLA是一种通用而有效的深度视觉网络拓展技术。
Deep layer Aggregation
本文将聚合定义为整个网络的不同层之间的组合。在这篇文章中,我们把注意力放在可以更有效的聚合深度、分辨率和尺度的网络。如果一组聚合是复合的、非线性的,并且最早的聚合层经过多个聚合层,我们就称它为深度聚合。
由于网络可以包含许多层和连接,模组化设计可以通过分组与复用来克服网络过于复杂的问题。层组合为块,块根据其特征分辨率组合成层级。本文主要探讨如何聚合块与层级。
3.1 迭代深度聚合(IDA)
IDA是迭代堆叠的主干网络结构。本文中将网络中堆叠起来的的块按照分辨率分成层级,更深的层级有更多语义信息但是空间信息更为粗糙。从浅层到深层的跳跃连接能够融和尺度和分辨率。但是这样的跳跃连接,比如FCN、U-Net、FPN,都是先行并且都至少聚合了最浅层的网络。
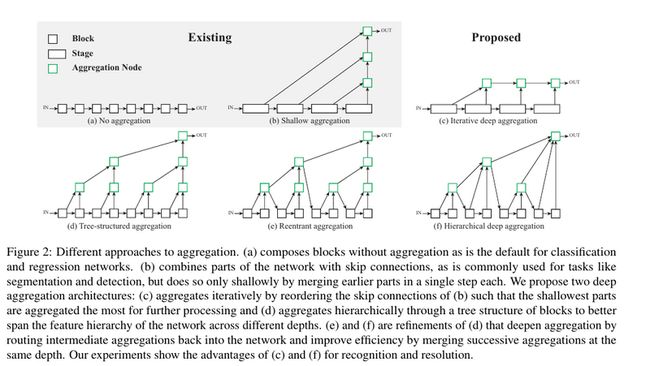
(b)通过跳跃连接来组合网络的各个部分。但这样做每一步只是融合前面的浅层信息。(c) 迭代式的聚合,使浅层的网络可以在后续的网络中获得更多的处理;(d) 通过树状结构块的聚合,可以将特征结构在网络的不同深度上传播。
因此,本文提出采用IDA的更为激进的聚合方法。在最浅、最小尺度开始聚合,并不断迭代与更深、更大尺度信息融合。这样的方式可以浅层网络的信息可以通过后续的不同层级的聚合而获得精炼。图2 (c) 展示了IDA的基本结构

3.2 层级深度聚合(HDA)
HDA在树结构融合块和层级,来保留并组合特征通道。通过HDA,浅层和深层的网络层可以组合到一起,这样可以学习跨越各个层级特征的丰富组合信息。IDA虽然能有效的组合层级,但是IDA依旧是呈序列的,它尚不足以融合网络的各个块的信息。HDA的深度分支结构如图2 (d)所示。
建立了基础的HDA结构后,可以在此基础上改进其深度与效率。通过改变中层网络的聚合形式和整个树结构,我们将一个聚合节点的输出返回到主干网络,作为下一个树结构的输入,如图2 (e)所示。这样可以将之前所有块的信息聚合到后续的处理中,更好地保留了特征,而不是单独地处理前面的块。为了提高效率,本文通过将父块与左边的子块融合,将拥有相同深度(也就是有相同特征图尺寸)的聚合节点融合在一起,如图2 (f)所示。
HDA建模为:

Q(1):是什么聚合,与融合有什么不同?
My ans: 融合分成语义融合和空间融合,语义(物体信息)融合能够推断“是什么”,空间融合能够推断“在哪里”。而聚合就是语义融合和空间融合的组合。
Q(1):块和层级有什么不同?
My ans: 块由多个网络层组成,层级由多个块组成,同一个层级输入输出分辨率保持一致,不同的层级分辨率是不同的。
Q(2):IDA和HDA分别有什么优点?
My ans: IDA是一种迭代式聚合,从图3(c)可以看到前面浅层信息不断地与后面的深层信息聚合,这样子,前面的浅层信息能够不断地提炼,能够丰富的语义信息。但IDA呈序列性,难以组合不同块的信息。HDA是一种树状结构块的分层聚合,以更好地学习跨越不同深度的网络特征层次的丰富(空间)信息。所以IDA和HDA的结构既能学习到语义信息也能学习到空间信息。
3.3 聚合元素
聚合节点:主要功能是组合和压缩节点的输入。这些节点通过训练来选择和投影重要的信息,以维持与输入维度一致相同尺度的输出。在本文的结构中,所有的IDA节点都是二分节点(只有两个输入),而HDA节点根据树结构的深度不同而有一系列的参数输入。
尽管一个聚合节点可以采用任意的块或层结构,为了简便起见,本文采用单一的卷积接一个BN层接一个非线性激活层的结构。这避免了聚合结构过于复杂。在图像分类网络中,所有的(聚合)节点采用1x1的卷积。在语义分割中,本文添加了额外一层IDA来对特征图进行差值,在这种情况下则采用3x3的卷积。
由于残差连接对于集成非常深的网络结构非常重要,本文在聚合节点中同样采用了残差连接。但是它们对于聚合的必要性尚不明确。通过HDA,任意块到网络根部的最短路径最大为架构的深度,因此聚合路径不太可能发生梯度消失以及梯度爆炸问题(?为什么)。在本文的实验中,在最深的网络结构达到4层及以上时,残差连接可以促进HDA,但是不利于更小的网络。我们的基础聚合,也就是公式1、2中的 由下式定义

块和层级:DLA是一个通用架构因为它可以与不同的骨干网络相兼容。我们的架构对于块和层级的内在结构并没有要求。
实验中我们采用三个不同类型的残差块。基础块将堆叠的卷积层和恒等跳跃连接组合在一起。瓶颈块通过使用1x1卷积对堆叠的卷积层进行降维来进行正则化。分割块通过将通道分组为多个单独的路径来对特征进行多样化。在这项工作中,我们将瓶颈块和分割块的输出和中间通道数量的比例减少了一半,分割块的基数为32。有关这些区块的确切细节,请参阅被引的论文。
- 应用
4.1 分类网络
我们的分类网络在ResNet和ResNet的基础上使用IDA和HDA。我们在层级间采用IDA连接,在层级内采用HDA。他们是层级网络,通过空间分辨率进行分块,每个分块用残差网络进行连接,每个层级结束分辨率减半,一共6个层级,第一个层级维持输入分辨率但是最后大的层级是32x的降采样。最后的特征映射通过全局平均池化来然后线性插值,变得很粗糙,最终的分类结果采用softmax的形式。
我们在层级间用IDA连接,在层级内用HDA连接。这种聚合类型很容易通过通向聚合节点进行组合。在这种情况下,我们只需要通过组合公式1和公式2来改变每个阶层的根节点。我们的层级通过size 2和stride2的maxpooling进行降采样。
在最早的层级有他们自己的结构。好像DRN,我们在层级1-2用stirded卷积来替换maxpooling。层级 1由一个7x7的卷积然后跟着一个基础块组成。层级 2仅仅是一个基础块。对于其他层级,我们使用骨干网络的块和层级组合的IDA和HDA。
DLA如图3所示。
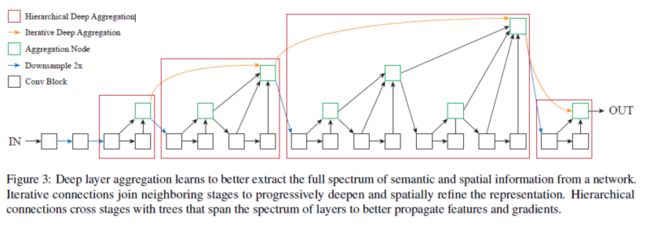
DLA学习更好地从网络中提取语义信息和空间信息的全部范围。迭代连接将邻近的stages连接在一起,逐步地深入并空间上提炼表达。跨越层范围树结构stages之间的层次连接可以更好地传播特征和梯度。
4.2 密集预测网络
语义分割,边缘检测,和其他image-to-image 任务可以利用聚合来融合局部和全局信息。分类DLA到全卷积DLA的转换简单并且跟其他架构没有什么区别。我们充分利用插值和进一步的IDA扩增来达到任务输出分辨率的需要。
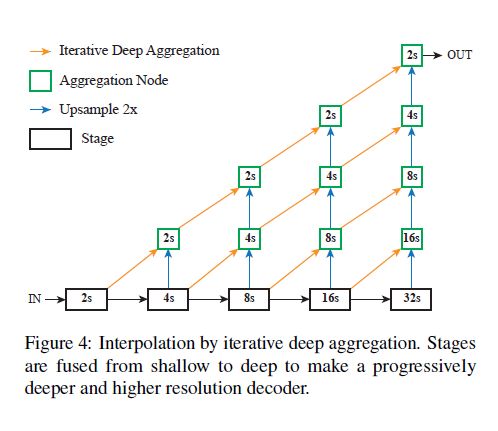
通过投影和上采样,IDA的插值同时增加了深度和分辨率,如图4所示。在网络优化时候,所有投影和上采样参数联合训练。上采样步骤的参数用双线性插值来初始化。我们首先对层级3-6的输出投影到32个通道然后对该层级进行插值,以达到层级2一样的分辨率。最后我们这些层级进行迭代聚合来学习一个低和高水平特征的深度融合。跟FCN跳跃连接,层级特征和FPN的top-down连接一样的目的。我们聚合的方法不一样,是从浅到深进一步提炼特征。注意的是我们在这种情况下,两次使用IDA:第一次是在骨干网络连接层级。然后是恢复分辨率。
个人总结
文章解决什么问题
解决网络层和层级聚合问题。
用自己的话总结文章思路:
文章提出了DLA拓展技术来融合语义和空间信息,以提高网络的精度。DLA分成IDA和HDA结构。其中IDA是一种迭代式的聚合结构,浅层信息可以与后面的层不断地地聚合,以更好地提炼特征。而HDA是一种树状块的聚合结构,学习到跨越层次的特征信息。
关键因素:
- 树状式聚合学习跨越层次的特征,能够学习到丰富空间信息
为我所用:
用DLA技术来拓展网络