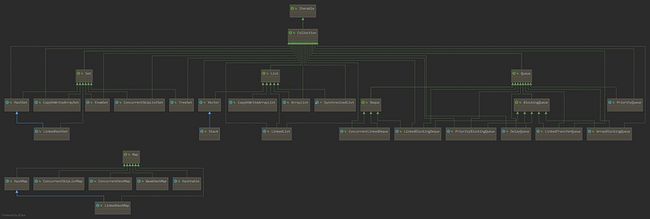
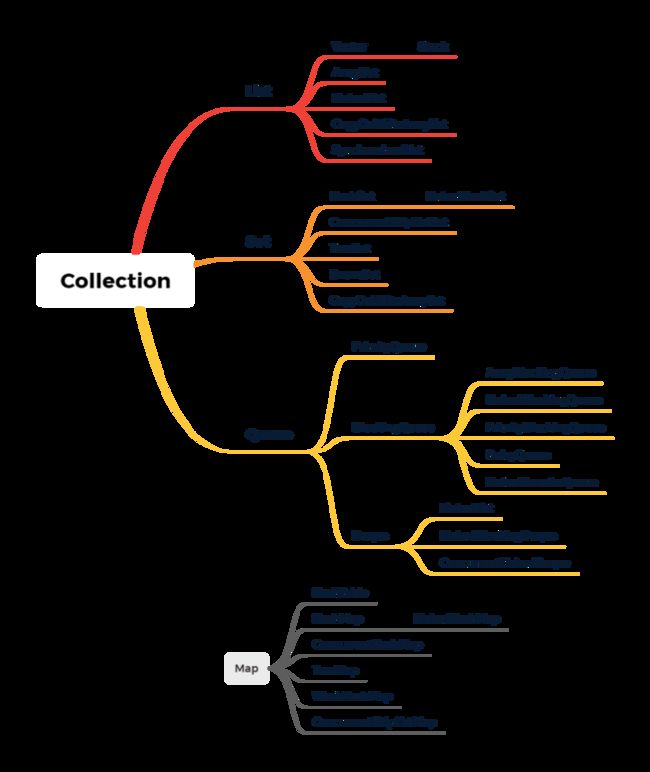
List
Vector
采用Object数组存储元素
protected Object[] elementData;Stack
Stack继承了Vector,采用Object数组存储元素
ArrayList
顾名思义,ArrayList底层采用数组存储元素
Object[] elementData;LinkedList
顾名思义,LinkedList底层采用链表存储元素。通过first和last指针分别指向头元素和尾元素。
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node last; 其中Node是LinkedList自定义的静态类,通过next和prev指针分别指向后驱节点和前驱节点。因此LinkedList底层是通过first和last指针分别指向头元素和尾元素的双向链表。
private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
} CopyOnWriteArrayList
顾名思义,CopyOnWriteArrayList底层是通过Object[] 数组存储数据,提供的构造方法在初始化时自动创建了长度为0的数组。
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
/**
* Creates an empty list.
*/
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
CopyOnWrite的逻辑大体上都是在插入数据的时候,重新复制一份数组,在新数组中插入新数据,之后将指针指向新的数组。这种模式主要是为了针对“改动操作很少,主要是读操作”的业务。CopyOnWriteArrayList一样,在操作数据时通过ReentrantLock锁住防止并发之后,复制原数组再在新数组中操作数据,最后将指针指向新数组。
- 相关代码
public E set(int index, E element) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
E oldValue = get(elements, index);
if (oldValue != element) {
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len);
newElements[index] = element;
setArray(newElements);
} else {
// Not quite a no-op; ensures volatile write semantics
setArray(elements);
}
return oldValue;
} finally {
lock.unlock();
}
}
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
public E remove(int index) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
E oldValue = get(elements, index);
int numMoved = len - index - 1;
if (numMoved == 0)
setArray(Arrays.copyOf(elements, len - 1));
else {
Object[] newElements = new Object[len - 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index + 1, newElements, index,
numMoved);
setArray(newElements);
}
return oldValue;
} finally {
lock.unlock();
}
}
Map
HashTable
HashTable底层通过Entry数组存储元素,
private transient Entry[] table;- 其中
Entry类型为HashTable自定义的数据结构,内部记录了元素的hash值,key,value,以及下一节点的指针next。
private static class Entry implements Map.Entry {
final int hash;
final K key;
V value;
Entry next;
protected Entry(int hash, K key, V value, Entry next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
@SuppressWarnings("unchecked")
protected Object clone() {
return new Entry<>(hash, key, value,
(next==null ? null : (Entry) next.clone()));
}
// Map.Entry Ops
public K getKey() {
return key;
}
public V getValue() {
return value;
}
public V setValue(V value) {
if (value == null)
throw new NullPointerException();
V oldValue = this.value;
this.value = value;
return oldValue;
}
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
return (key==null ? e.getKey()==null : key.equals(e.getKey())) &&
(value==null ? e.getValue()==null : value.equals(e.getValue()));
}
public int hashCode() {
return hash ^ Objects.hashCode(value);
}
public String toString() {
return key.toString()+"="+value.toString();
}
} HashMap
HashMap底层通过 Node数组存储元素
transient Node[] table; - 其中
Node是HashMap自定义的数据结构,内部记录了元素的hash值,key,value,以及下一节点的指针next。
static class Node implements Map.Entry {
final int hash;
final K key;
V value;
Node next;
Node(int hash, K key, V value, Node next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry e = (Map.Entry)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
} 当元素hash相同时,元素会通过链表的形式通过next指针相连。在JDK1.8之后,当满足一定条件后,链表会转化为红黑树,此时,元素会从Node类型转化为TreeNode类型。
TreeNode为HashMap自定义的数据结构,内部记录父节点parent,左右孩子left,right,颜色标志red已经同级前驱节点prev
static final class TreeNode extends LinkedHashMap.Entry {
TreeNode parent; // red-black tree links
TreeNode left;
TreeNode right;
TreeNode prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node next) {
super(hash, key, val, next);
}
......
} 具体的操作逻辑可以参考:[[HashMap]]
LinkedHashMap
LinkedHashMap继承了HashMap的逻辑,只不过添加了Entry结构。以及head,tail首尾指针。
static class Entry extends HashMap.Node {
Entry before, after;
Entry(int hash, K key, V value, Node next) {
super(hash, key, value, next);
}
}
private static final long serialVersionUID = 3801124242820219131L;
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry tail; Entry中保存了before和after指针,指向上一个插入元素Entry以及后一个插入元素Entry。以数组+红黑树+元素链表+插入顺序链表的形式存储数据。
ConcurrentHashMap
ConcurrentHashMap底层通过Node数组存储数据
transient volatile Node[] table; - 其中
Node是ConcurrentHashMap自定义的数据结构,内部记录了元素的hash值,key,value,以及下一节点的指针next。
static class Node implements Map.Entry {
final int hash;
final K key;
volatile V val;
volatile Node next;
Node(int hash, K key, V val, Node next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final String toString(){ return key + "=" + val; }
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
public final boolean equals(Object o) {
Object k, v, u; Map.Entry e;
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry)o).getKey()) != null &&
(v = e.getValue()) != null &&
(k == key || k.equals(key)) &&
(v == (u = val) || v.equals(u)));
}
/**
* Virtualized support for map.get(); overridden in subclasses.
*/
Node find(int h, Object k) {
Node e = this;
if (k != null) {
do {
K ek;
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
} 当元素hash相同时,元素会通过链表的形式通过next指针相连。在JDK1.8之后,当满足一定条件后,链表会转化为红黑树,此时,table数组中的Node 元素会转化为TreeBin类型,TreeBin类型记录了由TreeNode构成红黑树的根节点root。
TreeBin有ConcurrentHashMap自定义,继承了Node类型。存放了下辖红黑树的根节点root。
static final class TreeBin extends Node {
TreeNode root;
volatile TreeNode first;
volatile Thread waiter;
volatile int lockState;
// values for lockState
static final int WRITER = 1; // set while holding write lock
static final int WAITER = 2; // set when waiting for write lock
static final int READER = 4; // increment value for setting read lock
......
} TreeNode由ConcurrentHashMap自定义,跟HashMap的TreeNode类似,但是ConcurrentHashMap的TreeNode继承自Node类型。
static final class TreeNode extends Node {
TreeNode parent; // red-black tree links
TreeNode left;
TreeNode right;
TreeNode prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node next,
TreeNode parent) {
super(hash, key, val, next);
this.parent = parent;
}
......
} 具体的操作逻辑可以参考:[[ConcurrentHashMap]]
TreeMap
TreeMap 通过Entry存储数据,底层是以红黑树的逻辑结构存储。
private transient Entry root; Entry是TreeMap自定义的数据结构,其中包含key,value,左右子树left,right,以及父节点parent,和标记颜色的color;
static final class Entry implements Map.Entry {
K key;
V value;
Entry left;
Entry right;
Entry parent;
boolean color = BLACK;
/**
* Make a new cell with given key, value, and parent, and with
* {@code null} child links, and BLACK color.
*/
Entry(K key, V value, Entry parent) {
this.key = key;
this.value = value;
this.parent = parent;
}
......
} WeakHashMap
WeakHashMap底层通过Entry[] 数组存储数据,采用链表法解决hash冲突,跟HashMap 不同没有进行长链表的红黑树转化。
Entry[] table; Entry为WeakHashMap自定义的数据结构继承了WeakReference,其中包含value,hash值,以及next指针。key为弱引用reference的值。
private static class Entry extends WeakReference 具体的操作逻辑可以参考:[[WeakHashMap]]
ConcurrentSkipListMap
ConcurrentSkipListMap底层通过跳表的数据结构提高查找效率。ConcurrentSkipListMap通过Node存储基本的key,value数据,Index存储跳表索引,HeadIndex为层级头索引。
// Node存储基本的key,value数据,是一个简单的链表
static final class Node {
final K key;
volatile Object value;
volatile Node next;
...
}
// Index 内包含Node元素,以及向下和向右的Index指针
static class Index {
final Node node;
final Index down;
volatile Index right;
...
}
// HeadIndex继承了Index,添加了level索引层级属性
static final class HeadIndex extends Index {
final int level;
HeadIndex(Node node, Index down, Index right, int level) {
super(node, down, right);
this.level = level;
}
} 同时,ConcurrentSkipListMap通过对大部分操作添加CAS锁防止并发。
Set
HashSet
HashSet底层默认通过HashMap存储元素,数据储存在HashMap的key中,value设置为默认值Object。
private transient HashMap map;
private static final Object PRESENT = new Object(); // default value
public boolean add(E e) {
return map.put(e, PRESENT)==null;
} HashSet 底层还可以通过 LinkedHashMap 存储元素。根据构造函数参数不同选择是 HashMap还是LinkedHashMap实现。
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}LinkedHashSet
LinkedhashSet继承了HashSet,采用LinkedHashMap存储元素。
ConcurrentSkipListSet
底层通过ConcurrentSkipListMap实现,存放的值作为key存入ConcurrentSkipListMap中,使用Boolean.TRUE对象最为默认的value。
private final ConcurrentNavigableMap m;
/**
* Constructs a new, empty set that orders its elements according to
* their {@linkplain Comparable natural ordering}.
*/
public ConcurrentSkipListSet() {
m = new ConcurrentSkipListMap();
}
public boolean add(E e) {
return m.putIfAbsent(e, Boolean.TRUE) == null;
} TreeSet
TreeSet底层通过TreeMap存储元素,和HashSet类似,数据存储在TreeMap 的Key中,value设置为默认值Object。
private transient NavigableMap m;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public TreeSet(Comparator comparator) {
this(new TreeMap<>(comparator));
} CopyOnWriteArraySet
底层通过CopyOnWriteArrayList实现,通过List.addIfAbsent()方法实现同一个元素只存在一个,保证了元素的唯一性。
private final CopyOnWriteArrayList al;
/**
* Creates an empty set.
*/
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList();
}
public boolean add(E e) {
return al.addIfAbsent(e);
} Queue
PriorityQueue
PriorityQueue优先队列,底层通过Object数组存储元素,Object[]以层次遍历的形式存储优先队列(完全二叉树)的元素值。索引n的左右孩子索引分别为$2n+1,2*(n+1)$;
transient Object[] queue;BlockingQueue
A Queue that additionally supports operations that wait for the queue to become non-empty when retrieving an element, and wait for space to become available in the queue when storing an element.
阻塞队列接口,提供了额外的一些操作,当这些操作无法立即执行时(插入时容量满了、删除/获取元素时队列为空),不会像正常的queue一些立即返回而是阻塞一段时间直到满足条件(设置了等待时间、条件满足了)
阻塞队列的阻塞操作一般是通过创建多个条件锁ReentrantLock.Condition实现的,通过调用Condition.await()以及Condition.signal()进行线程的阻塞和唤醒。
private final Condition notEmpty;
/** Condition for waiting puts */
private final Condition notFull;添加元素
add(E e)/offer(E e)方法,当数组满了之后,直接返回falsepublic boolean offer(E e) { checkNotNull(e); final ReentrantLock lock = this.lock; lock.lock(); try { if (count == items.length) return false; else { enqueue(e); return true; } } finally { lock.unlock(); } }put(E e)/offer(E e, long timeout, TimeUnit unit)方法,当数组满了之后,阻塞直到唤醒或者阻塞指定时间public void put(E e) throws InterruptedException { checkNotNull(e); final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { while (count == items.length) notFull.await(); enqueue(e); } finally { lock.unlock(); } } public boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException { checkNotNull(e); long nanos = unit.toNanos(timeout); final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { while (count == items.length) { if (nanos <= 0) return false; nanos = notFull.awaitNanos(nanos); } enqueue(e); return true; } finally { lock.unlock(); } }
获取元素
poll(),弹出队首元素,队列为空时直接return null;take(),弹出队首元素,队列为空时阻塞至队列不为空。poll(long timeout, TimeUnit unit),弹出队首元素,队列为空时阻塞指定时间后重试一次。peek(),获取队首元素,队列为空时直接return null;
ArrayBlockingQueue
A bounded BlockingQueue backed by an array. This queue orders elements FIFO (first-in-first-out). The head of the queue is that element that has been on the queue the longest time. The tail of the queue is that element that has been on the queue the shortest time. New elements are inserted at the tail of the queue, and the queue retrieval operations obtain elements at the head of the queue.
顾名思义,ArrayBlockingQueue底层是通过Object[]数组实现元素的存储的。ArrayBlockingQueue是有界队列,存储元素的数量通过初始化方法指定。当数组满了的时候,就无法直接往数组中添加元素了。ArrayBlockingQueue FIFO,添加元素到队尾,删除队首元素。
初始化方法
public ArrayBlockingQueue(int capacity, boolean fair) { if (capacity <= 0) throw new IllegalArgumentException(); this.items = new Object[capacity]; lock = new ReentrantLock(fair); notEmpty = lock.newCondition(); notFull = lock.newCondition(); }
LinkedBlockingQueue
根据初始化参数动态构造是否有界的阻塞队列。底层通过Node结构实现的链表进行存储。
Node结构
static class Node{ E item; Node next; Node(E x) { item = x; } } 初始化方法
public LinkedBlockingQueue() { // 不指定队列容量,默认为Integer的最大值 this(Integer.MAX_VALUE); } public LinkedBlockingQueue(int capacity) { if (capacity <= 0) throw new IllegalArgumentException(); this.capacity = capacity; last = head = new Node(null); }
ArrayBlockingQueue 和LinkedBlockingQueue除了底层实现方式不同之外,ArrayBlockingQueue在进行数据操作时用的都是同一把锁final ReentrantLock lock;,而LinkedBlockingQueue初始化了二把锁插入和弹出操作使用不同的锁。final ReentrantLock putLock; final ReentrantLock takeLock;