作者:实验室小陈 / 大数据开放实验室
在上一篇文章《内存数据库解析与主流产品对比(二)》中,我们从数据组织和索引的角度介绍了内存数据库的特点和几款产品的技术实现。本文将继续解析内存数据库,从并发控制、持久化和查询处理的角度介绍几款技术,带来更多维度、更细致的内存数据库技术讨论。
— 数据库管理系统中的并发控制—
1. 内存数据库并发控制的两种策略
a. 多版本的并发控制
内存数据库中的并发控制主要采用两类策略:1. 多版本的并发控制;2. 分Partition处理。并发控制机制可以分为乐观和悲观两种类型。悲观并发控制则认为进程竞争资源总是存在的,因此访问时先加锁,访问完再释放;乐观并发控制认为大多数情况不需要竞争资源,只在最后提交前检查是否存在冲突,有冲突就回滚,没有就提交。
乐观并发控制大多数不采用基于锁的技术实现,并且通常是多版本的。多版本意味着每次更新都会产生新的版本,读操作根据可见范围选取合适的老版本,读操作不阻塞写操作,所以并发程度比较高。其缺点是会产生额外开销,例如更新要创建新版本,而且随着版本越来越多,还需要额外开销收回老版本。内存数据库多采用乐观的多版本并发控制机制,相比于基于锁的悲观并发控制其优势是开销较小,而且支持并发程度较高的场景;缺点是在有大量写竞争的场景下,事务间冲突概率比较高时,大量事务会失败和回滚。
b. 分Partition处理
内存数据库并发控制的另外一类策略是把数据库分成多个Partition,每个Partition采用串行方式处理事务。优势是单Partition业务的执行没有用于并发控制的额外开销,缺点是存在跨Partition事务时系统的吞吐率会直线下降。因此,如果不能保证所有业务都是单Partition进行,将导致性能不可预测。
2. 多版本并发控制之 Hekaton
Hekaton采用乐观的多版本并发控制。Transaction开始时,系统为事务分配读时间戳,并将Transaction标记为active,然后开始执行事务,在操作过程中系统记录被读取/扫描/写入的数据。随后,在Pre-commit阶段,先获取一个结束的时间戳,然后验证读和扫描数据的版本是否仍然有效。如果验证通过,就写一个新版本到日志,执行Commit,然后把所有的新版本设置为可见。Commit之后,Post-Processing记录版本时间戳,之后Transaction才真正结束。

a. Hekaton 的事务验证
i) Read Stability:Hekaton系统能够保证数据的读稳定性(Read Stability),比如交易开始时读到的每条记录版本,在Commit时仍然可见,从而实现Read Stability。
ii) Phantom Avoidances:Phantom指一个事务在开始和结束时执行相同的条件查询,两次结果不一样。出现幻影的原因是该事务执行过程中,其他事务对相同数据集进行了增加/删除/更新操作。应该如何避免幻影现象呢?可通过重复扫描,检查所读取的数据是否有新版本,保证记录在事务开始时的版本和在结束时一致。
Hekaton并发控制的好处在于,不需要对Read-Only事务做验证,因为多版本能够保证事务开始时的记录版本在结束时依然存在。对于执行更新的事务,是否做验证由事务的隔离级别决定。例如如果快照隔离级别,就不需要做任何验证;如果要做可重复读,就要做Read Stability;如果是串行化隔离级别,既要保证Read Stability,又要保证Phantom Avoidance。
b. Hekaton的回收策略
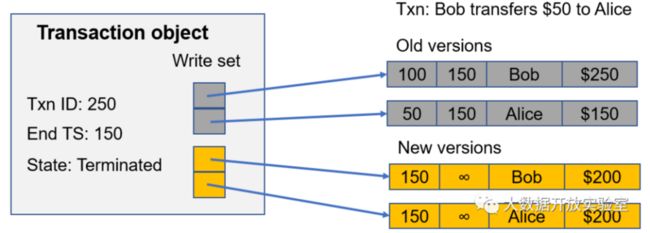
Hekaton中的回收任务并不由独立的线程处理,而是每个事务自己回收。如下图所示,Transaction ID为250的事务结束时间戳为150且状态为terminated,此时会有一个Write Set获取所有老版本,并判断当前所有active的Transaction的开始时间戳是否大于ID为250的事务结束时间,即150。如果都大于150,说明不可能再基于时间戳早于150的旧版本进行修改,因而由事务回收旧版本,这部分工作是每个线程在处理Transaction时的额外工作。
3. 多版本并发控制之Hyper
Hyper的并发控制和Hekaton的区别主要有以下三点:1. 直接在记录位置进行更新,通过undo buffer来保存对数据的修改,数据和所有修改被链接在一起;2. 验证是根据最近的更新与读的记录进行比较来实现(后续会涉及到);3. 串行化处理commit,对提交的事务进行排序,并依次处理。
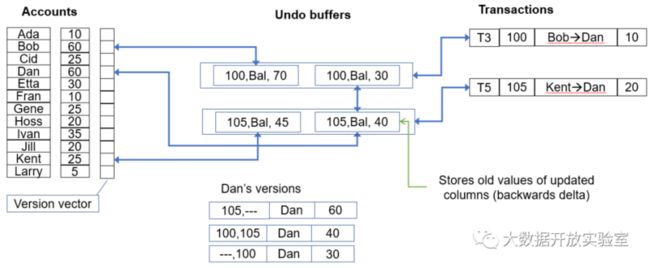
在事务验证方面,Hyper的验证需要在日志中记录Read Predictates,包括查询或Range Scan,而且要记录插入、删除和更新的记录。在Hyper模式中,插入/删除/更新通过对应的Undo Buffer获悉被修改过的记录,所以记录改动对于Hyper而言是容易的。
对于每个Transaction,只需要比较该事务从开始到Commit之间,是否存在其他Transaction对满足搜索条件的数据集进行过增/删/改,从而判断是否存在幻影现象,如果存在,就直接终止事务。
4. 多版本并发控制之HANA和HStore/VoltDB
HANA并行控制方式比较简单,采用悲观的多版本控制,由行级锁保护数据结构,每行由时间戳决定每个版本的可见范围。每个Transaction在更新或删除时都需要申请写锁,而且要做死锁检测。
HStore/VoltDB是一个Partition系统,锁的粒度很粗,每个Partition对应一把锁,因此Transaction在某节点上执行时,需要拿到该节点所有资源。一旦一个事务可能涉及到两个Partition,就需要把两个Partition的锁都拿到。所以Partition系统的优点是单Partition处理速度非常快,缺点是多Partition效率很低。同时,系统对于负载的偏斜非常敏感,如果有热点数据,那么热点数据就构成系统瓶颈。
5. 多版本并发控制之负载预知
假设一个工作负载中,事务需要读和写的数据集可以提前获得,就可以在执行前确定所有事务的执行顺序。Calvin就是基于这样的假设设计的VLL (Very Lightweight Locking)超轻量级锁数据库原型系统。通用场景的工作负载是无法提前知道读写集合的,但在存储过程业务的应用中,可以提前确定读写集合,对于这些场景就可以考虑类似Calvin的系统。
— 数据库管理系统中的持久化技术—
对于内存数据库而言,和基于磁盘的数据库相同也需要日志和Checkpoint。Checkpoint的目的是恢复可以从最近的检查点开始,而不需要回放所有数据。因为Checkpoint涉及写入磁盘的操作,所以影响性能,因此要尽量加快相关的处理。
一个不同是内存数据库的日志和Checkpoint可以不包含索引,在恢复时通过基础数据重新构造索引。内存数据库中的索引在恢复时重新构造,构造完成后也放在内存中而不用落盘,内存索引数据丢失了再重构即可。另外一个不同是内存数据库Checkpoint的数据量更大。面向磁盘的数据库在Checkpoint时,只需要把内存中所有Dirty Page写到磁盘上即可,但是内存数据库Checkpoint要把所有数据全部写到磁盘,数据量无论多大都要全量写一遍,所以内存数据库Checkpoint时写入磁盘的数据远大于基于磁盘的数据库。
Hekaton Checkpoint
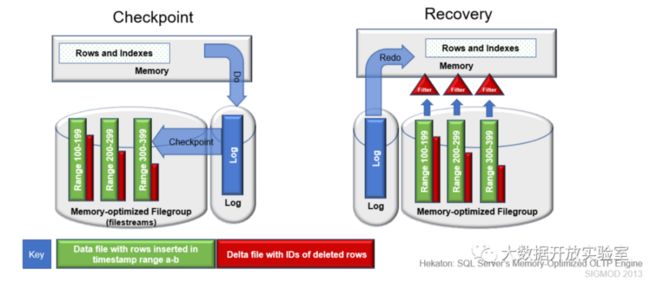
对于持久化的性能优化,第一要保证写日志时的高吞吐量和低延迟,第二要考虑恢复时如何快速重构整个数据库。Hekaton的记录和索引存放在内存,所有操作写日志到磁盘。日志只记录数据的更新,而不记录索引的更新。进行Checkpoint时,Hekaton会从日志中恢复,并根据主键范围并行处理。如下图,分三个主键范围:100~199、200~299、300~399,绿色代表数据,红色代表删除的记录(单独保存被删除的文件)。在恢复时,Hekaton用并行算法在内存中重构索引和数据,过程中根据删除记录过滤数据文件,去除被删除的数据,然后从Checkpoint点开始,根据日志回放数据。
其他系统的Checkpoints
- 采用Logic Logging的系统如H-Store/VoltDB,即不记录具体的数据改动,而是记录执行过的操作、指令。它的优势是记录的日志信息比较少。写日志时,HStore/VoltDB采用COW(Copy-on-Write)模式,即正常状态是单版本,但在写日志时会另外“复制”一个版本,待写完再合并版本。
- 另一种是定期把Snapshot写入磁盘(不包括索引),比如Hyper就是基于操作系统Folk功能来提供Snapshot。
— 数据库管理系统中的查询处理—
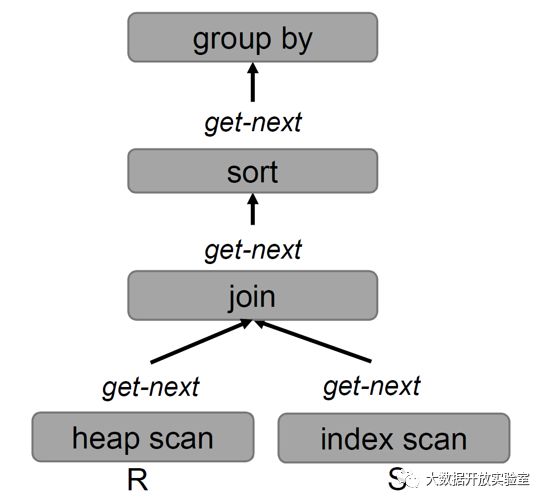
传统的查询处理采用火山模型,查询树上的每个节点是一个通用的Operator,优势在于Operator可以任意组合。但Operator拿到的记录只是一个字节数组,还需要调用另一个方法来解析属性以及属性类型。如果这种设计放到内存数据库中,属性以及类型的解析都是在Runtime而非编译时进行的,会对性能产生影响。
另外对于get-next,如果有百万个数据就要调用百万次,同时get-next通常实现是一个虚函数,通过指针调用,相比直接通过内存地址调用,这些都会影响性能。此外,这样的函数代码在内存中的分布是非连续的,要不断跳转。综上,传统DBMS的查询处理方式在内存数据库当中并不适用,尤其体现在在底层执行时。
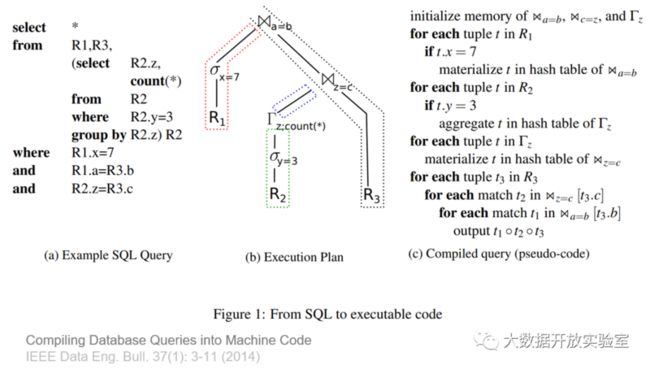
内存数据库通常采用编译执行的方式,首先对查询进行解析,然后优化解析后的语句,并生成执行计划,然后根据模板对执行计划进行编译产生可执行的机器代码,随后把机器代码加载到数据库引擎,执行时直接调用。
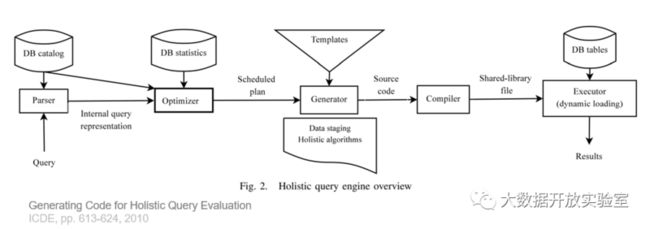
下图是对不同查询方式的耗时分析,可以看出编译执行方式中Resource Stall的占比很少。
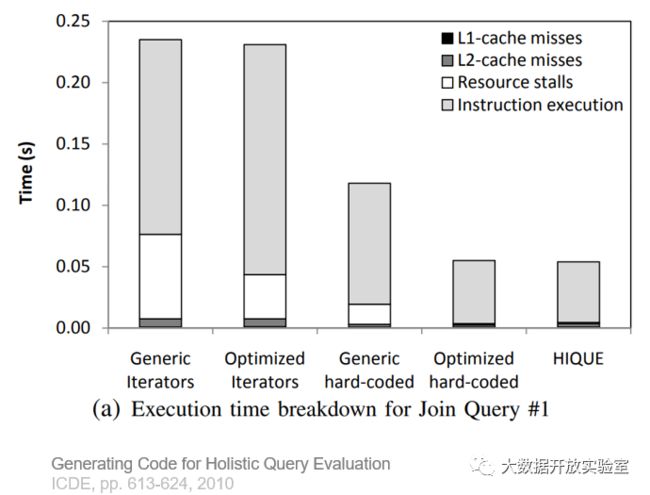
另外一张图解释了目前的CPU架构实现,L2 Cache和主存之间存在Hardware Pre-fetcher。L2 Cache分为指令Cache和Data Cache,指令Cache会由Branch Prediction实现分支预测,Data Cache会由基于Sequential Pattern的Pre-fetcher实现预测。因此,数据库系统的设计需要考虑该架构下如何充分发挥Pre-fetcher功能,让Cache可以不断为 CPU计算单元提供指令和数据,避免出现Cache Stall。
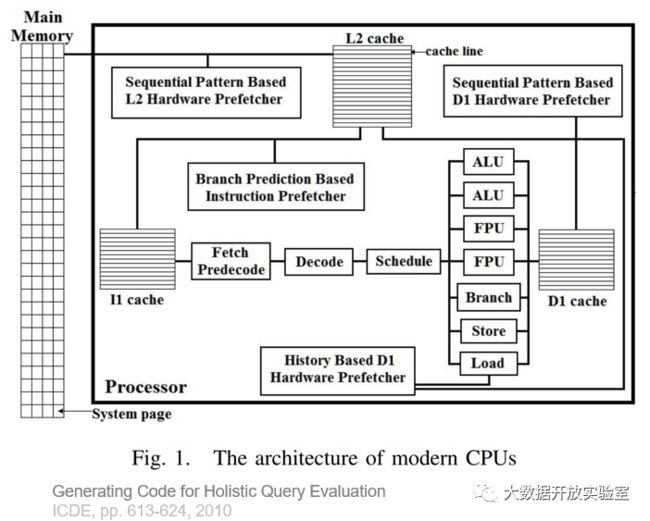
Hekaton编译查询处理
Hekaton的编译采用T-SQL存储过程,编译的中间形式叫做MAT Generator,生成最终的C代码在编译器中执行。它产生的库和通用Operator的区别在于:通用Operator需要在运行时解释数据类型;而Hekaton编译方式是把表的定义和查询编译在一起,每个库只能处理对应的表而不能通用,自然就能拿到数据类型,这样的实现能获得3~4倍的性能提升。
HyPer和MemSQL编译查询处理
HyPer的编译方式是把查询树按照Pipeline的分割点每段编译。而MemSQL采用LLVM做编译,把MPI语言编译成代码。
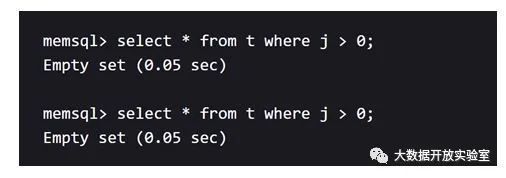
下图是一个对MemSQL性能的测试。没有采用编译执行时,MemSQL两次执行相同查询的时间都是0.05秒;如果采用编译执行,第一次耗时0.08秒,但是再执行时耗时仅0.02秒。

— 其他内存数据库系统—
除了之前提到的几种内存数据库外,还有其他一些著名的内存DBMS出现。
i) SolidDB:诞生于1992年的混合型数据库系统,同时具备基于磁盘和内存的优化引擎,使用VTRIE(Variable-length Trie)树索引和悲观锁机制进行并发控制,通过Snapshot Checkpoints恢复。
ii) Oracle Times Ten:早期是惠普实验室名为Smallbase的研究项目,在2005年被Oracle收购,现在多作为大型数据库系统的前端内存加速引擎。Oracle Times Ten支持灵活部署,具有独立的DBMS引擎和基于RDBMS的事务缓存;在BI工作时支持Memory Repository,通过Locking进行并发控制;使用行级Latching处理写冲突,采用Write-Ahead Logging和Checkpoint机制提高持久性。
iii) Altibase:于1999年在韩国成立,在电信、金融和制造业应用广泛。Altibase在Page上存储记录,以Page为粒度进行Checkpoint且兼容传统DBMS引擎;支持多版本并发控制,使用预写日志记录和检查点实现持久性和恢复能力,通过Latching-Free对Page的数据进行Checkpoint。
iv) PTime: 21世纪起源于韩国,2005年出售给SAP,现在是SAP HANA的一部分。PTime具备极佳的性能处理,对日志记录使用差分编码(XOR),采用混合存储布局,支持大于内存(Larger-than-Memory)的数据库管理系统。
— 本文小结—
每一个数据库系统都是针对特定的硬件环境设计,基于磁盘的数据库系统面临CPU单核、内存小、磁盘慢的场景设计。而内存数据库以内存为主存,不需要再重复读写磁盘,磁盘I/O不再是性能瓶颈,而要解决其他瓶颈,比如:1. Locking/Latching的开销;2. Cache-Line Miss,即如果数据结构定义的不够好或在内存中组织的不好,无法匹配CPU的层级缓存,会导致计算性能变差;3. Pointer Chasing,即需要另一个指针解释,或者查另外的表才能查到记录地址,也是主要的性能开销。此外,还有Predicate Evaluation计算、数据迁移/存储时的大量拷贝、分布式系统应用与数据库系统的网络通信等开销。
在本专栏中,我们介绍了传统基于磁盘的DBMS和内存数据库的特点,并从数据组织、索引、并发控制、语句处理编译、持久化几个方面对内存数据库与基于磁盘数据库的相同和差异性进行了介绍:
1. 数据组织:内存数据库中,把记录分成定长和变长管理,不需要数据连续存储,用指针替代了Page ID + Offset的间接访问;
2. 索引优化:考虑面向内存中的Cach Line优化、快速的内存访问等Latch-Free技术,以及索引的更新不记录日志等;
3. 并发控制:可以采用悲观和乐观的并发控制方式,但是与传统基于磁盘数据库的区别是,内存数据库锁信息和数据绑定,而不用单独的Lock Table管理;
4. 查询处理:内存数据库场景下的顺序访问和随机访问性能差别不大。可以通过编译执行提高查询性能;
5. 持久化:仍然通过WAL(Write-Ahead Logging)做Logging,并采用轻量级的日志,日志记录的内容尽量少,目的是降低日志写入磁盘延迟。
内存数据库从1970s开始出现经历了理论成熟、投入生产、市场验证等发展环节。随着当前互联网秒杀、移动支付、短视频平台等高并发、大流量、低时延的平台出现,对于数据库性能提出了巨大需求和挑战。同时,内存本身在容量、单位价格友好度上不断提升,以及近期非容失性存储(NVM)的发展,促进了内存数据库的发展,这些因素使得内存数据库在未来有着广阔的市场和落地机会。
注:本文相关内容参照以下资料:
1. Pavlo, Andrew & Curino, Carlo & Zdonik, Stan. (2012). Skew-aware automatic database partitioning in shared-nothing, parallel OLTP systems. Proceedings of the ACM SIGMOD International Conference on Management of Data. DOI: 10.1145/2213836.2213844.
2. Kemper, Alfons & Neumann, Thomas. (2011). HyPer: A hybrid OLTP&OLAP main memory database system based on virtual memory snapshots. Proceedings - International Conference on Data Engineering. 195-206. DOI: 10.1109/ICDE.2011.5767867.
3. Faerber, Frans & Kemper, Alfons & Larson, Per-Åke & Levandoski, Justin & Neumann, Tjomas & Pavlo, Andrew. (2017). Main Memory Database Systems. Foundations and Trends in Databases. 8. 1-130. DOI: 10.1561/1900000058.
- Sikka, Vishal & Färber, Franz & Lehner, Wolfgang & Cha, Sang & Peh, Thomas & Bornhövd, Christof. (2012). Efficient Transaction Processing in SAP HANA Database –The End of a Column Store Myth. DOI: 10.1145/2213836.2213946.
5. Diaconu, Cristian & Freedman, Craig & Ismert, Erik & Larson, Per-Åke & Mittal, Pravin & Stonecipher, Ryan & Verma, Nitin & Zwilling, Mike. (2013). Hekaton: SQL server's memory-optimized OLTP engine. 1243-1254. DOI: 10.1145/2463676.2463710.