作者|Behic Guven
编译|VK
来源|Towards Data Science

在这篇文章中,我将向你介绍一种称为监督学习的机器学习方法。我将向你展示如何使用Scikit-learn构建kNN分类器模型。
这将是一个实践演练,我们将能够在实践知识的同时学习。作为我们的分类器模型,我们将使用k-NN算法模型,这将在引言部分进行更多介绍。作为编程语言,我们将使用Python。
阅读本教程后,你将更好地了解深度学习和监督学习模型的工作原理。
目录
- 监督学习
- 库
- 了解数据
- kNN分类器模型
- 过拟合与欠拟合
- 结论
监督学习
深度学习是一门科学,它使计算机能够在没有明确编程的情况下从数据中得出结论。比如学会预测电子邮件是否是垃圾邮件。另一个很好的例子是通过观察花的图片将它们分为不同的类别。

在监督学习中,数据分为两部分:特征和目标变量。任务是通过观察特征变量来预测目标变量。监督学习可用于两种不同的模型:分类和回归
当目标变量是分类数据集时,可以使用分类模型。
当目标变量是连续值时,使用回归模型。
库
在这一步中,我们将安装本教程所需的库。正如引言中提到深度学习lib库的主要知识库。除此之外,我们将安装两个简单的库,它们是NumPy和Matplotlib。使用PIP(python包管理器)可以很容易地安装库。
安装库
进入终端窗口,开始安装过程:
pip install scikit-learn现在让我们安装其他两个库:
pip install numpy matplotlib导入库
很完美!现在让我们将它们导入到我们的程序中,以便使用它们。我将在本教程中使用Jupyter Notebook。因此,我创建了一个新的Notebook并导入了以下库模块。
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np了解数据
在本练习中,我们将使用数字数据。它也被称为MNIST。这是一个著名的数据开始建立一个监督学习模型。这个数据的好处是我们不必下载任何东西;它是随我们先前安装的sklearn模块一起提供的。下面是如何加载数据集:
digits = datasets.load_digits()现在,让我们试着对运行几行的数据集有一些了解。
print(digits.keys)
Bunch是一个提供属性样式访问的Python字典。Bunch就像字典。
print(digits.DESCR)
plt.imshow(digits.images[1010], cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()
K近邻分类器
在库步骤中,我们已经在库步骤中导入了k-NN分类器模块。所以,我们要做的就是在我们的数据集中使用它。这一步是在项目中使用sklearn模块的一个很好的练习。因为我们正在进行监督学习,所以数据集必须被标记。这意味着在训练数据时,我们也传递结果。
k-最近邻算法(k-NN)是一种用于分类和回归的非参数方法。在这两种情况下,输入由特征空间中k个最近的训练样本组成。输出取决于k-NN是用于分类还是回归。”(参考:https://en.wikipedia.org/wiki...
特征和目标变量
我们从sklearn数据集导入的数字数据有两个属性,即data和target。我们首先将这些部分分配给我们的新变量。我们把特征(数据)称为X和标签(目标)称为y:
X = digits.data
y = digits.target拆分数据
接下来,我们将使用train_test_split方法来分割数据部分。与其对整个数据进行训练,不如将其拆分为训练和测试数据,以审查模型的准确性。这将在下一步更有意义,我们将看到如何使用一些方法改进预测。
#test size 是指将数据集中作为测试数据的比率,其余将是训练数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=42, stratify=y)定义分类器
knn = KNeighborsClassifier(n_neighbors = 7)拟合模型
knn.fit(X_train, y_train)准确度得分
print(knn.score(X_test, y_test))
我来给你看看这个分数是怎么计算的。首先,我们使用knn模型对X_test特征进行预测。然后与实际标签进行比较。以下是在后台实际计算准确度的方法:
y_pred = knn.predict(X_test)
number_of_equal_elements = np.sum(y_pred==y_test)
number_of_equal_elements/y_pred.shape[0]
过拟合与欠拟合
以下是我在Amazon机器学习课程文档中发现的模型过拟合和欠拟合的一个很好的解释:
“当模型在训练数据上表现不佳时,模型对训练数据的拟合不足。这是因为模型无法捕获输入示例(特性)和目标值(标签)之间的关系。当你看到模型在训练数据上表现良好,但在评估数据上表现不佳时,该模型会过拟合你的训练数据。这是因为模型正在记忆它所看到的数据,并且无法将其推广到未看到的示例中。”(参考: https://docs.aws.amazon.com/m...
现在,让我们编写一个for循环,它将帮助我们了解数据在不同的邻居值中的表现。此函数还将帮助我们分析模型的最佳性能,这意味着更准确的预测。
neighbors = np.arange(1, 9)
train_accuracy = np.empty(len(neighbors))
test_accuracy = np.empty(len(neighbors))
for i, k in enumerate(neighbors):
# 定义knn分类器
knn = KNeighborsClassifier(n_neighbors = k)
# 将分类器与训练数据相匹配
knn.fit(X_train, y_train)
# 在训练集上计算准确度
train_accuracy[i] = knn.score(X_train, y_train)
# 在测试集上计算准确度
test_accuracy[i] = knn.score(X_test, y_test)现在,让我们用图形表示结果:
plt.title('k-NN: Performance by Number of Neighbors')
plt.plot(neighbors, test_accuracy, label = 'Testing Accuracy')
plt.plot(neighbors, train_accuracy, label = 'Training Accuracy')
plt.legend()
plt.xlabel('# of Neighbors')
plt.ylabel('Accuracy')
plt.show()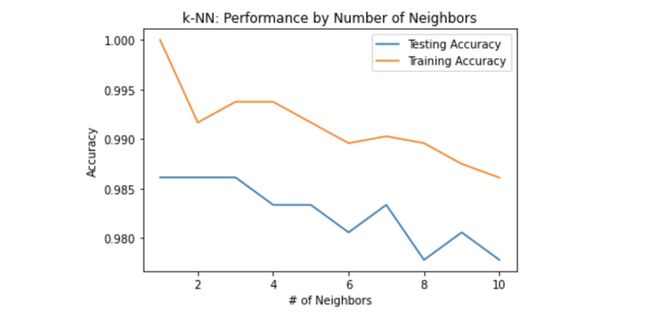
这个图证明了更多的邻居并不总是意味着更好的性能。当然,这主要取决于模型和数据。在我们的例子中,正如我们所看到的,1-3个邻居准确度是最高的。之前,我们用7个邻居训练了knn模型,得到了0.983的准确度。所以,现在我们知道我们的模型在两个邻居的情况下表现更好。让我们重新训练我们的模型,看看我们的预测将如何改变。
knn = KNeighborsClassifier(n_neighbors = 2)
knn.fit(X_train, y_train)
print(knn.score(X_test, y_test))
结论
很完美!你已经使用scikit learn模块创建了一个监督学习分类器。我们还学习了如何检查分类器模型的性能。我们还学习了过拟合和欠拟合,这使我们能够改进预测。深度学习是如此有趣和神奇。我将分享更多深入学习的文章。敬请期待!
原文链接:https://towardsdatascience.co...
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/