客座文章最初由Kevin LeimkuhLer在Buoyant的博客上发布
有了服务网格,SLO就容易多了
在本教程中,你将学习如何使用Prometheus(一个开源时间序列数据库)和Linkerd(一个开源超轻服务网格)在Kubernetes上轻松创建服务运行状况SLO。你将看到如何使用服务网格解决SLO中最困难的部分之一:为你想要度量的东西获得一致的度量标准。
但在我们开始之前,让我们先深入了解一下为什么SLO和Kubernetes会携手并进。
Kubernetes和服务网格的一个SLO案例
SLO,或者服务级别目标(service level objective),最近已经成为描述应用程序可靠性的流行工具。正如谷歌SRE书中所描述的,SLO是应用程序开发人员和SRE团队明确捕获应用程序风险容忍度的一种方法,通过定义可接受的失败级别,然后根据该决策做出风险vs回报的决策。
对于平台所有者,他们较少关注应用程序,更多关注底层平台,SLO还有另一个用途:它们提供了一种方法,可以了解平台上运行的服务的健康状况,而无需了解任何有关其运营历史的信息。这在Kubernetes中特别有用,在Kubernetes中,你可能在几十个集群中运行数百或数千个服务。你不需要了解每个服务的操作上下文,而可以使用SLO作为获得上下文无关判断的一种方法。(参见SLO vs Kubernetes指标)。
令人高兴的是,在Kubernetes上获得服务运行状况方面的SLO比你想象的要容易得多。这是因为SLO最难的部分之一是获得一致的、统一的度量,而这正是服务网格所做的!例如,Linkerd为你所有的服务提供了一个统一的、一致的黄金度量层--成功率、延迟、请求量--并且不需要任何配置。有了Linkerd的指标在手,获得基本的服务运行状况SLO就可以归结为做一些计算。
(当然,服务网格并不是SLO的完整解决方案,因为它不能捕获应用程序特定指标之类的东西。但对于常见的服务运行状况度量,如成功率和延迟,至少可以通过提取服务网格数据轻松构建服务运行状况SLO。)
让我们用一个演示用例来动手吧。
用Linkerd和Prometheus计算SLO
在本教程中,我们将看到如何为在Kubernetes上运行的gRPC服务设置一个滚动窗口的基本成功率SLO。当然,我们这里使用的技术同样适用于不同类型的指标和SLO。
首先,让我们回顾一下Linkerd如何捕捉它的黄金指标。当Linkerd被添加到服务中时,它会自动记录对服务pod的任何HTTP和gRPC调用。它记录这些调用的响应类和延迟,并将它们聚合到Prometheus的一个内部实例中。这个Prometheus实例为Linkerd的仪表板和CLI提供动力,并包含所有网格服务的观察黄金指标
因此,为了达到我们的目标,我们需要将存储在Linkerd的Prometheus中的成功率指标转换为SLO。
安装:访问Kubernetes集群并安装Linkerd CLI
让我们从最基本的开始。我们假设你有一个运行的Kubernetes集群和一个指向它的kubectl命令。在本节中,我们将带你完成Linkerd入门指南的简化版,以在这个集群上安装Linkerd和一个演示应用程序。
首先,安装Linkerd CLI:
curl -sL https://run.linkerd.io/install | sh
export PATH=$PATH:$HOME/.linkerd2/bin(或者,直接从Linkerd发布页面下载。)
验证你的Kubernetes集群能够处理Linkerd;安装Linkerd;并验证安装:
linkerd check --pre
linkerd install | kubectl apply -f -
linkerd check最后,安装我们将要使用的“Emojivoto”演示应用程序:
curl -sL https://run.linkerd.io/emojivoto.yml
| linkerd inject -
| kubectl apply -f -此时,我们已经准备好获得一些实际的指标了。但首先,让我们谈谈SLO中最重要的数字:错误预算(error budge)。
错误预算
错误预算可以说是SLO中最重要的部分。但它到底是什么,我们如何得到它?
让我们从一个例子开始。假设在过去7天内,你已经决定你的服务必须有80%的成功率。这是我们的SLO。我们可以将这个语句分解为三个基本组件:一个服务水平指示器(SLI),这是我们的度量;目标,也就是我们的门槛;还有时间窗口。在这种情况下:
SLI:服务成功率
目标:80%
时间窗口:7天
这个SLO意味着在7天滚动周期内20%的请求可能会失败,而我们并不认为这是一个问题。因此,我们的错误预算仅仅是衡量我们在一段时间内“消耗”了20%中的多少。
例如,如果我们在过去7天内成功地提供了所有响应的100%,那么我们的错误预算将保持100%—没有任何响应失败。另一方面,如果我们在过去7天成功地服务了80%的响应,那么我们就有0%的错误预算剩余。如果我们在这段时间内提供了少于80%的成功回应,我们的错误预算就会是负的,我们就违反了SLO。
错误预算由下式计算:
Error budget = 1-[(1-compliance)/(1-objective)]
compliance是在时间窗口内测量的SLI。因此,为了计算你的错误预算,我们在时间窗口内测量SLI(计算compliance),并将其与目标进行比较。
用Prometheus计算错误预算
好,回到键盘上来。让我们访问在Linkerd控制平面中的Prometheus实例,我们在上一步中通过一个port-forward安装了它:
# Get the name of the prometheus pod
$ kubectl -n linkerd get pods
NAME READY STATUS RESTARTS AGE
..
linkerd-prometheus-54dd7dd977-zrgqw 2/2 Running 0 16h用PODNAME表示pod的名称,我们现在可以这样做:
kubectl -n linkerd port-forward linkerd-prometheus-PODNAME 9090:9090现在我们可以打开localhost:9090并开始试验Prometheus的查询语言PromQL。
Prometheus仪表板
本教程不需要完全掌握语法知识,但是浏览示例熟悉一下肯定会有帮助!
构建Prometheus的查询
在上面的例子中,100%和80%的响应是成功的--这是我们在这段时间内的compliance数字。让我们先用Prometheus查询来计算这个数字。对于我们的服务,我们将使用Emojivoto的投票服务,它作为Emojivoto命名空间中的部署资源。
首先,让我们看看总共有多少对投票部署的响应:
查询:
response_total{deployment="voting", direction="inbound", namespace="emojivoto"}结果:
response_total{classification="success",deployment="voting",direction="inbound",namespace="emojivoto",..} 46499
response_total{classification="failure",deployment="voting",direction="inbound",namespace="emojivoto",..} 8652在这里我们看到两个结果,因为指标是由一个标签值分开的,它们的不同之处是:classification(分类)。我们有46499个成功的响应和8652个失败的响应。
在此基础上,通过添加classification="success"标签和[7d]时间范围,我们可以看到过去7天每个时间戳上成功响应的数量:
查询:
response_total{deployment="voting", classification="success", direction="inbound", namespace="emojivoto"}[7d]这个查询的响应很大,但是我们可以使用increase()和sum() PromQL函数来简化它,通过标签分组来区分不同的值:
查询:
sum(increase(response_total{deployment="voting", classification="success", direction="inbound", namespace="emojivoto"}[7d])) by (namespace, deployment, classification, tls)结果:
{classification="success",deployment="voting",namespace="emojivoto",tls="true"} 26445.68142198795这意味着在过去7天里,通过投票部署已经有大约26445个成功的响应(小数来自increase()计算的机制)。
使用这个,我们现在可以通过将这个数字除以响应总数来计算我们的compliance--只需删除classification="success"标签:
查询:
sum(increase(response_total{deployment="voting", classification="success", direction="inbound", namespace="emojivoto"}[7d])) by (namespace, deployment, classification, tls) / ignoring(classification) sum(increase(response_total{deployment="voting", direction="inbound", namespace="emojivoto"}[7d])) by (namespace, deployment, tls)结果:
{deployment="voting",namespace="emojivoto",tls="true"} 0.846113068695625我们发现,在过去7天内,84.61%的响应都是成功的。
计算错误预算
我们使用核心查询来计算剩余的错误预算。现在我们只需要把它们代入上面的公式:
Error budget = 1-[(1-compliance)/(1-objective)]
插入我们80%(0.8)的目标(objective):
查询:
1 - ((1 - (sum(increase(response_total{deployment="voting", classification="success", direction="inbound", namespace="emojivoto"}[7d])) by (namespace, deployment, classification, tls)) / ignoring(classification) sum(increase(response_total{deployment="voting", direction="inbound", namespace="emojivoto"}[7d])) by (namespace, deployment, tls)) / (1 - .80))结果:
{deployment="voting",namespace="emojivoto",tls="true"} 0.2312188519042635在我们的例子中,投票部署还有23.12%的错误预算。
祝贺你,你已经成功地计算了你的第一个错误预算!
用Grafana捕捉结果
数字很好,但花哨的图表呢?你是幸运的。Linkerd安装了一个Grafana实例,我们可以通过Linkerd的仪表板在本地访问它。
首先,通过运行Linkerd dashboard命令加载Linkerd的仪表板。
现在,让我们通过单击相应的Grafana徽标来查看emojivoto命名空间的Grafana仪表板。
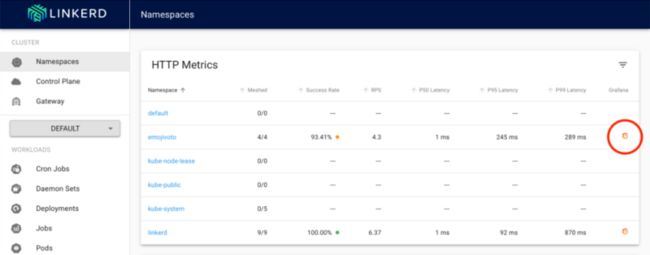
Linkerd仪表盘与Grafana集成
向下滚动到deploy/voting,我们可以看到黄金指标面板:成功率、请求率和延迟。让我们为剩余的错误预算添加一个面板。

Linkerd在Grafana仪表板上
为了保持简单,让我们添加面板标题7-day error budget (success rate),并在PromQL查询框中添加上面的最终查询。
应用结果,你现在应该有一个面板来跟踪投票部署的剩余错误预算!

Grafana与Linkerd指标显示错误预算。
进一步
有很多方法可以调整上面使用的查询以适应特定的用例。
现在我们有了一个跟踪服务错误预算的图表,我们可以使用额外的PromQL函数(如rate())来跟踪服务的错误预算消耗率。
如果你想以不同的方式查看你的预算,请尝试更改数据的可视化。在这里,我选择了测量和添加阈值来指示我是否应该关注。

7天错误预算(成功率)与测量。
要跟踪emojivoto命名空间中所有服务的剩余错误预算,只需删除deployment="voting"标签。请记住,这将假设命名空间中的所有服务都有相同的80%目标。
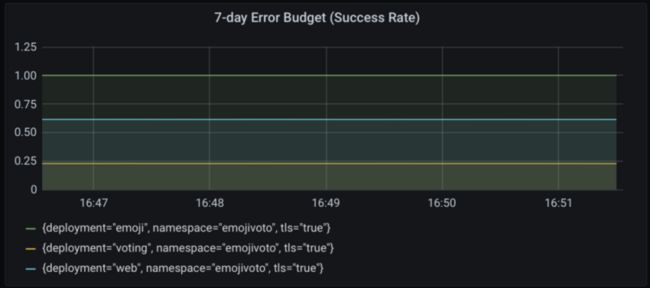
所有服务的7天错误预算(成功率)。
从SLO到可操作的观察性
你已经根据Linkerd的黄金度量标准制定了服务运行状况的SLO,计算了错误预算,并用Grafana绘制了它们的图表。祝贺你,你正在使用SLO!
下一步是什么呢?
遗憾的是,即使有了所有这些,要真正使用SLO仍然需要做很多工作。你需要为你平台上的每个相关服务一致地计算它们;你需要把它们交到组织中其他需要了解它们的人手中;当错误预算开始迅速下降时,你需要能够采取行动。如果没有这些部分,你的SLO将只是一个空数字。
在Buoyant,我们是SLO的巨大信徒,尤其是Kubernetes。这也是我们创建Dive的部分原因,它允许你通过点击一个按钮来设置SLO。Dive构建在Linkerd之上,并使用相同的指标来自动跟踪集群上运行的所有服务。Dive还提供了很棒的可共享仪表盘,你可以将其发送给团队的其他成员,允许你预测何时会违反你的SLO,以及许多其他有趣的东西。
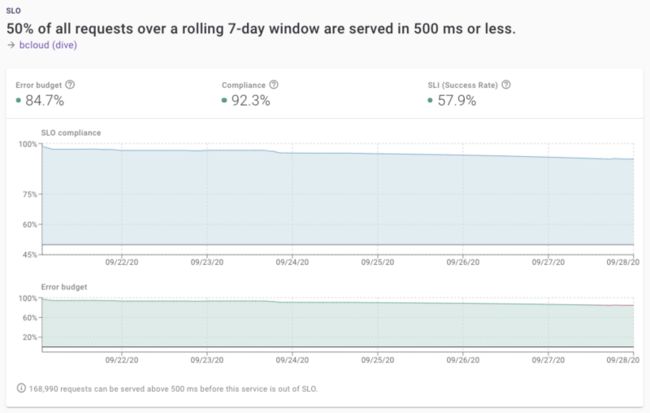
Dive仪表板显示SLO遵从性和错误预算的7天窗口。
无论你最终是使用Dive进行Linkerd服务的健康SLO,还是坚持我们上面概述的Prometheus和Grafana方法,我们都祝你在SLO旅程中好运!
CNCF (Cloud Native Computing Foundation)成立于2015年12月,隶属于Linux Foundation,是非营利性组织。
CNCF(云原生计算基金会)致力于培育和维护一个厂商中立的开源生态系统,来推广云原生技术。我们通过将最前沿的模式民主化,让这些创新为大众所用。扫描二维码关注CNCF微信公众号。