网站分析度量
今天的话题回到度量,因为度量是网站分析的骨骼,所谓皮之不存毛将焉附,没有度量,网站分析就成为不了一门科学。度量也是最多朋友们问起的问题,例如下面这个问题:
宋星老师:
有个困惑已久的问题.在GA里面的跳出率和退出率的问题。
他们的含义都知道:但是当他们同时存在时,主要看哪个数据比较好?
如果是单独出现时还行,但是在GA里面 是同时出现的。
这是一个好问题,体现了非常棒的探究精神,以及直击问题本质的敏锐观察。类似的问题太多了,所以,重新发一系列帖子是必不可少的。现在开始,我们从最基本的,一些容易让我们混淆的度量概念开始。同时这篇文章不会再重复过去的内容(关于度量的内容,请大家看博客的网站地图),而只是画龙点睛,说一说大家最该了解的东西。
最基本的流量度量也有陷阱
Page view,visit和visitor是三个最基本的流量度量,这三个度量按照监测难度来区分是这样的:
Visit > Visitor > Page View
原因在于:
 Page view只是一个简单计数,只是页面中的网站分析监测代码被运行了一次,仅此而已。它最简单。
Page view只是一个简单计数,只是页面中的网站分析监测代码被运行了一次,仅此而已。它最简单。
Visitor同样是一个简单计数,是网站分析监测代码识别了一个不同的cookie,或是一个不同的IP(对某些工具,没有cookie的时候,用IP分辨visitor)来到了网站而已。但visitor肯定比page view复杂,因为它包含了对cookie或者IP的记录和判断。
Visit代表某一个visitor一系列的网站访问动作,每个动作之间的间隔不超过特定的时间(例如不超过30分钟)。它意味着判断几个事情:(1)要有一个visitor,如果判断不出visitor,visit也就没有意义;(2)要判断page view或者其他网站分析工具能够识别的网站访问动作;(3)要识别动作与动作之间的间隔时间。所以visit的判别最复杂。所以,我们在最早的用log file进行网站分析的时候,是没有非常明确的visit的概念的,只有session的概念。
那么,陷阱在哪儿呢?
Visitor和page view没有什么陷阱,它们俩是简单的计数度量,触发了就触发了,记录下来即可。可是visit存在陷阱。这个陷阱在于如下几种可能:
- 我在A网站访问了20分钟,第21分钟的时候从A网站(比如CWA网站:http://www.chinawebanalytics.cn)的链接(这个链接连接到B网站)跑到B网站,然后在25分钟的时候,又从B网站的链接(这个链接指回A网站)回到A网站。这个过程中浏览器窗口并没有关闭,那么这个过程A网站有几个visit?
- 我在A网站访问了20分钟,第21分钟的时候关闭A网站的页面,然后打开一个新的浏览器窗口,然后在25分钟的时候又打开新窗口输入A的网址回到A网站,这个过程中网站A有几个visit?
- 我在A网站访问了20分钟,第21分钟的时候关闭A网站的页面,然后打开一个新的浏览器页面,即Tab(注意,浏览器没有关闭),然后在25分钟的时候又打开新Tab输入A的网址回到A网站,这个过程中网站A有几个visit?
答案:首先,一定要明确不同的网站分析工具,对于上面三种情况的计数是不一样的。我们先看看GA是怎么做的。
1. 在30分钟内,且没有关闭浏览器——注意是浏览器而不是浏览器Tab,即使从新的外部入口(例如不同的搜索引擎,不同的referring site,例如本例中中的B网站),也不会被记录为新的session。这意味着第一个题目的答案是1个visit。
2. 关闭了浏览器,意味着一个浏览器的session结束了。对于GA而言,这意味着一个新的visit。因此这个情况下visit是2。
3. 关闭了浏览器tab,但浏览器没有关闭,因此浏览器的session没有结束。对于GA而言,这不意味着一个session的结束,因此没有增加新的visit。这个情况下visit是1。
对于Omniture的SiteCatalyst,情况可能有一点不同。
1. 30分钟内,不会被记录为新的visit,因此是1个visit,跟GA情况一样。
2. 这个地方跟GA不同。Omniture的SiteCatalyst不以浏览器session结束作为新的visit的判定条件,因此这个visit还是1。
3. 跟GA一样,仍然是1个visit。
看来很多事情跟我们想的的确不太一样,不是吗?:)

图:Tab,伟大的Tab
我不想在这个里跟大家讨论这个三个问题的答案,欢迎大家在留言中讨论,要提醒的一点是不同的网站分析工具对于这些过程的定义都不太一样。所以,如果我们要选择一个网站分析工具,我们最好让供应商告诉我们他们对于这些基本度量的基本定义和监测方法是什么。
不过这三个问题直接回答了我们下面的问题:
(1)为什么Omniture SiteCatalyst监测到的visit只有Google Analytics的80%啊!
(2)为什么Google Analytics的数据和我服务器日志的数据相差那么远!
如果它们的数据一样我才会觉得奇怪呢![]() !按下这些不同工具的不同区别不表(同类工具有些过大的区别当然可能意味着监测实施的不正确)。我想说的是,我们应该至少明白visit其实是一个非常复杂的度量,它绝对不像我们想象的那样简单。
!按下这些不同工具的不同区别不表(同类工具有些过大的区别当然可能意味着监测实施的不正确)。我想说的是,我们应该至少明白visit其实是一个非常复杂的度量,它绝对不像我们想象的那样简单。
因此,我们走出对这个度量的一般性理解,而进入一个根本性的问题——为什么要设置“visit”这个度量?为什么我们不用page view或者visitor就可以了?
如果你能把这个问题想清楚,我想才算真正理解了visit。

图:It’s not as easy as you thought! ![]()
答案其实很简单——狭义的网站分析(Web Analytics)是分析什么的科学?是分析网站访问者行为的科学,因此落脚点是行为。所以,只有visitor肯定不行,visitor不附加上与之对应的行为,没有意义。但是,如果行为是孤立的,没有来龙去脉,同样意义不大,所以只有page view同样不行。Visit是为此而建立的,是为了衡量一个visitor的一系列体现为page view的行为。它是一个桥梁,让visitor和page view建立关系,也让访问者和行为建立联系,并以数据的方式进行表达。
听起来这是多么艺术的一个过程啊。这就是网站分析的美。如果你细细平常一些为什么背后的为什么,你会发现原来一花一世界。
即使是基本度量,也并非都有统一的定义
什么是质量,什么是长短,什么是速度,这些现实生活中我们经常用到的度量都有世界统一的标准的定义和单位。可是,在网站分析的世界中,并不是所有的度量都有统一的定义。
这是因为网站分析还是一个非常新的学科。网站分析这门学科的名字最初实际上也是不确定的。最早,人们用e-metrics(e度量),之后又有用web metrics(网站度量)的,直到最后越来越多的人开始用web analytics(网站分析),这门学科才有了正式的名字。
尽管学科名字被确定下来,但是学科内的很多度量还有这不同的解释。例如bounce rate(蹦失率),这个度量至今仍然存在两种以上的常见解释。除了解释的不同,不同的监测工具对于一些度量的算法也存在差异,例如上面说过的,对于如何辨识visitor,不同的工具就有不同的算法,visit也是如此。
为了解决不一致产生的矛盾,部分聪明的网站分析工具提供商会提供一些能够自定义度量的功能,可以让用户更加灵活的根据需要调整度量的定义和尺度,这客观上极大的增加了网站分析的适应性,产生了很好的效果。

但是,定义不一致毕竟不是一件好事,尤其是对于一些基本度量。因此业界的一些组织也在致力于建立一些国际标准,这些组织包括:英国发行量审计局(Britain’s Audit Bureau of Circulation,www.abc.org.uk),网站标准联合产业委员会(the Joint Industry Committee for Web Standards,www.jicwebs.org)以及网站分析协会(the Web Analytics Association,www.webanalyticsassociation.org)。
对于不同的定义,最终可能的结果是,某一些被最多人使用的度量定义将成为业界约定俗成的定义,被最终成为实施标准。
但,千万别觉得一个网站分析工具的定义就代表了网站分析业界,那也许只是无数种定义和规定中的一种罢了。关键,是要理解这些度量存在的目的是什么,以及它对应的网站在现实世界中的状态是什么。
最基本的度量构成复合度量
最基本的度量非常简单,不足以描述更复杂的网站浏览行为,因此人们开始引入复合度量。所谓复合度量,就是多个基本度量应用四则运算组合而成的新度量。比如bounce rate,比如exit rate,比如PV / visit。
复合度量给新手朋友们带来了许多困扰。下面的文字希望能够解决你们的困扰。
首先看看Bounce Rate。Bounce Rate被称为跳出率(Google Analytics),或者蹦失率(China Web Analytics),你可以选择任何一种叫法,大家应该都能听得懂,我喜欢我发明的后者。![]()
Bounce Rate一定要记住以下几点:
- Bounce Rate不是衡量所有页面的度量,而是衡量所有页面仅仅作为landing page时候的度量。
- 它是一个特殊的度量。它可以衡量整个网站的表现,也可以用来衡量某个页面作为landing page时的表现。即,它既是一个网站级的度量,又是一个页面级的度量,关于这个,本文的后面再讲。
- 不同的网站分析工具对它的定义不同。(如果你想了解这一点,一定要读这个帖子:网站分析的最基本度量(5)——Bounce Rate。)
- 它的公式不重要,它的目的和含义更重要。
现在我来谈谈它的目的是什么。
Bounce Rate的目的非常明确,即帮助人们搞清楚访问者进入你的网站的第一印象如何。请注意,是第一印象,是从网站外部进入网站的第一印象。
 在这个目的之下,人们开始想,该怎样用一个度量来描述它呢?人们最先想到的,是用你进入网站开始到离开网站的时间间隔。比如,你来到腾讯网,你随便看了几眼,然后啐了一口口水说,“草,垄断”,然后就关了窗口,整个过程可能就5秒钟。这说明这个网站给你的印象不佳。所以,用时间来描述真是一个好主意。这是人们最初设想的方法,也是Avinash先生最初在他的博客上提倡的方法。
在这个目的之下,人们开始想,该怎样用一个度量来描述它呢?人们最先想到的,是用你进入网站开始到离开网站的时间间隔。比如,你来到腾讯网,你随便看了几眼,然后啐了一口口水说,“草,垄断”,然后就关了窗口,整个过程可能就5秒钟。这说明这个网站给你的印象不佳。所以,用时间来描述真是一个好主意。这是人们最初设想的方法,也是Avinash先生最初在他的博客上提倡的方法。
可是这个方法,存在一个很大的问题,那就是时间问题。你可能讨厌腾讯网,但由于网页tab的存在,你可能并不急于关闭它,而是打开一个新的网页,例如打开360杀毒的首页,津津有味的读起周鸿祎先生抨击腾讯网的“檄文”,然后半个小时后才发现怎么“恶心的”腾讯网还开着,这才关掉它。这个时候,时间来判断就存在偏差。另外一个很大的问题是,网站分析工具对于时间的监测和我们真实的在网页上浏览的时间并不可能完全一致。因此,时间方法来衡量网站第一印象,执行起来挺难。
但是人脑总是聪明的,虽然站在宇宙尺度上这样的聪明不过是浮云,和凤姐的美貌程度不见得能有多大差异,但我们并不畏惧困难。因此,另一种想法诞生了——如果你进入这个网站的第一页就觉得讨厌,那么你不太可能花费时间继续浏览这个网站的其他页面,这就使bounce rate诞生了。bounce rate衡量的就是——只访问一个页面的访问(visit)占总体访问(visit)的比例,或者是只访问一个页面的访问者(visitor)占总体访问者(visitor)的比例。至于何种数学定义并不重要,关键是,人们总算找到了一个跟时间无关的,而且容易计算的方法来衡量网站的第一印象。

这就是bounce rate的故事,所以bounce rate不用来衡量所有页面的所有访问,而只是用来衡量页面作为landing page时候的访问印象,因为landing page才是网站带给访问者的第一印象。所以,你也应该明白:一个网站的每个页面都有可能是landing page(因为搜索引擎能够把流量带到你的网站的任何一个页面上),但相对于不同的visit,每个页面只有一部分可能是landing page——当且仅当这个visit进入网站访问的第一个页面是这个页面时。
Exit Rate呢?则是另外一个故事。Exit Rate衡量的是人们离开网站的行为。人总要离开一个网站,虽然我想吉尼斯世界纪录应该统计连续上网时间最长的人,但这个人毕竟也是会死的,所以即使他能100年持续访问一个网站,他也终须离开他心爱的网站。再说,cookie也没有那么长的时限。因此,人们更多的从网站的什么地方离开这个网站成为大家关心的问题。
Exit rate就是衡量这个事情的,说白了,exit rate就是一个网页作为网站出口的几率大小。exit rate=87%,就说明,经过这个页面所有的访问中,有87%的可能性从这个页面离开网站。这个网站当然要承担不能“留住”访问者的责任。
这样看来,bounce rate和exit rate两个度量被发明的初衷是没有什么关系的,它们各自衡量各自的,虽然很像,但其实逻辑完全不同。我刚刚学习网站分析的时候,我也很疑惑,拼命想搞清楚这两个度量的关系。现在看来,搞清这两者的关系其实没有多大意义,搞清楚什么时候该用它们中的哪一个才更有意义。

所以,我们不要让复合度量在数学上弄糊涂我们。我相信Google Analytics被发明出来的时候没有想到人们最后会那么精确计算这些复合度量,所以我们才会现在发现Google Analytics上有那么多数字对不拢的情况。但是,这根本不妨碍我们分析,因为在什么情况下该用什么我们早已了然于心。
计数度量和复合度量
 现在,总结一下什么事计数度量,什么事复合度量。计数度量(count)是指不需要计算的,以记录个数、次数、时间长短等为目的的一元度量。page view,visit,visitor都是计数度量,overall time on page,也是计数度量。计数度量不可以再拆分。
现在,总结一下什么事计数度量,什么事复合度量。计数度量(count)是指不需要计算的,以记录个数、次数、时间长短等为目的的一元度量。page view,visit,visitor都是计数度量,overall time on page,也是计数度量。计数度量不可以再拆分。
复合度量(calculate)是指由多个计数度量进行公式运算(一般是四则运算)组合而成的度量。例如,我们常用的衡量访问者访问页面广度的度量——page view/visit,即是用page view除以visit而得来。
计数度量和复合度量有涉及到如何通过数据表达的问题。通常,网站分析对于度量具体数值的表达都是用计数的方法展现的,例如,网站在5月份的visit是34,567个,访问者是23,456个云云。计数度量常常都对应其数据报告的计数表达。
对于复合度量,同样也用计数报告来表示,例如网站的bounce rate是13.3%。计数报告是最常见的网站分析报告。下面的报告就是典型的计数报告:

另一种报告被称为分布报告,记录了不同统计维度的分布情况,例如图D就是一个典型的分布报告,标明了不同路径长度所对应的visit的数量。
下图也是一个典型的分布报告,所展示的是不同时间长度的访问的数量分布:

计数报告和分布报告都是网站分析工具常用的数据展示形式,在制作网站分析报告的时候,我们也同样经常使用这两种形式。可以说,计数和分布是我们每天都要打交道的最常见模型。
今天继续度量这个话题,对Visitor和Visit进行更深入一点儿的挖掘。这个话题本来是不存在的,但是看到大家对这个系列第一集中关于visitor和visit的一些小疑惑,发现还是值得拿出来再说一说。仍然说它的原因,并不在于让大家死记住这两个度量本身的相关规定,而是这两个度量涉及了原理、方法和工具,这些是更有价值的知识。
为什么Visitor和Visit容易让我们疑惑?
 Visitor让我们疑惑的,值得澄清的地方在于如下几点:
Visitor让我们疑惑的,值得澄清的地方在于如下几点:
- Visitor的含义是指访问的人数,但visitor并不可能等同于真正的访问你的网站的自然人的数量。
- Visitor与visit和page view这两个度量不同的是,visitor跟时间的粒度(granularity)有关:即使相同的时间长度,时间粒度取的不同,visitor的数量也会不同。
- 相对而言,利用log file(日志法)对visitor的计数有先天不足,因此visitor这个概念对日志法较少使用。(关于什么是日志法,什么是标记法请看我的这个文章:服务器日志法网站分析的原理及优缺点)
对于上面三点稍作一点儿解释。第一点,visitor的含义是网站的访问人数,是具体的人。可是,并不可能真正知道到底有多少人访问了你的网站。为什么呢?假如你和你的朋友公用一台电脑,而且都用同一个浏览器访问我的博客(www.chinawebanalytics.cn, www.cwachina.com),这个时候用技术的方法来精确分辨出是两个访问者非常困难——总不能在你的电脑上装上一个摄像头窥视吧!因此,无论技术发展到何种程度,我认为100%准确记录访问网站的人数都是不太可能的,不仅是网站分析的工具难以做到,其他不同方法和不同工具也做不到(关于网站分析计数准确性的研究,请大家看这篇文章:网站分析——我们的数据准确吗?)。 因此,人们采用了一些变通的方法来解决识别visitor数量的问题,我后面会重点讲到。
因此,人们采用了一些变通的方法来解决识别visitor数量的问题,我后面会重点讲到。
第二点,visitor跟时间的粒度有关。所谓粒度,就是我们所说的截取的时间范围。举个例子,2010年11月14日到11月20日这一周的七天,你在每天都访问了CWA网站一次(感谢这么忠诚的读者。:) ),那么如不同的时间粒度下visitor的计数不同。Weekly visitor是1,而daily visitor则是7。值得注意的是,对于所有的网站分析工具,weekly、monthly或者quarterly、yearly这样的时间粒度都是指日历上的自然周、月或者季度和年。因此,虽然11月24日到11月30日也是七天,而且你分别在这期间的11月25日和11月29日访问了我的CWA网站,weekly visitor仍然会被记录为2。
第三点,日志法对于记录visitor的数量是采用分辨IP的方法的。因此,在日志法中,我们常常提到的一个概念是独立IP的数量,并借此指代实际的访问者数量。但是,今天的IP地址已经不可能再跟计算机一一对应了,更不用说跟使用计算机的人一一对应。因此,用这个方法统计visitor的数量存在很大误差,逐渐被人们抛弃掉。
相对而言,visit的麻烦其实更多一点:
- 为什么要存在visit?
- Visit和session是什么关系?
- 关闭浏览器窗口对visit的计数有没有影响?
- 关闭浏览器标签(Tab)对visit的计数有没有影响?
- 从不同来源访问网站,一定会使这个网站visit的计数增加吗?
- Visit和unique page view是什么关系?
这些问题普遍反映了大家对visit和(标记法)网站分析的疑惑,但实际上,如果我们深入领会了visit的本质,解答这些问题其实很容易。
首先,为什么要存在visit?我们说过,网站分析不是分析孤立的数据(这是跟过去网站简单的流量统计有本质的区别的地方),而是分析网站访问者的行为。page view本身是一个个的孤立数据,不能解答网站访问过程中,网页之间的相互关系。例如,我说首页的page view是19,807,网站分析工具频道首页的page view是2,303次,这不能说明首页就一定更受欢迎。而visit,是指访问者来到网站的一系列打开页面的访问过程,是行为,是联系page view和visitor的桥梁。Visit这个度量的重要性就在于,它几乎是其他所有网站分析度量的基石,或者直接影响到了其他所有的网站分析度量。

其次,visit和session是什么关系呢?session和visit肯定不完全是一回事,但是你可以认为这二者是一样的名词。因为这涉及到一些历史。session是计算机原理课中的一个名词,即一个“会话”,如果你学过网络的七层结构模型,你就一定还记得其中有一个session layer——会话层,就是指它。在日志法网站分析中,人们用session来表示一个连结的建立和解除,以用之描述visit。不过,由于标记法网站分析的出现,visit直接采用了别的更好的方法表述(马上也会重点讲到),这样就使session这个名词实际上弃用了,而直接使用visit来表示一次访问行为。当然,session作为技术上的一个名词,是不会被丢掉的,但在网站分析上,人们采用了更符合自然语言的表达。
剩下还有几个问题,关于visit的计数,以及visit和unique page view的关系,我会在下面首先跟朋友们解答visit和visitor的计数原理,然后在这个系列的下一篇中说明visit和unique page view的区别和联系,因为这一点将要引发出来的课题非常重要。为了弄清楚网站分析工具对于visit和visitor的计数,我们先要搞清楚怎样查看网站分析是否记录到了网站访问者的行为数据。
怎样查看网站分析工具是否捕捉到了数据
回答这个问题,我们不能靠猜测了,我们要用几种HTTP Sniffer(HTTP数据包嗅探器)工具(其实一般一种就够了,但不妨我们多了解几种)来探测,如同用雷达探测天上的飞机。首先,我推荐一个我最喜欢的工具:
 HttpWatch
HttpWatch
HttpWatch(http://www.httpwatch.com/)肯定不是最强大的,但我觉得是最容易上手的,能够跟IE和火狐很好的整合,并且很稳定。
其他工具
然后其他工具大家也可以试试。Charles(www.charlesproxy.com/),是最强大的工具。firebug,主要用来查看cookie,这是个免费工具。另外还有WASP(http://webanalyticssolutionprofiler.com/),专门用来查验各种网站分析工具的软件。还有httpfox,也是免费的,从firefox的插件库中可以找到,功能也基本上齐全了。
如果不想付费,建议装上httpfox(或者基本版的HttpWatch),firebug和WASP(试用版)就足够了。
怎样查看网站分析工具是否捕捉到了数据
下面我以HTTPWatch为例,介绍如何查看网站分析工具是否捕获到了数据。对这个部分熟知的朋友直接跳过。
1. 在Firefox浏览器空白页中,打开(快键Shift+F2)打开HTTPWatch。
2. 启动HTTPWatch的记录模式,即点击下图中的红色框中的红button。

3. 在地址栏中输入你要检查的网页URL,打开网页。这个步骤可不需要拘泥于在地址栏中输入URL,你一样可以通过点击外部链接来到这个页面,HTTPWatch仍然会忠实的记录页面打开过程中的HTTP数据包。这时,你可以看到一条条的浏览器传输的数据记录产生了。
请千万不要把这些记录当做是网站服务器的Log记录,这是两回事。
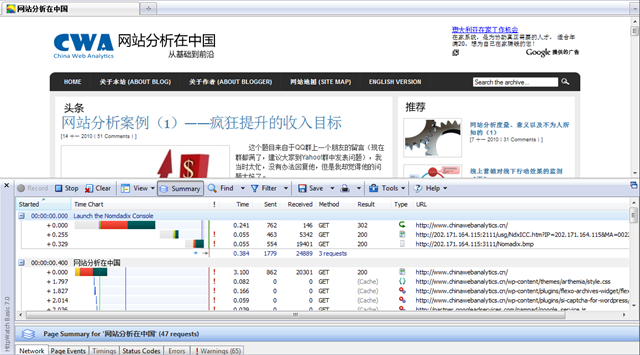{kind=link}
4. 上面的数据很多,怎么能看到网站分析工具捕获的数据呢?利用过滤功能就好了。利用快捷键Ctrl+F9,调出过滤器,然后勾选Enabling Filtering,再勾选URL Contains,其下输入“-analytics”,再点OK之后就过滤出页面中GATC(Google Analytics Tracking Codes)发送的信息,如图所示的两条。如果你的页面上加有多个GA profile ID,那么这个数据也可能是多条。如果过滤之后没有数据了,说明网页没有正常运行GATC,或者没有加入GATC,那当然就是不能完成正常监测啦。

对于Omniture SiteCatalyst,在过滤器中输入“2o7”,就能把只是Omniture Tracking Code发出的监测数据过滤出来。
现在,你有了这个好武器,它的用途可不只是让你看看监测代码正常工作了没有。我们下面要用它来检查网站分析工具是如何计数visit和visitor的。
Visitor和visit如何计数?
你可能会问,上面过滤之后的这两条信息是什么东西?想要搞清楚这个问题,我们得打开另外一个话题,即网站分析工具获取数据的原理。如果大家感兴趣,我会另开一篇帖子,如果没兴趣就算了,反正也不太影响大家直接进行网站分析的实践,在我未来计划(现在还只是计划,实在是忙的对不起大家)的书中会再专门提及。下面我们还是聚焦在网站分析工具如何计数这个问题上。
你可以先阅读这个帖子——网站分析工具如何辨别UV,然后再继续往下看,一定会有新的收获。在标记法的网站分析中,除了page view之外,visitor和visit以及一切我们分析报告中显现的度量和计数其实都是通过cookie实现的,只有在没有cookie的情况下,才通过其他的方法实现,因此,如果想要搞清楚visitor或者visit到底是如何被网站分析工具记录的,最好的办法是直接看看cookie是怎么记录的。
不同网站分析工具cookie记录的方法有所不同,但核心思想是一致的。因此,这里先说说Google Analytics的cookie设置,未来有机会再聊Omniture SiteCatalyst的,因为后者的架构相对更加复杂。
Google Analytics的cookie设置
利用HttpWatch,我们点入第二条信息,然后选择“Query String”标签,在下方的检视窗口中出现了更多的信息。

先不管其他信息,我们直接看utmcc,这条记录是GA跟visit和visitor相关的cookie信息。如下:
utmcc __utma=148702437.1696395432.1289879776.1290424992.1290508917.6;+__utmz=148702437.
1289882757.1.6.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=%E7%BD%91%E7%AB%99%E5%88%86%E6%9E%90;
现在,我们一条条的看这些数据到底是什么意思。
- utma
记录visitor的信息,utma后面的信息,包括域的hash值,visitor的ID、访问时间相关信息和访问次数。utma对应的信息,除非人为删除,否则它在两年后才失效。为了免去我自己作图的痛苦,我直接利用了Google转化大学中的图,因此下图中的数字信息跟上面的不一样,但相应信息的含义是完全一样的。

本图的来源为http://services.google.com/analytics/breeze/en/ga_cookies/index.html
版权归Google所有
第一个蓝色的字段是域名的哈希串,对于一个确定的域名来说,这个值是不会改变的。
第二个字段(绿色字段)是识别visitor的ID,就是这个绿色字段,标识了不同的访问者,不同的值就意味着不同的访问者。这就是GA能够辨别不同访问者的原因。这个值如果不发生人为地删除cookie的情况的话,两年后才会被替换为一个新的值。
第三个字段(紫色字段)是这个visitor第一次访问网站的时间,如果不删除cookie,两年内这个值也不会变。这个时间是UNIX时间,0000000001代表着1970年1月1日0点0分1秒,之后每过一秒,数字加一。实际上UNIX时间是有点小错误的,但是已经不会再对使用产生影响。这里同学们需要注意了。这里以及cookie中其他的UNIX时间记录,构成了GA的整个时间度量系统。时间是这么创造的!
第四个字段(浅蓝色字段)是这个visitor前一个visit开始的时间。
第五个字段(浅紫色字段)是这个visitor这一次visit开始的时间。
第六个字段(最后那个独立数字)太重要了,是记录这个visitor访问网站的次数。
现在,再回头看看前面的我的网站(CWA,China Web Analytics,http://www.chinawebanalytics.cn)的utma,大家会发现这个visitor(就是我)已经有6次访问了。
通过第六个字段值的增加与否,就能判断GA是否记录某一次访问行为为一次新的visit。
- utmz
utmz的功能是用来记录网站访问者的来源(即Traffic Source或者Campaign),如下:


这里各个字段的含义除了Campaign Number之外就不多解释了,大家肯定能看懂。Campaign Number是指这个访问者通过不同来源(除了直接来源)访问网站的来源数。如果通过了一个新的来源访问了网站,即使是在一个visit之内,campaign number也会加一,但visit并不会增加。
Campaign number的作用我并不是很明确,很希望知道的朋友告诉我。我知道的是,如果在一个visit之内,访问者通过多个来源访问了网站,那么GA默认把最后的那个来源归为这个visit的主人。如果你用utm_nooverride=1配置,那么GA则会把第一个来源记录为这个visit的主人。
- utmb和utmc
utmb和utmc是另外两个重要的cookie信息,在免费版本的HttpWatch中看不到,不过没关系,大家用firebug就能看到。
简单讲,utmb和utmc都是记录visit的cookie。两个cookie的区别是,utmb在30分钟后过期,如果utmb过期刷新,那么visit也被刷新。utmc是浏览器关闭则随浏览器一起关闭(失效),再打开浏览器访问那个网站,visit也被刷新。这就是为什么GA的visit在不活动30分钟后结束,以及关闭浏览器结束的原因。

=====================以上摘自:http://www.chinawebanalytics.cn/