Table of Contents
1 前言
Web Search 的历史经历了
传统的 “text retrieval” 到 “基于link analysis的搜索引擎”,目前,由于机器学习和数据挖掘
的技术不断成熟,利用统计模型来解决rank问题已经成为一个hot topic: Learning to Rank
2 LTR的流程
- Collect Training Data (Queries and their labeled documents)
- Feature Extraction for Query-document Pairs
- Learning the Ranking Model by Minimizing a Loss Function on the Training Data
- Use the Model to Answer Online Queries
3 训练数据的获取
有2种获取训练数据的来源:1)人工标注;2)搜索日志。
3.1 人工标注
从搜索日志中随机选取一部分Query,让受过专业训练的数据评估员对”Query-Url对”给出
相关性判断。常见的是5档的评分:差、一般、好、优秀、完美。以此作为训练数据。人工标
注是标注者的主观判断,会受标注者背景知识等因素的影响。
3.2 搜索日志
使用点击日志的偏多。比如,结果ABC分别位于123位,B比A位置低,但却得到了更多的点击,
那么B的相关性可能好于A。点击数据隐式反映了同Query下搜索结果之间相关性的相对好坏。
在搜索结果中,高位置的结果被点击的概率会大于低位置的结果,这叫做”点击偏见”(Click Bias)。
但采取以上的方式,就绕过了这个问题。因为我们只记录发生了”点击倒置”的高低位结果,使用这
样的”偏好对”作为训练数据。关于点击数据的使用,后续再单独开帖记录,这里不展开。
在实际应用中,除了点击数据,往往还会使用更多的数据。比如通过session日志,挖掘诸如页面停
留时间等维度。在实际场景中,搜索日志往往含有很多噪音。且只有Top Query(被搜索次数较多
的Query)才能产生足够数量能说明问题的搜索日志。
3.3 公共数据集
现存一批公开的数据集可以使用
- LETOR, http://research.microsoft.com/en-us/um/beijing/projects/letor/
- Microsoft Learning to Rank Dataset, http://research.microsoft.com/en-us/projects/mslr/
- Yahoo Learning to Rank Challenge, http://webscope.sandbox.yahoo.com/
4 特征抽取
搜索引擎会使用一系列特征来决定结果的排序。一个特征称之为一个“feature”。按照我的理解,
feature可以分为3大类:
- Doc本身的特征:Pagerank、内容丰富度、是否是spam等
- Query-Doc的特征:文本相关性、Query term在文档中出现的次数等
此阶段就是要抽取出所有的特征,供后续训练使用。
5 模型训练
5.1 训练方法
LTR的学习方法分为Pointwise、Pairwise和Listwise三类。Pointwise和Pairwise把排序问题转换成
回归 、 分类 或 有序分类 问题。Lisewise把Query下整个搜索结果作为一个训练的实例。3种方法
的区别主要体现在损失函数(Loss Function)上:
- Regression: treat relevance degree as real values
- Classification: treat relevance degree as categories
- Pairwise classification: reduce ranking to classifying the order between each pair of documents.
5.1.1 Pointwise
Pointwis方法的主要思想是将排序问题转化为多类分类问题或者回归问题。以多类分类为例
进行说明:假设对于查询query,与其相关的文档集合为:{d1, d2, …, dn}。那么首先对这n个pair:
(query, di)抽取特征并表示成特征向量。
- Regression-based:
将query与di之间的相关度作为value,利用regression model来得到一个query与document之间相关
度的预测。
- Classification-based:
将query与di之间的相关度的程度作为label,一般的label等级划分方式为:{Perfect, Excellent,
Good, Fair, Bad},一共五个类别。于是,对于一个查询及其文档集,可以形成n个训练实例。有了
训练实例,我们可以使用任一种多类分类器进行学习,比如最大熵,SVM。下面是一个例子:

5.1.2 Pairwise
Pairwise方法是目前比较流行的方法,效果也非常不错。它的主要思想是将Ranking问题形式化为二元
分类问题。
下面这张图很直观地表达了pairwise方法的思想,同时也给出了构造训练实例的方法。
{kind=link}
对于同一条query,在它的所有相关文档集里,对任两个不同label的文档,都可以得到一个训练实例
(pair),比如图中的()分别对应label为5和3,那么对于这个pair实例,给它赋予类别+1(5>3),
反之则赋予类别-1。于是,按照这种方式,我们就得到了二元分类器训练所需的样本了。预测时,只需要对
所有pair进行分类,便可以得到文档集的一个偏序关系,从而实现排序。
Pairwise方法有很多的实现,比如SVM Rank(开源), 还有RankNet(C. Burges, et al. ICML 2005), FRank
(M.Tsai, T.Liu, et al. SIGIR 2007),RankBoost(Y. Freund, et al. JMLR 2003)等等。下面是SVM Rank的例子:
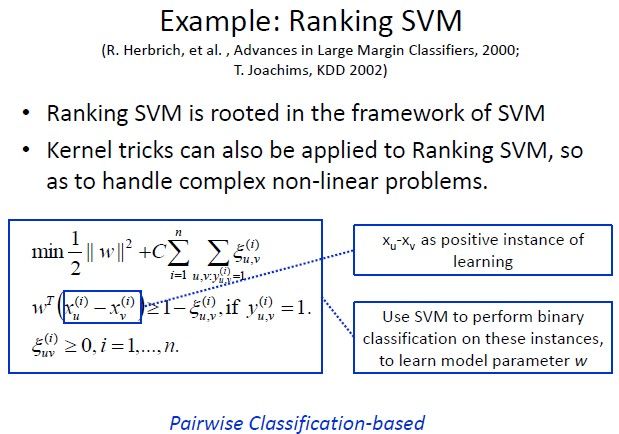
相比于Pointwise方法,Pairwise方法不再对相关度作独立假设,因为它只对同一个query里的文档集生成
训练样本。然而,Pairwise模型也有一些缺点:1.它对不同级别之间的区分度是一致对待的。在信息检索领域,
尤其对于搜索引擎而言,人们更倾向于只点击搜索引擎返回的前几页结果,甚至只是前几条。所以我们对相关
度高(Perfect)的文档应该作更好的区分。2.相关文档集大小带来的模型偏置。假设query1对应的相关文档
集大小为5,query2的相关文档集大小为1000,那么从后者构造的训练样本数远远大于前者,从而使得分类器
对相关文档集小的query所产生的训练实例区分不好,甚至视若无睹。
还有一个重要的因素也会影响Pairwise方法的排序性能。以Ranking SVM为例,它优化的目标是使得正负
样本之间的Margin最大,而并非以排序性能为优化目标。就像BP神经网络以训练误差为目标优化函数,从而使
得它很容易过拟合。优化目标本身的差异将导致模型本身的功能偏置。于是,基于这个特性,人们提出了Listwise
的方法。
5.1.3 Listwise
Listwise方法相比于前两种(Pointwise,Pairwise)而言,不再将Ranking问题直接形式化为一个分类或者
回归问题,而是直接对文档的排序结果(list)进行优化。目前主要有两种优化方法:
- 直接针对Ranking评价指标进行优化。比如常用的MAP, NDCG(下面介绍)。这个想法非常自然,但是往往
难以实现,因为NDCG这样的评价指标通常是非平滑(连续)的,而通用的目标函数优化方法针对的都是连续函数。
- 优化损失函数
损失函数的构造有很多种方式。RankCosine(T. Qin, T. Liu, et al. IP&M 2007)使用正确排序与预测排序的分值向量
之间的Cosine相似度(夹角)来表示损失函数。 ListNet(Z. Cao, T. Qin, T. Liu, et al. ICML 2007)使用正确排序与预测排
序的排列概率分布之间的KL距离(交叉熵)作为损失函数,等等。
以ListNet为例,其损失函数如下:
{kind=link}
和分别表示正确的排序以及预测的排序。其中,概率分布由以下公式定义:
{kind=link}
其中为第j个特征向量的Score。当然这个概率分布需要满足一些性质,比如,对于更佳排序,其概率值应该更高。
那么,最终损失函数就可以表示为以下形式:
{kind=link}
从式中可以看出,ListNet对特征向量进行简单的线性加权来对Score进行预测。此时,任务转化为对权矢量w的学习。
这显然是一个老生常谈的问题,梯度下降是最常用的方法。这里就不再赘述了。
我觉得Listwise的方法是最优美的,因为它专注于自己的目标和任务。相比之下,Pairwise有点儿歪门邪道的感觉:)
当然,这种方法也并非完美,还是有一些缺点的。比如Score()如何构造?能直接使用Label么?事实上,这也是制约性能
的一大原因。还有,求解KL距离时,需要对所有排列计算其概率,算法复杂度趋于。针对这几个问题,都有相应的
Solution。
对于ListNet,据我目前所知,有两个开源的Java版本实现,一是Minorthird,这是CMU的教授William W. Cohen带领他的
学生们做的,类似于Weka,是一个实现了大量机器学习、数据挖掘算法的开源工具,它在Sorceforge上的主页在这儿。另一个
是罗磊同学近期做的,使用的是单层神经网络模型来调整权值。目前已经在Google code上开源,地址在这儿。欢迎大家使用并给
出意见。
6 效果评估
对于搜索结果,有多种量化搜索得分的计算方法,这里介绍NDCG和MAP。
6.1 NDCG(Normalized Discounted Cumulative Gain)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
7 参考
信息检索初学者's Learning to Rank 小结:http://blog.crackcell.com/2011/12/17/learning-to-rank_intro_note/
jiangfeng's 漫谈Learning to Rank:http://www.jiangfeng.me/blog/123
1: Adapting Ranking SVM to Document Retrieval. (Liu Tie Yan. et al. MSRA) 【PDF】
2: Learning to rank for Information Retrieval– tutorial. (Liu Tie Yan. et al. MSRA) 【PDF】
3: Learning to rank: From Pairwise Approach to Listwise Approace. (Liu Tie Yan. et al. MSRA)【PDF】
4: Learning to rank for Information Retrieval - book. (Liu Tie Yan. MSRA)【PDF】
5:Learning to Rank Report @ CIIR 2011 【PDF】