可观察性是Istio4大特性之一。在 Istio可观察性--Metrcis篇 文中我们讲到,Istio会为Istio服务网格内,外所有服务流量生成指标。这些度量标准提供有关行为的信息,例如总流量,流量中的错误率以及请求的响应时间。
这些丰富的指标信息,不仅可以准确描述服务行为和服务质量,而且可以用来作为工作负载弹性伸缩的标准参考。比如我们可以根据qps,来对工作负载进行弹性伸缩。
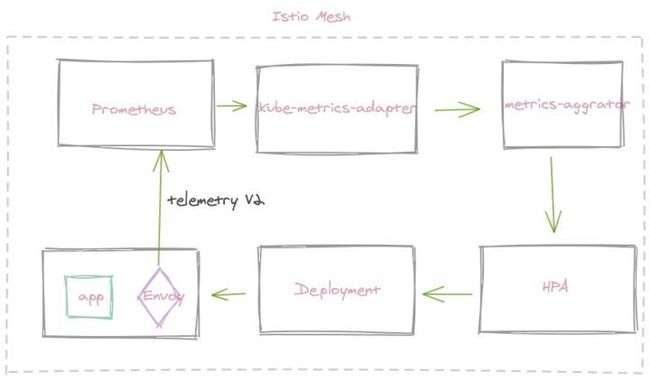
部署 kube-metrcis-adaptor
Kube Metrics Adapter 是Kubernetes的通用指标适配器,可以收集和提供用于水平Pod自动缩放的自定义指标和外部指标。
它支持基于Prometheus度量标准,SQS队列和其他现成的扩展。
它会发现Horizontal Pod Autoscaling资源,并开始收集请求的指标并将其存储在内存中。它是使用 custom-metrics-apiserver 库实现的。
我们使用helm3部署,部署之前先下载 Kube Metrics Adapter 代码仓库,然后进入到chart路径下,执行下面的语句:
helm -n kube-system install mesh ./kube-metrics-adapter --set prometheus.url=http://monitor-pod-agent.kube-admin.svc:9090
NAME: mesh
LAST DEPLOYED: Fri Nov 20 18:38:40 2020
NAMESPACE: kube-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
mesh-kube-metrics-adapter has been deployed.
In a few minutes you should be able to list metrics using the following command:
kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1
Also if you enabled external metrics:
kubectl get --raw /apis/external.metrics.k8s.io/v1beta1
Wait till deployment is done by:
kubectl -n kube-system rollout status deployment mesh-kube-metrics-adapter部署完成之后,我们可以确定一下pod是否正常运行:
kubectl get po -n kube-system |grep mesh-kube-metrics-adapter
mesh-kube-metrics-adapter-6cb47f849d-ts5jh 1/1 Running 0 154m部署示例程序
示例程序我们选择istio官方 httpbin。不过我们为了演示HPA,部署完成之后,查看一下pod运行状态:
kubectl get pods
NAME READY STATUS RESTARTS AGE
httpbin-779c54bf49-mvscg 2/2 Running 0 56s并创建了VirtualService 和Gateway,从而让我们可以从我们的压测机器上发起对httpbin的请求。
配置HPA
定义一个HPA,该HPA将根据qps来扩缩httpbin的工作负载数量。 当qps负载超过5 req/sec 时,以下配置将扩大负载数量。
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: httpbin
annotations:
metric-config.external.prometheus-query.prometheus/processed-requests-per-second: |
sum(
rate(
istio_requests_total{
destination_service_name="httpbin",
destination_service_namespace="default",
reporter="source"
}[1m]
)
)
spec:
maxReplicas: 5
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: httpbin
metrics:
- type: External
external:
metric:
name: prometheus-query
selector:
matchLabels:
query-name: processed-requests-per-second
target:
type: AverageValue
averageValue: "5"这是配置为基于Prometheus查询获取指标的HPA的示例。该查询在注释metric-config.external.prometheus-query.prometheus/processed-requests-per-second定义,其中processed-requests-per-second是与查询结果相关联的查询名称。必须在度量标准定义的matchLabels中定义匹配的query-name标签。这允许将多个Prometheus查询与单个HPA相关联。
列出Prometheus适配器提供的自定义外部指标。
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1" | jq .
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "external.metrics.k8s.io/v1beta1",
"resources": [
{
"name": "prometheus-query",
"singularName": "",
"namespaced": true,
"kind": "ExternalMetricValueList",
"verbs": [
"get"
]
}
]
}压测
我们使用wrk即可,
wrk -c10 -d180s -t8 --latency http://httpbin.example.com/压测过程中,我们观察hpa变化:
kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
httpbin Deployment/httpbin 17075m/5 (avg) 1 5 4 5m57s发现基准指标已经发生变化,示例数目也已经变化。
此时我们查看一下pod数目:
kubectl get pods
NAME READY STATUS RESTARTS AGE
httpbin-779c54bf49-hkqp7 2/2 Running 0 48s
httpbin-779c54bf49-ljj9z 2/2 Running 0 108s
httpbin-779c54bf49-mvscg 2/2 Running 0 14m
httpbin-779c54bf49-nxnz4 2/2 Running 0 108s
httpbin-779c54bf49-xldt7 2/2 Running 0 108s发现已经扩到最大值5。
压测结束之后一段时间,pod数目逐步减小,最终恢复到1个。