导读
搜索引擎是一种结合自然语言处理,信息检索,网页架构,分布式数据处理为一体的帮助用户准确解释信息获取信息的一种技术。

目前业界在网页端与手机端的主流门户搜索份额基本被各类巨头(图1.1)(SEO, 2020)所分割。当然,随着时代的发展,搜索越来越向以细分业务为主导的精细化门户搜索的方向发展。比如你会选择在知乎搜索专栏知识,在得物搜索潮流爆品,在美团点评搜索吃喝玩乐等等。
THE NO.1
信息检索
搜索引擎
我们要聊搜索引擎,那必然离不开信息检索(information retrieval)。
首先我们对何为信息检索需要有一个明确的定义:通过在一个大的数据集合中找到满足信息需求(information needs)的非结构化自然形式(通常指文本语料库)的材料(一般指代文章)(Manning, 2008)。
在检索信息时,有两个指标是在讨论搜索性能时无可避免。一个是召回率(recall),另一个是准确率(percision)。有趣的是,这两个指标就像一对孪生兄弟,总是此长彼消,此消彼长,因此,如何做好其中的制衡是各个搜索算法面临的问题。
本文作为搜索引擎技术的启蒙文章,主要针对文章结构、倒排索引、操作符与查找算法这四个维度来讲解一下搜索引擎的基本工作流程。
THE NO.2
文章结构
文档
首先我们来谈一谈搜索引擎都是如何理解它的那些文档的。在聊这个话题之前,我们要先明确一个定义,搜索引擎分为两种,网页级搜索引擎和公司级搜索引擎。
无论是那种搜索引擎,它们第一件需要解决的问题就是理解语料库,之后要做的就是存储语料库。
那么如何理解呢?现在让我们来看一下基本的文档的脉络机构。

很多时候人们一般认为文档就可以看作一个独立的词袋。但其实不然,每个文档其实是由不同的组成部分构成的。
比如一般网页的构建逻辑基本会是XML形式构成的,在大类上我们把它们分成三层,第一层是metadata,里面一般会有_url、关键字、作者、日期_等等,第二层是body,里面一般包含的就是像_标题、主体内容_这些信息。第三层是外部信息,主要有一些_外部链接与内部链接_跳转。
分区可以帮助我们对各个区块的信息量进行一个区分,原因在于每个区块的信息熵是不一样的。
简而言之,包含的信息量不一样,比如文章标题含有关键词的信息量就相对而言要大于段落中包含这个关键词所有的信息量。
得物搜索
在我们得物平台,主要有两个搜索主要发力点:商品和社区。那也可以进行这样的分层,虽然具体的信息分层方式有所变化,但是具体的设计逻辑依然不变。
根据香农定理里面的信息论,这些文档它们提供的信息价值是不同的,信息熵也是不同的,如果把他们混为一谈的话,我们搜索的准确度必然会有一定程度的降低。
一般而言,文档标题包含的信息量要略高于文档主体的信息量,通过将内部结构分层的操作,我们在后期进行算法干预的时候就可以人为的对其中的内容的权重进行调整,从而提高我们所召回内容与用户输入query符合度的准确程度,更好的满足用户的搜索期望。
THE NO.3
倒排索引
存储
讲完了文档的结构,我们就要讨论下如何对这些文档结构用数据结构进行存储。相信大家都知道,我们在搜索引擎存储信息一般采用倒排索引,而倒排索引主要分为两种索引结构。
第一种办法我们针对的是平铺的页面布局,也就是我前面所提到的将所有页面的各个区块独立对待的方法。说白了萝卜是萝卜,坑就是坑,各个信息块之间各自独立,没有交互。
而第二种结构我们采用的是垂直结构,也就是说,我们令页面中的各个布局存在层级关系。
我拿主体部分举个例子,主体部分 -> 区块 -> 段落 -> 句子。
平铺的页面布局
首先我们来讲下第一种归并倒排索引,我们看下构建模式。
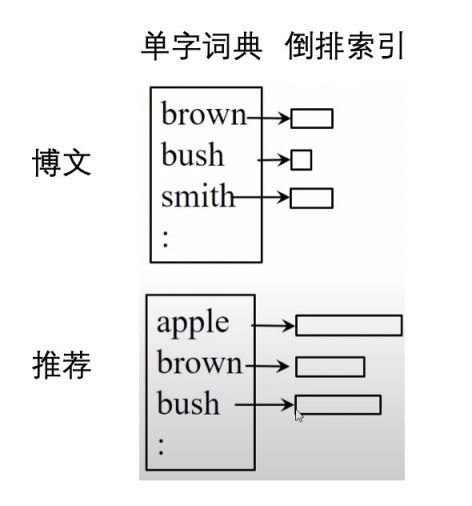
我们在推荐和博文这两个field里面都有一个词典,那我们在这儿要做的就是把各自的词典和它所对应的field合并起来。
在这里我们需要注意的是,一个term将会有多个倒排索引,比如说bush这个词,在推荐这儿我们为它构建了一个倒排,在博文这儿我们也为它构建了一个倒排。
在这种情况下,我们不会把不同field的信息杂糅在一起。很多次和bush一样都具有歧义性,通过建立各自独立的倒排索引,可以有效的保证信息的独立性。
垂直结构
有的时候我们搜索信息时,并不需要搜索到全部的信息,可能我们只想要搜索到特定位置的特定信息。

如果我们想要搜索句子里面的癌症,在归并结构下,我们的搜索进程就会变得很是复杂,我们要先从文章再到章节再到句子,很显然,如果采用这样的结构,我们的搜索速度很受到一定的影响。
因此,我们需要的采用一种比较精巧的独立倒排索引结构,这种结构一般面向的是那种相对比较复杂的文章结构。
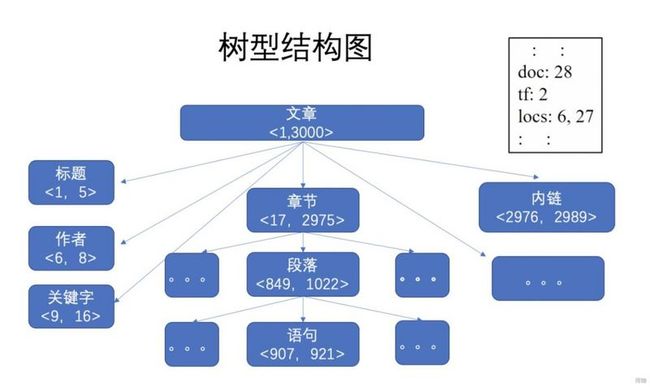
我们接下来看一下这个树形结构,在这种结构下,我们会记录下文档各个词所在的位置以及它们的上下级父子关系。
如果我们要搜索位于位置6和位置27的信息,我们就会先溯源到搜索脉络中所处的位置,之后用一种相对快速的方式快速检索到信息(log级别的速度)。
如果要搜在章节位置的信息,那么它就会丢弃loc为6的信息,因为loc为6的信息在树结构中属于作者这个区块。
这样的方式可以大大提升我们的搜索效率,而我们需要付出的只是唯不足道的一些内存而已,在这个云存储的时代,这样的操作非常具有性价比。
完全倒排
除此之外,我们也可以用完全倒排的方法来构建倒排索引-即独立倒排形式。
我们可以把field的边界阈值存放在倒排索引里面,另外构建一个term的倒排索引,通过把这两个进行归并,即可构建独立倒排。

比如说在这儿我们假设这是一个句子的倒排索引,开始和起始为止标注在那儿了,extentFreq表示这是第几个field。
当我们确立好loc的具体值时,我们只需要到旁边的[begin,end]判断是否在区域范围内,就可以快速确定这个loc包含的信息是否是我们需要的信息。
另外右侧的部分是tfidf的含义解读:
tfidf主要用来描绘出词汇在文章中的信息量;tf表示文章中包含该词的个数;df表示含有这个词的文章的个数;idf表示倒排文章频率,用来描绘文本稀缺度N表示总库存的文章数。
通过tfidf,我们可以对文章的信息度进行一个相对粗略的判断,可以说tfidf是信息检索的鼻祖算法,之后的一系列其他的算法都是对tfidf的补充及优化。
THE NO.4
Query操作符
操作符分类
操作符一般来说可以分为三类,一类用来构建新的倒排索引,其中有_#SYN,#NEAR,#WINDOW_;一类用来生成分数列表,它的操作符是_#SCORE_;一类用来合并生成好的分数列表,其中有_#AND,#OR,#WSUM_。
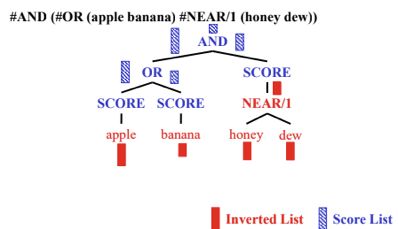
Callan, 2020*
分场景应用
这些操作符可以用来帮助我们在不同的情境下构建一些复杂的query。
NEAR或者WINDOW操作符
我们之前已经讲完了倒排索引,我们自然可以构建Nike ,AJ,阿迪等等的倒排索引,但是光这些基础结构很难满足我们的需求。因此,我们还需要一些其他结构的倒排索引,比如说布莱克奥巴马和AJ1。
这样的query其实是由两个或者多个词合并而出的短语,为了保证其中的次序性能够被正确识别,我们在这个时候就需要使用NEAR或者WINDOW操作符来进行词汇链接。
syn操作符
syn操作符可以用来构建一些概念性质的倒排,比如各类颜色的集合。
Score操作符
Score操作符比较容易理解,我们通过我们构建的一些记分算法来讲一个倒排索引构建成一份分数列表。
AND和#OR
#AND和#OR这些操作符则是用来合并已经构建好的分数列表。
THE NO.5
搜索算法
讲完了文章结构与操作符,搜索引擎的冰山一角已经被我们剖析了出来。
如果把搜索引擎比做修炼,那我们基础已经打完了,接下来我们进入硬核部分 - 搜索算法,了解完了搜索算法,那你基本可以开始尝试构建自己的小型搜索引擎了。
首先,我们讨论一下从倒排索引到分数列表过程中可能会使用到的一些粗排算法。
搜索引擎查找信息的过程其实是我们在用各种各样的方法来解释我们的信息,通过算法一步一步的压缩召回池的数量,最后通过排序来获得我们想要的信息(即排序好的文章)。
粗排
最简单的粗排算法就是UnRankedBoolean和RankedBoolean两种,它们都是精确查找的过程。在过去人们认为文档就是一个词袋的集合,那么只要进行精确查找就行了。
Unrankbooolean
Unrankbooolean顾名思义得到的信息是无序的。这种方法简单直接,得分匹配就是1,不匹配就是0。
在90年代前一直都是主宰级的办法,但是现在已经基本被淘汰了,因为人们开始逐渐发现人们很难确保query本身是准确的。
RankedBoolean
RankedBoolean就是给予文章得分,办法也很简单,单纯依据tf得分。
那我们讲完了基本被淘汰的exact match,我们来聊一聊best match,best match有以下几种:
- Vector space retrieval model (VSM)
- Probabilistic retrieval model (BM25)
- Statistical Language Model (query likelihood)
- Inference networks (Indri)
由于vector space已经基本被业界弃用了,所以我们这边不对它进行展开。
BM25
我们先主要聊一聊BM25。
BM25的展开公式如下图所示。
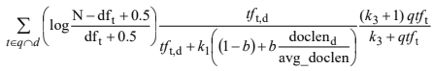
BM25算法由Steve Robertson创建。M25刚开始叫BM10,BM15,随着一系列的实验和调参最后成了现在这样。
第一部分叫RSJ weight,叫这个是因为Roberson开发了这个算法,Karen Spark Jones是他的mentor,辅助他开发了这个算法,所以联合命名为RSJ weight。
它其实很像idf,主要在idf上做了进一步的优化。
这边的tf weight主要是对文本的长度做了一个标准化(normalization)。因为一个词汇在如果在一篇20字的文本中出现了一次和在一篇2000字的文章中出现了一次,所代表的置信度应该是不一样的,通过标准化处理,我们可以在一定程度上消除长文章的不正当竞争优势。
另一块是user weight,主要用来调节用户的权重,这一部分我们可以相对忽略,业务在实际调参中,user weight的值一般为1。
在这三个可调节参数中,K1调节的是这个调节幅度的强度,B用来调节的是文本长度normalization的程度,K3用来调节的是用户权重的程度。
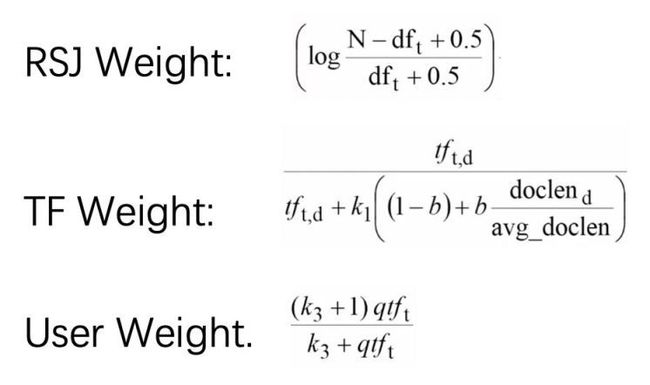
BM25到这儿基本结束,接下来我们讲下Two-Stage Smoothing算法。
Two-Stage Smoothing算法
要估计一个词汇在文档中出现的估计,很多人首相想到的可能是最大似然估计(Maximum Likelihood Estimation)。
但是在搜索中他是有缺陷的,比如说我们要搜镭射粉AJ夏款,那么可能镭射粉AJ是有的,但是夏款没有。
那么夏款这个词的MLE score就是0,而我们最后是要把镭射粉AJ的分数和夏款的分数相乘的,那么最后结果就是无结果,什么都搜索不到。
这个时候smoothing function就派上用场了,首先我们需要处理一些很少见的term,其次我们要平滑一些很短的文章。
首先我们先介绍下这个jelinek-mercer smoothing function,也叫混合模型。这个模型下我们会有两个最大似然估计,一个是query term基于文档的,一个是query term基于库的。
Lambda用来控制平滑的程度,一般来说当lambda趋向于0的时候,平滑程度趋向于0。那么如何选取lambda呢,我们的实验建议是小的lambda适用于短的query,是大的lambda适用于长的query。
另一个平滑方法是狄利克雷特先验平滑算法,这个算法它的目的是为了调节稀有词和高频词在词库中的出现频次。一般来说mu的值在1000到10000中为比较合适的范畴。
上述各个平滑算法及MLE算法的公式如下所示:
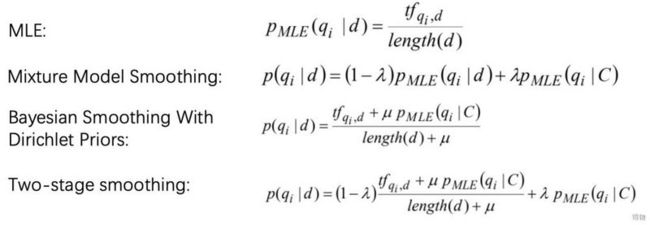
Indri
讲完了BM25和平滑算法,我们来讲一下Indri。
Indri是用统计语言模型和贝叶斯干扰网络构成的。
听起来可能很吓人,但是仔细总结一下,他的关键在于以下几点:
- 它是一个概率型检索模型
- query是结构化的
- 文档由多样的形式进行表现
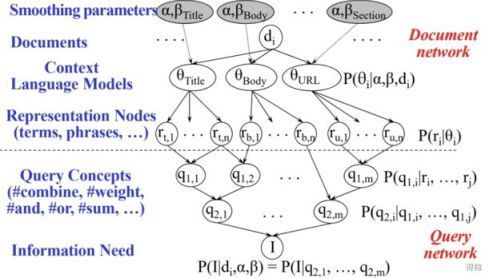
这个看起来很复杂,但其实并不复杂,具体表现形式如下:
Callan, 2020*
首先我们有一个网页,每个网页有着它所属的网络结构,比如说标题、主题、URL等等。那么很自然,我们可以将文章拆解为不同的区块。
与此同时,我们在前文提到过平滑模型,我们通过将平滑模型中的两个参数与文章结构相结合我们就可以得到一个文本语言模型,即在这个区块中的贝叶斯概率值。
另外,每一个文档区块都可以拆分成不同的子节点表现形式,比如单字、短语等等,它们也有着各自所对应的贝叶斯概率。这样的话,在文档层面我们就完成了语言模型到贝叶斯概率的转变。
然后我们往下看,I表示某个人的信息需求,这个信息需求一般由一个query来表示,而这个query又由许多子query来构建,我们现在可以思考一下and/or/Near等操作符。
对于每一个query,我们都可以先用nlp拆词拆分成小的单字,再通过操作符进行组合构建,这样每一个query概念就也包含了各自的贝叶斯概率。这就构建了一个query网络。
之后,我们就可以将query网络和我们的文档网络建立连接。通过对query网络和文章网络对似然度进行匹配,我们就可以尽可能准确的找到准确度较高的文章,这就是我们整个Indri网络的体系流程。
引文说明
SEO, 2020. SEO Search Engine - SEO Rank Services. [online] SEO Rank Services. Available at: https://seorankservices.com/search-engines-optimize-site/seo-search-engine/ [Accessed 3 February 2020].
Manning, C., 2008. Introduction To Information Retrieval. 1st ed.
Callan, J., 2020. Search Engine 11642 - Carnegie Mellon University.
文|Ray
关注得物技术