对于任何一家业务快速成长的企业来说,应对峰值流量冲击,一直是摆在技术团队面前的一大难题。面对海量数据,数据库及业务团队都希望做到“无感扩容”,但流行的分库、分表方案在扩容速度和一致性上经常不能满足需求。行业期待着性能强大、简单易用的全新数据库方案,从根本上解决企业面对流量高峰时的数据库性能瓶颈。
行业需求是技术创新的最大推动力。近年来,由 PingCAP 开发的 TiDB 分布式数据库异军突起,在海量数据处理领域具有很大的优势。在此背景下, 2020 年初京东智联云联合 PingCAP,基于 TiDB 打造了云端分布式数据库——Cloud-TiDB 。
11 月 26 日,京东智联云与英特尔联合举办了主题为“突破极限,TiDB 在京东智联云的技术架构与实践”的线上直播活动。直播邀请到 京东智联云云产品研发部架构师葛集斌老师,和 PingCAP TiDB 生态技术布道专家戚铮老师 分别带来分享,希望借此机会帮助更多企业和开发人员拓展思路,提供一个分库分表途径之外的新选择,并了解如何在生产实践中发挥 TiDB 的价值。
本文总结自本场直播分享,内容有调整。
一、TiDB在京东智联云的技术架构与实践
直播第一部分,葛老师深入分析了京东智联云为何选择 TiDB 数据库,并介绍了 TiDB 在京东智联云上的技术架构和技术生态细节。
1,TiDB数据库希望解决哪些问题
传统单机数据库在当下的大数据时代暴露出了越来越多的局限性,对于一家快速增长的企业来说,由于数据量会随着企业规模有序扩大,单机数据库很快就会遭遇多个瓶颈:
- 单表、单库数据量过大;
- 单机存储容量达到上限;
- 单机处理能力达到瓶颈。
- 读取延迟和存储需求上升,并且无法扩展写入性能。
- 想要继续提升性能,传统方法就是对数据库进行分库分表,但分库分表也存在很多天然约束。
- 在高可用性方面,MySQL 需要集成外部程序来处理。
- MySQL 的故障检测、主从判断和转移都需要定制策略。
- 异步和半同步复制是非强一致性的,增加了数据丢失的风险。
- 此外,MySQL 的 OLAP 数据处理能力较弱,数据分析需求还需要 ETL 到外部分析系统。以上这些都是传统数据库方案现实存在的瓶颈。TiDB 的诞生,就是为了解决这些传统数据库常见的问题,希望能够从根本上突破单机数据库的能力极限。
具体到技术层面,TiDB 数据库有哪些良药来应对上述问题呢?首先要明确的是,TiDB 不同于传统单机架构,而是一个真正意义上的分布式数据库。采用计算、存储分离的架构设计,提供水平线性扩展能力。它还具备强一致性、高可用性,支持自动故障恢复,可以对数据进行实时分析。另外它还高度兼容 MySQL 协议。整体架构来看,TiDB 分为 TiDB Server、分布式存储层和 PD 三大部分:
- TiDB Server 兼容 MySQL 协议,可以水平扩展,因此用户可以将 TiDB 当作 MySQL 使用。
- TiDB 存储层 TiKV 是分布式 KV 存储,可以线性扩展,并通过多副本和 Raft 协议保证强一致性。TiKV 还分为多个 region,以 region 为单位进行管理。数据分布在各个 TiKV 节点上,节点可以水平扩展。
- PD 负责集群管理,包括调度和负载均衡工作,并负责生成全局的 TSO 时间戳。PD 本身也是无单点故障的集群。
TiDB 使用 TiFlash 列存储引擎来支持实时数据分析。它通过 Raft learner 进行异步复制,配合 MVCC 提供强一致性读取,还支持计算下推,使得其 AP/TP 功能相互无干扰。使用 TiFlash 时 TiDB 优化器会计算查询代价,根据结果自动选择 TiKV 行存或 TiFlash 列存。
基于这样的架构设计,TiDB 集群实现了整体的高可用性和数据强一致性,即使少数副本丢失也能自动完成数据修复和故障转移,不会干扰业务层。TiDB 可以实现跨中心的异地多活部署。
2,云上TiDB的实现和功能
近年来,京东智联云的客户对数据处理能力的需求不断提升。针对这样的需求, 京东智联云与 PingCAP 联合,基于 TiDB 打造了云端分布式数据库——Cloud-TiDB ,主要面向高性能、高可靠、高可用场景。
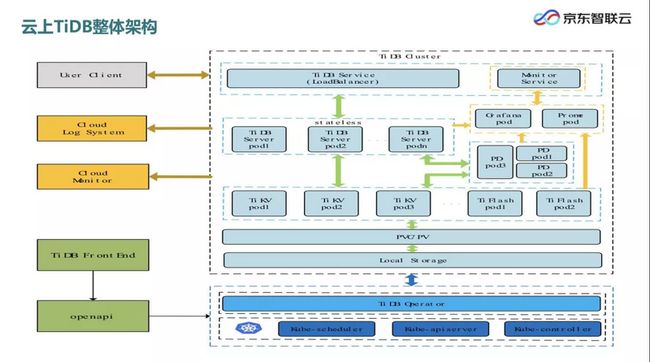
上图为京东智联云 Cloud-TiDB 的整体架构,基于这样的架构,Cloud-TiDB 提供了一些业务价值较高的功能,包括水平弹性扩容、备份和恢复、实时数据分析、数据迁移和同步、云端监控告警等。
- 水平弹性扩容。TiDB 可以在线动态增减存储和计算节点,具备接近无限的水平扩展能力。伸缩操作后,数据库还可以自动实现数据再均衡。
- 备份和恢复。TiDB 支持自动 / 手动全量备份,并将数据备份在 OSS 中。恢复时数据不会覆盖原有集群,可有效防止误操作。
- 实时数据分析。在支持 OLTP 的同时提供业务数据的实时分析和处理。
- 数据迁移和同步。支持全量 / 增量迁移,可以将数据同步到 MySQL、Kafka 下游存储中。
- 监控与告警。TiDB 提供了丰富的监控指标,支持浏览器直接访问。云监控提供资源 / 业务层面的监控告警,云日志可以配置错误日志监控报警。除上述能力外,在实践应用中 Cloud-TiDB 的另一大优势就是更低的运维成本。Cloud-TiDB 可以很好地满足云服务按需伸缩的需求,使用户可以精确地控制资源使用量,避免资源浪费。
选择一项新技术的同时也是在选择一个生态,生态越完善,开发和运维效率也会越高。TiDB 生态的一大特点就是兼容 MySQL 协议,从而可以受惠于成熟的 MySQL 生态资源。MySQL 的所有数据库驱动、第三方开发 / 管理工具、数据交换 / 迁移工具等,都可以用于 TiDB 数据库。
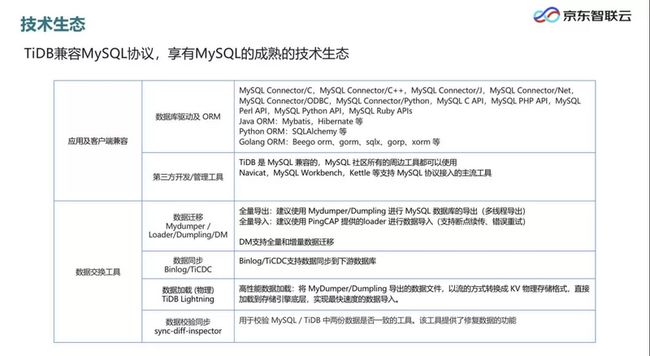
TiDB 与其他主流数据处理技术也可以方便地互联互通。例如 TiDB 数据可以导入 Kafka,接入 Flink,乃至 Hive、HDFS、Amazon S3、Spark 等。用户无需担心技术锁定风险,这也为 TiDB 的生态繁荣打下了基础。
在分享的最后,葛老师对云端数据库的发展趋势做了展望:
分布式是未来技术发展的重要趋势之一,包括操作系统、应用程序和数据库都在向分布式转变。TiDB 作为分布式数据库,比较符合这一技术发展趋势。与此同时,数据库上云可以带来很多好处,例如弹性调度、与 AI 结合,还能更好地理解用户的业务视角,实现数据处理的智能优化。
长远来看,数据库上云可以在开发、运维和稳定性层面获得很大收益。正因如此,京东智联云选择 TiDB 上云,就是希望能给用户带来更好的使用体验。
二、TiDB在大数据量和高并发场景下的应用
葛老师的演讲结束后,来自 PingCAP 的 TiDB 生态技术布道专家戚铮分享了 TiDB 在大数据量和高并发场景下的应用实践。
1,TiDB与SHARDING 在 OLTP场景下的解决方案对比
当企业遇到海量数据需求时,往往伴随数据量短期内急剧增长的压力。这样的业务需要数据库具备快速扩容能力和高并发能力,在响应延迟和吞吐量指标上都有足够高的水平以应对突发流量。而 OLTP 场景主要涉及线上 2C 交易,对数据库稳定性要求较高,数据库性能波动会直接影响用户体验。
针对这样的需求特点,业内常见的解决方案分为 Sharding、New SQL 和中间的 DB-Based 几大类型。其中,ShardingSphere 和 TiDB,就是第一和第三种类型中的两个典型。两者都是当下活跃的开源项目,分别代表了应对海量数据需求的两大思路。所谓 Sharding 就是分库分表,实践中主要分为水平拆分和垂直拆分两大纬度。垂直纬度一般按照业务模块或者数据系列来拆分,水平纬度可以按取模、时间、冷热库等方式拆分。Sharding Sphere 作为分库分表思路的代表,其架构大致如下:
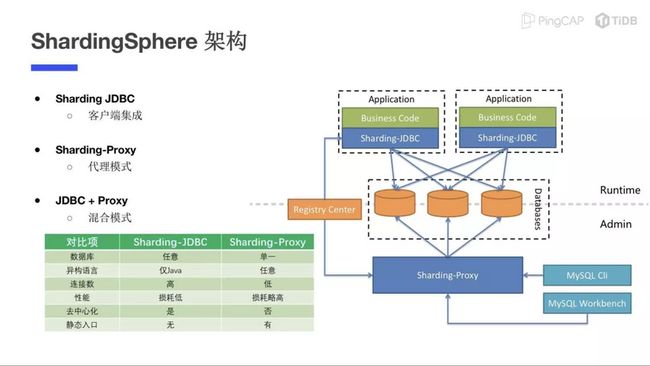
与前文列举的 TiDB 架构相比,Sharding 架构的数据备份、高可用、监控告警等需求,都需要周边第三方工具来配置解决。而 TiDB 自身就是完整的解决方案,可以一站式满足用户对高性能数据库的各项要求。如今 ShardingSphere 也开始在新版中开始向整体分布式数据库方案转型,从侧面印证了分布式数据库是未来的必然趋势。
2,TiDB的海量数据应用案例
TiDB 的初衷就是解决分库分表存在的许多问题,但某些场景并不太适合向 TiDB 迁移。具体来说,这样的场景中业务不会有快速增长,业务请求比较简单,也没有分布式事务需求。除了这样的场景以外,大部分海量数据需求都可以通过向 TiDB 迁移得到较好的解决。戚老师这里列举了几个实践案例。
某社区个性化首页和推送业务。由于海量用户的个性化推送业务特性,数据库每天需要生成 30 亿条数据,历史数据高达万亿量级,业务对吞吐量和延迟也高度敏感。该用户原有的 MySQL 方案基于分库分表,但 MySQL 实例总量达到上百个,风险和延迟都难以满足需求。经过调研,用户认为 TiDB 是唯一能满足他们对高扩展、强一致、高可用需求的解决方案,因此决定全面迁移。在迁移过程中,PingCAP 开发了一个快速导入工具 Lightning 结合 DM 工具来平滑转移数据,迁移完成后又做出了一系列优化,最终很好地满足了需求。尤其令用户满意的是新架构具备很强的扩展能力,迁移后数据量从 1.3 万亿逐渐增长至 1.8 万亿,性能、可用性依旧保持在很高的水平上,成本相比过去也没有明显增加。
某电信个人账单系统。该用户账单总表有 80 亿数据,对性能要求很高,而原有的 MyCAT 方案已接近扩展极限,只能存储不足一年的历史数据。由于 MySQL 分库分表的处理瓶颈,继续分片会出现不少问题,故此用户选择了 TiDB 进行升级换代。向 TiDB 迁移后,单表数据量即可达到 100 亿,数据存储周期由半年延长至 3-5 年,QPS 和延迟都有显著改善。
戚老师还介绍了某 O2O 平台 PMC 订单流水业务、某金融核心账务系统和某互金营销平台向 TiDB 迁移的案例。这些案例的共同点都是用户原有的数据库分库分表遇到了增长瓶颈,对业务造成了越来越多的负面影响,而迁移到 TiDB 后完全解决了原有瓶颈,迁移过程没有遇到严重故障,成本投入也在可控范围内。
3,TiDB 5.0 亮点解析
分享的最后环节,戚老师介绍了 TiDB 5.0 版本的性能优化亮点和细节,主要包括以下几项特性。
Async Commit。旧版 TiDB 采用两阶段提交模式,开销相对较大。Async Commit 主要在第二阶段实现了异步提交,对于小事务达到类似 1PC 的效果,从而带来了一定的性能提升。
Clustered Index。新版的这一特性很适合条件范围包含主键列的查询,类似 Innodb 聚簇索引,可以节省这类查询的回表成本。根据 TPCC 测试,新版在这方面可以带来一定性能增幅。
Compaction Filter。该特性主要针对后台自动整理压缩数据引起的性能抖动进行优化,开启后 QPS 的波动标准差降低到了 5% 以内。
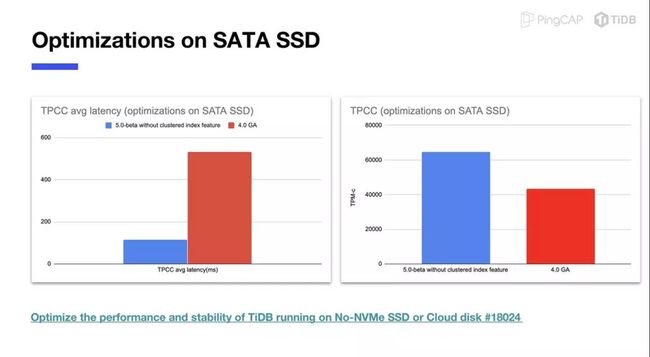
SATA SSD 优化。结合 compaction filter,fsync control,compaction guard 等这些新增特性,5.0 版本在 SATA SSD 上的性能吞吐和延迟表现都比 4.0 有了较大改善,由于 SATA 盘本身抖动导致的 QPS 抖动也有明显下降。
三、突破容量极限,TiDB打破企业数据库性能瓶颈
相比传统的分库分表,TiDB 是真正一站式的分布式数据库整体解决方案,能够充分满足企业业务快速增长、海量数据高并发、实时数据分析和金融数据高可用等场景的苛刻需求。通过本场直播两位老师的精彩分享,听众对 TiDB 数据库的能力、实现细节和业务落地实践都有了更深入的认知,也了解了 TiDB 数据库服务的各项突出优势。
正如两位老师所言,分布式数据库是业内必然的发展趋势,而 TiDB 顺应了这一潮流,将成为越来越多企业根治数据库性能瓶颈的良方。与此同时,TiDB 在京东智联云的应用,为企业快速采用 TiDB、尽早享受 TiDB 收益和价值开辟了一条便捷通道。
想要了解更多京东智联云与 TiDB 相关内容,获取演讲PPT,可在评论区评论PPT,我们会及时回复获取方式。
点击 【 阅读原文 】 查看视频回放链接。
推荐阅读:
欢迎点击【京东智联云】,了解开发者社区
更多精彩技术实践与独家干货解析
欢迎关注【京东智联云开发者】公众号
