C5.0算法学习
C5.0是决策树模型中的算法,79年由J R Quinlan发展,并提出了ID3算法,主要针对离散型属性数据,其后又不断的改进,形成C4.5,它在ID3基础上增加了队连续属性的离散化。C5.0是C4.5应用于大数据集上的分类算法,主要在执行效率和内存使用方面进行了改进。
C4.5算法是ID3算法的修订版,采用GainRatio来加以改进方法,选取有最大GainRatio的分割变量作为准则,避免ID3算法过度配适的问题。
C5.0算法则是C4.5算法的修订版,适用于处理大数据集,采用Boosting方式提高模型准确率,又称为BoostingTrees,在软件上计算速度比较快,占用的内存资源较少。
决策树模型,也称规则推理模型。通过对训练样本的学习,建立分类规则;依据分类规则,实现对新样本的分类;属于有指导(监督)式的学习方法,有两类变量:目标变量(输出变量),属性变量(输入变量)。
决策树模型与一般统计分类模型的主要区别:决策树的分类是基于逻辑的,一般统计分类模型是基于非逻辑的。
常见的算法有CHAID、CART、Quest和C5.0。对于每一个决策要求分成的组之间的“差异”最大。各种决策树算法之间的主要区别就是对这个“差异”衡量方式的区别。
决策树很擅长处理非数值型数据,这与神经网络智能处理数值型数据比较而言,就免去了很多数据预处理工作。
C5.0是经典的决策树模型算法之一,可生成多分支的决策树,目标变量为分类变量,使用C5.0算法可以生成决策树或者规则集。C5.0模型根据能偶带来的最大信息增益的字段拆分样本。第一次拆分确定的样本子集随后再次拆分,通常是根据另一个字段进行拆分,这一过程重复进行指导样本子集不能在被拆分为止。最后,重新缉拿眼最低层次的拆分,哪些对模型值没有显著贡献的样本子集被提出或者修剪。
C5.0优点:
C5.0模型在面对数据遗漏和输入字段很多的问题时非常稳健;
C5.0模型比一些其他类型的模型易于理解,模型退出的规则有非常直观的解释;
C5.0也提供强大技术以提高分类的精度。
C5.0算法
C5.0算法选择分支变量的依据:以信息熵的下降速度作为确定最佳分支变量和分割阀值的依据。信息熵的下降意味着信息的不确定性下降。
信息熵:信息量的数学期望,是心愿发出信息前的平均不确定性,也称先验熵。
信息ui(i=1,2,…r)的发生概率P(ui)组成信源数学模型,å P(ui)=1;
信息量(单位是bit,对的底数取2):

信息熵:先验不确定性:
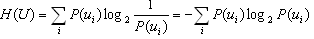
决策树中熵的应用:
设S是一个样本集合,目标变量C有K个分类,freq(Ci,S)表示属于Ci类的样本数,|S|表示样本几何S的样本数。则几何S的信息熵定义为:
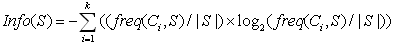
如果某属性变量T,有N个分类,则属性变量T引入后的条件熵定义为:
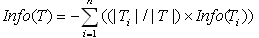
属性变量T带来的信息增益为:

C5.0算法示例:
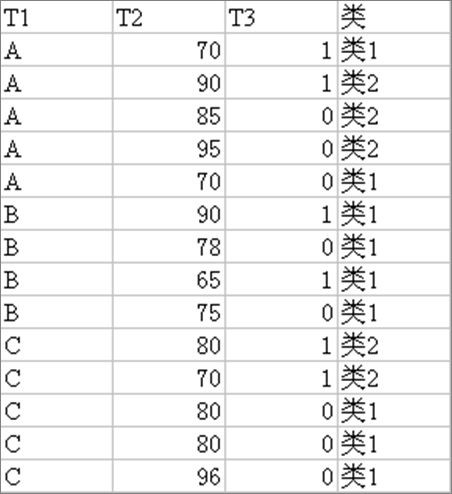
该组样本的熵:
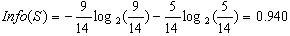
关于T1的条件熵为:
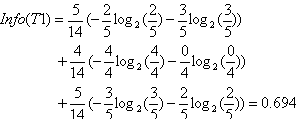
T1带来的信息增益为:
