Intel64及IA-32架构优化指南——3.5 优化执行核心
3.5 优化执行核心
在最近微架构产品中的超标量、无序执行核心含有多个执行硬件资源,可以并行地执行多个微操作。这些操作一般确保微操作高效地执行并以固定的延迟执行下去。利用可用的并行性的通用准则有:
● 遵循规则(3.4小节)以最大化有用的译码带宽以及前端吞吐。这些规则包括偏向使用单个微操作指令并利用微融合、栈指针追踪器以及宏融合。
● 最大化重命名带宽。在本小节所讨论到的准则包含适当的对部分寄存器、ROB[译者注:重排序缓存]读端口以及对标志引起副作用的指令的处理。
● 对指令序列的调度建议,使得多个依赖链在保留站(RS)中同时处于活动状态,从而确保你的代码利用最大的并行度。
● 避免危机,最小化可能发生在执行核心的延迟,允许被分派的微操作不断继续进行并快速地为隐退做好准备。
3.5.1 指令选择
某些执行单元不被流水化,这意味着微操作不能在连续的周期内被分派并且吞吐在每周期少于一个。
通过考虑与每条指令相关联的微操作的个数通常是选择指令的一个好的出发点,偏向这个顺序:单个微操作指令,少于4个微操作的单个指令,需要微顺序器ROM的最后指令(在微顺序器之外执行的微操作涉及额外的负荷)。
汇编/编译器编码规则28:偏向使用单个微操作指令。也偏向使用具有更短延迟的指令。
一个编译器在指令选择上可能已经做了一个好工作。如果这样,用户干涉通常是没有必要的。
汇编/编译器编码规则29:避免指令前缀,尤其是多个不带前缀的操作码。
汇编/编译器编码规则30:不要使用许多段寄存器。
在奔腾M处理器上,只有一级段寄存器的重命名。
汇编/编译器编码规则31:避免使用复杂指令(比如enter、leave或loop),它们具有多于四个微操作并需要多个周期来译码。使用简单指令序列来代替它们。
汇编/编译器编码规则32:在函数调用/返回之间使用push/pop来管理栈空间和地址调整而不是enter/leave。用非零立即数使用enter指令在流水线内除了错误预测外还会导致严重的延迟。
在Intel NetBurst微架构中,复杂指令会节省架构寄存器,但遭受4个微操作的处罚来为微顺序器ROM建立参数。理论上,安排指令序列来匹配4-1-1-1模板[译者注:在Intel Core微架构中,译码器0能够译码Intel 64和IA-32指令达到4个微操作。而三个其它译码器每个周期处理单个微操作。]应用于基于Intel Core微架构的处理器。然而,在前端中带有宏融合和微融合的特性,试图使用4-1-1-1模板来调度指令序列,回报将会变小。
取而代之的是,软件应该遵循以下这些额外的译码器准则:
● 如果你需要使用有多个微操作、没被微顺序的指令,设法用一些简单操作的指令进行独立开。下列指令是使用不需要微顺序器带有多个微操作的指令的例子:
ADC/SBB
CMOVcc
读-修改-写指令
● 如果一串多个微操作指令不能被独立开,设法将它们分解成一个不同等价指令序列。比如,一串读-修改-写指令可以变得更快,如果被串成一列读-修改+存储指令。这个策略可以提升性能,即使新的代码序列比原来的更大。
3.5.1.1 对INC和DEC指令的使用
INC和DEC指令只修改标志寄存器中的标志位的一个子集。这创建了所有先前对标志寄存器的写的依赖。当这些指令在关键路径上时,这尤为成问题,因为他们被用于为一次加载而改变一个地址,而许多其它指令依赖这个加载。[译者注:这里所描述的应用场景是将INC/DEC的操作数作为与寻址相关的寄存器,比如:inc edx; mov eax, [edx]]
汇编/编译器编码规则33:INC和DEC指令应该用ADD或SUB指令代替,因为ADD和SUB会重写所有的标志,而INC和DEC只是部分的,从而对早先设置标志的指令产生错误的依赖。
3.5.1.2 整数除法
一般,在做一个整数除法之前会用一条CWD或CDQ指令。依赖于操作数大小,除法指令使用DX:AX或EDX:EAX作为被除数。CWD或CDQ指令分别将AX或EAX带符号扩展到DX或EDX。这些指令比起一个移位和搬移具有更密集的编码,但它们产生了相同数量的微操作。如果AX或EAX已知是正的,那么用以下指令来代替:
xor dx, dx
或
xor edx, edx
现代编译器一般将涉及到整数除法并且除数是一个在编译时已知的常量的高级语言表达式转换为使用IMUL指令的更快速的序列。因而程序员应该最小化用在编译时未知的除数的值来写整数除法表达式。
可替换地,如果某个已知除数值有利于其它未知范围,那么软件会考虑将最不有利的已知的除数值在常量除数表达式中分离出来。
9.2.4小节描述了使用MUL/IMUL来替代整数除法的更多细节。
3.5.1.3 使用LEA
在代号名为Sandy Bridge的Intel微架构中,对LEA指令的性能特征有两个重要的改变:
● LEA在大部分情况下可以通过端口1和5来被分派,对于先前的处理器有了双倍的吞吐。然而这只应用于带有一个或两个源操作数的LEA指令。
例3-18:独立的两个操作数的LEA例子
mov edx, N mov eax, X mov ecx, Y loop: lea ecx, [ecx=ecx * 2] lea eax, [eax = eax * 5] and ecx, 0xff and eax, 0xff dec edx jg loop
● 对于带有三个源操作数和某些特定场景的LEA指令,指令延迟会增加到3个周期,而且只能通过端口1分派:
——具有全部三个源操作数的LEA:基、索引和偏移
——使用基和索引寄存器的LEA,这里基为EBP、RBP或R13
——使用RIP相对寻址模式的LEA
——使用16位寻址模式的LEA
例3-19:对三操作数的LEA的替换
; 3操作数更慢 #define K 1 uint32 an = 0; uint32 N = mi_N; mov ecx, N xor esi, esi xor edx, edx cmp ecx, 2 jb finished dec ecx loop1: mov edi, esi lea esi, [K + esi + edx] and esi, 0xFF mov edx, edi dec ecx jnz loop1 finished: mov [an], esi ; 可替换的两个操作数的LEA #define K 1 uint32 an = 0; uint32 N = mi_N; mov ecx, N xor esi, esi xor edx, edx cmp ecx, 2 jb finished dec ecx loop1: mov edi, esi lea esi, [K + edx] lea esi, [esi + edx] and esi, 0xFF mov edx, edi dec ecx jnz loop1 finished: mov [an], esi ;代替2 #define K 1 uint32 an = 0; uint32 N = mi_N; mov ecx, N xor esi, esi mov edx, K cmp ecx, 2 jb finished mov eax, 2 dec ecx loop1: mov edi, esi lea esi, [esi + edx] and esi, 0xFF lea edx, [edi + K] dec ecx jnz loop1 finished: mov [an], esi
在基于NetBurst微架构的处理器的某些情况下,LEA指令或一串LEA、ADD、SUB和SHIFT指令可以代替常量乘法指令。LEA指令也可以被用作为一多操作数的额外指令,比如:
LEA ECX, [EAX + EBX + 4 + A]
以这种方法使用LEA可以通过不对算术指令的操作数捆绑寄存器来避免寄存器的使用。这也可以节省代码空间。
如果LEA指令用一个常量来使用一个移位,那么微操作序列的延迟会更短,如果使用的是加法而不是移位,并且LEA指令可以用一串合适的微操作序列来代替。然而,这会增加微操作数的总数,导致一个权衡。
汇编/编译器编码规则34:如果使用带缩放的索引的一个LEA指令在关键路径上,那么带有ADD的一串指令序列可以会变得更好。如果在踪迹Cache外的代码密度和带宽是关键因子,那么使用LEA指令。
3.5.1.4 在代号名为Sandy Bridge的Intel微架构中的ADC和SBB
在代号名为Sandy Bridge的的Intel微架构中的ADC和SBB的吞吐与先前处理器的1.5到2个周期比较起来为1个周期。这两条指令在对不超过硬件内部最大宽度的整数数据类型的数值处理中有用。
例3-20:512位加法
; 64位到512位数加法 lea rsi, gLongCounter lea rdi, gStepValue mov rax, [rdi] xor rcx, rcx loop_start: mov r10, [rsi+rcx] add r10, rax mov [rsi+rcx], r10 mov r10, [rsi+rcx+8] adc r10, 0 mov [rsi+rcx+8], r10 mov r10, [rsi+rcx+16] adc r10, 0 mov [rsi+rcx+16], r10 mov r10, [rsi+rcx+24] adc r10, 0 mov [rsi+rcx+24], r10 mov r10, [rsi+rcx+32] adc r10, 0 mov [rsi+rcx+32], r10 mov r10, [rsi+rcx+40] adc r10, 0 mov [rsi+rcx+40], r10 mov r10, [rsi+rcx+48] adc r10, 0 mov [rsi+rcx+48], r10 mov r10, [rsi+rcx+56] adc r10, 0 mov [rsi+rcx+56], r10 add rcx, 64 cmp rcx, SIZE jnz loop_start ; 512位加法 loop1: mov rax, [StepValue] add rax, [LongCounter] mov LongCounter, rax mov rax, [StepValue+8] adc rax, [LongCounter+8] mov LongCounter+8, rax mov rax, [StepValue+16] adc rax, [LongCounter+16] mov LongCounter+16, rax mov rax, [StepValue+24] adc rax, [LongCounter+24] mov LongCounter+24, rax mov rax, [StepValue+32] adc rax, [LongCounter+32] mov LongCounter+32, rax mov rax, [StepValue+40] adc rax, [LongCounter+40] mov LongCounter+40, rax mov rax, [StepValue+48] adc rax, [LongCounter+48] mov LongCounter+48, rax mov rax, [StepValue+56] adc rax, [LongCounter+56] mov LongCounter+56, rax dec rcx jnz loop1
3.5.1.5 按位环移
按位环移在以CL寄存器中所指定的计数进行循环位移与用一个立即数常量和用1比特进行循环位移之间选择。一般来说,用立即数进行循环位移和用寄存器进行循环位移的指令比用1进行循环位移要慢。用1进行循环位移的指令具有与一个移位相同的延迟。
汇编/编译器编码规则35:避免用寄存器环移或用立即数环移。如果可能的话用以1环移指令来代替。
在代号为Sandy Bridge的Intel微架构中,ROL/ROR用立即数具有1个周期的吞吐,SHLD/SHRD使用与源和目的相同寄存器移位一个立即数常量具有一个周期延迟和0.5个周期吞吐。“ROR/ROL reg, imm8”指令具有两个微操作,环移寄存器的结果要1个周期延迟和2个周期的标志,如果使用标志的话。
在代号名为Ivy Bridge的Intel微架构中,"ROL/ROR reg, imm8"指令,立即数大于1,是一个微操作并具有1个周期延迟,当溢出标志结果被使用时。当立即数为1,受后一条指令所依赖的ROL/ROR溢出标志,将会看到ROL/ROR指令具有两个周期延迟。
3.5.1.6 可变位计数环移和移位
在代号名为Sandy Bridge的Intel微架构中,“ROL/ROR/SHL/SHR reg, cl”指令具有三个微操作。当不需要结果标志时,这些微操作的一个可以被丢弃,在许多公共使用中提供了更好的性能。当这些指令更新了部分标志结果,而这些结果在后面要被使用时,这三个微操作流必须完整地穿过执行和隐退流水线,会表现出更慢的性能。在代号名为Ivy Bridge的Intel微架构中,执行完整的三个微操作流来使用已被更新的部分标志结果具有额外的延迟。考虑以下循环序列:
loop: shl eax, cl add ebx, eax dec edx ; DEC并不更新进位标志,导致SHL要执行更慢的三微操作流 jnz loop
DEC指令不修改进位标志。结果,SHL EAX, CL指令在后续迭代中需要执行三微操作流。SUB指令将更新所有标志。因此用SUB来代替DEC将会允许SHL EAX, CL来执行两个微操作流。
3.5.1.7 地址计算
对于地址计算,使用寻址模式而不是通用目的计算。内部地,存储器引用指令可以具有四个操作数:
● 可重定位的加载时常量
● 立即数常量
● 基寄存器
● 缩放索引寄存器
注意带有多于两个操作数的LEA的延迟和吞吐在代号名为Sandy Bridge的Intel微架构中会更慢(见3.5.1.3小节)。同时使用基地址和索引寄存器的寻址模式在执行引擎中将消耗更多的读端口资源,从而会引起更多的延迟,由于读端口资源的能力。软件应该小心地选择地址计算的快速版本。
在分段模型中,一个段寄存器在线性地址计算中可以构成一个额外的操作数。在许多情况下,可以通过全面地使用存储器引用的操作数来消除若干条整数指令。
3.5.1.8 清除寄存器和依赖打破习语
修改部分寄存器的代码序列在其依赖链中会引起一些延迟,但可以通过使用依赖打破习语来避免。
在基于Intel Core微架构的处理器中,一些指令可以帮助清除执行依赖,当软件使用这些指令将寄存器内容清零时。这些指令包括
XOR REG, REG SUB REG, REG XORPS/PD XMMREG, XMMREG PXOR XMMREG, XMMREG SUBPS/PD XMMREG, XMMREG PSUBB/W/D/Q XMMREG, XMMREG
在基于代号名为Sandy Bridge的Intel微架构的处理器中,上述所列的指令加上等价的AVX指令也是零习语,可以被用于打破依赖链。此外,它们不消耗一个发布端口或一个执行单元。因此,使用零习语比起将0移入寄存器更好。AVX等价的零习语是:
VXORPS XMMREG, XMMREG
VXORPS YMMREG, YMMREG
VPXOR XMMREG, XMMREG
VSUBPS/PD XMMREG, XMMREG
VSUBPS/PD YMMREG, YMMREG
VPSUBB/W/D/Q XMMREG, XMMREG
在Intel Core Solo和Intel Core Duo处理器中,XOR、SUB、XORPS或PXOR指令可以被用于清除对目的寄存器的零计算的执行依赖。
奔腾4处理器提供了对XOR、SUB和PXOR操作特殊的支持,当在同一个寄存器内执行时。这识别了清除一个寄存器不依赖于该寄存器旧的值。XORPS和XORPD指令没有这种特殊支持。它们不能被用于打破依赖链。
汇编/编译器编码规则36:使用依赖打破习语指令将一个寄存器设置为0,或者打破导致寄存器重使用的一个错误依赖。在条件码必须被保留的上下文中,将0移到寄存器中。这需要比使用XOR和SUB更多的代码空间,但避免了设置条件码。
例3-21,当对一个数组执行取相反数时,使用PXOR来对一个XMM寄存器打破依赖性习语。
int a[4096], b[4096], c[4096]
for(int i = 0; i < 4096; i++)
c[i] = -(a[i] + b[i]);
例3-21:在对数组元素取相反数时,清除寄存器来打破依赖性
; 没打破依赖性的取相反数(-x = (x XOR (-1)) - (-1) lea eax, a lea ecx, b lea edi, c xor edx, edx movdqa xmm7, allone lp: movdqa xmm0, [eax+edx] paddd xmm0, [ecx+edx] pxor xmm0, xmm7 psubd xmm0, xmm7 movdqa [edi+edx], xmm0 add edx, 16 cmp edx, 4096 jl lp ; 使用PXOR reg, reg来打破依赖取相反数(-x = 0 - x) lea eax, a lea ecx, b xor edx, edx lp: movdqa xmm0, [eax+edx] paddd xmm0, [ecx+edx] pxor xmm7, xmm7 psubd xmm7, xmm0 movdqa [edi+edx], xmm7 add edx, 16 cmp edx, 4096 jl lp
汇编/编译器编码规则37:通过对完整的32位寄存器操作而不是32位寄存器的一部分来打破对部分寄存器的依赖。对于搬移,这可以用32位搬移或通过使用MOVZX来实现。
对于奔腾M处理器,MOVSX和MOVZX指令都采用一个微操作,不管它们是从一个寄存器搬移还是搬移到存储器中。在奔腾4处理器上,MOVSX采用了一个额外的微操作。这可能导致比起上述所提到的部分寄存器更新问题更少的延迟,但是性能增益可能会有所不同。如果额外的微操作是一个临界问题,MOVSX有时可以作为可选地来使用。
有时带符号扩展的语义可能会通过零扩展操作数来维护。比如,下列语句的C代码不需要带符号扩展,也不需要对操作数大小重载的前缀:
static short int a, b;
if(a == b){
...
}
用于比较这些16位操作数的代码可以是:
MOVZW EAX, [a] MOVZW EBX, [b] CMP EAX, EBX
这些情况趋于通常的。然而,如果比较是用于大于、小于、大于等于等等,或者如果在eax或ebx中的值将被用在另一个操作中,而需要带符号扩展,那么这个技术是不起作用的。
汇编/编译器编码规则38:设法使用零扩展或对32位操作数操作而不是使用带符号的搬移。
当带有可以被表示为32位的操作数的指令不邻近时,踪迹Cache可以被打包地更紧密。
汇编/编译器编码规则39:避免放置使用32位立即数的指令,这些立即数在相互邻近的之间不能被编码为带符号扩展的16位立即数。设法在紧跟32位立即数之前或之后调度没有立即数的微操作。
3.5.1.9 比较
当用零在一个寄存器中比较一个值时,使用TEST。TEST本质上将操作数一起想与,而不把结果写入到一个目的寄存器中。TEST比起AND更好,因为AND会产生一个额外的结果寄存器。TEST比CMP ..., 0更好,因为指令大小更小。
当用一个逻辑与跟一个立即数常量比较结果是否相等或不相等时,如果寄存器是EAX用于下列情况,那么使用TEST:
IF(AVAR & 8){ }
TEST指令也可以用作为探测2的幂的模。比如下列C代码:
if((AVAR % 16) == 0){ }
会使用下列指令序列实现:
TEST EAX, 0x0F JNZ AfterIf
在可能修改部分标志寄存器的指令和使用标志寄存器的指令之间使用TEST指令可以帮助防止部分标志寄存器延迟。
汇编/编译器编码规则40:当逻辑结果不被使用时使用TEST指令而不是AND。这在执行中节省了微操作。以一个寄存器其自身来使用一条TEST,而不是用寄存器与零使用CMP,这节省了对编码零的需要并节省了编码空间。避免将一个常量与存储器操作数进行比较。更好的是加载存储器操作数然后用一个寄存器与常量进行比较。
往往,一个所产生的值必须与零进行比较,并且然后用在一个分支中。因为大部分Intel架构指令设置条件码作为其执行的一部分,所以比较指令可以被消除。因而,该操作可以直接用一条JCC指令来测试。要注意的例外是MOV和LEA。在这些情况下,使用TEST。
汇编/编译器编码规则41:通过使用适当的带条件的跳转指令来消除不必要的与零比较指令,当标志已经被前一条算数指令设置时。如果有必要,使用一条TEST指令而不是一条比较指令。确定,任何所做变换后的代码不引入溢出问题。
3.5.1.10 使用NOP
代码生成器生成一条无操作(NOP)来做指令对齐。以下展示在32位模式中的不同长度的NOP的例子:
1字节:XCHG EAX, EAX
2字节:66 NOP
3字节:LEA REG, 0(REG)(8位位移)
4字节:NOP DWORD PTR [EAX + 0](8位位移)
5字节:NOP DWORD PTR [EAX + EAX * 1 + 0](8位位移)
6字节:LEA REG, 0(REG)(32位位移)
7字节:NOP DWORD PTR [EAX + 0](32位位移)
8字节:NOP DWORD PTR [EAX + EAX * 1 + 0](32位位移)
9字节:NOP DWORD PTR [EAX + EAX * 1 + 0](32位位移)
这些都是真正的NOP,对机器状态没有影响,除了让EIP递增。因为NOP需要硬件资源来解码并执行,所以使用最少的数量来实现想要的填充。
单字节NOP:[XCHG EAX, EAX]具有特殊硬件支持。尽管它仍然消耗一个微操作以及其伴随资源,但是对EAX旧值的依赖被移除。此微操作可以以最早可能机会来被执行,从而减少显著的指令个数并且作为最低成本的NOP。
其它NOP不具有特殊硬件支持。其输入和输出寄存器被硬件解释。因此,一个代码生成器应该安排含有最老值的寄存器作为输入,这样NOP将以最早可能机会分派并释放RS资源。
设法观察以下NOP生成优先级:
● 选择最少数量的NOP以及伪NOP来提供所期待的填充。
● 选择最不可能在更慢执行单元簇上执行的NOP。
● 选择NOP的寄存器参数来减少依赖。
3.5.1.11 混合SIMD数据类型
以前的微架构(在Intel Core微架构之前)不具有对XMM寄存器的混合整型和浮点型(FP)操作的限制。对于Intel Core微架构,在一个XMM寄存器的内容上混合整型和浮点型操作会降低性能。软件应该避免在XMM寄存器上对整型/浮点操作的混合使用。具体地,
● 使用SIMD整型操作来喂送SIMD整型操作。使用PXOR来用作习语。
● 使用SIMD浮点操作来喂送SIMD浮点操作。使用XORPS来作为习语。
● 当浮点操作是按位等价的,那么使用PS数据类型而不是PD数据类型。MOVAPS和MOVAPD做同样的事情,但MOVAPS少花费一个字节来编码指令。
3.5.1.12 溢出调度
由一个代码生成器所使用的溢出调度算法将受存储器子系统影响。一个溢出调度算法在有太多的活动值要适应到寄存器时选择什么值溢出到存储器。考虑例3-22中的代码,这里需要溢出A,B或C。
例3-22:溢出调度代码
LOOP C:=... B:=... A:+A +...
对于现代的微架构,在溢出调度中使用依赖深度信息比起在先前的处理器中更重要。对A的带有循环的依赖使得它对于A没被溢出尤为重要。不仅仅要在依赖链中放置存储/加载,而且还会有加载的数据没准备好延迟,花费更多周期。
汇编/编译器编码规则42:对于小的循环,在存储器中放置循环不变量比起溢出带有循环的依赖要更好。
一个可能直观的统计的结果是,在这么一种情况下,将循环不变量放在存储器中比起放在寄存器中更好,由于对循环不变量的加载永远不会受还没准备好的存储数据阻塞。
3.5.1.13 零延迟MOV指令
在基于代号名为Ivy Bridge的Intel微架构的处理器中,寄存器到寄存器搬移操作的一个子集在前端(类似于零习语,见3.5.1.8小节)被执行。这保存了无序引擎中的调度/执行资源。寄存器到寄存器的MOV指令的大部分形式可以从零延迟MOV获益。例3-23列出了满足这条件的那些形式而一小部分集合不满足的详细细节。
例3-23:零延迟搬移指令
; 可以被消除的MOV指令延迟 MOV reg32, reg32 MOV reg64, reg64 MOVUPD/MOVAPD xmm, xmm MOVUPD/MOVAPD ymm, ymm MOVUPS/MOVAPS xmm, xmm MOVUPS/MOVAPS ymm, ymm MOVDQA/MOVDQU xmm, xmm MOVDQA/MOVDQU ymm, ymm MOVZX reg32, reg8 ; reg8如果不是AH/BH/CH/DH MOVZX reg64, reg8 ; reg8如果不是AH/BH/CH/DH ; 不能被消除的MOV指令 MOV reg8, reg8 MOV reg16, reg16 MOVZX reg32, reg8 ;如果reg8是AH/BH/CH/DH MOVZX reg64, reg8 ;如果reg8是AH/BH/CH/DH MOVSX
例3-24展示了如何使用MOVZX来处理8位整型来利用零延迟的MOV提升。考虑
X = (X * 3^N) MOD 256;
Y = (Y * 3^N) MOD 256;
当"MOD 256"使用"AND 0xff"技术来实现时,其延迟在结果依赖链中暴露。在一个被截断字节输入上使用一个MOVZX的形式,它可以利用零延迟MOV增强并在速度上获得约45%的增益。
例3-24:字节粒度的数据计算技术
; 使用AND reg32, 0xff mov rsi, N mov rax, X mov rcx, Y loop: lea rcx, [rcx + rcx * 2] lea rax, [rax + rax * 4] and rcx, 0xff and rcx, 0xff and rax, 0xff lea rcx, [rcx + rcx * 2] lea rax, [rax + rax * 4] and rcx, 0xff and rax, 0xff sub rsi, 2 jg loop ; 使用MOVZX mov rsi, N mov rax, X mov rcx, Y loop: lea rbx, [rcx + rcx * 2] movzx rcx, bl lea rbx, [rcx + rcx * 2] movzx rcx, bl lea rdx, [rax + rax * 4] movzx rax, dl lea rdx, [rax + rax * 4] movzx rax, dl sub rsi, 2 jg loop
对依赖于一条零延迟MOV指令的一串密集指令序列进行代码编写的效果必须也要考虑微架构中的资源限制。
例3-25:重新安排指令序列以提升零延迟MOV指令效果
; 需要更多为零延迟MOV的内部资源 mov rsi, N mov rax, X mov rcx, Y loop: lea rbx, [rcx + rcx * 2] movzx rcx, bl lea rdx, [rax + rax * 4] movzx rax, dl lea rbx, [rcx + rcx * 2] movzx rcx, bl lea rdx, [rax + rax * 4] movzx rax, dl sub rsi, 2 jg loop ; 需要更少为零延迟MOV的资源 mov rsi, N mov rax, X mov rcx, Y loop: lea rbx, [rcx + rcx * 2] movzx rcx, bl lea rbx, [rcx + rcx * 2] movzx rcx, bl lea rdx, [rax + rax * 4] movzx rax, dl lea rdx, [rax + rax * 4] movzx rax, dl sub rsi, 2 jg loop
在例3-25中,RBX/RCX与RDX/RAX是被共享并且被连续重写的寄存器对。在右手边的序列[译者注:在上述代码中下面的示例]中,寄存器立即以新的结果被覆盖,耗费更少由底层提供的内部资源。结果,它会比左手边的指令序列[译者注:上述代码的上面的示例]快大约8%。左手边指令序列中,其内部资源仅能支持试图利用零延迟MOV指令的50%。
3.5.2 在执行核心中避免拖延
尽管执行核心的设计被优化以使得通常情况下的执行更快,不过一个微操作在从前端到ROB和RS进行过程中可能遭到各种危机、延迟[译者注:delay]或拖延[译者注:stall]。比较显著的是:
● ROB读端口拖延
● 部分寄存器引用拖延
● 对XMM寄存器的部分更新拖延
● 部分标志寄存器引用拖延
3.5.2.1 ROB读端口拖延
在对一个微操作重命名时,该微操作判定其源操作数是否已经被执行并且已经写到重排序缓存(ROB),或它们是否在RS中或旁通网络中“在流动时”被捕获。一般,大部分源操作数在重命名期间被发现是“在流动的”。已经被写回到ROB的微操作通过一组读端口来读。
由于Intel Core微架构为通常情况优化,在通常情况下,操作数是“在流动的”,它并不提供一组完整的读端口来允许被重命名的微操作在同一个周期内从ROB去读所有资源。
当不是所有源可以被读时,一个微操作在重命名阶段中会拖延,直到它可以访问足够的ROB读端口来完成重命名微操作。这个拖延往往是短暂的。一般,一个微操作将在下一个周期完成重命名,但它以重命名带宽的一个损失出现到应用上。
某些会引起ROB读端口拖延的软件可见的情景包括:
● 已经变冷并需要一个ROB的读端口的寄存器,因为执行单元正在做其它独立的计算。
● 在寄存器内的内容
● 指针和索引寄存器
在很少情况下ROB读端口拖延会导致更显著的性能下降。有些探索发可帮助防止过度预定ROB读端口:
● 保持公共寄存器使用集中在一起。对同一个写回寄存器的多重引用可以在无序执行引擎内被“折叠”。
● 保持短依赖链完整。这个实践确保寄存器将不会被写回当新的微操作被写到RS中时。
这两个调度探索法可能与其它更通常的调度探索法相冲突。为了减少对ROB读端口的需求,仅当下列情景都满足的时候使用这两个探索法:
● 短延迟操作
● 实际的ROB读端口拖延迹象可以通过性能事件(相关事件是RAT_STALL.ROB_READ_PORT,见Intel开发者指南,卷3B的附录A)的测量来确认
如果代码具有一个长依赖链,那么这两个探索法不应该被使用,因为它们会引起RS填充,导致比起减少对ROB读端口的需求的正效果更大的损害。
从代号名为Sandy Bridge的Intel微架构起,ROB端口拖延不再应用,因为数据从物理寄存器文件来读。
3.5.2.2 回写总线冲突
在执行引擎内的回写总线是一个需要减轻流动中的微操作的无序执行负担的公共资源。当在同一执行单元栈中在同一时间有两个正在执行的微操作需要回写总线(见表2-4),那么更晚被创建的微操作将不得不等待回写总线可用。这种情况一般将更可能针对短延迟指令遭受一个延迟,当它可能已经准备好分派到执行引擎时。
考虑独立的浮点ADD与一个单周期的MOV一起绑定到同一个分派端口的一个重复序列。当MOV发现分派端口可用时,ADD可能占用了回写总线。这延迟了MOV操作。
如果这个问题被探测到,那么你有时可以改变指令选择来使用一个不同的发布端口并减少回写竞争。
3.5.2.3 在执行域之间旁通
浮点(FP)加载具有一个额外的延迟周期。在FP和SIMD栈之间搬移具有另一个额外的延迟周期。
例:
ADDPS XMM0, XMM1
PAND XMM0, XMM3
ADDPS XMM2, XMM0
上述计算总的延迟为9个周期:
● 3个周期为每个ADDPS指令
● 一个周期为PAND指令
● 1个周期是在ADDPS浮点域到PAND整型域之间的旁通
● 1个周期是将数据从PAND整数搬移到第二个浮点ADDPS域
为了避免这个处罚,你应该组织代码以最小化域改变。有时,你无法避免旁通。
当对你的代码统计整体延迟时要统计旁通周期。如果你的计算是延迟绑定的,那么你可以执行并行地执行更多的指令,要么打破依赖链来减少整体延迟。
具有许多旁通域并且是完整延迟绑定的代码可能会在Intel Core微架构上比起先前的微架构运行更慢。
3.5.2.4 部分寄存器拖延
通用目的寄存器可以以字节、字、双字粒度来被访问;64位模式也支持四字粒度。引用一个寄存器的一部分被称作为一个部分寄存器引用。
当一条指令引用一个寄存器,其某些部分在之前被其它指令修改时,则一个部分寄存器拖延发生。例如,在之前的指令存储了AL和AH时,对AX的一次读会引发部分寄存器拖延;或在前一条指令修改了AX,然后对EAX做一次读时,也会发生部分寄存器拖延。
一个部分寄存器拖延的延迟在基于Intel Core和NetBurst微架构上的处理器,以及奔腾M,Intel Core Solo和Intel Core Duo处理器中比较小。部分奔腾M处理器以及P6家族的处理器会遭致一个很大的处罚。
注意,在Intel 64架构中,对一个64位整型寄存器的低32位更新在架构上被定义为用零扩展高32位。由于这个行为可能在逻辑上被看作为一个32位更新,实际上它确实是64位更新(并从而不会导致一个部分拖延)。
频繁引用部分寄存器用错误的或真实的依赖来产生代码序列。例3-18说明了一列由引用部分寄存器而导致的错误的且真实的依赖。
如果指令4和6(在例3-18中)被改变为使用一条movzx指令,而不是mov,那么指令4对2的依赖,以及指令6对5的依赖被打破。这创建了两条独立的计算链而不是一条。
例3-26阐明了MOVZX的使用来避免一个部分寄存器拖延,当打包3字节的值到一个寄存器中时。
例3-26:在整型代码中避免部分寄存器延迟
; 导致部分寄存器拖延的一个序列 mov al, byte ptr a[2] shl eax, 16 mov ax, word ptr a movd mm0, eax ret ; 使用MOVZX来避免延迟的替换代码序列 movzx eax, byte ptr a[2] shl eax, 16 movzx ecx, word ptr a or eax, ecx movd mm0, eax ret
在代号名为Sandy Bridge的Intel微架构中,部分寄存器访问通过插入一个微操作而在硬件中处理,该微操作在下列情况下用完整的寄存器融合了部分寄存器:
● 在对寄存器AH、BH、CH或DH的寄存器的其中之一进行一次写之后,并且跟在对同一个寄存器以2、4、或8字节的形式做一个读之前。在这些情况下,一个融合微操作被插入。该插入消耗一个完整的分配周期,在这个周期中其它微操作不能被分配。
● 在带有1或2字节的一个目的寄存器的一个微操作之后,该微操作不是指令的一个源(或寄存器的更大形式),并且在对同一寄存器的2、4、8字节形式的一次读之前。在这些情况下融合微操作是流的一部分。比如
● MOV AX, [BX]
当你想从存储器加载到一个部分寄存器时,考虑使用MOVZX或MOVSX来避免额外的融合微操作处罚。
● LEA AX, [BX + CX]
对于最优性能,在使用寄存器之前使用零习语,消除部分寄存器融合微操作的需要。
3.5.2.5 部分XMM寄存器拖延
部分寄存器拖延也会应用到XMM寄存器。以下SSE和SSE2指令只更新部分目的寄存器:
MOVL/HPD XMM, MEM64
MOVL/HPS XMM, MEM32
MOVSS/SD 在寄存器之间
使用这些指令在寄存器的未修改部分与寄存器的修改部分之间创建创建一条依赖链。这条依赖链会引起性能损失。
例3-27阐明了对MOVZX的使用来避免一个部分寄存器拖延,当将三字节值打包到一个寄存器中时。
遵循下列建议来避免对XMM寄存器的部分更新:
● 避免使用仅更新部分XMM寄存器的指令
● 如果需要一个64位加载,那么使用MOVSD或MOVQ指令。
● 如果对同一个寄存器从非连续位置需要2个64位加载,那么使用MOVSD/MOVHPD而不是MOVLPD/MOVHPD。
● 当拷贝 XMM寄存器时,使用下列指令来做完整的寄存器拷贝,即使你只想拷贝源寄存器数据的某些部分:
MOVAPS
MOVAPD
MOVDQA
例3-27:避免在SIMD代码中的部分寄存器拖延
; 对存储器访问使用movlpd并在寄存器拷贝之间使用movsd引发部分寄存器拖延 mov edx, x mov ecx, count movlpd xmm3, _1_ movlpd xmm2, _1pt5_ align 16 lp: movlpd xmm0, [edx] addsd xmm0, xmm3 subsd xmm1, xmm2 mulsd xmm0, xmm1 movsd [edx], xmm0 add edx, 8 dec ecx jnz lp ; 使用movsd来做存储器访问以及在寄存器拷贝之间使用movapd来避免拖延 mov edx, x mov ecx, count movsd xmm3, _1_ movsd xmm2, _1pt5_ align 16 lp: movsd xmm0, [edx] addsd xmm0, xmm3 movapd xmm1, xmm2 subsd xmm1, [edx] mulsd xmm0, xmm1 movsd [edx], xmm0 add edx, 8 dec ecx jnz lp
3.5.2.6 部分标志寄存器拖延
当一条指令修改了标志寄存器的一部分并且下一条指令依赖于标志的结果时,一个“部分标志寄存器拖延”发生。这常常在移位指令(SAR、SAL、SHR、SHL)中发生。在一个零移位的情况下标志不被修改,但移位数往往仅仅在执行时才知道。前端会一直拖延,直到指令隐退。
其它会修改标志寄存器的某些部分的指令包括CMPXCHG8B,各种循环移位指令,STC以及STD。例3-28展示了带有一个部分标志寄存器拖延以及没有拖延的可替代方法的汇编的例子。
在基于Intel Core微架构上的处理器中,以立即数1来移位由特殊硬件来处理,这样它并会引起部分标志拖延。
例3-28:避免部分标志寄存器拖延
; 部分标志寄存器拖延 xor eax, eax mov ecx, 2 sar ecx, 2 setz al ; SAR会更新进位标志,导致一次拖延 ; 避免部分标志寄存器拖延 or eax, eax mov ecx, 2 sar ecx, 2 test ecx, ecx ; test总是更新所有标志 setz al ; 没有部分寄存器或标志拖延
在代号名为Sandy Bridge的Intel微架构中,部分标志访问的成本由一个微操作的插入而不是一次拖延来替代。然而,仍然建议使用更少的指令来仅针对某些标志(诸如INC、DEC、SET CL)来写,在能够有条件地写标志的指令(诸如SHIFT CL)之前。
例3-29比较了两个技术来实现非常大的整数(比如1024位)的加法。在代号名为Sandy Bridge的Intel微架构上,例3-29的右边【译者注:示例代码的下半部分】会比左手边更快,但它将在先前架构上会有部分标志拖延。
例3-29:代号名为Sandy Bridge的Intel微架构中对部分标志寄存器的访问
lea rsi, [A] lea rdi, [B] xor rax, rax mov rcx, 16 ; 16 * 64 = 1024位 lp_64bit: add rax, [rsi] adc rax, [rdi] mov [rdi], rax setc al ; 为下一次迭代保存进位 movzx rax, al add rsi, 8 add rdi, 8 dec rcx jnz lp_64bit ; 简化的代码序列 lea rsi, [A] lea rdi, [B] xor rax, rax mov rcx, 16 lp_64bit: add rax, [rsi] adc rax, [rdi] mov [rdi], rax lea rsi, [rsi+8] lea rdi, [rdi+8] dec rcx jnz lp_64bit
3.5.2.7 浮点/SIMD操作数
写一个寄存器的一部分的搬移会引入不想要的依赖。MOVSD REG, REG指令只写一个寄存器的低64位,而不是所有128位。这引入了对产生高64位的前一条指令的依赖(即使那些位不再想要)。这依赖禁止了寄存器重命名,从而减少了并行性。
使用MOVAPD作为一个替代;它写了所有的128位。即使这条指令有一个更长的延迟,MOVAPD的微操作使用一个不同的执行端口并且这个端口更可能是空闲的。这种改变能影响性能。也可能有例外情况,延迟比起执行端口的依赖更要紧。
汇编/编译器编码规则43:避免引入带有部分浮点寄存器写的依赖,比如MOVSD XMMREG1, XMMREG2指令。使用MOVAPD XMMREG1, XMMREG2指令作为替代。
MOVSD XMMREG, MEM指令写所有的128位并打破依赖。
加载存储器的MOVUPD指令执行两次64位加载,但需要额外的微操作来调整地址并将这两个加载与一单个寄存器结合起来。同样的功能可以使用MOVSD XMMREG1, MEM; MOVSD XMMREG2, MEM+8; UNPCKLPD XMMREG1, XMMREG2来获得,这使用了更少的微操作并且可以更有效地被打包进踪迹Cache。已经发现了后一种替代方式在同一情况下提供了若干个百分点的性能提升。其编码需要更多的指令字节,但这在奔腾4处理器上很少是一个问题。MOVUPD的存储版本是复杂且缓慢的,以至于应该总是使用两个MOVSD和一个UNPCKHPD。
汇编/编译器编码规则44:不要使用MOVUPD XMMREG1, MEM来做一次非对齐的128位加载,而是使用MOVSD XMMREG1, MEM; MOVSD XMMREG2, MEM+8; UNPCKLPD XMMREG1, XMMREG2。如果额外的寄存器不可用,那么使用MOVSD XMMREG1, MEM; MOVHPD XMMREG1, MEM+8。
汇编/编译器编码规则45:不要使用MOVUPD MEM, XMMREG1来做一次存储,而是使用MOVSD MEM, XMMREG1; UNPCKHPD XMMREG1, XMMREG1; MOVSD MEM+8, XMMREG1。
3.5.3 向量化
这小节提供了关于向量化的简要概述。在后续的几个章节中将会有详细介绍。
向量化是一个程序变换,允许硬件对多个数据元素同时执行相同的操作。处理器时代已经经过了MMX技术,流SIMD扩展(SSE),流SIMD扩展2(SSE2),流SIMD扩展3(SSE3)以及补充的流SIMD扩展3(SSSE3)。
向量化是是SIMD的一种专有情况,是在Flynn架构分类系统中定义的一个术语,表示能够对多个数据并行操作的一条指令。可以被并行操作的元素个数从SSE中的四个单精度浮点和SSE2中的两个双精度浮点到SSE2中的16个字节。从而,向量长度范围是从2到16,依赖于对数据类型所使用的指令扩展。
Intel C++编译器支持以三种方式支持向量化:
● 编译器可以不需要用户的干涉来产生SIMD代码。
● 用户可以插入pragma来帮助编译器意识到它可以向量化代码。
● 用户可以显式地使用内建函数和C++类来写SIMD代码。
为了帮助允许编译器生成SIMD代码,避免全局指针以及全局变量。如果所有模块被同时编译,以及使用了整个程序优化的话,这样可以减少麻烦。
用户/源编码规则2:使用最小可能的浮点或SIMD数据类型,来允许使用一个(更长的)SIMD向量获得更多并行性。比如,只要可能,使用单精度而不是双精度。
用户/源编码规则3:安排循环嵌套,使得最内部嵌套等级免受迭代间依赖。尤其避免这种情况,在一个更早的迭代中存储数据词法上在一个后面的迭代中的加载那个数据之后发生,这称为一个词法后向依赖。
SIMD指令集扩展的整数部分覆盖8位、16位和32位操作数。并不是所有的SIMD操作都支持32位,这意味着某些源代码将根本无法被向量化,除非使用更小的操作数。
用户/源编码规则4:避免在内部循环使用条件分支并考虑使用SSE指令来消除分支
用户/源编码规则5:保持归纳[译者注:induction](循环)变量表达式简单。
3.5.4 优化部分可向量化的代码
一个程序频繁地包含一个可向量化的代码和一些非可向量化的例程的混合。部分可向量化的代码的一个通常场景涉及到含有向量化的代码和未向量化的代码相混合的一个循环结构。
这个情景在图3-1中描述。
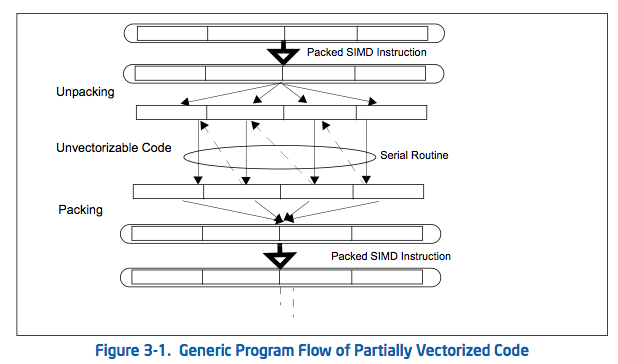
它在循环内通常含有5个阶段:
● 序言[译者注:即初始化]
● 将向量化的数据解包为独立的元素
● 调用一个非向量化的例程来串行地处理每个元素
● 将独立的结果打包为向量化数据结构
● 收尾
本小节讨论了在这些部分被向量化的代码中可以减少与打包/解包相关联的成本和瓶颈。
例3-30展示了一个参考模板可以表示部分可向量化代码的情景,也体现了性能问题。代码的不可向量化部分一般用一系列多次调用名字为“foo”的一个串行函数来表示。这个通用的例子被称作为“带有存储转运的混排[译者注:shuffle with store forwarding]”,因为这个问题一般涉及到在寄存器和存储器之间混排数据元素的解包阶段,后面跟着一个会表现出存储转运问题的打包阶段。
有不只一种的有用技术来减少串行部分和打包阶段之间的存储转运瓶颈。下面的子小节体现了可替代的技术来处理打包、解包、以及传参给串行的函数调用。
例3-30:对于部分可向量化程序的参考代码模板:
; 序言 /////////////////////// push ebp, esp mov ebp, esp ; 解包 /////////////////////// sub ebp, 32 and ebp, 0xfffffff0 movaps [ebp], xmm0 ; 对分量的串行操作 /////////// sub ebp, 4 mov eax, [ebp+4] mov [ebp], eax call foo mov [ebp+16+4], eax mov eax, [ebp+8] mov [ebp], eax call foo mov [ebp+16+4+4], eax mov eax, [ebp+12] mov [ebp], eax call foo mov [ebp+16+8+4], eax mov eax, [ebp+12+4] mov [ebp], eax call foo mov [ebp+16+12+4], eax ; 打包 //////////// movaps xmm0, [ebp+16+4] ; 尾声 //////////// pop ebp ret
3.5.4.1 可替代的打包技术
在例3-30的参考代码中所实现的打包方法将会有延迟,由于存储转运的限制,它从存储器汇编了4个双字结果到一个XMM寄存器。
使用不同的SIMD指令来汇编XMM寄存器中的内容,有三种替代技术来打包,这些在例3-31中展示。这三种技术都通过满足在先前的存储和后续的加载操作之间的数据大小的限制来避免存储转运延迟。
例3-31:三种可替代的打包方法来避免存储转运困难
; 打包方法1 movd xmm0, [ebp+16+4] movd xmm1, [ebp+16+8] movd xmm2, [ebp+16+12] movd xmm3, [ebp+12+16+4] punpckldq xmm0, xmm1 punpckldq xmm2, xmm3 punpckldq xmm0, xmm2 ; 打包方法2 movd xmm0, [ebp+16+4] movd xmm1, [ebp+16+8] movd xmm2, [ebp+16+12] movd xmm3, [ebp+12+16+4] psllq xmm3, 32 orps xmm2, xmm3 psllq xmm1, 32 orps xmm0, xmm1 movlhps xmm0, xmm2 ; 打包方法3 movd xmm0, [ebp+16+4] movd xmm1, [ebp+16+8] movd xmm2, [ebp+16+12] movd xmm3, [ebp+12+16+4] movlhps xmm1, xmm3 psllq xmm1, 32 movlhps xmm0, xmm2 orps xmm0, xmm1
3.5.4.2 简化结果传递
在例3-30中,通过存储到连续的存储器位置将独立的结果传递到打包阶段。不使用存储器溢出来传递这四个结果,结果传递可以通过使用一个或多个寄存器来完成。使用寄存器来简化结果传递并减少存储器溢出,可以通过在运行时改变存储器压力依赖度来提升性能。
例3-32展示了使用四个额外的XMM寄存器来减少所有存储器溢出将结果传递回父例程的的代码序列。然而,当使用这个技术时,软件必须观察下列条件:
● 没有存储器不足
● 如果循环不具有许多存储或加载但具有许多计算,这个技术不会帮助提升性能。这个技术在存储和加载端口空闲时增加了对计算单元的工作。
mov eax, [ebp+4] mov [ebp], eax call foo movd xmm0, eax mov eax, [ebp+8] mov [ebp], eax call foo movd xmm1, eax mov eax, [ebp+12] mov [ebp], eax call foo movd xmm2, eax mov eax, [ebp+12+4] mov [ebp], eax call foo movd xmm3, eax
3.5.4.3 栈优化
在例3-30中,一个输入形参依次被拷贝到栈上并传递到非可向量化的例程来处理。从连续存储器位置传递的形参可以用例3-33中所展示的技术来简化。
例3-33:栈优化技术来简化形参传递
call foo mov [ebp+16], eax add ebp, 4 call foo mov [ebp+16], eax add ebp, 4 call foo mov [ebp+16], eax add ebp, 4 call foo
栈优化只能在以下情况被优化:
● 串行操作是函数调用。函数“foo”被声明为:INT FOO(INT A)。形参在栈上被传递。
● 对这些向量元素的操作顺序是从最后到第一。
注意,对FOO的调用以及EBP的递增,在将向量元素从后到前一个一个传递到FOO时。
3.5.4.4 调整考虑
由例3-30的循环所表示的情景的调整考虑包括
● 应用下列多个组合中的一个:
——选择一个交替的打包技术
——考虑一种技术来简化结果传递
——考虑栈优化技术来简化参数传递
● 最小化执行循环的每次迭代的平均周期数
● 最小化解包和打包操作的每次迭代的成本
使用本小节中所讨论的技术来做速度提升将是可变的,依赖于所实现的组合的选择以及非可向量化的例程的特征。比如,如果例程“foo”是短的(可以由紧密的、短的循环表示),那么解包/打包的每次迭代的成本比起非可向量化的代码包含更长的操作或许多依赖的情景趋于更小。这是因为短的、紧密循环的许多迭代可能是在执行核心中是在流动中的,因此打包和解包的每次迭代的成本仅仅是部分暴露的并且出现为引起非常少的性能下降。
打包/解包的每次迭代的计算成本应该是以一种有条理的方式来选择一组测试用例而被执行,每个用例可以实现在本小节中所讨论的技术的某些组合。每次迭代的成本可以用以下方式来评估:
● 评估测试用例执行一次迭代的平均周期
● 评估一个非可向量化代码的基准循环序列执行一次迭代的平均周期
例3-34展示了可以被用于评估执行非可向量化例程的一个循环的平均成本的基准代码序列。
例3-34:评估循环负荷的基准代码序列
push ebp mov ebp, esp sub ebp, 4 mov [ebp], edi call foo mov [ebp], edi call foo mov [ebp], edi call foo mov [ebp], edi call foo add ebp, 4 pop ebp ret
打包/解包的平均每次迭代成本可以通过测量一个大量的迭代的执行次数来获得:(运行测试用例的周期数 - 运行等价的基准序列的周期数) / 迭代次数。
比如,使用返回一个输入形参的(可表示为紧凑的、短的循环)的一个简单函数,打包/解包的每次迭代范围可以从稍微超过7个周期(带有存储转运情况的混排,例3-30)到0.9个周期(通过几个测试用例可以实现)。通过27个测试用例(由其中一个打包方法,对1或4结果进行无简化或简化,带栈优化或不带栈优化),打包/解包的平均每次成本大约为1.7个周期。
通常来说,打包方法2和3(见例3-31)比起方法1更趋于健壮;简化1或4结果的最优选择将受运行时的寄存器压力和其它相关架构上的条件影响。
注意,打包/解包的每次迭代成本的数值上的讨论仅仅是说明性的。使用一个不同基准代码序列做测试用例会有所不同,如果非可向量化的例程需要更长时间执行,那么通常成本数值会增加,因为驻留在执行核心中的流动的循环迭代的次数减少了。