24.开窗函数
在开窗函数出现之前存在着很多用SQL语句很难解决的问题,很多都要通过复杂的相关子查询或者存储过程来完成。为了解决这些问题,在2003年ISO SQL标准加入了开窗函数,开窗函数的使用使得这些经典的难题可以被轻松的解决。
create table T_Person ( FName varchar(20),--人员姓名 FCity varchar(20),--所在城市 FAge int,--人员年龄 FSalary int--人员工资 ) insert into T_Person(FName,FCity,FAge,FSalary) values('Tom','BeiJing',20,3000); insert into T_Person(FName,FCity,FAge,FSalary) values('Tim','ChengDu',21,4000); insert into T_Person(FName,FCity,FAge,FSalary) values('Jim','BeiJing',22,3500); insert into T_Person(FName,FCity,FAge,FSalary) values('Lily','London',21,2000); insert into T_Person(FName,FCity,FAge,FSalary) values('John','NewYork',22,1000); insert into T_Person(FName,FCity,FAge,FSalary) values('YaoMing','BeiJing',20,3000); insert into T_Person(FName,FCity,FAge,FSalary) values('Swing','London',22,2000); insert into T_Person(FName,FCity,FAge,FSalary) values('Guo','NewYork',20,2800); insert into T_Person(FName,FCity,FAge,FSalary) values('YuQian','BeiJing',24,8000); insert into T_Person(FName,FCity,FAge,FSalary) values('Ketty','London',25,8500); insert into T_Person(FName,FCity,FAge,FSalary) values('Kitty','ChengDu',25,3000); insert into T_Person(FName,FCity,FAge,FSalary) values('Merry','BeiJing',23,3500); insert into T_Person(FName,FCity,FAge,FSalary) values('Smith','ChengDu',30,3000); insert into T_Person(FName,FCity,FAge,FSalary) values('Bill','BeiJing',25,2000); insert into T_Person(FName,FCity,FAge,FSalary) values('Jerry','NewYork',24,3300);
1.开窗函数简介
与聚合函数一样,开窗函数也是对行集组进行聚合计算,但是它不像普通聚合函数那样每组只返回一个值,开窗函数可以为每组返回多个值,因为开窗函数所执行聚合计算的行集组是窗口。
查询每个工资小于5000元的员工信息,并且在每行中都显示所有工资小于5000元的员工个数。
子查询:
SELECT *, ( SELECT COUNT(*) FROM T_Person WHERE FSALARY<5000 ) FROM T_Person WHERE FSALARY<5000
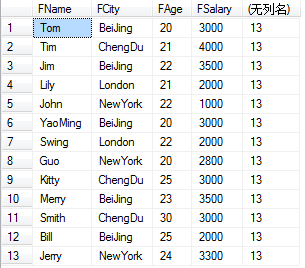
如果使用开窗函数来实现同样的效果:
SELECT FCITY , FAGE , COUNT(*) OVER() FROM T_Person WHERE FSALARY<5000
可以看到与聚合函数不同的是,开窗函数在聚合函数后增加了一个OVER关键字。开窗函数的调用格式为:函数名(列) OVER(选项)
OVER关键字表示把函数当成开窗函数而不是聚合函数。SQL标准允许将所有聚合函数用做开窗函数,使用OVER关键字来区分这两种用法。OVER关键字后的括号中还经常添加选项用以改变进行聚合运算的窗口范围。如果OVER关键字后的括号中的选项为空,则开窗函数会对结果集中的所有行进行聚合运算。在上边的例子中,开窗函数COUNT(*) OVER()对于查询结果的每一行都返回所有符合条件的行的条数。
2.Partition By
开窗函数的OVER关键字后括号中的可以使用Partition By子句来定义行的分区来供进行聚合计算。与GROUP BY子句类似,但Partition By子句创建的分区是独立于结果集的,创建的分区只是供进行聚合计算的,而且不同的开窗函数所创建的分区也不互相影响。
下面的SQL语句用于显示每一个人员的信息以及所属城市的人员数:
select FName,FCity,FAge,FSalary,count(*) over(Partition by FCity) from T_Person
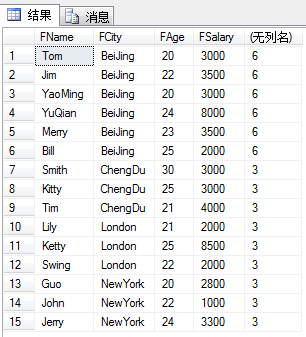
count(*) over(Partition by FCity表示对结果集按照FCity进行分区,并且计算前行所属的组的聚合计算结果。比如对于FName等于Tom的行,它所属的城市是BeiJing,同属于BeiJing的人员一共有6个,所以对于这一列的显示结果为6。
3.排名函数
SELECT FName, FSalary,FAge, Rank() over(order by FAge), Dense_Rank() over(order by FAge), Row_Number() over(order by FAge) FROM T_Person
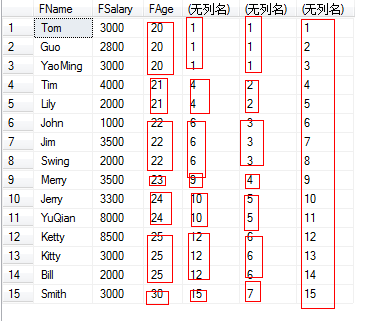
从上面的执行结果可以看出,使用DENSE_RANK()的时候如果发生并列排名的情况,名次的位置会被占用,而使用RANK()的时候则名次会顺延,而ROW_NUMBER()则会返回一个唯一的排名。
分页:
select @Id,@ufts from ( select ROW_NUMBER() OVER (ORDER BY @Id desc) AS Row,@Id,cast(@ufts as bigint) @ufts from @Table )as temp WHERE (Row BETWEEN @i and @j)