**原文URL:http://www.brendangregg.com/o...
此文章为翻译,并非原创,仅供学习交流,不得转载。**
性能问题可分为以下两种类型之一:
* On-CPU:线程在 CPU 上运行的时间。
* Off-CPU:计时器、分页/交换等上阻塞时所花费的时间。
Off-CPU 是一种用于测量和研究 CPU时间之外以及上下文堆栈跟踪的性能分析方法。它不同于 On-CPU 仅分析在 CPU 上执行的线程。它的目标是分析被阻止线程状态,如下图中的蓝色所示。

Off-CPU 外分析是对 On-CPU 分析的补充,因此可以 100% 地了解线程时间。此方法也不同于应用程序阻塞的跟踪技术,因为此方法针对内核调度程序被阻塞原因的分析,比应用程序阻塞分析的应用场景更广。
造成线程Off-CPU 的原因有很多,包括 I/O 和锁,但也有一些与当前线程的执行无关的原因,包括由于对 CPU 资源的高需求而导致的非自愿上下文切换和中断。无论出于什么原因,如果在工作负载请求(同步代码路径)期间发生这种情况,则造成延迟。
在本文中,我将介绍Off-CPU 时间分析方法。
目录:
1. 先决条件
2. 介绍
3. 开销
4. Linux
5. 关闭 CPU 时间
6. CPU 外分析
7. 请求上下文
8. 注意事项
9. 火焰图
10. 唤醒
11. 其他工作
12. 产地
13. 摘要
14. 更新
先决条件
Off-CPU 分析需要堆栈跟踪可用。许多应用程序都是使用 -fomit-frame-pointer的 gcc 选项编译的,这打破了基于帧指针的堆栈方法。VM 运行时(如 Java)可自由编译方法,在没有额外帮助的情况下可能无法找到其符号信息,从而导致仅能十六进制堆栈跟踪。请参阅关于修复Stack Traces和 JIT Symbols for perf。
介绍
为了解释Off-CPU 分析的作用,我先总结 CPU 采样和跟踪进行比较。然后,我将总结两种Off-CPU 分析方法:跟踪和采样。虽然十多年来我一直在推广Off-CPU分析,但它仍然不是一个广泛使用的方法,部分原因是在生产Linux环境中缺乏工具来测量它。现在,随着eBPF和较新的Linux内核(4.8+)的不断更新,情况正在发生变化。
- CPU 采样
许多传统的分析工具使用所有 CPU 的活动定时采样,收集当前指令地址(程序计数器)的快照或以特定时间间隔或速率(例如 99 赫兹)的整个堆栈回溯的快照。这将提供运行函数或堆栈跟踪的计数,从而可以计算 CPU 周期的花费位置的合理估计值。在 Linux 上,采样模式下的 perf 工具(例如 -F 99)执行时间 CPU 采样。
考虑应用程序函数 A() 调用函数 B(),它使阻塞系统调用:
上面的CPU 采样虽然这对于研究 On-CPU 的问题(包括热代码路径和自适应互斥旋转)非常有效,但当应用程序被阻止并处于 Off-CPU 等待时,它不会收集数据。
- 应用程序跟踪

应用程序跟踪对函数进行检测,以便当时间戳开始"("和"结束")时收集时间戳,以便计算函数中花费的时间。如果时间戳包括经过的时间和 CPU 时间(eg, using times(2) or getrusage(2)),那么也可以计算哪些功能在 CPU 上速度较慢,而哪些功能由于被阻止而在 CPU 上速度较慢。与采样不同,这些时间戳的分辨率(纳秒)非常高。
这个方法虽然有效,但缺点是需要跟踪所有应用程序函数,这会对性能产生重大影响(并影响您尝试测量的性能),或者选择个别函数跟踪,并希望不会错过其他可能被阻塞的函数。
- Off-CPU 跟踪
我将在这里总结一下,然后在下一节中更详细地解释它。

使用这种方法,仅跟踪切换线程 Off-CPU 的内核函数,时间戳以及用户堆栈跟踪。这侧重于跟踪 Off-CPU 事件,而无需跟踪所有应用程序功能,也不需要知道应用程序是什么。此方法适用于任何阻塞事件,适用于任何应用程序:MySQL、Apache、Java 等。
Off-CPU tracing captures all wait events for any application.
稍后在此文中,我将跟踪内核Off-CPU 事件,并包括一些应用程序级检测以筛选出异步等待时间(例如,等待工作的线程)。与应用程序级检测不同,我不需要寻找每个可能阻塞Off-CPU的位置;我只需要确定应用程序位于时间敏感的代码路径中(例如,在 MySQL 查询期间),以便延迟与工作负载同步。
Off-CPU跟踪是我用于Off-CPU 分析的主要方法。但也有采样。
- Off-CPU 采样

此方法使用时间采样从未在 CPU 上运行的线程捕获阻塞的堆栈跟踪。它也可以通过wall-time探查器来完成:它一直采样所有线程,无论它们是 On-CPU 上还是 Off-CPU。然后可以筛选wall-time配置文件输出,以查找 Off-CPU 堆栈。
系统探查器很少使用 Off-CPU采样。采样通常实现为每 CPU 计时器中断,然后检查当前正在运行的中断进程:生成 CPU 上配置文件。Off-CPU 采样器必须以不同的方式工作:要么在每个应用程序线程中设置计时器来唤醒它们并捕获堆栈,要么让内核每隔一段时间走走所有线程并捕获它们的堆栈。
开销
警告:使用 Off-CPU 跟踪时,调度程序事件可能非常频繁(在极端情况下,每天数百万事件),尽管跟踪器可能只会给每个事件增加少量开销,但由于开销可能增加并变得显著,因此只能增加少量开销。Off-CPU 采样也有开销问题,因为系统可能有数以万计的线程必须不断采样,比 CPU 采样的开销仅高于 CPU 采样数量。
要使用 Off-CPU 分析,需要注意每一步的开销。将每个事件转储到用户空间进行后期处理的跟踪器很容易变得令人望而却步,每分钟创建 1 Gb 的跟踪数据。该数据必须写入文件系统和存储设备,后期处理也会花费更多的 CPU。这就是为什么能够执行内核摘要(如 Linux eBPF)的跟踪器对于减少开销和使 Off-CPU 分析切实可行非常重要的原因。还要提防反馈循环:跟踪器跟踪自己造成的事件。
如果我完全使用新的调度程序跟踪器,我将开始仅跟踪十分之一秒(0.1 秒),然后从那里向上加长,同时密切测量对系统 CPU 利用率、应用程序请求速率和应用程序延迟的影响。我还将考虑上下文切换的速率(例如,通过 vmstat 中的"cs"列进行测量),并在具有较高速率的服务器上更加小心。
为了让您了解开销,我测试了运行 Linux 4.15 的 8 CPU 系统,大量 MySQL 负载导致 102k 个上下文交换/秒。服务器以 CPU 饱和度(0% 空闲)运行,因此任何跟踪开销都会导致应用程序性能明显损失。然后,我比较了通过调度程序跟踪进行 CPU 分析与 Linux perf 和 eBPF,它们演示了不同的方法:用于事件转储的 perf 和用于内核中的 eBPF 汇总:
- 使用 perf 跟踪每个调度程序事件导致跟踪时吞吐量下降 9%,在 perf.data 捕获文件刷新到磁盘时,吞吐量偶尔会下降 12%。该文件最终为 224 MB,用于 10 秒的跟踪。然后通过运行 perf 脚本进行符号转换对文件进行发布处理,这会花费 13% 的性能下降(丢失 1 个 CPU)35 秒。您可以总结这一点,说 10 秒 perf 跟踪花费 9-13% 开销 45 秒。
- 使用 eBPF 对内核上下文中的堆栈进行计数,在 10 秒跟踪期间导致吞吐量下降 6%,从初始化 eBPF 时 1 秒内的吞吐量下降 13%开始,随后是 6 秒的后处理(已汇总堆栈的符号分辨率),成本下降了 13%。因此,10 秒跟踪需要 6-13% 的开销 17 秒。
增加跟踪持续时间时会发生什么?对于 eBPF,它只捕获和转换唯一堆栈,不会随着跟踪持续时间线性扩展。我通过将跟踪从 10 秒增加到 60 秒来测试这一点,这仅将 eBPF 后处理从 6 秒增加到 7 秒。perf 将其后期处理从 35 秒增加到 212 秒,因为它需要处理 6 倍的数据量。为了完全了解这一点,值得注意的是,后期处理是一种用户级活动,可以调整以减少对生产工作负载的干扰,例如使用不同的计划程序优先级。想象一下,此活动的 CPU 上限为 10%:性能损失可能微不足道,eBPF 后处理阶段可能需要 70 秒 - 还不算太坏。但是,perf 脚本时间可能需要 2120 秒(35 分钟),这将阻碍调查。perf 的开销不仅仅是 CPU,它也开销磁盘 I/O。
此 MySQL 示例与生产工作负载相比如何?它当时在进行102k的上下文开关/秒,这是相对较高的:目前我看到的许多生产系统都在20-50k/s范围内。这表明,这里描述的开销比我在这些生产系统上看到的要高2倍。但是,MySQL 堆栈深度相对较轻,通常只有 20-40 帧,而生产应用程序可以超过 100 帧。这也很重要,而且可能意味着我的 MySQL 堆栈行走开销可能只有我在生产中看到的一半。因此,这可以平衡我的生产系统。
Linux: perf, eBPF
Off-CPU 分析是一种通用方法,可在任何操作系统上工作。我将演示使用 Off-CPU 跟踪在 Linux 上执行该方法,然后在后两节中总结其他操作系统。
Linux 上有许多用于 Off-CPU 分析的跟踪器。我将在这里使用 eBPF,因为它可以很容易地执行堆栈跟踪和时间内核中的摘要。eBPF 是 Linux 内核的一部分,我通过 bcc 前端工具使用它。这些至少需要 Linux 4.8 来支持堆栈跟踪。
你可能想知道我在 eBPF 之前是如何进行 CPU 外分析的。许多不同的方法,包括每种阻塞类型的完全不同的方法:存储 I/O 的存储跟踪、调度程序延迟的内核统计信息等等。要实际执行 Off-CPU 分析之前,我曾使用过 SystemTap,也使用过 perf 事件日志记录 , 尽管这具有更高的开销(我在 perf_events 非 CPU 时间火焰图中写过)。有一次,我写了一个简单的wall-time内核堆栈探查器proc-profiler.pl,它采样/proc/PID/堆栈给定的PID。它工作得很好。我也不是第一个破解这样的墙时间分析器, 看poormansprofiler和Tanel Poder's quick'n'dirty故障排除。
Off-CPU Time
这是线程等待 Off-CPU (阻塞时间)而不是On-CPU 的时间。它可以作为持续时间(已由 /proc 统计信息提供)的总计进行测量,或测量每个阻塞事件(通常需要一个跟踪器)。
首先,我将展示您可能已经熟悉的工具的总关闭 CPU 时间。 The time(1) command. Eg, timing tar(1):

tar 运行大约一分钟,但时间命令显示,它只花了 1.0 秒的用户模式 CPU 时间,以及 11.6 秒的内核模式 CPU 时间,总共 50.8 秒的运行时间。我们错过了 38.2 秒!这是 tar 命令在 Off-CPU 的时间,毫无疑问,作为其存档生成一部分,执行存储 I/O。
为了更详细地检查 Off-CPU 时间,可以使用内核调度程序函数的动态跟踪或使用 sched 跟踪点的静态跟踪。bcc/eBPF 项目包括由 Sasha Goldshtein 开发的 cpudist,该项目具有测量 Off-CPU 时间的 -O 模式。这需要 Linux 4.4 或更高版本。
Measuring tar's off-CPU time:

这表明大多数阻塞事件在 64 到 511 微秒之间,这与闪存存储 I/O 延迟(这是基于闪存的系统)一致。跟踪时最慢的阻塞事件达到 65 到 131 毫秒的范围(此直方图中的最后一个存储桶)。
此 Off-CPU 关闭时间由什么组成?从线程阻塞到再次开始运行的所有内容,包括调度程序延迟。
在编写本文时,cpudist 使用 kprobes(内核动态跟踪)来检测 finish_task_switch() 内核函数。(出于 API 稳定性原因,它应该使用 sched 跟踪点,但第一次尝试未成功,现在已reverted。)
finish_task_switch()的原型是:![]()
为了让您了解此工具的工作原理:finish_task_switch() 函数在下一个运行线程的上下文中调用。eBPF 程序可以使用 kprobes 检测此函数和参数,获取当前 PID(通过 bpf_get_current_pid_tgid()),还可以获取高分辨率时间戳 (bpf_ktime_get_ns())。这是上述摘要所需的全部信息,它使用 eBPF 映射在内核上下文中有效地存储直方图存储桶。这里是 cpudist 的完整来源。
eBPF 不是 Linux 上测量 Off-CPU 外时间的唯一工具。perf 工具在其 perf sched timehist时间设置输出中提供"wait time"列,该列排除了计划程序时间,因为它分别显示在相邻列中。该输出显示每个调度程序事件的等待时间,并且与 eBPF 直方图摘要更需要测量的开销。
将 Off-CPU 时间作为直方图进行测量有点有用,但不是很多。我们真正想知道的是上下文 - 为什么线程会阻塞和Off-CPU。这是 Off-CPU 分析的重点。
Off-CPU Analysis
Off-CPU 分析是分析 Off-CPU 时间以及堆栈跟踪以确定线程阻塞原因的方法。由于以下原因,Off-CPU 跟踪分析技术很容易实现:
Application stack traces don't change while off-CPU.
这意味着我们只需要在 Off-CPU 周期的开始或结束时测量一次堆栈跟踪。通常测量结束更容易,因为你总是在记录时间间隔。以下是用于使用堆栈跟踪测量Off-CPU 时间的伪代码:

对此有一些注意事项:所有测量都发生在一个检测点,上下文切换例程的末尾,该例程位于下一个线程的上下文中(例如,Linux finish_task_switch() 函数)。这样,我们可以在检索该持续时间的上下文的同时计算Off-CPU 持续时间,只需获取当前上下文(pid、execname、用户堆栈、内核堆栈),跟踪器就很容易了。
这就是我的 fcputime bcc / eBPF 程序所做, 它至少需要 Linux 4.8 才能工作。我将演示使用 bcc/eBPF 的 fcputime 来测量 tar 程序的阻塞堆栈。我将限制为内核堆栈,仅从 (-K) 开始):

我已经将输出截断为最后三个堆栈。最后一个,显示总共18.4秒的Off-CPU时间,结束在读取系统调用io_schedule() - 这表示tar读取文件内容,并被磁盘 I/O阻塞。它上面的堆栈显示 662 毫秒Off-CPU时间,最终结束在存储I/O xfs_buf_submit_wait()函数。顶部堆栈总共为 203 毫秒,结束在 getdents 系统调用(目录列表)函数上。
解释这些堆栈跟踪需要对源代码的一些熟悉,这取决于应用程序的复杂程度及其语言。这样做的越快,你就能识别出相同的函数和堆栈。
我现在将包括用户级堆栈:

这不起作用:用户级堆栈只是"[unknown]"。原因是,默认版本的 tar 编译时没有帧指针,并且此版本的 bcc/eBPF 需要它们来跟踪堆栈跟踪。我想展示这个 gotcha 是什么样子的, 以防你打它。
我修复了 tar 的堆栈 (请参阅前面的先决条件), 以查看它们看起来像什么:

好的,所以看起来 tar 具有文件系统树的递归行走算法。
这些堆栈跟踪很棒 - 它显示了应用程序阻止和等待 CPU 外,以及多长时间。这正是我通常要找的信息。但是,阻止堆栈跟踪并不总是那么有趣,因为有时您需要查找请求同步上下文。
Request-Synchronous Context
等待工作的应用程序(如具有等待套接字的线程池的 Web 服务器)对 Off-CPU 分析提出了挑战:通常大多数阻塞时间将位于堆栈中等待工作,而不是执行工作。这会用不太有趣的堆栈来淹没输出。
作为这种现象的示例,下面是 MySQL 服务器进程的Off-CPU 堆栈,该进程不执行任何操作,秒零请求:

各种线程轮询工作和其他后台任务。这些后台堆栈可以主导输出,即使对于繁忙的 MySQL 服务器。我通常要查找的是数据库查询或命令期间的 CPU 关闭时间。这是重要的时间 - 伤害最终客户的时间。要在输出中查找堆栈,我需要在查询上下文中查找堆栈。
例如,现在从繁忙的 MySQL 服务器:

此堆栈标识查询期间的一些时间(延迟)。do_command() -> mysql_execute_command() 代码路径是放弃。我知道这一点,因为我熟悉来自此堆栈的所有部分的代码:MySQL 和内核内部。
可以想象编写一个简单的文本后处理器,它根据一些特定于应用程序的模式匹配来挑选出感兴趣的堆栈。这也许工作正常。还有另外一种方法,虽然还需要应用程序细节,但效率更高一些:扩展跟踪程序以检测应用程序请求(do_command() 函数,在此 MySQL 服务器示例中),然后仅记录在应用程序请求期间发生的 CPU 关闭时间。我以前做过, 它会有所帮助。
Caveats
最大的警告是 Off-CPU 分析的开销,如前面的开销部分所述,然后是获取堆栈跟踪的工作,我在前面的"先决条件"部分中总结了这一点。还有一些调度程序延迟和非自愿上下文切换需要注意,我将在这里总结,并唤醒堆栈,我将在下一节中讨论。
Scheduler Latency
这些堆栈中缺少的是,如果 Off-CPU 时间包括等待 CPU 运行队列所花费的时间。此时间称为计划程序延迟、运行队列延迟或调度程序队列延迟。如果 CPU 以饱和状态运行,则每次线程阻塞时,它可能会承受额外的时间等待其打开 CPU 后被唤醒。该时间将包含在Off-CPU 时间中。
您可以使用额外的跟踪事件来区分 Off-CPU 时间与计划程序延迟,但在实践中,CPU 饱和度很容易发现,因此,当您有已知的 CPU 饱和问题要处理时,您不太可能花费大量时间研究 Off-CPU 时间。
Involuntary Context Switching
如果您看到用户级堆栈跟踪没有意义(显示没有理由阻止和Off-CPU),这可能是由于非自愿的上下文切换。当 CPU 饱和,内核 CPU 调度程序让线程打开 CPU,然后在它们到达其时间切片时启动它们时,通常会发生这种情况。线程可以随时启动,例如在 CPU 重代码路径的中间,生成的 CPU 外堆栈跟踪没有意义。
下面是一个示例堆栈从 fcputime,可能是一个非自愿的上下文开关:

不清楚(基于函数名称)为什么此线程在 Item_func:type()。我怀疑这是一个非自愿的上下文开关, 因为服务器是 CPU 饱和的。
使用 offcputime 的解决方法是筛选TASK_UNINTERRUPTIBLE (2):
![]()
在 Linux 上,非自愿上下文切换发生在状态 TASK_RUNNING (0),而我们通常感兴趣的阻塞事件位于 TASK_INTERRUPTIBLE (1) 或 TASK_UNINTERRUPTIBLE (2)中,在使用 --state,这些阻塞事件可以匹配。我在 Linux Load Averages: Solving the Mystery中使用了此功能。
Flame Graphs
Flame Graphs 是分析堆栈变化的可视化工具,对于快速理解可由 Off-CPU 分析生成的数百页堆栈跟踪输出非常有用。Yichun Zhang最先使用 SystemTap 制作了Off-CPU 时间火焰图。
offcputime 工具具有一个 -f 选项,用于以 "folded format": semi-colon delimited on one line, followed by the metric。这是我的FlameGraph软件作为输入的格式。
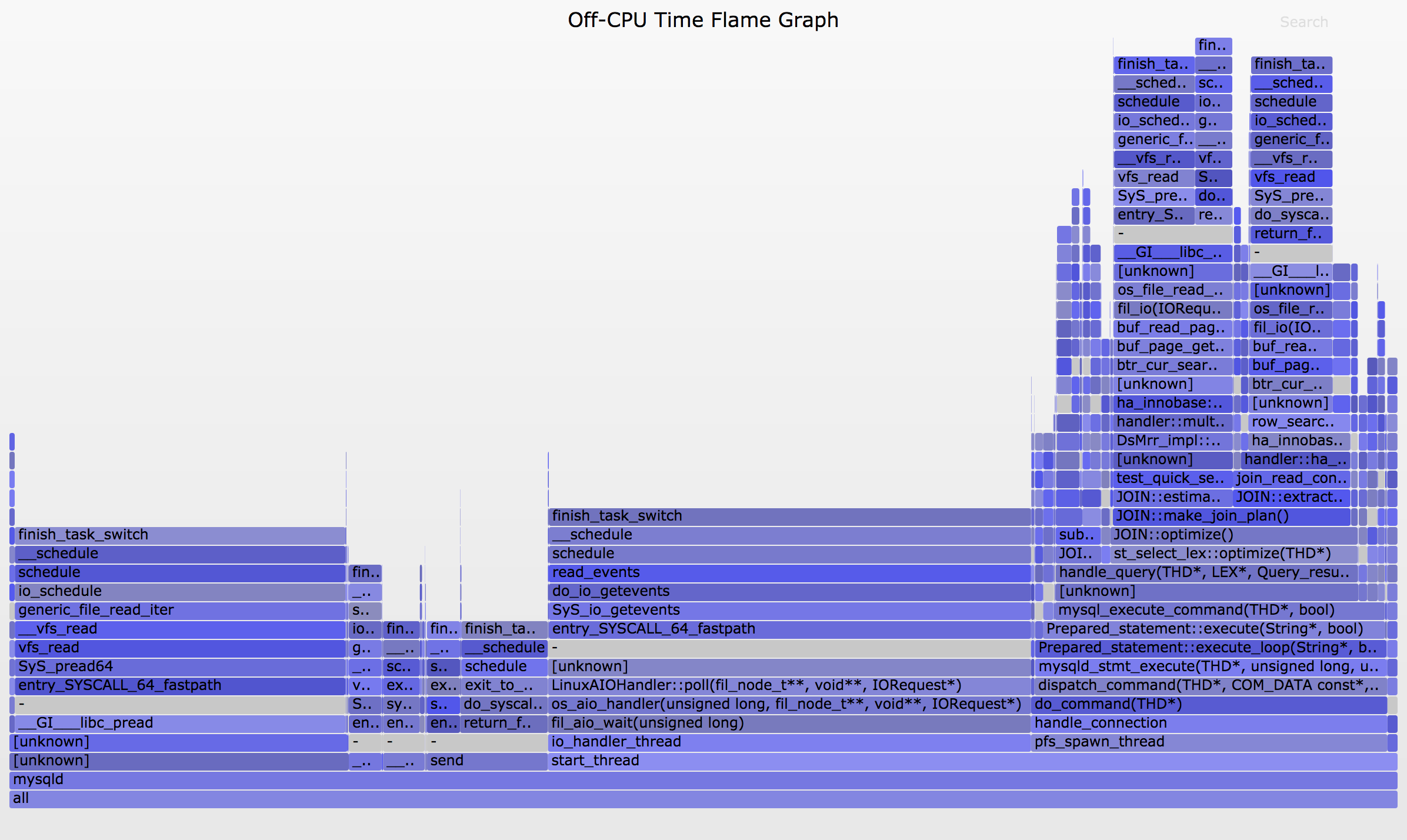
例如,为 mysqld 创建 Off-CPU 火焰图:
Then open out.svg in a web browser. It looks like this (SVG, PNG):
{kind=link}
{kind=link}

现在看起来更好了:这显示了所有Off-CPU 堆栈跟踪,堆栈深度在 y 轴上,宽度对应于每个堆栈中的总时间。从左到右排序没有意义。内核和用户堆栈之间有分隔帧"-",这些帧由 offcputime 的 -d 选项插入。
您可以单击以缩放。例如,单击右do_command的"do_command(THD*)"框架,可放大查询期间发生的阻塞路径。您可能希望生成仅显示这些路径的火焰图,这些路径可以像 grep 一样简单,因为折叠格式是每个堆栈一行:![]()
That looks great.
For more on off-CPU flame graphs, see my Off-CPU Flame Graphs page.
Wakeups
现在,您已经知道如何进行Off-CPU 跟踪并生成火焰图,您开始真正查看这些火焰图并解释它们。您可能会发现许多Off-CPU 堆栈显示阻塞路径,但不包括阻止路径的全部原因。原因是代码路径在另一个线程,即调用阻塞线程上的唤醒线程。这种情况经常发生。
我在Off-CPU Flame Graphs中介绍此主题,以及两种工具:wakeuptime and offwaketime,以测量唤醒堆栈,并将其与Off-CPU 堆栈关联。
Other Operating Systems
- Solaris: DTrace can be used for off-cpu tracing. Here is my original page on this: Solaris Off-CPU Analysis.
- FreeBSD: Off-CPU analysis can be performed using procstat -ka for kernel-stack sampling, and DTrace for user- and kernel-stack tracing. I've created a separate page for this: FreeBSD Off-CPU Analysis.
Origin
在探索了 DTrace sched 提供程序及其 sched 的用途后,我开始在 2005 年使用这种方法desched:::off-cpu。在DTrace探测器名称之后,我称它为Off-CPU分析和Off-CPU时间测量(这不是一个完美的名字:2005年在阿德莱德教授DTrace课程时,一位太阳工程师说我不应该称它为Off-CPU,因为CPU不是"关闭")。Solaris 动态跟踪指南提供了一些测量从 sched:关闭 cpu 到 sched:在 cpu 上某些特定案例和过程状态的时间的示例。我没有筛选进程状态,而是捕获了所有Off-CPU 事件,并包含堆栈跟踪来解释原因。我认为这种方法是显而易见的,所以我怀疑我是第一个这样做,但我似乎是唯一真正推广这种方法的人一段时间。我在 2007 年写了DTracing Off-CPU Time, 并在后来的帖子和谈话中写过。
Summary
Off-CPU 分析是查找线程阻止并等待其他事件的延迟类型的有效方法。通过从上下文切换线程的内核调度程序函数中跟踪,可以以相同方式分析所有Off-CPU 延迟类型,而无需跟踪多个源。若要查看 OFF-CPU 事件的上下文以了解事件发生的原因,可以检查用户和内核堆栈回跟踪。
借助 CPU 分析和 Off-CPU 分析,您可以全面了解线程花费时间的方式。这些是互补技术。
For more on off-CPU analysis, see the visualizations in Off-CPU Flame Graphs and Hot/Cold Flame Graphs.
Updates
My first post on off-CPU analysis was in 2007: DTracing Off-CPU Time.
Updates from 2012:
- I included off-CPU analysis as a part of a Stack Profile Method in my USENIX LISA 2012 talk. The Stack Profile Method is the technique of collecting both CPU and off-CPU stacks, to study all the time spent by threads.
Updates from 2013:
- Yichun Zhang created off-CPU flame graphs using SystemTap and gave the talk Introduction to off CPU Time Flame Graphs (PDF).
- I included off-CPU flame graphs in my USENIX LISA 2013 talk Blazing Performance with Flame Graphs.
Updates from 2015:
- I posted FreeBSD Off-CPU Flame Graphs to explore the procstat -ka off-CPU sampling approach.
- I posted Linux perf_events Off-CPU Time Flame Graph to show how these could be created with perf event logging – if all you had was perf (use eBPF instead).
Updates from 2016:
- I posted Linux eBPF Off-CPU Flame Graph to show the value of this and help make the case for stack traces in eBPF (I had to hack them in for this proof of concept).
- I posted Linux Wakeup and Off-Wake Profiling to show wakeup stack analysis.
- I posted Who is waking the waker? (Linux chain graph prototype as a proof of concept of walking a chain of wakeups.
- I described the importance of off-CPU analysis at the start of my Facebook Performance@Scale talk: Linux BPF Superpowers (slides).
Updates from 2017:
- I used a few off-CPU flame graphs in my Linux Load Averages: Solving the Mystery post.
- I summarized off-CPU, wakeup, off-wake, and chain graphs in my USENIX ATC 2017 talk on Flame Graphs: youtube, slides.