将两个表或者多个表关联在一起是常见的运算,这时通常使用 SQL join 的方式进行关联并进行后续计算。但有时数据并不存储在数据库,而是以文件的形式存储在文件系统,单纯为了计算而把数据存储到数据库有点得不偿失。
Python 的 Pandas 提供了丰富的关联运算函数,能更方便的完成文本文件间的关联计算,现在我们就一起来讨论下 Python 的关联处理。
基础关联
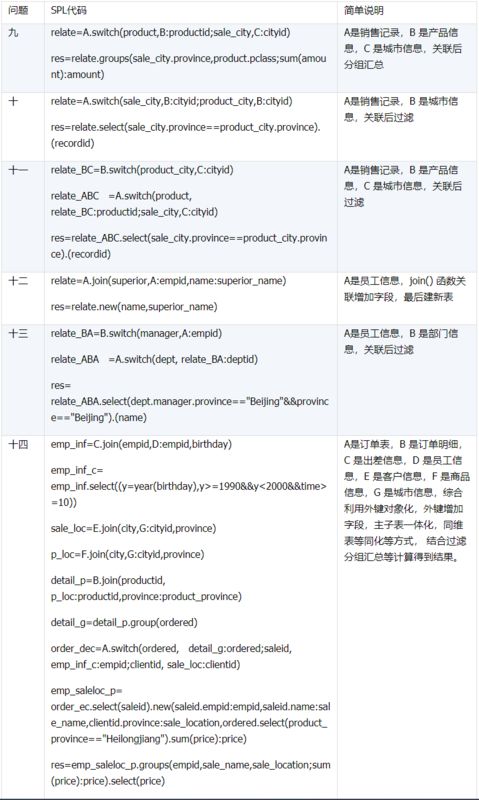
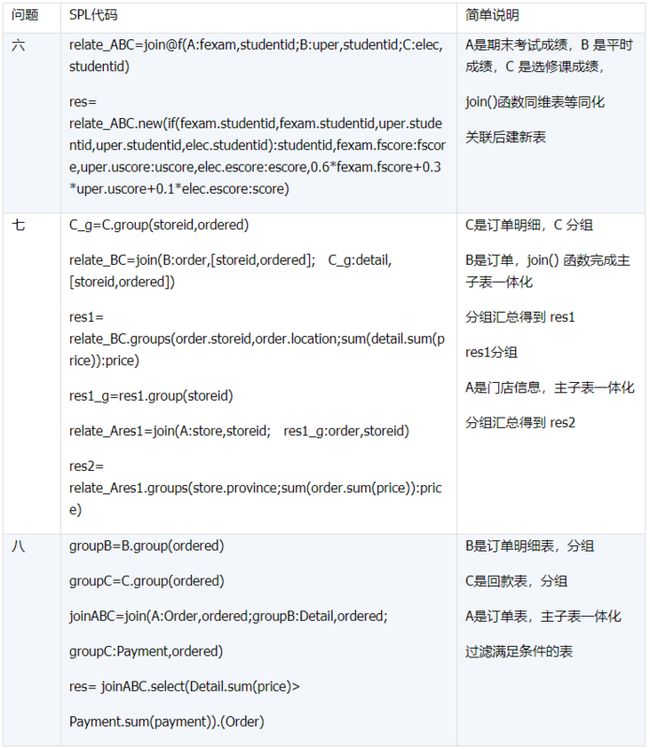
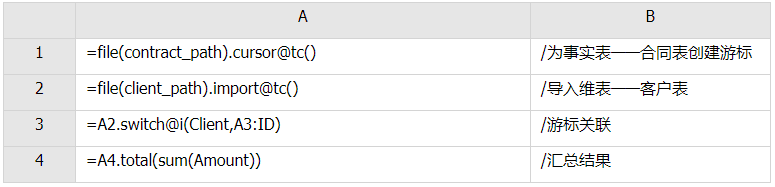
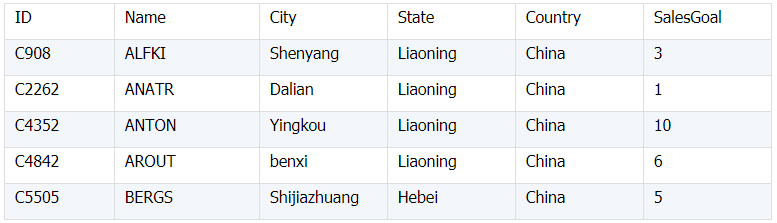
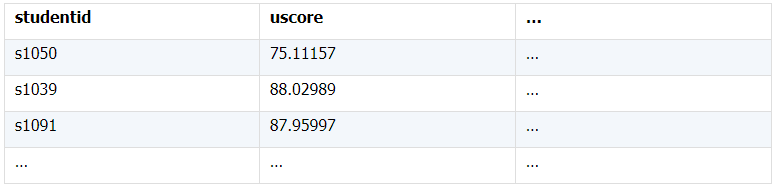
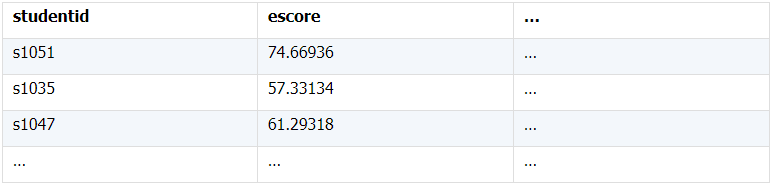
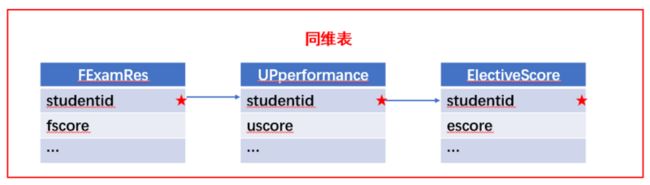
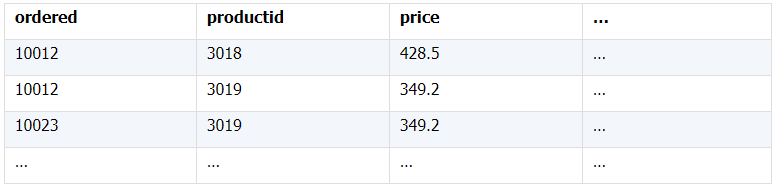
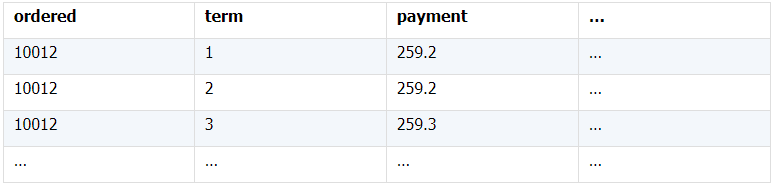
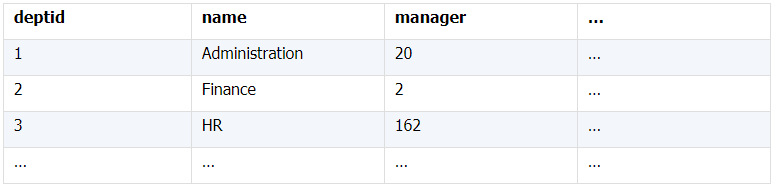
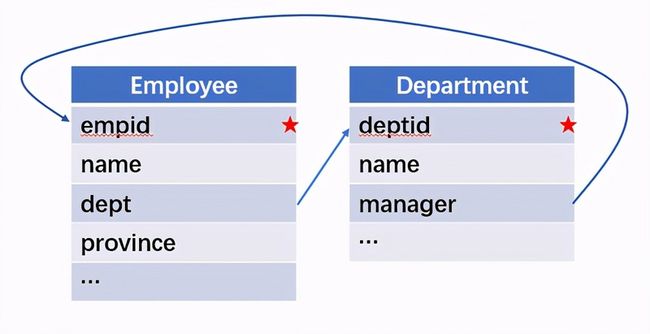
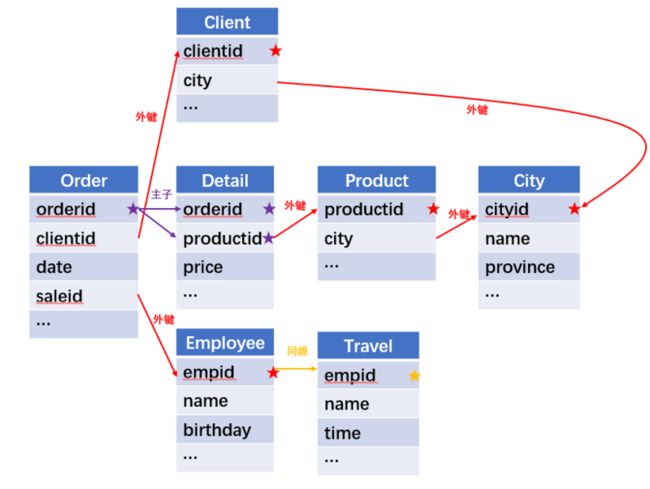
所谓关联是指两张数据表通过某个字段或者某些字段之间存在的某种关系,将两张表以某种条件关联起来。SQL 中的关联可以是等值 JOIN 也可以是非等值 JOIN,所谓非等值 JOIN 就是 JOIN 时的过滤条件不一定是相等的,比如 select A.x,B.y from A join B on A.a 关联的方式有内连接、左连接、右连接、全连接。Pandas 使用 merge() 函数的 how 参数完成,其中 inner:内连接,left:左连接,right:右连接,outer:全连接(默认 how=‘inner’)。下面以一些例子加以说明。 合同数据文件和老客户数据文件分别存储在两份文件中,合同数据文件是 2019 年的合同信息,其中的 Client 可能有新客户,部分内容如下: 老客户数据文件是历年来经常合作的老客户的信息,部分内容如下: 内连接,是两表关联后,保留两表共有的键。 问题一:计算老客户 2019 年的合同总金额 问题分析:由于合同数据中可能有新客户,也可能有老客户没有在 2019 年签订合同,所以需要使用内连接的方式将两表关联。 Python 代码 讨论:本例中关联列在两个 dataframe 中列名不同,不能使用 on 参数,而是使用 left_on,左 dataframe 的关联列名,和 right_on,右 dataframe 的关联列名,此时默认的参数 how=’inner’,对关联结果的 Amount 列求和得到结果。 左连接,指两表关联后,保留左侧表的全部键,右侧表不具备左侧键的列为 nan。 问题二:计算出各省客户的合同金额,新客户的省份用 unknown 表示。 问题分析:因为不光要求各省老客户的合同金额,还要把新客户作为 unknown 来计算,因此关联的时候需要使用 left 的方式。 Python 代码 讨论:修改默认参数 how=‘inner’为‘left’,实现左连接,保留新客户的合同信息。后续再用‘unknown’填补缺失值,分组求和得到结果。 右连接和全连接的方式就是修改 how=‘right’或者 how=‘outer’。这里就不再一一举例了。 左排除连接,指两表关联后,只保留左侧键值未在右侧表的键出现的行,右侧表的列为 nan。 问题三:计算新客户的合同总金额 问题分析,只求新客户,只需要左连接后,排除掉两表共有键的行就可以了。 Python 代码 讨论:左连接时,增加参数 indicator,那些两表共有的键的行为 both,左表独有的键的行为 left_only,右表独有的为 right_only。然后筛选出 left_only 标记的行就得到了新客户的行,直接求和得到结果。 右排除连接和全排除连接和左排除连接类似,这里也不举例说明了。 Pandas 中的关联函数除了 merge,还有 join 和 concat,我们继续以问题一——计算老客户 2019 年的合同总金额作为案例简单介绍一下这两个函数的使用方法。 join 函数 Python 代码 讨论:join() 函数关联时,只能使用两表的索引,因此需要先将关联列设置成索引。join 时默认的方式 how=‘left’,这里需要修改为‘inner’。最后求和即可。 concat 函数 问题分析:concat()函数关联时,要求关联表的索引是唯一的,这里合同数据的 Client 列有重复,不适合使用 concat() 函数关联,不过为了更好的理解 concat 函数,我们对数据中的客户去重,然后再用 concat 连接。 问题四:求老客户 2019 年第一份合同的总金额。 Python 代码 讨论:把两个 dataframe 放入列表,axis=1 指按行索引进行关联,默认的 join 方式是 outer,这里改为 inner,最后进行求和。 多字段关联是指两表关联时的键不是单一字段,需要同时关联两个或者更多字段。 现有学生表,部分内容如下: 班级表,部分内容如下: 问题五:查询学生的学号、姓名、专业、班级和班主任 问题分析,要查询学生的学号、姓名、专业、班级和班主任,需将两表按照专业号 majorid 和班级号 classid 进行关联。 Python 代码: 讨论:Pandas 支持多字段关联,只要把要关联的字段放入列表里就可以了。 如果两表的关联字段名不同,如学生表的专业号和班级号是 MAJORID 和 CLASSID。 Python 代码 讨论:merge 函数中使用 left_on 和 right_on 参数即可。 表 A 的主键与表 B 的主键关联,他们是一对一的关系,A 和 B 互称为同维表。 期末考试成绩表,平时成绩表,选修课成绩表部分内容如下: 期末考试成绩表 平时成绩表 选修课成绩表 问题六:统计学生的学期成绩(期末考试成绩、平时成绩、选修课成绩所占比例分别是 0.6,0.3,0.1)。 问题分析: 三张表都是以学生学号为主键,但有的学生可能没有参加某一项的考试,因此可能会有学生缺少某一项成绩,在关联的时候需要使用外关联的方式。 关联关系如下图: Python 代码: 讨论:因为三类成绩的主键都是学生学号,因此将学号设为索引,然后使用 concat 函数同时关联三张表,使得关联更加快捷。 表 A 的主键与表 B 的部分主键关联,A 称为主表,B 称为子表。主子表是多对一的关联关系。 门店信息,订单表,订单明细表部分内容如下: 门店信息表(主表): 订单表(门店信息表的子表,订单明细表的主表): 订单明细表(订单信息表的子表) 问题七:查看各门店各省客户的消费情况和各省门店的销售情况。 问题分析:1. 订单表和订单明细表关联,其中订单表是主表,订单明细表是子表,关联字段是 [storeid,ordered],关联后分组汇总即得结果。 2. 门店信息和第 1 步的汇总结果关联,门店信息表是主表,第 1 步的汇总结果是子表,关联字段是 storeid,关联后分组汇总即得结果。 关联关系如下图: Python 代码: 讨论:主子表关联时要一步一步理清关联关系,找准关联字段和需汇总的字段,必要的时候画出关联关系图。本例实际上是两次主子表关联,每一步关联也可以按照分组汇总——同维关联——分组汇总的方式完成。具体代码如下: 订单表,订单明细表,回款表部分内容如下: 订单表(主表) 订单明细表(子表) 回款表(子表) 问题八:找出未完全回款的订单 问题分析:订单表是主表,订单明细表和回款表都是子表,关联的字段是 ordered。注意这里不可以先用主表分别与两个子表关联,再用两个关联结果关联,因为这样做会发生多对多的关联,使得计算错误。正确的做法应该是先对两个子表汇总,然后再分别与主表关联,得到最终的结果。 关联关系如下: Python 代码: 讨论:两子表汇总结果与订单表的索引相同,此时可以使用 join 函数或者 concat 函数同时关联多表,最后筛选即可得到结果。 表 A 的某些字段与表 B 的主键关联,表 A 的关联字段可以不唯一,表 B 的关联字段唯一,这就是多对一关联,也称作外键关联,即表 A 是事实表,表 B 是维表,A 表中与 B 表主键关联的字段称为 A 指向 B 的外键,B 也称为 A 的外键表。下面介绍几种常见的外键关联实例: 销售记录表、城市信息表、产品信息表部分内容如下: 销售记录表 (事实表): 城市信息表(维表 1): 产品信息表(维表 2): 问题九:汇总各个省份各类产品的销售额。 问题分析:计算各省的各类产品的销售额,需要用销售记录表的 sale_city 和城市信息表的 cityid 关联获取省份的信息,用 product 和产品信息表的 productid 关联获取产品类别信息。 关联关系如下图: Python 代码 讨论:销售记录表作为事实表,分别与两个维表关联,得到一张宽表,最后对宽表分组汇总即可。 销售记录表,城市信息表部分内容如下: 销售记录表(事实表): 城市信息表(维表): 问题十:找出产品产地与销售地在同一省份的销售记录。 问题分析:产品产地与销售地都要关联城市信息,从而找到两者在同一省的销售记录,城市信息表被关联了两次。 关联关系如下: Python 代码: 讨论:第二次关联城市信息时,recitys 的表中已经有了城市的信息,因此需要设置相同字段名的后缀,这里把销售地的城市信息加后缀“_s”,产地信息后缀“_p”,最后过滤出两者省份相同的记录即可。 销售记录表、城市信息表、产品信息表部分内容如下: 销售记录表 (事实表): 城市信息表(维表 1): 产品信息表(维表 2): 问题十一:找出产品产地与销售地在同一省份的销售记录。 问题分析:为获取产品信息,需要用销售记录关联产品信息。关联产品信息后就和例 2 类似了,分别用产地和销售地关联城市信息,过滤后就可得到产品产地与销售地在同一省份的销售记录。 关联关系如下: Python 代码 讨论:三次关联,1. 销售记录与产品;2. 销售地与城市;3. 产地与城市。最后对三次关联后的结果过滤即可。 员工信息表部分内容如下: 问题十二:列出所有员工姓名及其直接上级的姓名。 问题分析:要获取上级的名字须用上级的工号 superior 与员工表的工号 empid 关联。 关联关系如下: Python 代码 讨论:自己既是事实表又是维表,关联的时候设置后缀即可。 员工信息表,部门信息表部分内容如下: 员工信息表: 部门信息表: 问题十三:找出北京经理的北京员工 问题分析:首先要关联部门信息表,找到经理字段;然后用经理字段关联员工编号;最后筛选出北京经理的北京员工。 关联关系如图: Python 代码: 讨论:第一步关联时,员工信息表是事实表,部门信息表是维表;第二步关联时,关联的结果是事实表,员工信息表是维表,这就形成了环状关联。由于员工信息表和部门表都有 name 字段,所以第一步关联时,默认为员工信息表的 name 字段增加了后缀“_x”。 现有以下几张表:订单表,订单明细表,产品信息表,员工信息表,出差信息表,客户信息表,城市信息表,他们的表结构与关联关系如下: 问题十四:计算出差时间大于 10 天的 90 后销售员在各省份销售黑龙江商品的金额。 问题分析: 多张表关联,要理清下述三个问题: (1) 关联关系,多对一、一对一、一对多(当发生多对多关联时,多半是错了)。 (2) 关联方式,内连接、左连接、右连接、全连接。 (3) 关联与处理的顺序,先处理(包括过滤和分组)还是先关联。 Python 代码: 讨论:在日常工作中,经常会遇到这种混合的关联,多种关联关系混在一起,理不清其中的关系,会事倍功半甚至得到错误的结果。 Python 中的关联是将两表根据某个或者某些字段连接在一起,组成一张宽表,这和 SQL 类似。从上述例子中也可以看出,Python 在解决基础关联和同维关联(问题一至问题八)时,还是比较方便的,一步一步计算下来,思路清晰,代码也好理解。 但是,对于外键关联,Python 的处理方法有这样一些问题: 1.Python 的 merge 函数一次只能解析一个关联关系,在关联关系较多时比较麻烦。 相比之下,esProc SPL 在处理外键关联时要聪明一些。SPL 会建立外键与主键对象的关联,并没有复制数据本身,这样就可以同时建立多个关联关系,计算快捷且节省内存,而且发生自关联(循环关联)时,也可以重复利用建好的关联关系,简洁而高效。 比如问题九至十四,SPL 代码写出来是这样的: 问题SPL代码简单说明 当然,SPL 处理同维关联也一样简单,比如问题六至八: Python 还有一个比较严重的缺点,那就是当数据量大到无法一次性载入内存时,使用 Python 进行关联运算将是灾难性的,几乎所有的关联方式都需要自己手动来实现,涉及到外存排序,hash 分段等等复杂代码,非高级程序员几乎不可能完成。这些代码实在过于繁琐,这里也就没有再给出来。对于大文件的场景,Python 不再合适,还是得用 SPL,它提供有游标对象,可以轻松解决内存装不下的文件之间的关联及其它运算。 比如问题一计算 2019 年老客户的合同总金额。当合同数据很大,无法一次性载入内存时,而客户数据可以放入内存时,可以为合同表创建游标来计算,SPL 代码只有区区几行: 两个表都特别大时,SPL 还提供了 joinx() 函数,对有序游标进行关联,可以非常高效的完成大数据的关联任务。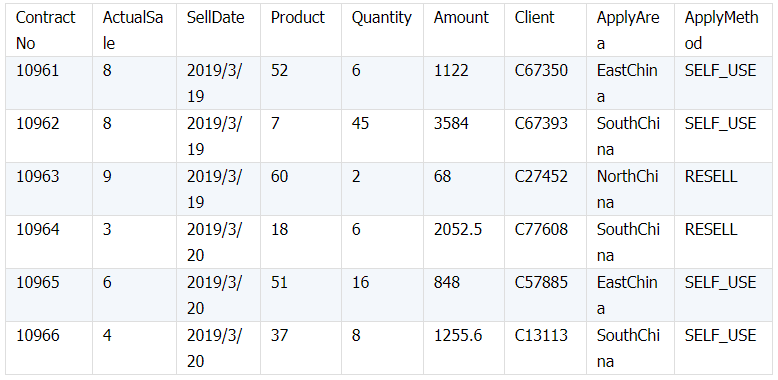
内连接(inner)

左连接(left)

左排除连接(left_exluding)



多字段关联




同维关联
(一)多同维表


(二)多层主子表

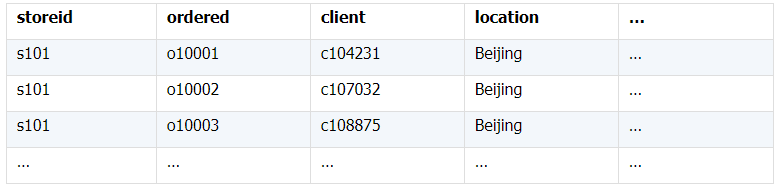
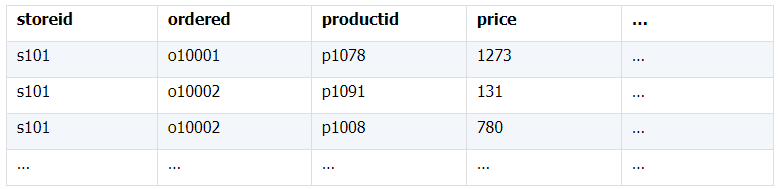
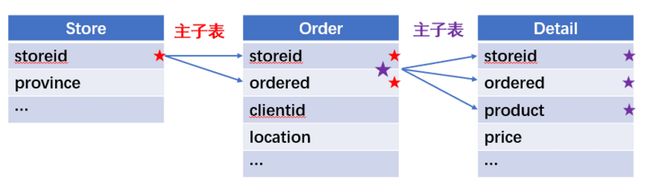


(三)多子表查询
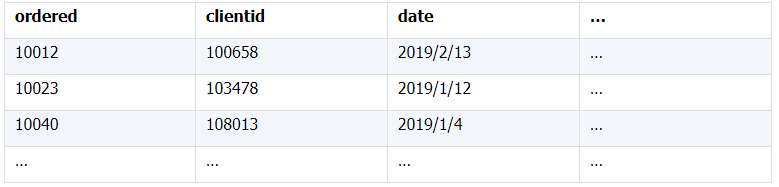
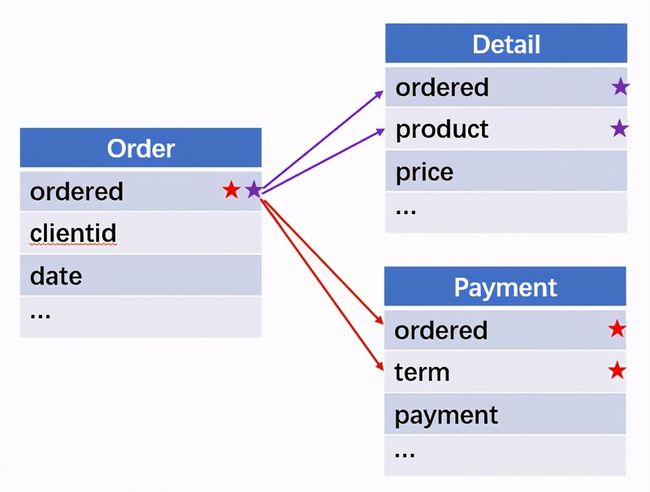

外键关联
(一)一个事实表,多个不同维表。
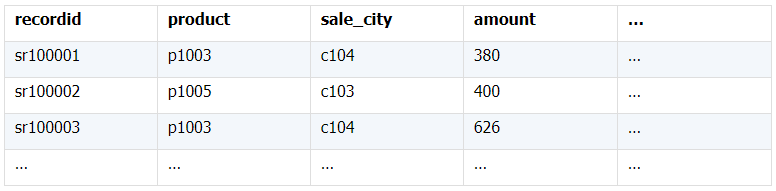
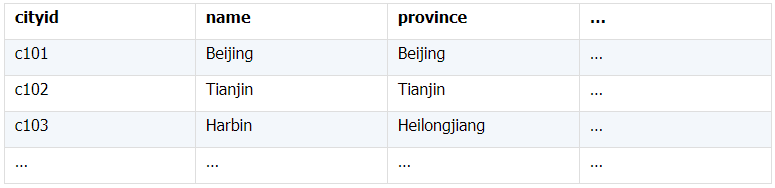
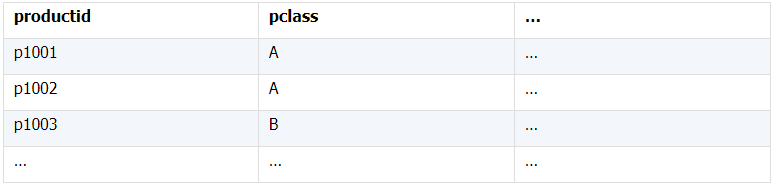
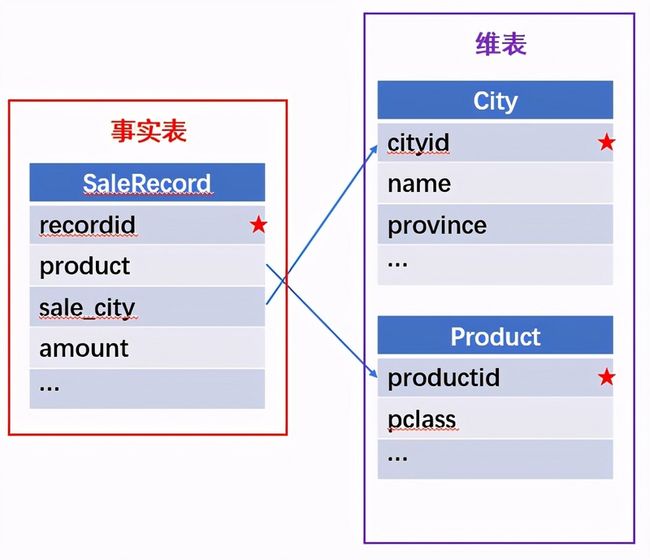

(二)一个事实表,多个维表有维表被多次使用。
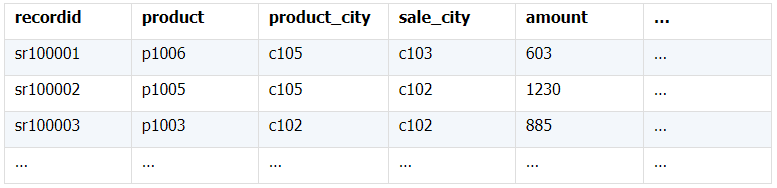
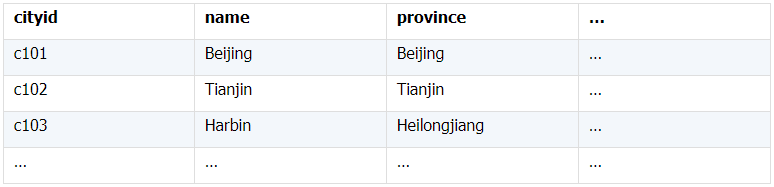
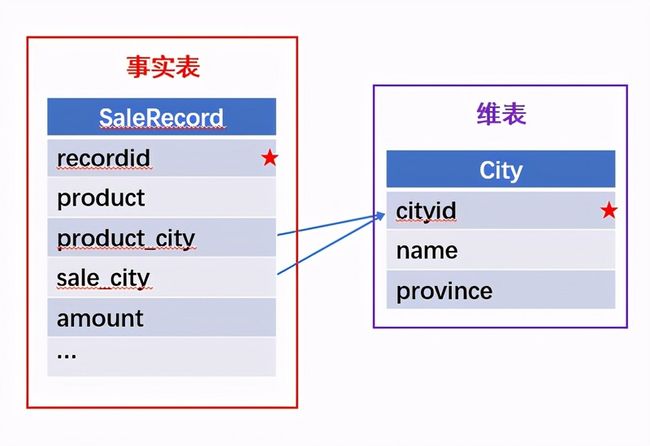

(三)多层维表
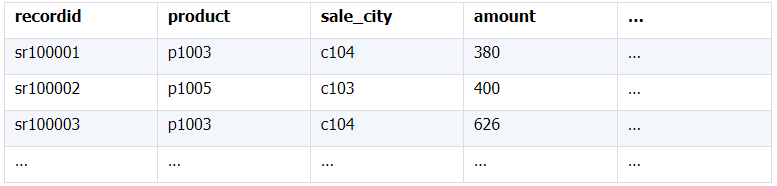
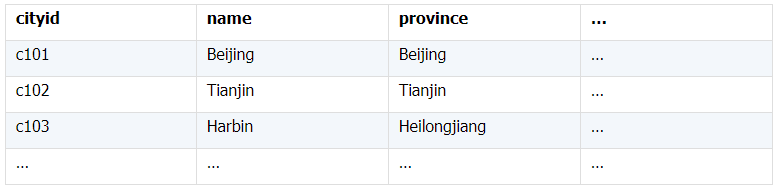

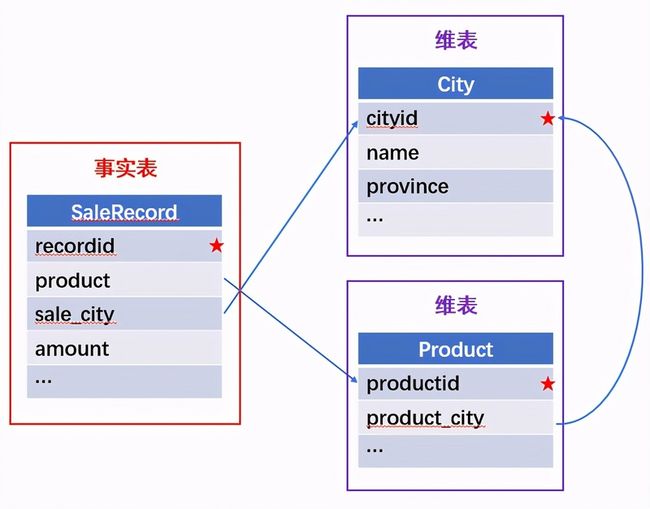

(四)自关联
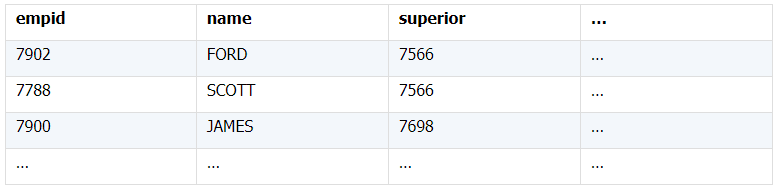
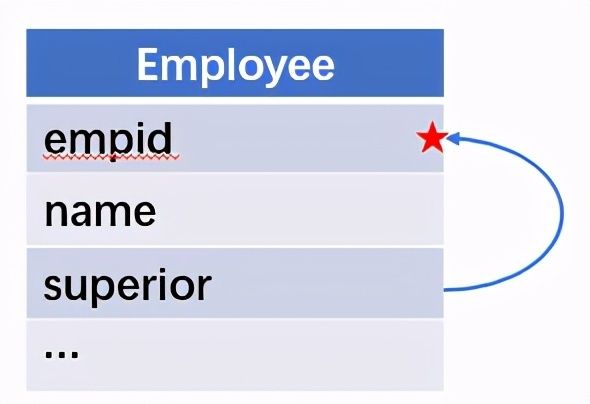

(五)环状关联。


小结