Princeton NLP Group姚顺雨博士:文本游戏中基于语言模型的动作生成
⬆⬆⬆ 点击蓝字
关注我们
AI TIME欢迎每一位AI爱好者的加入!
“你在卧室,东边是一个走廊,西边有一个紧闭的木门,屋子中间有一个厚地毯,一个储物柜,你有一个钥匙……”在文本游戏里这样的观察(observation)下你会做什么探索?“向东走”,“揭开地毯”,“用钥匙开木门”,“打开柜子”?……生成这些候选动作(action candidates)需要充分的语言和常识理解。之前的模型往往通过游戏的作弊器(handicap)或人造规则(ad-hoc rules)生成候选动作,然而这样方法缺少对语言的学习理解,且难以泛化。我们提出利用一种语言模型 CALM(n-gram,GPT-2)学习动作生成的任务,并收集了ClubFloyd Dataset,其中有不同人类选手在超过500种游戏里20万组动作生成的数据。CALM训练后被用作动作生成器与强化学习结合,并在未训练的游戏上取得了state-of-art的游戏分数。
本期AI TIME PhD直播间,我们有幸邀请到了Princeton NLP Group博士生姚顺雨为我们进行分享,本次分享的主题是——文本游戏中基于语言模型的动作生成

姚顺雨:Princeton NLP Group博士生,导师为Karthik Narasimhan。目前研究方向为交互环境中的语言学习与运用。

一、文本游戏和动作生成

语言游戏就是一种用语言玩的游戏,你会收到一些语言的观察信息,例如你在这个地方看到了什么,有什么东西之类。你的工作就是输入一个文本的动作,比如:open mailbox,read leaflet,go north。每当你输入一个新的语言动作的时候,游戏的引擎会告诉你一个新的文本的观察,相当于游戏中载入一个新的剧情或者场景,你可以在语言的世界里面不停的做一些动作,然后会获得一些数字积分的奖励。
从对游戏的研究来看,在这个游戏里面有两种不同的视角。首先游戏的运行方式可以看作一个强化学习的环境,它可以等效成为一个离散的马尔科夫决策过程问题(MDP),你会有很多不同的状态,能进行很多不同的动作。大多数动作不会导致游戏状态改变,并且你获得分数的操作是非常稀疏的,可能要进行很多动作才能获得奖励。但是从玩家的视角来说他就是一个故事,你的行动方式不是在以分数为目标,而是生活中的常识判断。所以这两种视角最大的区别就是有没有对语言的理解和应用。
从上文能够知道这是一个部分可观测的马尔科夫决策过程问题,这涉及到两个问题:
(1)玩这种游戏它需不需要语言理解;
(2)我们是不是可以直接用一种强化学习的方法去解决这个游戏。
因为我们想用这种游戏作为一种研究问题,进而通过这种环境产生一种对语言的理解应用。但如果只是使用单纯的强化学习去暴力通关就违背了项目的初衷。
在这当中,一个最直接的挑战就是动作空间,强化学习不能够直接解决这个挑战。比如说当你处在一个环境中,你需要生成接下来的动作,如果你的状态空间没有数据规模庞大的动作候选,强化学习是无法运行的。因此一个最直接的挑战就是怎么获得符合语法,能够改变游戏状态的动作。这是单纯的强化学习不能解决的,所以之前主要通过两种方法去解决动作空间的问题,第一种就是使用人造规则,比如说看到上面写着房间很黑暗,看到黑暗这个词就自动生成打开灯的动作,这是一种ad-hoc的方法。另一种ad-hoc的方法叫action handicap,就是动作生成器,也称为作弊器,本质上就是枚举可能的所有动作,并且找到其中的合法动作,实现这一过程需要模拟器的作弊功能。但是这两种方法与语言理解没有关系,也不具备方便的泛化性。所以我们想要研究一种方法通过语言学习生成合理的动作。在这个工作中我们使用了一种语言模型去生成合理的动作,这个方法的最大的好处就是具备泛化的能力。
二、构建模型
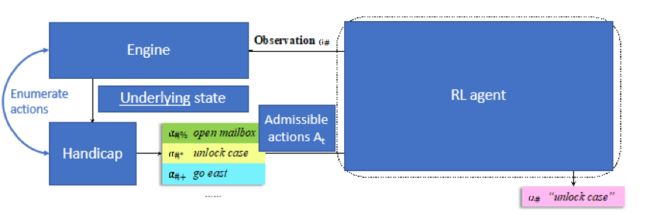
为了理解我们的模型在哪方面有着创新,先来看一个强化学习的模型。强化学习模型的输入是文本环境的描述,并且包含一个可能的候选的动作列表。你可以通过一些方法选择最好的一个动作来优化你的游戏分数。为了控制动作空间的大小,之前的强化学习方法都使用了Handicap,就是一个动作生成作弊器,本质上来说就是枚举不同的可能动作,并且使用读档存档,调用模拟器状态,来找出改变游戏状态的这些动作。这个方法有利有弊,优点在于枚举准确且数量有限,缺点在于假如游戏没有激活模拟器或者没有读档存档就不能使用。
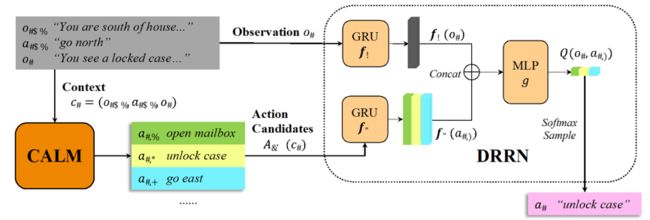
在这个工作里,我们提出了这个语言模型Contextual Action Language Model (CALM),当这个模型训练好之后就是一个冷冻的语言模型。将游戏之前的观察和动作输入到这个语言模型里面,模型就会帮你产生一些可能的动作候选。这里提出的强化学习的模型现在是一个语言模型。这样做有两个直接的好处,首先不需要作弊的功能,也不需要读档存档,以及调用模拟器的操作,第二个好处就是实现了泛化,即不依赖游戏的存档机制和模拟状态的情况下,模型可以应用到任何游戏上面。这里动作空间原本是由一个作弊器产生,现在由一个语言模型产生,所以对强化学习模型没有任何假设。在这个工作里面,我们使用了强化学习模型,叫做Deep Reinforcement Relevance Network (DRRN),本质上来说可以和任何强化学习模型进行结合。
我们收集了人类玩游戏的轨迹,因为很难获得机器玩游戏并且玩很好的轨迹。这个语言模型的任务也很简单,基于之前游戏的历史,即之前的一个动作和现在的一个观察,然后基于人类行为去预测下一个动作。我们现在尝试了两种语言模型,首先是GPT-2,其做一个条件语言生成,使用的是标准的交叉熵损失函数。另一个就是一个更低级的语言模型,N-gram,当你计算一个动作产生的概率时,其实就是用N-gram的统计量来计算,即在训练集里面,N-gram统计越多,这个动作出现的概率越大。所以N-gram的概率计算是和上下文没有关系的,但它生成的动作仍然基于游戏语境。

假设语言模型训练完成,现在用这个模型生成Top-K的动作候选。从上图的游戏文本中可以看到,在房间里有门,箱子,地毯,灯等物品。N-gram的模型就是获取房间、门这样的名词,然后根据训练模型中的统计量找到和它最匹配的动词。GPT-2就更灵活一些,模型可以生成任意长度或任意格式的动作,即有简单的动作,也有复杂的动作。把这些生成的动作当作简化的动作空间,在这之间进行强化学习。通俗的理解就是,语言模型学到的是一种非常宽泛的或者通用的生成动作的先验知识,这先验知识可能比较合理,但不能依赖它在一个新的游戏里面直接生成直接获得分数的动作,它只能生成一堆合理的动作,这时候需要强化学习从一堆动作中找到最利于获得分数的动作。
三、实验分析

接下来就讨论一下使用的数据还有实验。其中一个数据集叫ClubFloyd,因为它来自于一个叫ClubFloyd的网站,这是一个文本游戏爱好者的聚集地。我们收集了超过500种游戏,超过20万个训练数据,这里比较重要的一点是人类的动作充满了噪声,动作生成器在同一状态下会有很多不同的动作,所以人类的动作也非常的随机,其目的也不是为了最大化游戏分数,但重要的是这些动作包含了很多常识,我们希望模型能够获得这些常识的知识,并且用到新的游戏里面。
另一方面为了测试这个模型,并且进行强化学习,我们使用了另一个数据集,叫做Jericho Benchmark,之前的ClubFloyd只有文本的轨迹,并没有游戏的文本。而在这个数据集中有28个游戏,并且具有模拟器和模拟器的读取功能。从另一方面也就拥有了动作作弊器,可以获得每一步具有哪些合法动作,另一方面玩家也为这28个游戏标注了最优轨迹,沿着这个轨迹走就能获得最高分数。这里进行了这两种数据集的比较,可以看到ClubFloyd有着更多的游戏,单词量更大,轨迹更长,因为它没有标注最优解,所以很适合做训练集。另一方面Jericho Benchmark的轨迹非常的短,因为就是为了尽快获得最好的分数,动作质量是最好的,很适合做测试集。其中两个数据集有8个游戏是重合的,所以从ClubFloyd去掉了这8个游戏,这两个数据集没有重叠的部分,对泛化能力有所提升。
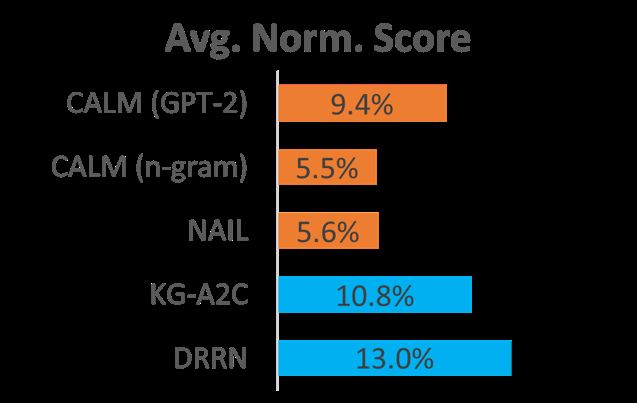
最主要实验的就是如何用CALM去强化并且获得分数。我们有三个基线,第一个NAIL,采用as-hoc rules,且不使用强化学习或者作弊器。第二个是DRRN,它使用作弊器生成动作空间。KG-A2C也是使用作弊器来生成动作,并且还使用了知识图谱的表示。所以DRRN和KG-A2C是两个使用作弊器最优的模型,而NAIL是不使用作弊器时最优的模型。
因为不同的游戏具有不同的总分,所以对游戏进行了平均归一化处理,可以看到在没有作弊器的模型里面,GPT-2 > N-gram ~ NAIL, CALM在没有作弊器的情况下把之前的成绩提升了接近两倍。在有作弊器的模型中,CALM和KG-A2C和DRRN相比,差别并不是很大。并且在结果中CALM(GPT-2)加DRRN模型在28个游戏中有8个游戏的表现优于KG-A2C和DRRN,它没有使用作弊器,不知道真正的合法动作是什么而且CALM也没有在这些游戏中训练过。
所以针对上述现象提出了两种假设,第一种是人类的动作可能不只是合法还包含合理性,所以一些合法但是不合理的动作没有被设计出来。还有一种可能是作弊器没有涉及所有合法动作,他可能丢掉一些合法动作,而模型能够捕捉到一些作弊器忽略的动作。
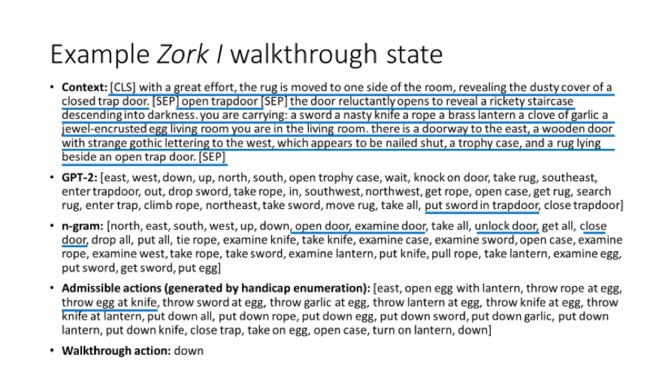
为了更直观理解模型怎么工作,举个例子。这是一个具体的文本,包含了之前的观察、之前的动作和现在的观察。在这种情况下GPT-2生成的动作,内容和形式都非常的多样化,并且还会生成一些非常长或者复杂的动作,比如put sword in trapdoor,即便这个动作在这个情况下不是一个合法动作。N-gram就是找一些名词,然后看哪些动词和它比较配,这些动作都非常简单,它很难生成比较长或复杂的动作。上面提及到作弊器能够生成一些合法的动作,但是有些合法动作不合理,例如throw egg at knife,虽然会造成游戏状态的改变,但是很明显人类不会选择这样的动作,CALM也不会。最后的是Walkthrough action,它只有一个down,这是这个情况下最好的选择。
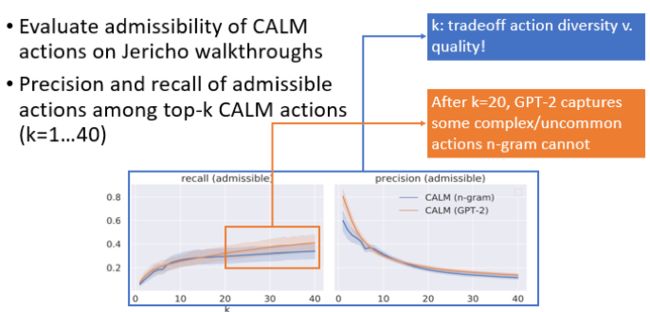
所以为了进一步分析我们的模型,使用了Jericho walkthroughs来研究CALM生成的动作有多少是合法的,其中采用precision和recall指标。考虑生成Top-k的动作,precision和recall是怎么变化的。上图是n-gram和GPT-2的动作合法性的recall和precision。很明显当生成的动作越多的时候,可能的合法动作也就越多,recall就越大,但同时动作质量会越来越低,因为k越大,生成动作质量可能会越差,也就导致了precision会越来也低。这里有一个折中点,k是一个很重要的控制动作空间大小的超参数。在k≤20时,n-gram和GPT-2很像,在k≥20的时候,recall会产生差异。其中的逻辑是,k≤20时,GPT-2同样只是生成一些简单的常见的动作,只有当大于20的时候才会产生一些复杂的不常见的动作。因为这些动作是n-gram无法产生的,所以会产生一个差异,也使得游戏的分数产生差异。
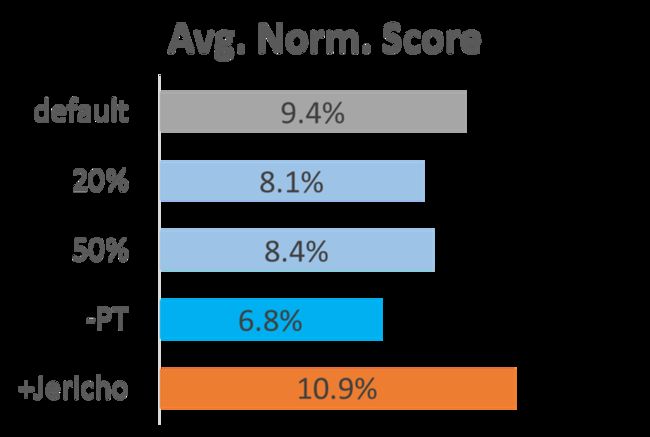
更进一步的,首先我们研究了数据的重要性,我们训练这个模型有两种数据,首先是GPT-2是预训练模型,其中预训练的是一部分数据,另一部分就是ClubFloyd对于文本游戏的训练。前面提到CALM(GPT-2)的分数达到9.4%,如果使用了20%或50% ClubFloyd数据,表现会有一个下滑,大约在8%左右;如果使用了一个随机初始化的GPT-2,下滑会更大,到达了6.8%;另一方面,将前面提及的8个重合的Jericho的游戏轨迹加入,对于游戏有着显著的提升,达到了10.9%,因为ClubFloyd和Jericho的游戏还是有很大的差别的。当加入这8个游戏的时候,并不代表这8个游戏的强化学习能力提高,反而是其他游戏成绩有所提高,证明泛化性有所提升。
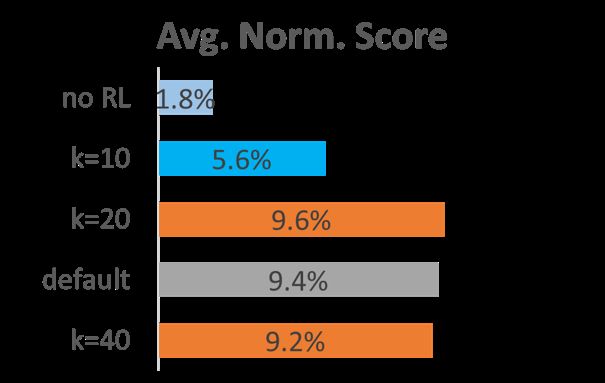
还有一部分对于强化学习的分析。当没有强化学习的时候是无法工作的,即通过CALM随机生成一些动作,然后随机采样,平均表现只有1.8%。另一方面,k也就是空间大小,是一个很重要的超参数,默认使用k=30,但是当使用k=20或40的时候,发现综合成绩比较相似,但是有些游戏20表现更好,有些游戏40表现更好,所以还能够进一步优化游戏,就是对每一个游戏特定一个动作空间大小。但是当k=10的时候,成绩会显著的变差,和之前的CALM(n-gram)的成绩很像。这和我们之前对于动作视角的分析也是比较一致的,因为生成的前10或十几个动作都是比较简单常见的动作,n-gram也能生成。但真正改变游戏成绩的是GPT-2在k>20后生成的一些复杂的不常见的动作。
总结
文章研究的问题是如何在文本游戏里面用语言模型进行动作生成,如果从强化学习的角度来说,会有一个非常巨大的动作空间,然后通过语言模型进行动作空间的减小,所以说我们的工作是强化学习和NLP两个之间的交界。从语言角度来说在文本游戏中组成动作其实是一种很典型的如何带有目的性的使用语言。通过语言模型的预训练它能够获得一种泛化能力,能够在全新的游戏上面生成合理的动作,并且这些动作能够支持游戏的进行。现在的模型还是非常的落后,即便达到最好的也只有百分之十几的分数。所以我们也公布了代码和数据集,希望继续帮助这个领域发展。
整理:闫昊
审稿:姚顺雨
排版:杨梦蒗
本周直播预告:


AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你,请将简历等信息发至[email protected]!
微信联系:AITIME_HY

AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注
(直播回放:https://b23.tv/lAiohV)
(点击“阅读原文”下载本次报告ppt)