万字长文,Python数据分析实战,使用Pandas进行数据分析
文章目录
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:101677771
- 一、Pandas的使用
- 1.Pandas介绍
- 2.Pandas基本操作
- Series的操作
- 创建DataFrame
- 常见列操作
- 常见行操作
- DateFrame的基本操作
- 时间操作
- 3.Pandas进行数据分析
- 读取数据
- 选择数据子集
- 数据清洗
- 布尔索引
- group_by()的使用
- 基本画图
- 二、简单分析College数据
- 三、鸢尾花数据集分析
- 1.基础操作
- 2.数据分析
- 四、电影评分数据分析
一、Pandas的使用
1.Pandas介绍
Pandas的主要应用包括:
- 数据读取
- 数据集成
- 透视表
- 数据聚合与分组运算
- 分段统计
- 数据可视化
Pandas的使用很灵活,最重要的两个数据类型是DataFrame和Series。
对DataFrame最直观的理解是把它当成一个Excel表格文件,如下:
索引是从0开始的,也可以将某一行设置为index索引;
missing value为缺失值。
DataFrame的一列就是Series,Series可以转化为dataframe,调用方法函数to_frame()即可。
2.Pandas基本操作
Series的操作
Series的常见操作如下:
sis = Series([4,7,-5,3]
sis.to_frame()
sis.value_counts() # 统计每个唯一值的所有出现次数
sis.size
sis.shape
sis.count() # 返回非缺失值的数目
sis.min()
sis.max()
sis.median()
sis.std()
sis.sum()
sis.describe() # 返回摘要统计信息和几个分位数
sis.isnull() # 非空值
sis.fillna(0) # 用0来补充缺失值
#上述函数可以结合使用,如下
sis.isnull().sum()# 统计空值的个数
创建DataFrame
创建数据帧的语法如下:
pd.DataFrame( data=None, index=None, columns=None, dtype=None, copy=False)
参数说明:
- data:可选数据类型,如:ndarray,series,map,lists,dict,constant和另一个DataFrame
- index:行标签索引,缺省值np.arrange(n),不计入df列
- columns:列标签索引,缺省值np.arrange(n),不计入df行
- dtype:每列的数据类型
- copy:默认值False,引用/复制数据
常见的几种创建数据帧的方式如下:
pd.set_option("max_columns",10,"max_rows",20) # 设置最大列数和最大行数
df = pd.DataFrame() # 空数据帧
df = pd.DataFrame(['a','b','c','d']) # 从一维列表创建
df = pd.DataFrame([['Alex',10],['Bob',12],['Clarke',13]], dtype=float) # 从二维列表创建,浮点型数字
df = pd.DataFrame({'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}) # 从字典创建,字典键默认为列标签
常见列操作
列名参与代数运算,表示列中每一个元素都与该数字进行同样的操作,如下:
movie = pd.read_csv('movie.csv')
imdb_score = movie['imdb_score']
imdb_score + 1 # 每一个列值加1
imdb_score * 2.5 # 给每一个列值乘2.5
imdb_score > 7 # 判断每一个列值是否大于7
imdb_score=="hello" # 判断是否等于字符串
imdb_score.floordiv(7) # imdb_score // 7,整数除法
imdb_score.gt(7) # imdb_score > 7
imdb_score.eq('James Cameron') # imdb_score == 'James Cameron'
type(imdb_score)
imdb_score.astype(int).mod(5) #每一个列值取模
sex_age = wl_melt['sex_age'].str.split(expand=True) # 对列使用字符串的多个方法
创建、删除列,通过[列名]来完成,如下:
movie["new_col"]=0
movie.insert(0, 'id', np.arange(len(movie))) # 插入新的列
movie["new_col"].all() #用来检测所有的布尔值都为True,用于比较两列是否相等
设置索引相关操作:
movie2 = movie.set_index('movie_title') # set_index()给行索引命名
movie2.reset_index() #复原索引
movie.rename(index=,columns=) # 其中参数值为键值对,键为旧值,值为新值。
movie.columns.tolist()
movie.columns=new_columns
# 索引第1个行索引的值
idx = pd.Index(list('abc'))
idx.get_level_values(0)
特殊的列选择如下:
movie.get_dtype_counts() # 输出每种特定数据类型的列数
movie.select_dtypes(include=['int']).head() # 仅选择整数列
movie.filter(like='facebook').head() # like参数表示包含此字符串
movie.filter(regex='\d').head() # movie.filter支持正则表达式
movie.filter(items=['actor_1_name', 'asdf']) # 传入精确列名的列表
常见行操作
添加新行,用loc指定:
new_data_list = ['Aria', 1]
names.loc[4] = new_data_list
#等价于
names.loc[4] = ['Aria', 1]
names.append({'Name':'Aria', 'Age':1}, ignore_index=True) # append方法可以同时添加多行,此时要放在列表中
data_dict = bball_16.iloc[0].to_dict()
# keys参数可以给两个DataFrame命名,names参数可以重命名每个索引层
pd.concat(s_list, keys=['2016', '2017'], names=['Year', 'Symbol'])
pres_41_45['President'].value_counts()
DateFrame的基本操作
选取多个列时,参数用中括号[]括起来:
movie[['actor_1_name', 'actor_2_name',]] # 里面那个[]不要少
方法链:
用点记号.表示函数调用顺序的方式,要求为返回值必须为另外一个对象,如下:
person.drive('store').buy('food').drive('home').prepare('food').cook('food').serve('food').eat('food').cleanup('dishes')
DataFrame中操作如下:
actor_1_fb_likes.fillna(0).astype(int).head()
对整个数据帧的操作:
movie.shape
movie.count()
movie.min() # 各列的最小值
movie.isnull().any().any() # 判断整个DataFrame有没有缺失值,方法是连着使用两个any
movie.isnull().sum() # 统计缺失值最主要方法是使用isnull方法
movie.sort_values('UGDS_HISP', ascending=False)# 按照某一列排序
movie.dropna(how='all')# 如果所有列都是缺失值,则将其去除
时间操作
pd.to_datetime能够将整个列表或一系列字符串或整数转换为时间戳。
使用如下:
s = pd.Series(['12-5-2015', '14-1-2013', '20/12/2017', '40/23/2017'])
pd.to_datetime(s, dayfirst=True, errors='coerce')
时间戳操作如下:
pd.Timestamp(year=2012, month=12, day=21, hour=5,minute=10, second=8, microsecond=99)
pd.Timestamp('2016/1/10')
pd.Timestamp('2016-01-05T05:34:43.123456789')
pd.Timestamp(500) # 可以传递整数,表示距离1970-01-01 00:00:00.000000000的毫秒数
pd.to_datetime('2015-5-13') # 类似函数有pd.to_dataframe
to_timedelta()方法可以产生一个Timedelta对象,还可以和Timestamp互相加减,甚至可以相除返回一个浮点数,如下:
# to_timedelta产生Timedelta对象。
pd.Timedelta('12 days 5 hours 3 minutes 123456789 nanoseconds')
time_strings = ['2 days 24 minutes 89.67 seconds', '00:45:23.6']
pd.to_timedelta(time_strings)
# Timedeltas和Timestamps互相加减
pd.Timedelta('12 days 5 hours 3 minutes') * 2
ts = pd.Timestamp('2016-10-1 4:23:23.9')
ts.ceil('h') # Timestamp('2016-10-01 05:00:00')
td.total_seconds()
可以在导入的时候将时间列设为index,然后可以加快速度,时间支持部分匹配:
# REPORTED_DATE设为了行索引,所以就可以进行智能Timestamp对象切分。
crime = crime.set_index('REPORTED_DATE')# .sort_index()
crime.loc['2016-05-12 16:45:00']
# 选取2012-06的数据
crime.loc[:'2012-06']
crime.loc['2016-05-12']
# 也可以选取一整月、一整年或某天的某小时
crime.loc['2016-05'].shape
crime.loc['2016'].shape
crime.loc['2016-05-12 03'].shape
crime.loc['Dec 2015'].sort_index()
# 用at_time方法选取特定时间
crime.at_time('5:47').head()
crime.plot(figsize=(16,4), title='All Denver Crimes')
crime_sort.resample('QS-MAR')['IS_CRIME', 'IS_TRAFFIC'].sum().head()
Pandas中关于时间的概念和比较如下:
| 时间类型 | 标量类 | 数组类 | pandas数据类型 | 基本创建方法 |
|---|---|---|---|---|
| Date times | Timestamp | DatetimeIndex | datetime64[ns] or datetime64[ns, tz] | to_datetime or date_range |
| Time deltas | Timedelta | TimedeltaIndex | timedelta64[ns] | to_timedelta or timedelta_range |
| Time spans | Period | PeriodIndex period[freq] | Period or period_range | |
| Date offsets | DateOffset | None | None | DateOffset |
3.Pandas进行数据分析
读取数据
college = pd.read_csv('college.csv')
employee = pd.read_csv('employee.csv')
college.head()
college.shape
display(college.describe(include=[np.number]).T) # 统计数值列,并进行转置
选择数据子集
直接在序列或数据帧之后加[]即可选择指定的数据集。
.iloc索引器只按整数位置进行选择,其工作方式与Python列表类似,区间为前闭后开;.loc索引器只按索引标签进行选择,这与Python字典的工作方式类似,区间为后闭后开。
它们对行列均可以选择。
使用如下:
college.iloc[:, [4,6]].head( ) # 选取两列的所有的行
college.loc[:, ['WOMENONLY', 'SATVRMID']]
college.iloc[[60, 99, 3]].index.tolist() # .index.tolist()可以直接提取索引标签,生成一个列表
college.iloc[5, -4] # 整数索引
college.loc['The University of Alabama', 'PCTFLOAN'] # 标签索引
college[10:20:2] # 逐行读取
# Series也可以进行同样的切片
city = college['CITY']
city[10:20:2]
数据清洗
stack方法可以将每一行所有的列值转换为行值, unstack方法可以将其还原,如下:
state_fruit = pd.read_csv('state_fruit.csv', index_col=0)
state_fruit.stack() # 再使用reset_index()将结果转换为dataframe;给.columns赋值可以重命名列
# 也可以使用rename_axis给不同的行索引层级命名
state_fruit.stack().rename_axis(['state', 'fruit']).reset_index(name='weight')
用read_csv()方法只选取特定的列,指定uscols参数,如下:
usecol_func = lambda x: 'UGDS_' in x or x == 'INSTNM'
college = pd.read_csv('data/college.csv',usecols=usecol_func)
透视表pivot_table是一个很重要的概念,透视针对的对象是不同的列名,用法如下:
pandas.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False)[source]
其中参数:
index参数接受一个(或多个)不进行透视的列,其唯一值将放在索引中;
columns参数接受一个或多个列,该列将被透视,其唯一值将被生成列名;
values参数接受一个或多个要聚合的列;
aggfunc参数确定如何聚合values参数中的列。
具体可参考https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.pivot_table.html。
拼接方法包括:concat()提供了基于轴的连接灵活性(所有行或所有列);append()是特殊情况的concat()( case(axis=0, join=‘outer’));join()是基于索引(由set_index设置)的,其变量为['left', 'right', 'inner', 'couter'];merge()是基于两个数据帧中的每一个特定列,这些列是像’left_on’、‘right_on’、'on’一样的变量。
布尔索引
布尔索引也叫布尔选择,通过提供布尔值值来选择行,这些布尔值通常存储在一个序列中,不同条件可以进行与或非(&、|、~)操作,但是在Python中,位运算符的优先级高于比较运算符,所以需要加括号。
如下:
criteria1 = movie.imdb_score > 8
criteria2 = movie.content_rating == 'PG-13'
criteria3 = (movie.title_year < 2000) | (movie.title_year >= 2010) # 括号不能少
final=criteria1 & criteria2 & criteria3
college[final] # 作为索引,直接选择值为True的行
employee.BASE_SALARY.between(80000, 120000) # 用between来选择
criteria = ~employee.DEPARTMENT.isin(top_5_depts) # 排除最常出现的5家单位
employee[criteria].head()
条件复杂时,可以采用数据帧的query方法,如下:
df.query('A > B') # 等价于df[df.A > df.B]
# 确定选取的部门和列
depts = ['Houston Police Department-HPD', 'Houston Fire Department (HFD)']
select_columns = ['UNIQUE_ID', 'DEPARTMENT', 'GENDER', 'BASE_SALARY']
qs = "DEPARTMENT in @depts and GENDER == 'Female' and 80000 <= BASE_SALARY <= 120000"
emp_filtered = employee.query(qs)
emp_filtered[select_columns].head()
对DataFrame的行调用msak()方法,使得所有满足条件的数据都消失:
criteria = criteria1 | criteria2
movie.mask(criteria).head()
对不满足条件的值进行替换,使用pandas的where语句。
如下:
s = pd.Series(range(5))
s.where(s > 1, 10)
group_by()的使用
通用数据分析模式:
将数据分解为独立的可管理块,独立地将函数应用于这些块,然后将结果组合在一起,
如下: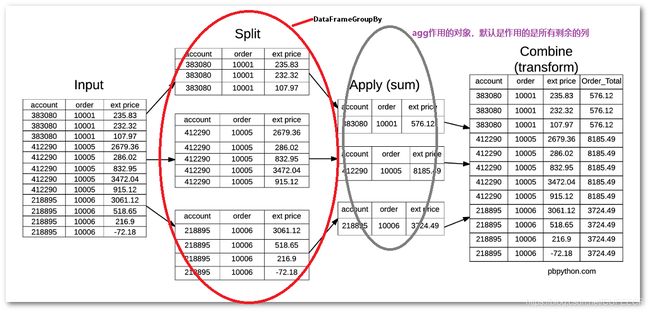
这需要使用到pandas提供的groupby()方法,可以对数据进行分组并调用聚合函数操作。
Pandas中,cut()方法用来把一组数据分割成离散的区间;groupby()用于分组,并且可以对分组进行迭代,还可以使用分组运算方法即聚合函数agg() :针对某列使用agg()时进行不同的统计运算聚合size方法,同时聚合多种方法。
假设有数据:
import pandas as pd
df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar',
'foo', 'bar', 'foo', 'foo'],
'B' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'C' : np.random.randn(8),
'D' : np.random.randn(8)})
df
即: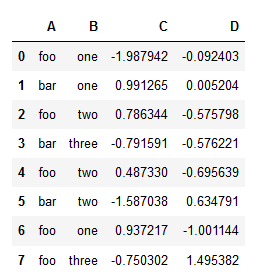
分组迭代:
grouped = df.groupby('A')
for name, group in grouped:
print(name)
print(group)
打印:
bar
A B C D
1 bar one 0.991265 0.005204
3 bar three -0.791591 -0.576221
5 bar two -1.587038 0.634791
foo
A B C D
0 foo one -1.987942 -0.092403
2 foo two 0.786344 -0.575798
4 foo two 0.487330 -0.695639
6 foo one 0.937217 -1.001144
7 foo three -0.750302 1.495382
获取分组:
#获得一个分组get_group
grouped.get_group('bar')
显示: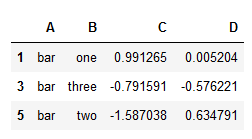
使用聚合函数:
grouped = df.groupby('A')
grouped['C'].agg([np.sum, np.mean, np.std])
显示: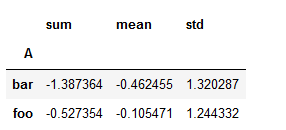
聚合函数统计个数:
df = pd.DataFrame({'Year' : ['2001', '2002', '2001', '2002',
'2001', '2002', '2001', '2002'],
'score' : ['primary', 'second', 'third', 'fourth',
'primary', 'second', 'fourth', 'third'],
'C' : [1,2,1,2,1,2,1,2],
'D' : np.random.randn(8)})
grouped = df.groupby('Year')
print (grouped['C'].agg(np.size))
打印:
Year
2001 4
2002 4
Name: C, dtype: int64
聚合函数中使用多种函数:
grouped = df.groupby('Year')
print (grouped['C'].agg([np.size,np.sum,np.mean]))
打印:
size sum mean
Year
2001 4 4 1
2002 4 8 2
更进一步操作:
score = lambda x: (x - x.mean())
print(df)
print('----------')
print(grouped['C'].agg(np.mean))
print('----------')
print (grouped['C'].transform(score))
打印:
Year score C D
0 2001 primary 1 -0.135237
1 2002 second 2 0.346450
2 2001 third 1 -0.004958
3 2002 fourth 2 2.722841
4 2001 primary 1 0.209729
5 2002 second 2 0.308275
6 2001 fourth 1 0.825608
7 2002 third 2 -0.569078
----------
Year
2001 1
2002 2
Name: C, dtype: int64
----------
0 0
1 0
2 0
3 0
4 0
5 0
6 0
7 0
Name: C, dtype: int64
进一步举例说明如下:
# 按照AIRLINE分组,使用agg方法,传入要聚合的列和聚合函数
flights.groupby('AIRLINE').agg({'ARR_DELAY':'mean'}).head()
# 或者要选取的列使用索引,聚合函数作为字符串传入agg
flights.groupby('AIRLINE')['ARR_DELAY'].agg('mean').head()
flights.groupby('AIRLINE')['ARR_DELAY'].mean().head()
#分组可以是多组,选取可以是多组,聚合函数也可以是多个,此时一一对应
flights.groupby(['AIRLINE', 'WEEKDAY'])['CANCELLED', 'DIVERTED'].agg(['sum',
'mean']).head(7)
#可以对同一列施加不同的函数
group_cols = ['ORG_AIR', 'DEST_AIR']
agg_dict = {'CANCELLED':['sum', 'mean', 'size'],
'AIR_TIME':['mean', 'var']}
flights.groupby(group_cols).agg(agg_dict).head()
#下面这个例子中,max_deviation是自定义的函数
def max_deviation(s):
std_score = (s - s.mean()) / s.std()
return std_score.abs().max()
college.groupby('STABBR')['UGDS'].agg(max_deviation).round(1).head()
grouped = college.groupby(['STABBR', 'RELAFFIL'])
grouped.ngroups# 用ngroups属性查看分组的数量
list(grouped.groups.keys())
需要用到的常见方法和含义如下:
| 方法 | 含义 |
|---|---|
| aggregate() | 为每个组获取一个值 |
| filter() | 获取输入行的子集 |
| transform() | 为每个输入行获取新值 |
| apply() | 对某一列实施复杂操作 |
基本画图
Matplotlib提供了两种方法来作图:
面向过程和面向对象,可以根据需要选择。
Matplotlib常见画图过程如下:
x = [-3, 5, 7]
y = [10, 2, 5]
fig, ax = plt.subplots(figsize=(15,3))
ax.plot(x, y)
ax.set_xlim(0, 10)
ax.set_ylim(-3, 8)
ax.set_xlabel('X axis')
ax.set_ylabel('Y axis')
ax.set_title('Line Plot')
fig.suptitle('Figure Title', size=20, y=1.03)
pandas画图如下:
df = pd.DataFrame(index=['Atiya', 'Abbas', 'Cornelia', 'Stephanie', 'Monte'],data={'Apples':[20, 10, 40, 20, 50],'Oranges':[35, 40, 25, 19, 33]})
color = ['.2', '.7']
df.plot(kind='bar', color=color, figsize=(16,4))
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(16,4))
fig.suptitle('Two Variable Plots', size=20, y=1.02)
df.plot(kind='line', color=color, ax=ax1, title='Line plot')
df.plot(x='Apples', y='Oranges', kind='scatter', ax=ax2, title='Scatterplot')
df.plot(kind='bar', color=color, ax=ax3, title='Bar plot')
如下: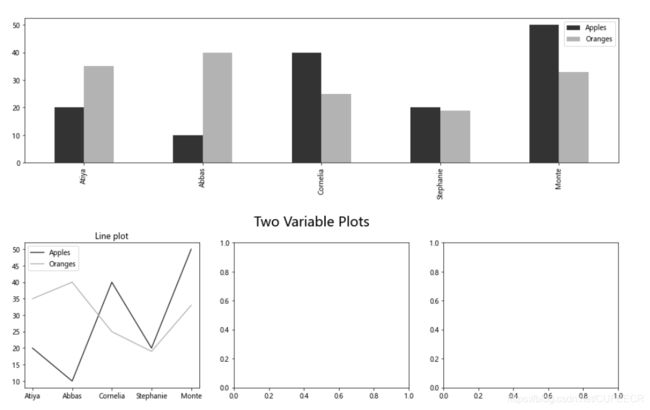
还可以使用seaborn画图,如下:
import seaborn as sns
sns.heatmap(crime_table, cmap='Greys')
二、简单分析College数据
新建college_data目录,下放College.csv如下:
如需获取数据、代码等相关文件进行测试学习,可以直接点击加QQ群
963624318 在群文件夹Python数据分析实战中下载即可。
先读取和预览数据:
import pandas as pd
import numpy as np
from IPython.display import display
pd.options.display.max_columns = 50
college = pd.read_csv('College.csv')
college.head()
显示: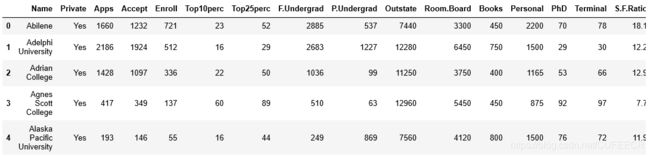
获取所有列名:
columns=college.columns
columns
打印:
Index(['Name', 'Private', 'Apps', 'Accept', 'Enroll', 'Top10perc', 'Top25perc', 'F.Undergrad', 'P.Undergrad', 'Outstate', 'Room.Board', 'Books', 'Personal', 'PhD', 'Terminal', 'S.F.Ratio', 'perc.alumni', 'Expend', 'Grad.Rate'], dtype='object')
选择数据子集:
print(college.iloc[:, [4,6]].head( )) # 选取4、6列的所有行
s1=college.loc[:, ['PhD', 'Books']]
s1.head()
显示: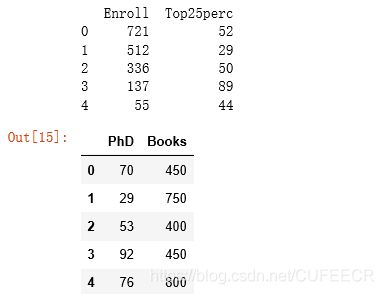
一般在jupyter的一个cell中只默认输出最后一行的变量,要想输出前面行的数据,需要调用print()方法。
设置索引:
index=college.iloc[[60, 99, 3]].index.tolist() # .index.tolist()可以直接提取索引标签,生成一个列表
print(index)
college = college.set_index('Name',drop=False)
index2=college.iloc[[60, 99, 3]].index.tolist()
print(index2)
打印:
[60, 99, 3]
['Bowdoin College', 'Centenary College of Louisiana', 'Agnes Scott College']
显然,在设置索引之前,索引默认为数字索引,在设置索引为Name之后,索引也相应发生变化。
其中,set_index()方法如果不设置drop参数,在将Name设为索引后,就将该列移除了,不能再重复执行这一行代码,否则会报错,设置drop参数为False后,设置Name为索引后也不会移除该列。
根据索引位置获取值如下:
col3 =college.loc['Albion College','Top10perc']
col3
打印:
37
这与数据中的值一致。
逐行读取如下:
s4=college[10:20:2]# 逐行读取,跨行读取
print(s4)
seriesapps = college['Apps']
seriesapps[1:10:2] # Series也可以进行同样的切片
显示: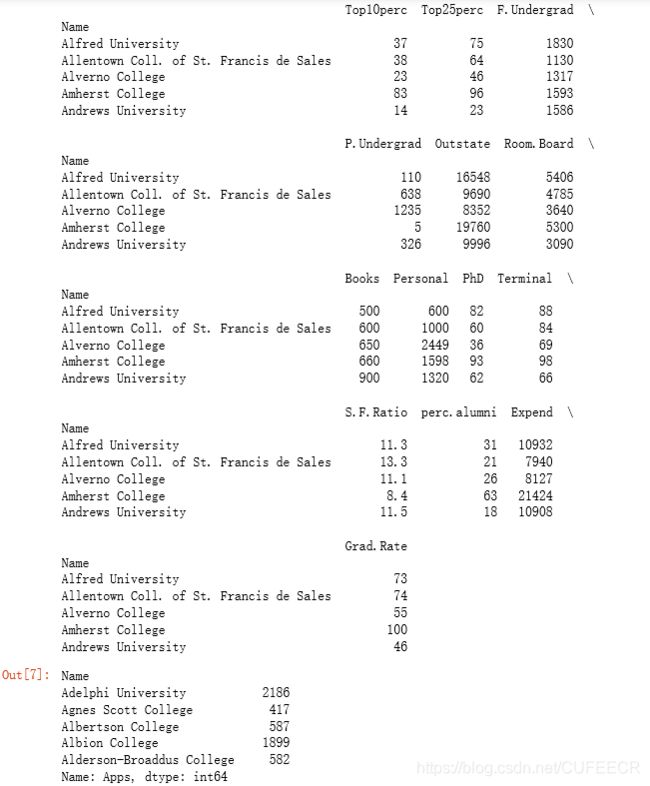
其中,college[10:20:2]是对数据进行逐行读取,从第11行开始到21行,每隔一行读取一行数据。
查看索引如下:
college.index
打印:
Index(['Abilene', 'Adelphi University', 'Adrian College',
'Agnes Scott College', 'Alaska Pacific University', 'Albertson College',
'Albertus Magnus College', 'Albion College', 'Albright College',
'Alderson-Broaddus College',
...
'Winthrop University', 'Wisconsin Lutheran College',
'Wittenberg University', 'Wofford College',
'Worcester Polytechnic Institute', 'Worcester State College',
'Xavier University', 'Xavier University of Louisiana',
'Yale University', 'York College of Pennsylvania'],
dtype='object', name='Name', length=777)
完整操作过程如下:
三、鸢尾花数据集分析
新建iris_data文件夹,存放iris.csv。
鸢尾花Iris数据如下:
如需获取数据、代码等相关文件进行测试学习,可以直接点击加QQ群
1.基础操作
数据的基本操作步骤如下:
(1)读取数据:
import pandas as pd
import numpy as np
iris_data = pd.read_csv("iris.csv",header=0,
names = ["花萼长度", "花萼宽度", "花瓣长度", "花瓣宽度", "类别"],
encoding = 'gbk');
pd.set_option("display.max_rows", 5) # 设置最大显示5行数据
iris_data.head()
显示: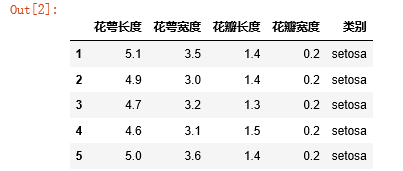
(2)对数据进行切片与删除:
iris_data[:50]
DataFrame = iris_data[:5].copy() # 建立数据副本,以便多次修改
DataFrame.drop(index=[1,3])
显示: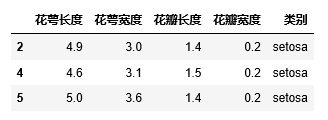
显然,删除了第一行和第三行,这与
DataFrame = iris_data[:5].copy() # 建立数据副本,以便多次修改
DataFrame.drop(columns=["花萼宽度", "花瓣宽度"])
不同,显示: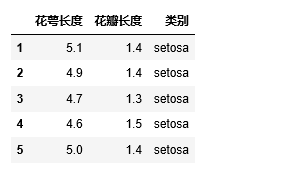
删除的是指定列。
还可以既 删除行、又删除列,如下:
DataFrame = iris_data[:5].copy() # 建立数据副本,以便多次修改
DataFrame.drop(index=[1,3],columns=["花萼宽度", "花瓣宽度"])
显示: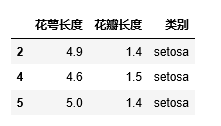
(3)基本赋值
可以通过多种方式赋值,如下:
DataFrame = iris_data[:5].copy() # 建立数据副本,以便多次修改
DataFrame.loc[1, "类别"] = "新类别名" # 修改第0行类别标签列的数据
print(DataFrame)
DataFrame = iris_data[:5].copy() # 建立数据副本,以便多次修改
DataFrame.loc[1] = "新数据" # 修改第1行的数据
print(DataFrame)
DataFrame = iris_data[:5].copy() # 建立数据副本,以便多次修改
DataFrame.loc[:, "花萼长度"] = 10 # 修改第1列的数据
print(DataFrame)
打印:
花萼长度 花萼宽度 花瓣长度 花瓣宽度 类别
1 5.1 3.5 1.4 0.2 新类别名
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
花萼长度 花萼宽度 花瓣长度 花瓣宽度 类别
1 新数据 新数据 新数据 新数据 新数据
2 4.9 3 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5 3.6 1.4 0.2 setosa
花萼长度 花萼宽度 花瓣长度 花瓣宽度 类别
1 10 3.5 1.4 0.2 setosa
2 10 3.0 1.4 0.2 setosa
3 10 3.2 1.3 0.2 setosa
4 10 3.1 1.5 0.2 setosa
5 10 3.6 1.4 0.2 setosa
(4)索引检索
index检索iloc[]是左闭右开,如DataFrame.iloc[1:3, 1]选择第一二行的第一列,如下:
print(DataFrame.iloc[-1]) # 最后一行
print(DataFrame.iloc[1:3, 1]) # 第一二行的第1列
print('----')
print(DataFrame.iloc[1:3, 1:3])
print(DataFrame.iloc[:3, :3]) # 前三行的前三列
print(DataFrame.iloc[[0,1,3], 1]) # 第0,1,3行的第1列
print(DataFrame.iloc[[True, False, True, False, False]]) # 第0,2行
打印:
花萼长度 10
花萼宽度 3.6
花瓣长度 1.4
花瓣宽度 0.2
类别 setosa
Name: 5, dtype: object
2 3.0
3 3.2
Name: 花萼宽度, dtype: float64
----
花萼宽度 花瓣长度
2 3.0 1.4
3 3.2 1.3
花萼长度 花萼宽度 花瓣长度
1 10 3.5 1.4
2 10 3.0 1.4
3 10 3.2 1.3
1 3.5
2 3.0
4 3.1
Name: 花萼宽度, dtype: float64
花萼长度 花萼宽度 花瓣长度 花瓣宽度 类别
1 10 3.5 1.4 0.2 setosa
3 10 3.2 1.3 0.2 setosa
可以看到,iloc[]的使用很灵活。
还可以用label检索,使用loc[]方法,是左闭右闭,如下:
# DataFrame.loc[-1] # 语法错误!!!
print(DataFrame.loc[1]) # 第0行
print(DataFrame.loc[:, "花萼长度"]) # 所有行的“花萼长度”列
print(DataFrame.loc[[1,3], "类别"]) # 第0,1,3行的“类别”列
print(DataFrame.loc[[True, False, True, False, False]]) # 第0,2行
打印:
花萼长度 10
花萼宽度 3.5
花瓣长度 1.4
花瓣宽度 0.2
类别 setosa
Name: 1, dtype: object
1 10
2 10
3 10
4 10
5 10
Name: 花萼长度, dtype: int64
1 setosa
3 setosa
Name: 类别, dtype: object
花萼长度 花萼宽度 花瓣长度 花瓣宽度 类别
1 10 3.5 1.4 0.2 setosa
3 10 3.2 1.3 0.2 setosa
注意:loc[]方法使用数字索引时不能从0开始,因为一般自带的索引是从1到length,而不是0到length-1,需与前者保持一致,并且也不能使用-1索引,可以使用length。
(5)条件检索
比较条件检索如下:
DataFrame["花萼长度"] = pd.to_numeric(DataFrame["花萼长度"], errors='coerce')
s1=DataFrame.loc[DataFrame["花萼长度"]>4]
print(s1)
s2=DataFrame.loc[(DataFrame["花萼长度"]>=5.0) & (DataFrame["花瓣长度"]>=1.4)]
s2
显示: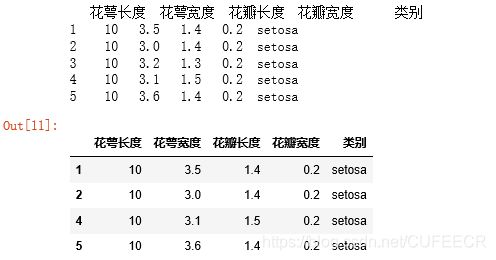
判断为空和不为空用isnull()和notnull(),如下:
df = iris_data.loc[iris_data["花萼长度"].isnull()]
print(df[:4])
df = iris_data.loc[iris_data["类别"].notnull()]
print(df[:5])
打印:
Empty DataFrame
Columns: [花萼长度, 花萼宽度, 花瓣长度, 花瓣宽度, 类别]
Index: []
花萼长度 花萼宽度 花瓣长度 花瓣宽度 类别
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
判断值是否在某个集合用isin(),如下:
df = iris_data.loc[iris_data["花萼长度"].isin([5.0, 4.7])]
df[:5]
显示: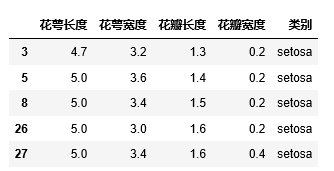
(6)条件统计
如下:
print(iris_data.loc[iris_data["类别"] == "versicolor"].count())
c1 = sum(iris_data["类别"] == "setosa")
c2 = sum(iris_data["类别"] == "versicolor")
c3 = sum(iris_data["类别"] == "virginica")
print(c1, c2, c3) # 手动统计各类样本数量
iris_data["类别"].value_counts()
打印:
花萼长度 50
花萼宽度 50
花瓣长度 50
花瓣宽度 50
类别 50
dtype: int64
50 0 0
virginica 50
versicolor 50
setosa 50
Name: 类别, dtype: int64
(7)条件赋值
对某一列数据复制如下:
DataFrame = iris_data[:5].copy() # 建立数据副本,以便多次修改
DataFrame.loc[DataFrame["花萼长度"]>4.8, "类别"] = "大花萼"
DataFrame
打印:
花萼长度 花萼宽度 花瓣长度 花瓣宽度 类别
1 5.1 3.5 1.4 0.2 大花萼
2 4.9 3.0 1.4 0.2 大花萼
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 大花萼
对所有列数据进行赋值如下:
DataFrame = iris_data[:5].copy() # 建立数据副本,以便多次修改
DataFrame.loc[DataFrame["花萼长度"]>4.8] = "错误数据"
DataFrame
打印:
花萼长度 花萼宽度 花瓣长度 花瓣宽度 类别
1 错误数据 错误数据 错误数据 错误数据 错误数据
2 错误数据 错误数据 错误数据 错误数据 错误数据
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 错误数据 错误数据 错误数据 错误数据 错误数据
(8)缺失值处理
判断缺失值:
print(iris_data.isnull())
print(iris_data.isnull().sum())
打印:
花萼长度 花萼宽度 花瓣长度 花瓣宽度 类别
1 False False False False False
2 False False False False False
.. ... ... ... ... ...
149 False False False False False
150 False False False False False
[150 rows x 5 columns]
花萼长度 0
花萼宽度 0
花瓣长度 0
花瓣宽度 0
类别 0
dtype: int64
指定单一值填充缺失值:
iris_data.fillna('Unknown')
iris_data["花萼长度"].fillna('Unknown')
打印:
1 5.1
2 4.9
...
149 6.2
150 5.9
Name: 花萼长度, Length: 150, dtype: float64
根据列指定不同的值填充缺失值:
mean = iris_data['花萼宽度'].mean() # 平均数
median = iris_data['花瓣长度'].median() # 中位数
mode = iris_data['花萼宽度'].mode() # 众数
values = {'花萼长度': 0, '花萼宽度': mean, '花瓣长度': 2, '花萼宽度': mode}
iris_data.fillna(value=values)
打印:
花萼长度 花萼宽度 花瓣长度 花瓣宽度 类别
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
... ... ... ... ... ...
149 6.2 3.4 5.4 2.3 virginica
150 5.9 3.0 5.1 1.8 virginica
150 rows × 5 columns
移除缺失值如下:
iris_data.dropna() # 去掉含缺失项的行
iris_data.dropna(axis='columns') # 去掉含缺失项的列
iris_data.dropna(how='all') # 去掉所有项均缺失的行
iris_data.dropna(thresh=2) # 去掉多于2个缺失项的行
打印:
花萼长度 花萼宽度 花瓣长度 花瓣宽度 类别
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
... ... ... ... ... ...
149 6.2 3.4 5.4 2.3 virginica
150 5.9 3.0 5.1 1.8 virginica
150 rows × 5 columns
替换值:
df = iris_data.replace(5.0, 50) # 默认为深复制,保护原数据
df['花萼宽度'] = df['花萼宽度'].replace(3.5, 30.5)
df = df.replace([0, 1, 2, 3], 4)
df = df.replace([0, 1, 2, 3], [4, 3, 2, 1])
df = df.replace({'花萼长度':5.1, '花瓣长度':5.1}, 5)
df = df.replace({'花瓣长度' : {5.1:5.0, 6.2:6.0}})
df.head()
打印:
花萼长度 花萼宽度 花瓣长度 花瓣宽度 类别
1 5.0 30.5 1.4 0.2 setosa
2 4.9 4.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 50.0 3.6 1.4 0.2 setosa
2.数据分析
描述统计如下:
iris_data["类别"].describe()
打印:
count 150
unique 3
top virginica
freq 50
Name: 类别, dtype: object
打印:
count 150
unique 3
top virginica
freq 50
Name: 类别, dtype: object
计数:
print(iris_data["类别"].count())
打印:
150
求所有列的最大值和指定列的最大值:
print(iris_data.max())
print(iris_data["花萼长度"].max())
打印:
花萼长度 7.9
花萼宽度 4.4
花瓣长度 6.9
花瓣宽度 2.5
类别 virginica
dtype: object
7.9
求所有列的最小值和指定列的最小值:
print(iris_data.min())
print(iris_data["花萼长度"].min())
打印:
花萼长度 4.3
花萼宽度 2
花瓣长度 1
花瓣宽度 0.1
类别 setosa
dtype: object
4.3
求所有列的平均值和指定列的平均值:
print(iris_data.mean())
print(iris_data["花萼长度"].mean())
打印:
花萼长度 5.843333
花萼宽度 3.057333
花瓣长度 3.758000
花瓣宽度 1.199333
dtype: float64
5.843333333333335
求所有列的中位数和指定列的中位数:
print(iris_data.median())
print(iris_data["花萼长度"].median())
打印:
花萼长度 5.80
花萼宽度 3.00
花瓣长度 4.35
花瓣宽度 1.30
dtype: float64
5.8
列出某一列的所有不同值:
iris_data["类别"].unique() # 列出所有不同的取值
打印:
array(['setosa', 'versicolor', 'virginica'], dtype=object)
对值进行升序排列:
np.sort(iris_data["花萼长度"].unique()) # 默认升序排列
打印:
array([4.3, 4.4, 4.5, 4.6, 4.7, 4.8, 4.9, 5. , 5.1, 5.2, 5.3, 5.4, 5.5,
5.6, 5.7, 5.8, 5.9, 6. , 6.1, 6.2, 6.3, 6.4, 6.5, 6.6, 6.7, 6.8,
6.9, 7. , 7.1, 7.2, 7.3, 7.4, 7.6, 7.7, 7.9])
聚合函数,对不同数据进行多维度统计:
iris0=iris_data.agg(['max', 'min', 'mean', 'median']) # agg聚合操作,可运行多个函数
iris0
打印:
花萼长度 花萼宽度 花瓣长度 花瓣宽度 类别
max 7.900000 4.400000 6.900 2.500000 virginica
min 4.300000 2.000000 1.000 0.100000 setosa
mean 5.843333 3.057333 3.758 1.199333 NaN
median 5.800000 3.000000 4.350 1.300000 NaN
对某一列进行聚合函数操作:
iris1=iris_data["花萼长度"].agg(['max', 'min', 'mean', 'median'])
iris1
打印:
max 7.900000
min 4.300000
mean 5.843333
median 5.800000
Name: 花萼长度, dtype: float64
对某一列进行分组并计数:
iris2=iris_data.groupby(['花萼长度'])['花萼长度'].count() # 分组,花萼长度由小到大排列
iris2
打印:
花萼长度
4.3 1
4.4 3
..
7.7 4
7.9 1
Name: 花萼长度, Length: 35, dtype: int64
对分组后的数据进行聚合函数操作:
iris_data_review = iris_data.groupby(['花萼长度'])['花瓣宽度'].agg(['min', 'max']) # 分组
iris_data_review
打印:
min max
花萼长度
4.3 0.1 0.1
4.4 0.2 0.2
... ... ...
7.7 2.0 2.3
7.9 2.0 2.0
35 rows × 2 columns
最后保存数据:
iris_data.to_csv("newdata.csv", na_rep="NA", index = False, encoding='gbk')
iris_data = pd.read_csv("newdata.csv", encoding = "gbk");
iris_data.head()
打印:
花萼长度 花萼宽度 花瓣长度 花瓣宽度 类别
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa
完整过程如下:
四、电影评分数据分析
对电影数据的分析主要包括以下方面:
- 平均分较高的电影
- 不同性别对电影平均评分
- 男女观众区别最大电影
- 评分次数最多热门的电影
- 不同年龄段区别最大的电影
新建movie_data目录用于保存电影相关数据。
电影评分数据主要包括3组数据:
users.dat用户数据如下: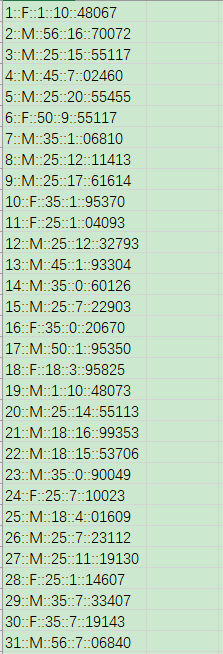
movies.dat电影数据如下: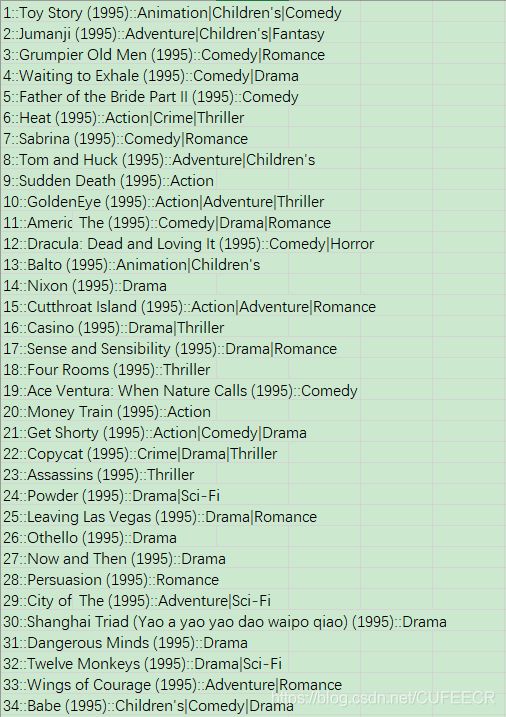
ratings.dat评分数据如下: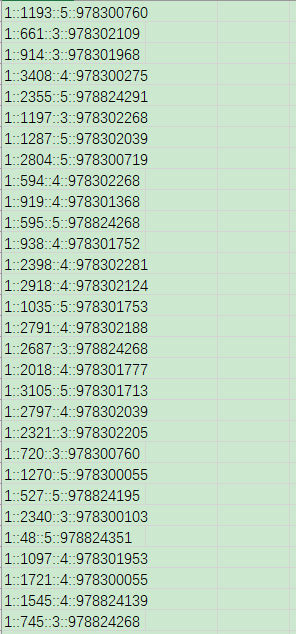
可以看到,三组数据的每一行都类似1::F::1::10::48067,需要通过双冒号分隔成不同的数据列。
基本操作步骤如下:
(1)导包和数据
先导入所需要的库,如下:
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
# 画图
import matplotlib.pyplot as plt
%matplotlib inline
再导入用户数据:
# 读取user用户
# UserID::Gender::Age::Occupation::Zip-code
labels = ['UserId','Gender','Age','Occupation','zip-code']
users = pd.read_csv('users.dat',sep = '::',header = None,names = labels, engine='python')
index = users.index
data = users.values
display(users.shape,index,data)
打印:
(6040, 5)
RangeIndex(start=0, stop=6040, step=1)
array([[1, 'F', 1, 10, '48067'],
[2, 'M', 56, 16, '70072'],
[3, 'M', 25, 15, '55117'],
...,
[6038, 'F', 56, 1, '14706'],
[6039, 'F', 45, 0, '01060'],
[6040, 'M', 25, 6, '11106']], dtype=object)
易知,有6040条数据,每条数据5个属性值。
查看用户数据:
users.head()
打印:
UserId Gender Age Occupation zip-code
0 1 F 1 10 48067
1 2 M 56 16 70072
2 3 M 25 15 55117
3 4 M 45 7 02460
4 5 M 25 20 55455
读取电影数据如下:
# movie
# MovieID::Title::Genres
labels = ['MovieId','Title','Genres']
movie = pd.read_csv('movies.dat',sep = '::',header = None,names = labels, engine='python')
display(movie.head(),movie.shape)
打印:
MovieId Title Genres
0 1 Toy Story (1995) Animation|Children's|Comedy
1 2 Jumanji (1995) Adventure|Children's|Fantasy
2 3 Grumpier Old Men (1995) Comedy|Romance
3 4 Waiting to Exhale (1995) Comedy|Drama
4 5 Father of the Bride Part II (1995) Comedy
(3883, 3)
电影数据共有3883条,每条3个属性;display()函数可以用户同时展示多个数据。
读取评分数据如下:
# 评分
# UserID::MovieID::Rating::Timestamp
labels = ['UserId','MovieId','Rating','Time']
ratings = pd.read_csv('./ratings.dat',sep = '::',header = None,names = labels, engine='python')
display(ratings.head(),ratings.shape)
打印:
UserId MovieId Rating Time
0 1 1193 5 978300760
1 1 661 3 978302109
2 1 914 3 978301968
3 1 3408 4 978300275
4 1 2355 5 978824291
(1000209, 4)
电影数据共有1000209条,每条3个属性;
因为数据量较大,因此执行稍有延迟。
(2)数据合并
需要将三张表进行合并。
先查看三张表:
#三个表
display(users.head(),movie.head(),ratings.head())
显示: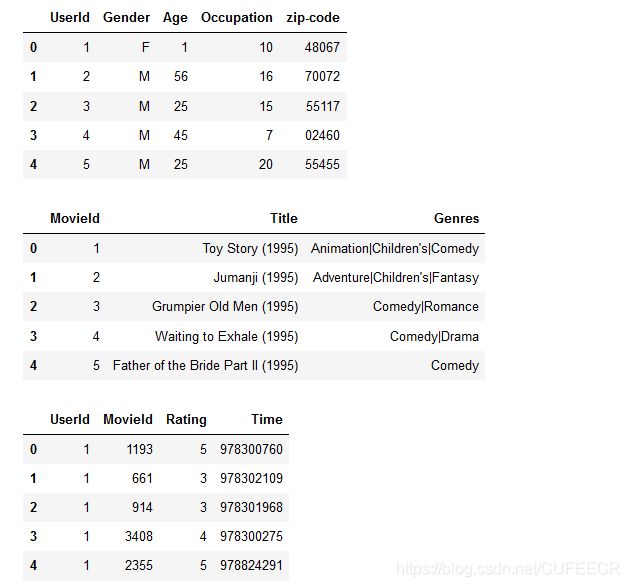
先合并电影表和评分表:
df1 = pd.merge(left = movie,right=ratings)
df1.head()
显示: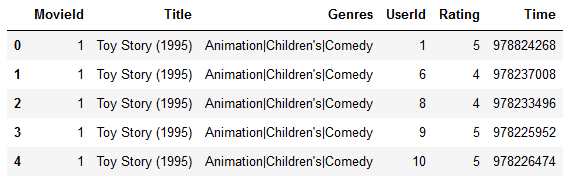
电影表和评分表之所以可以合并,是因为这两张表中都有MovieId属性,可以作为两张表的关联属性,类似于SQL数据库中将两张表进行关联时需要外键。
同理,将df1与用户表进行合并:
movie_data = pd.merge(df1,users)
movie_data.head()
显示:
同样,df1可以和users表合并,是因为这两张表都有UserId作为关联属性。
(3)查看数据
查看movie_data表的规模:
movie_data.shape
打印:
(1000209, 10)
显然,合并后的表有3个属性。
查看Age属性的唯一值:
movie_data['Age'].unique()
打印:
array([ 1, 50, 25, 35, 18, 45, 56], dtype=int64)
可以看到,共有7个唯一的值。
查看Title唯一值的个数:
movie_data['Title'].unique().size # 查看有多少部电影
打印:
3706
即有3706部电影。
(4)获取平均分较高的电影
先求出每部电影的平均评分如下:
#以title 作为index 对数据进行划分
movie_rate_pingjun = pd.pivot_table(movie_data,values=['Rating'],index = ['Title'],aggfunc='mean')
movie_rate_pingjun.shape
打印:
(3706, 1)
可以看到,是调用Pandas的pivot_table()透视表方法、并传递平均值作为聚合函数求出每部电影的平均评分的。
查看平均评分情况:
movie_rate_pingjun.head()
显示: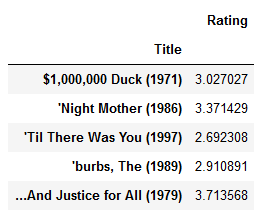
对平均评分进行降序排列:
movie_rate_pingjun.sort_values(by = 'Rating',ascending=False,inplace=False)
显示: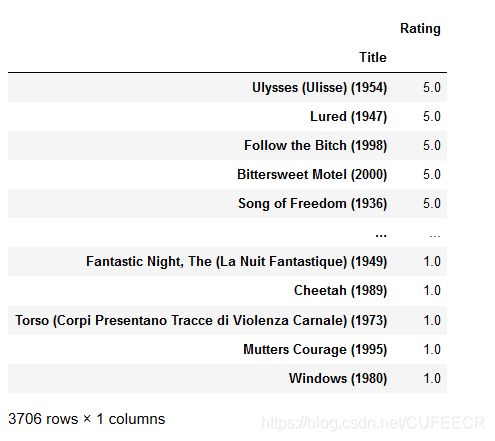
获取movie_data表中前20和后20条数据如下:
display(movie_rate_pingjun[:20],movie_rate_pingjun[-20:])
显示:
(5)不同性别对电影的平均评分
现根据电影名和性别计算平均评分如下:
# 透视表,透视数据结构 ,两个index
movie_gender_rating_pingjun = pd.pivot_table(movie_data,values=['Rating'],index=['Title','Gender'],aggfunc='mean')
movie_rate_pingjun.shape
打印:
(3706, 1)
查看平均评分结果如下:
movie_gender_rating_pingjun.head() # dataframe
显示: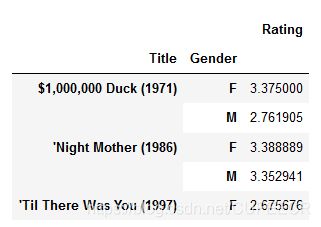
可以看到,相当于是进行了两次分组,先对电影名进行分组,在电影名相同的情况下再对姓名进行分组,并计算出相应的平均评分。
下面两种形式又有所不同:
#去掉中括号 ,
movie_gender_rating_pingjun0 = pd.pivot_table(movie_data,values=['Rating'],index=['Title'],columns=['Gender'],aggfunc='mean')
movie_gender_rating_pingjun = pd.pivot_table(movie_data,values='Rating',index=['Title'],columns=['Gender'],aggfunc='mean')
display(movie_gender_rating_pingjun0.shape, movie_gender_rating_pingjun0.head(),movie_gender_rating_pingjun.shape,movie_gender_rating_pingjun.head())
显示:![movie data merge average gender []](http://img.e-com-net.com/image/info8/ac146f7b531647d5b23de24f7128c095.jpg)
显然,表格表现上有所区别。
(6)不同性别区别最大电影的排序
先查看movie_gender_rating_pingjun表的列:
movie_gender_rating_pingjun.columns
打印:
Index(['F', 'M'], dtype='object', name='Gender')
再增加一列数据为男女平均评分的差值:
# 女性用户和男性用户对定影评分差异 ,给数据集增加一列
movie_gender_rating_pingjun['diff'] = movie_gender_rating_pingjun.F - movie_gender_rating_pingjun.M
movie_gender_rating_pingjun.head()
显示: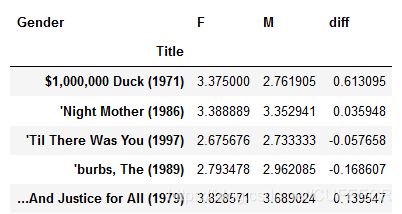
再对评分差异排序:
# 排序sort_values,是pandas常用的方法
movie_gender_rating_pingjun.sort_values(by = 'diff',ascending=False,inplace=True)
movie_gender_rating_pingjun.head()
显示: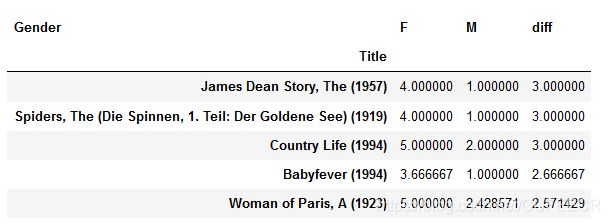
可以看到,性别差异最大的5部电影。
因为越排在前面,表示女性比男性越多,可以表示女性越喜欢、男性越不喜欢,查看前10如下:
# 女性用户和男性用户差异最大,女性用最喜欢 ,前10名
female = movie_gender_rating_pingjun[:10]
female
显示: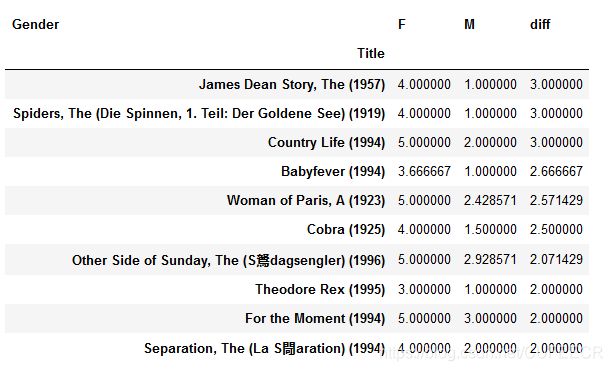
同样,排在越靠后,表示男性越喜欢、女性越不喜欢,排名前10如下:
#男性用户最喜欢的 ,去除女性用户评分空数据
print(movie_gender_rating_pingjun[-10:]) #有空值
male = movie_gender_rating_pingjun.dropna()[-10:]
male
显示: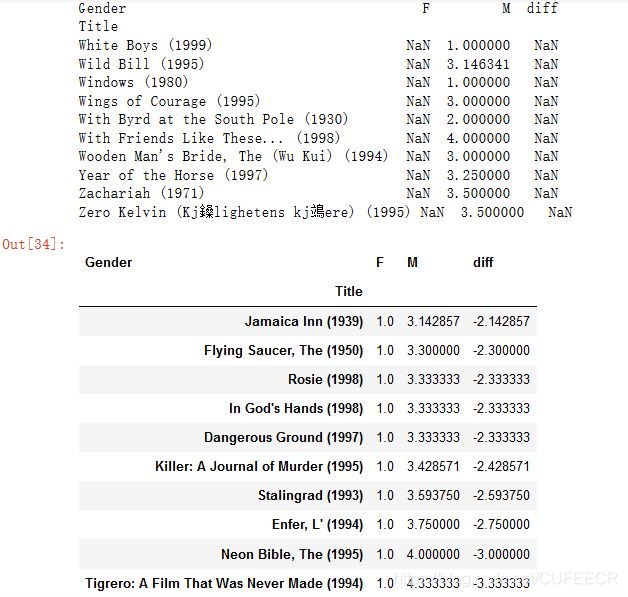
再连接女性最喜欢的前10和男性最喜欢的前10:
diff = pd.concat([female,male]) # 连接两个数据集
diff
显示: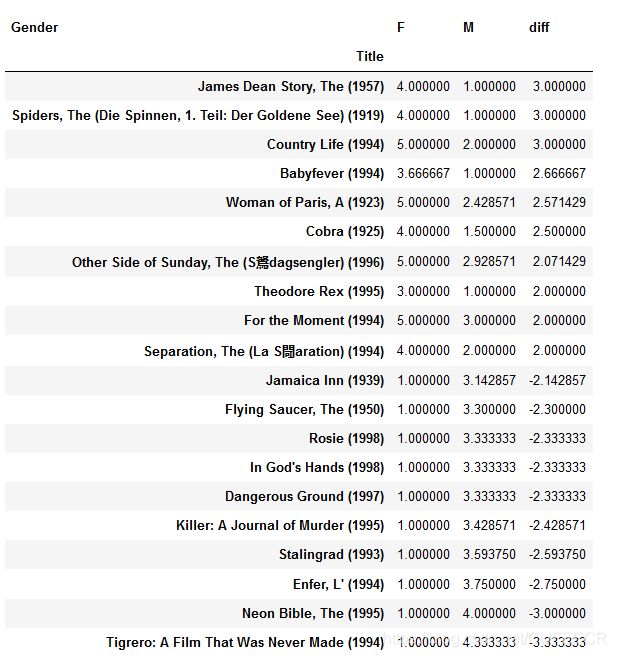
再对连接后的数据画图:
# 分析结果数据可视化,barh水平的柱状图 x 横坐标,标题, y 纵坐标
diff.plot(y = 'diff' ,kind = 'barh',figsize=(12,9),color= 'green')
显示: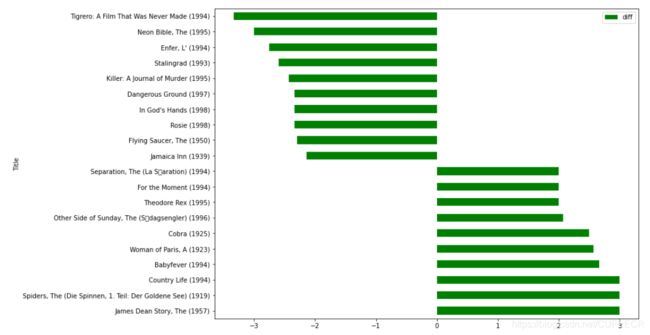
可以直观地将男性和女性最喜欢的电影展示出来。
(7)获取评分次数最多热门的电影
先查看movie_data.shape的数据概况:
movie_data.shape
打印:
(1000209, 10)
根据电影标题对数据分组:
# pandas分组运算
rating_count = movie_data.groupby(['Title']).size()
rating_count.sort_values(ascending=False)[:50]
打印:
Title
American Beauty (1999) 3428
Star Wars: Episode IV - A New Hope (1977) 2991
Star Wars: Episode V - The Empire Strikes Back (1980) 2990
Star Wars: Episode VI - Return of the Jedi (1983) 2883
Jurassic Park (1993) 2672
Saving Private Ryan (1998) 2653
Terminator 2: Judgment Day (1991) 2649
Matrix, The (1999) 2590
Back to the Future (1985) 2583
Silence of the Lambs, The (1991) 2578
Men in Black (1997) 2538
Raiders of the Lost Ark (1981) 2514
Fargo (1996) 2513
Sixth Sense, The (1999) 2459
Braveheart (1995) 2443
Shakespeare in Love (1998) 2369
Princess Bride, The (1987) 2318
Schindler's List (1993) 2304
L.A. Confidential (1997) 2288
Groundhog Day (1993) 2278
E.T. the Extra-Terrestrial (1982) 2269
Star Wars: Episode I - The Phantom Menace (1999) 2250
Being John Malkovich (1999) 2241
Shawshank Redemption, The (1994) 2227
Godfather, The (1972) 2223
Forrest Gump (1994) 2194
Ghostbusters (1984) 2181
Pulp Fiction (1994) 2171
Terminator, The (1984) 2098
Toy Story (1995) 2077
Alien (1979) 2024
Total Recall (1990) 1996
Fugitive, The (1993) 1995
Gladiator (2000) 1924
Aliens (1986) 1820
Blade Runner (1982) 1800
Who Framed Roger Rabbit? (1988) 1799
Stand by Me (1986) 1785
Usual Suspects, The (1995) 1783
Babe (1995) 1751
Airplane! (1980) 1731
Independence Day (ID4) (1996) 1730
Galaxy Quest (1999) 1728
One Flew Over the Cuckoo's Nest (1975) 1725
Wizard of Oz, The (1939) 1718
2001: A Space Odyssey (1968) 1716
Abyss, The (1989) 1715
Bug's Life, A (1998) 1703
Jaws (1975) 1697
Godfather: Part II, The (1974) 1692
dtype: int64
可以获取到每部电影被评论的次数。
(8)查看不同年龄段差别最大的电影
先查看用户的年龄分布:
movie_data['Age'].plot(kind = 'hist',bins = 30) #横坐标年龄段
- 1
显示: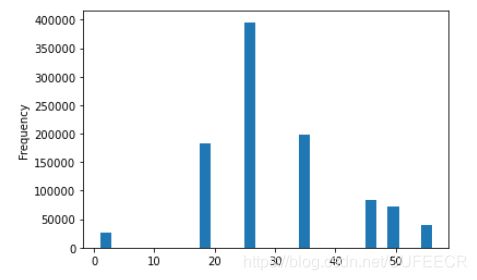
再获取最大年龄:
movie_data.Age.max() # 最大年龄
打印:
56
再用pandas.cut函数将用户年龄分组:
labels = ['0-9','10-19','20-29','30-39','40-49','50-59']
movie_data['Age_range'] = pd.cut(movie_data.Age,bins = range(0,61,10),labels=labels)
movie_data.head()
显示: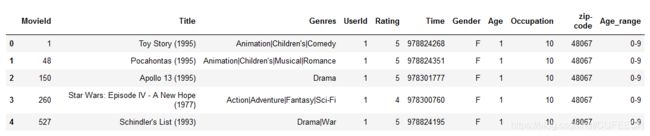
可以看到多了一个字段年龄段。
此时再查看不同年龄段各数据的均值:
movie_data.groupby('Age_range').mean()
显示: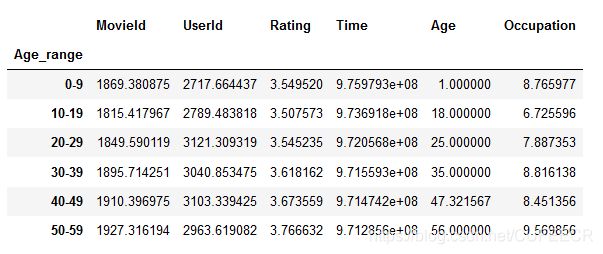
查看各年龄段的人数和评分均值:
movie_data.groupby('Age_range').agg({'Rating':[np.size,np.mean]})
显示: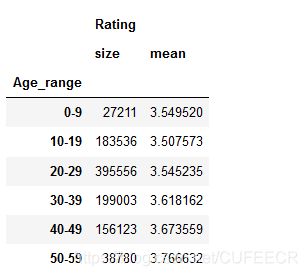
(9)加入评分次数限制的分析不同性别对电影的平均评分
查看平均评分前10的电影:
#看平均分的前10个数据,发现很大都不知道的电影。
movie_rate_pingjun[:10]
显示: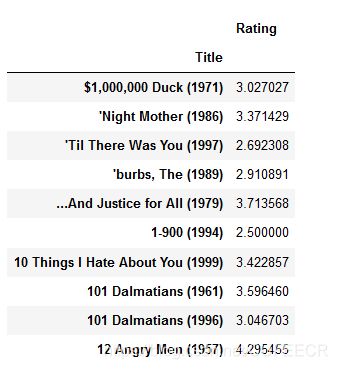
可以看到,很多电影年代久远、不出名还评分比较高,可能存在人为因素,比如评分人数很少、但是评分较高(可能由内部人员评分等),因此产生了噪声、导致结果不准确,因此需要加上评分次数的限制。
查看性别与平均评分如下:
display(movie_gender_rating_pingjun.index, movie_gender_rating_pingjun.head())
- 1
显示: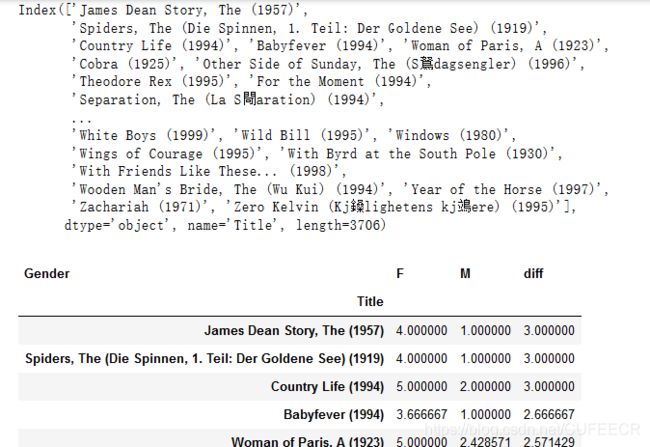
在对电影评分数进行排名,获取前100:
movie_data.groupby('Title').size().sort_values()[::-1][:100]
打印:
Title
American Beauty (1999) 3428
Star Wars: Episode IV - A New Hope (1977) 2991
Star Wars: Episode V - The Empire Strikes Back (1980) 2990
Star Wars: Episode VI - Return of the Jedi (1983) 2883
Jurassic Park (1993) 2672
...
Christmas Story, A (1983) 1352
Aladdin (1992) 1351
Romancing the Stone (1984) 1345
Blues Brothers, The (1980) 1341
Rock, The (1996) 1340
Length: 100, dtype: int64
获取评分次数前100的电影名单:
#对观影次数做排序,获取索引
top_movie_title = movie_data.groupby('Title').size().sort_values()[::-1][:100].index
top_movie_title
打印:
Index(['American Beauty (1999)', 'Star Wars: Episode IV - A New Hope (1977)',
'Star Wars: Episode V - The Empire Strikes Back (1980)',
'Star Wars: Episode VI - Return of the Jedi (1983)',
'Jurassic Park (1993)', 'Saving Private Ryan (1998)',
'Terminator 2: Judgment Day (1991)', 'Matrix, The (1999)',
'Back to the Future (1985)', 'Silence of the Lambs, The (1991)',
'Men in Black (1997)', 'Raiders of the Lost Ark (1981)', 'Fargo (1996)',
'Sixth Sense, The (1999)', 'Braveheart (1995)',
'Shakespeare in Love (1998)', 'Princess Bride, The (1987)',
'Schindler's List (1993)', 'L.A. Confidential (1997)',
'Groundhog Day (1993)', 'E.T. the Extra-Terrestrial (1982)',
'Star Wars: Episode I - The Phantom Menace (1999)',
'Being John Malkovich (1999)', 'Shawshank Redemption, The (1994)',
'Godfather, The (1972)', 'Forrest Gump (1994)', 'Ghostbusters (1984)',
'Pulp Fiction (1994)', 'Terminator, The (1984)', 'Toy Story (1995)',
'Alien (1979)', 'Total Recall (1990)', 'Fugitive, The (1993)',
'Gladiator (2000)', 'Aliens (1986)', 'Blade Runner (1982)',
'Who Framed Roger Rabbit? (1988)', 'Stand by Me (1986)',
'Usual Suspects, The (1995)', 'Babe (1995)', 'Airplane! (1980)',
'Independence Day (ID4) (1996)', 'Galaxy Quest (1999)',
'One Flew Over the Cuckoo's Nest (1975)', 'Wizard of Oz, The (1939)',
'2001: A Space Odyssey (1968)', 'Abyss, The (1989)',
'Bug's Life, A (1998)', 'Jaws (1975)', 'Godfather: Part II, The (1974)',
'Casablanca (1942)', 'Die Hard (1988)', 'GoodFellas (1990)',
'Hunt for Red October, The (1990)', 'Speed (1994)',
'Indiana Jones and the Last Crusade (1989)', 'Lethal Weapon (1987)',
'Monty Python and the Holy Grail (1974)', 'Toy Story 2 (1999)',
'When Harry Met Sally... (1989)', 'Good Will Hunting (1997)',
'Titanic (1997)', 'Breakfast Club, The (1985)',
'Mission: Impossible (1996)', 'Election (1999)', 'X-Men (2000)',
'Twelve Monkeys (1995)', 'Beetlejuice (1988)', 'Big (1988)',
'Ferris Bueller's Day Off (1986)', 'Edward Scissorhands (1990)',
'Close Encounters of the Third Kind (1977)', 'Fight Club (1999)',
'Dances with Wolves (1990)', 'Star Trek: The Wrath of Khan (1982)',
'Raising Arizona (1987)',
'Austin Powers: The Spy Who Shagged Me (1999)', 'Batman (1989)',
'As Good As It Gets (1997)', 'Face/Off (1997)',
'Butch Cassidy and the Sundance Kid (1969)', 'Thelma & Louise (1991)',
'Clerks (1994)', 'True Lies (1994)', 'American Pie (1999)',
'Contact (1997)', 'Amadeus (1984)', 'Fifth Element, The (1997)',
'High Fidelity (2000)', 'There's Something About Mary (1998)',
'Dr. Strangelove or: How I Learned to Stop Worrying and Love the Bomb (1963)',
'Arachnophobia (1990)', 'Clueless (1995)', 'Get Shorty (1995)',
'Jerry Maguire (1996)', 'Christmas Story, A (1983)', 'Aladdin (1992)',
'Romancing the Stone (1984)', 'Blues Brothers, The (1980)',
'Rock, The (1996)'],
dtype='object', name='Title')
判断每一部电影是否在评分次数前100的名单中:
flag = movie_gender_rating_pingjun.index.isin(top_movie_title)
flag
打印:
array([False, False, False, ..., False, False, False])
根据男女之间的差别对列表中的电影排序(升序):
df1 = movie_gender_rating_pingjun[flag].sort_values(by = 'diff') # 比较好的电影男女都喜欢
df1
显示: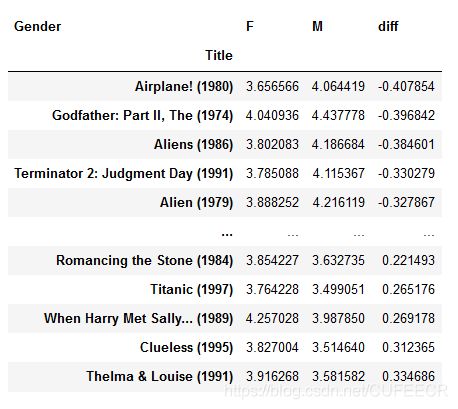
画图:
df1.plot(kind = 'barh',figsize=(12,9))
显示: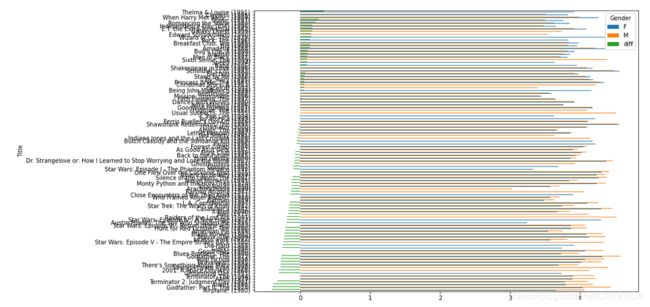
显然,很直观。
(10)加入评分次数限制但不区分性别的分析平均分高的电影
前面是包括了性别区别在内的电影评分数据,这里不加入性别因素来考虑。
先获取到电影平均评分数据:
movie_rating_mean = pd.pivot_table(movie_data,values='Rating',index=['Title'])
movie_rating_mean
显示:
获取评分次数前100的电影:
#::-1 对数据做切片,倒序 最受欢迎的电影 获取index
top_movie_title2 = movie_data.groupby('Title').size().sort_values()[::-1][:100].index
top_movie_title2
打印:
Index(['American Beauty (1999)', 'Star Wars: Episode IV - A New Hope (1977)',
'Star Wars: Episode V - The Empire Strikes Back (1980)',
'Star Wars: Episode VI - Return of the Jedi (1983)',
'Jurassic Park (1993)', 'Saving Private Ryan (1998)',
'Terminator 2: Judgment Day (1991)', 'Matrix, The (1999)',
'Back to the Future (1985)', 'Silence of the Lambs, The (1991)',
'Men in Black (1997)', 'Raiders of the Lost Ark (1981)', 'Fargo (1996)',
'Sixth Sense, The (1999)', 'Braveheart (1995)',
'Shakespeare in Love (1998)', 'Princess Bride, The (1987)',
'Schindler's List (1993)', 'L.A. Confidential (1997)',
'Groundhog Day (1993)', 'E.T. the Extra-Terrestrial (1982)',
'Star Wars: Episode I - The Phantom Menace (1999)',
'Being John Malkovich (1999)', 'Shawshank Redemption, The (1994)',
'Godfather, The (1972)', 'Forrest Gump (1994)', 'Ghostbusters (1984)',
'Pulp Fiction (1994)', 'Terminator, The (1984)', 'Toy Story (1995)',
'Alien (1979)', 'Total Recall (1990)', 'Fugitive, The (1993)',
'Gladiator (2000)', 'Aliens (1986)', 'Blade Runner (1982)',
'Who Framed Roger Rabbit? (1988)', 'Stand by Me (1986)',
'Usual Suspects, The (1995)', 'Babe (1995)', 'Airplane! (1980)',
'Independence Day (ID4) (1996)', 'Galaxy Quest (1999)',
'One Flew Over the Cuckoo's Nest (1975)', 'Wizard of Oz, The (1939)',
'2001: A Space Odyssey (1968)', 'Abyss, The (1989)',
'Bug's Life, A (1998)', 'Jaws (1975)', 'Godfather: Part II, The (1974)',
'Casablanca (1942)', 'Die Hard (1988)', 'GoodFellas (1990)',
'Hunt for Red October, The (1990)', 'Speed (1994)',
'Indiana Jones and the Last Crusade (1989)', 'Lethal Weapon (1987)',
'Monty Python and the Holy Grail (1974)', 'Toy Story 2 (1999)',
'When Harry Met Sally... (1989)', 'Good Will Hunting (1997)',
'Titanic (1997)', 'Breakfast Club, The (1985)',
'Mission: Impossible (1996)', 'Election (1999)', 'X-Men (2000)',
'Twelve Monkeys (1995)', 'Beetlejuice (1988)', 'Big (1988)',
'Ferris Bueller's Day Off (1986)', 'Edward Scissorhands (1990)',
'Close Encounters of the Third Kind (1977)', 'Fight Club (1999)',
'Dances with Wolves (1990)', 'Star Trek: The Wrath of Khan (1982)',
'Raising Arizona (1987)',
'Austin Powers: The Spy Who Shagged Me (1999)', 'Batman (1989)',
'As Good As It Gets (1997)', 'Face/Off (1997)',
'Butch Cassidy and the Sundance Kid (1969)', 'Thelma & Louise (1991)',
'Clerks (1994)', 'True Lies (1994)', 'American Pie (1999)',
'Contact (1997)', 'Amadeus (1984)', 'Fifth Element, The (1997)',
'High Fidelity (2000)', 'There's Something About Mary (1998)',
'Dr. Strangelove or: How I Learned to Stop Worrying and Love the Bomb (1963)',
'Arachnophobia (1990)', 'Clueless (1995)', 'Get Shorty (1995)',
'Jerry Maguire (1996)', 'Christmas Story, A (1983)', 'Aladdin (1992)',
'Romancing the Stone (1984)', 'Blues Brothers, The (1980)',
'Rock, The (1996)'],
dtype='object', name='Title')
获取在列表内的电影:
#平均分的数据 看头100个评分的数据是否在里面
print(movie_rating_mean.index.isin(top_movie_title2).sum())
flag = movie_rating_mean.index.isin(top_movie_title2)
display(flag.shape,flag)
# 热门电影平均分
movie_rating_top_mean = movie_rating_mean[flag]
movie_rating_top_mean
显示:
对列表内的电影根据评分排名排序:
movie_rating_top_mean.sort_values(by = 'Rating',ascending=False)
- 1
显示: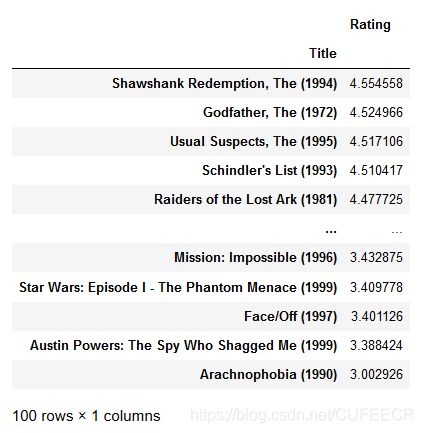
由上处数据处理和分析的过程中可以看到,在数据处理过程中,合并、透视、分组、排序这四大类操作是最经常用的,需要熟练掌握。