SQL Server 数据库 T-SQL 高级查询
SQL Server 数据库 T-SQL 高级查询
- 一、在查询中使用函数
-
- 1.系统函数
- 2.字符串函数
- 3.日期函数
- 4.聚合函数与分组查询
-
- 1)聚合函数
- 2)分组查询
- 3)数学函数
- 4)函数综合应用
- 二、使用 T-SQL 实现多表查询
-
- 1.表联接类型
-
- 1)内联接
- 2)外链接
- 3)交叉链接
一、在查询中使用函数
先创建一个工资表
create table 工资表
(
编号 int identity (1,1) not null,
姓名 nvarchar(10) not null,
身份证号 varchar(18) primary key,
职务 nvarchar(30) not null,
出生日期 datetime not null,
基本工资 money not null,
备注 nvarchar(1000),
)

往表里写入数据
insert into [工资表](姓名,身份证号,职务,出生日期,基本工资)
values ('张三','10086','DBA','1995/3/3','10000')
insert into [工资表](姓名,身份证号,职务,出生日期,基本工资)
values ('李四','20086','运维工程师','1992/2/2','9000')
insert into [工资表](姓名,身份证号,职务,出生日期,基本工资,备注)
values ('王五','22286','运维经理','1990/5/5','15000','技术全面')
insert into [工资表](姓名,身份证号,职务,出生日期,基本工资)
values ('孙七','33386','运维工程师','1995/1/1','8000')
insert into [工资表](姓名,身份证号,职务,出生日期,基本工资)
values ('赵六','66086','运维总监','1980/7/7','36000')
insert into [工资表](姓名,身份证号,职务,出生日期,基本工资)
values ('张嘴','66686','DBA','1989/6/6','9000')
insert into [工资表](姓名,身份证号,职务,出生日期,基本工资,备注)
values ('王者','88086','CTO','1975/11/11','55000','项目经验丰富')
查询 工资表 中所有员工信息:
select * from [工资表]

1.系统函数
系统函数用来获取有关 SQL Server 中对象和设置的系统信息。
| 函数名 | 描述 |
|---|---|
| CONVERT() | 数据类型转换 |
| CAST() | 数据类型转换,与 CONVERT 相比语法比较简单,转换功能较少 |
| CURRENT_USER() | 返回当前登录的数据库用户名 |
| DATALENGTH() | 返回用于指定表达式的字节数 |
| HOST_NAME() | 返回当前用户所登录的计算机的名称 |
| SYSTEM_USER() | 返回当前登录系统用户名 |
| USER_NAME() | 从给定的用户 ID 中返回数据库用户名 |
- 上面所有这些函数,可以在 T-SQL 中混合使用,得到符合特殊要求的查询输出。
2.字符串函数
字符串函数用于控制返回给用户的字符串,这些功能仅用于字符型数据。
| 函数名 | 描述 |
|---|---|
| CHARINDEX() | 用来寻找一个指定的字符串在另一个字符串中的起始位置 |
| LEN() | 返回传递给它的字符串长度 |
| UPPER() | 把转递给它的字符串转换为大写 |
| LTRIM() | 清除字符左边的空格 |
| RTRIM() | 清除字符右边的空格 |
| RIGHT() | 替换一个字符串中的字符 |
| STUFF() | 在一个字符串中,删除指定位置指定长度的字符串,并在该位置插入一个新的1字符串 |
- 字符串在信息处理时由特殊的地位,几乎所有信息都需要转换成字符串才能正确显示,尤其是不同数据拼接起来显示的使用更加广泛。
- 字符串拼接很简单,两个字符串之间使用"+"即可。
将 工资表 中所有运维工程师的姓名和基本工资组合:
select '运维工程师 '+姓名+' 的基本工资是:'+CAST(基本工资 as varchar(10))+'元'
from [工资表]
where 职务='运维工程师'

3.日期函数
在 SQL Server 中不能直接对日期运用数学函数,需要使用日期函数操作日期值。日期函数帮助提取日期值中的日、月及年,以便分别操作它们。
| 函数名 | 描述 |
|---|---|
| GETDATE() | 取得当前的系统日期 |
| DATEADD() | 添加指定的年(YY)、月(MM)、或日(DD) |
| DATEDIFF() | 比较两个日期之间的指定日期部分的差 |
| DATENAME() | 显示指定日期中特定部分的字符串 |
| DATEPART() | 显示日期中指定日期部分的整数形式 |
- 日期函数是实际生活中使用频率非常高的一类函数,可以说很多应用都与日期函数关联。
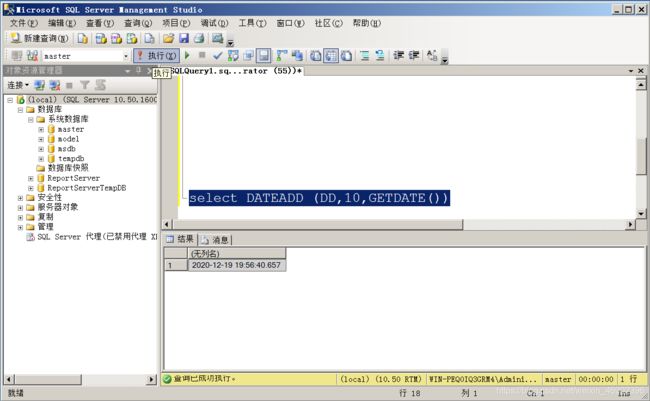
显示距离当前 10 天之后的日期和时间:
select DATEADD (DD,10,GETDATE())
显示 工资表 中所有人的姓名和年龄:
select 姓名,DATEDIFF(YY,出生日期,GETDATE()) AS 年龄 from [工资表]

显示 工资表 中所有 90 后员工的姓名和出生年份:
select 姓名,DATENAME(YEAR,出生日期) AS 出生年份
from [工资表]
where 出生日期 BETWEEN '1990-01-01' AND '1999-12-31'

4.聚合函数与分组查询
在查询时还会经常碰到的是取某些列的最大值、最小值、平均值等信息,有时候还需要计算出究竟查询到多少行数据项。这个时候就可以使用聚合函数,因为聚合函数能够基于列进行计算,并返回单个值。
1)聚合函数
常用的聚合函数有SUM()、AVG()、MAX()、MIN()、COUNT()。
- SUM():SUM() 函数返回表达式中所有数值的总和,它只能用于数字类型的列,不能够汇总字符串、日期等其他数据类型。
- AVG():AVG() 函数返回表达式中所有数值的平均值,它也只能用于数字类型的列。
- MAX():MAX() 函数返回表达式中的最大值,它能够用于数字型、字符型及日期/时间类型的列。
- MIN():MIN() 函数返回表达式中的最小值,它能够用于数字型、字符型及日期/时间类型的列。
- COUNT():COUNT() 函数返回表达式中非空值的计数,它可以用于数字和字符类型的列。另外,也可以使用星号 (*) 作为 COUNT() 函数的表达式,使用星号可以不必指定特定的列而计算所有的行数。
查询 工资表 中所有员工基本工资的总和:
select SUM(基本工资) AS 总工资 from [工资表]

查询 工资表 中所有员工的平均基本工资:
select AVG(基本工资) AS 平均工资 from [工资表]

查询 工资表 中最高和最低的基本工资:
select MAX(基本工资) AS 最高工资,MIN(基本工资) AS 最低工资 from [工资表]

查询 工资表 中全部行数:
select COUNT(*) AS 总行数 from [工资表]

查询 工资表 中 90 后员工的人数:
select COUNT(出生日期) AS '90后人数'
from [工资表]
where 出生日期>='1990-01-01'

2)分组查询
分组查询就是将表中的数据通过 GROUP BY 子句分类组合,再根据需要得到统计信息。如果需要对分组结果进行筛选,只显示满足条件的组,需要使用 HAVING 子句。
查询 工资表 中每个职务的平均工资:
select 职务,AVG(基本工资) AS 职务平均工资 from [工资表] GROUP BY 职务
在使用 GROUP BY 关键字时,在 SELECT 列表中可以指定的项目有限的,SELECT 语句中仅允许以下几项:
- 被分组的列。
- 为每个分组返回一个值的表达式,如果一个列名作为参数的聚合函数。

查询 工资表 中平均工资小于 10000 的职务:
select 职务,AVG(基本工资) AS 职务平均工资 from [工资表] GROUP BY 职务
HAVING AVG(基本工资)<10000
当 GROUP BY 子句使用 HAVING 子句时,查询结果只返回满足 HAVING 条件的组。HAVING 子句与 WHERE 子句类似,均用于设置限制条件。但 HAVING 子句和 WHERE 子句的作用有如下区别:
- WHERE 子句的作用是在对查询结果进行分组前,根据 WHERE 条件筛选数据,条件中不能包含聚合函数。
- HAVING 子句的作用是在分组之后筛选满足条件的组,条件中经常包含聚合函数,也可以使用多个分组标准进行分组。
当 WHERE 和 HAVING 同在一个 SELECT 语句中使用时,执行顺序为 WHERE——》GROUP BY——》HAVING。

查询 工资表 中平均工资小于 10000 的职务,前提是员工 张三 不计算在内:
select 职务,AVG(基本工资) AS 职务总工资 from [工资表]
where 姓名 != '张三'
GROUP BY 职务
HAVING AVG(基本工资)<10000

3)数学函数
数学函数用于对数值进行代数运算。
| 函数名 | 描述 |
|---|---|
| ABS() | 取数值表达式的绝对值 |
| CEILING() | 取大小或等于指定数值、表达式的最小整数 |
| FLOOR() | 取小数或等于指定表达式的最大整数 |
| [POWER() | 取数值表达式的幂值 |
| ROUND() | 将数值表达式四舍五入为指定精度 |
| SIGN() | 对于正数返回+1,对于负数返回-1,对于0则返回0 |
| SQRT() | 取浮点表达式的平方根 |
查询 工资表 中所有人平均工资,用CEILING()取整:
select CEILING(AVG(基本工资)) AS 平均工资 from [工资表]

4)函数综合应用
在实际生产环境中可以根据需要,将函数进行不同的组合,以满足实际需求。
查询未满 30 岁的员工的生日和年龄,并计算出距离 30 岁的天数,最后用字符串拼接显示结果:
1. 查询正确数据结果
- 计算年龄使用日期函数 DATEDIFF(),比较"出生日期"和"当前日期",其中使用参数"YY"取其 Year 的差。
- 计算距离 30 岁的天数也使用日期函数 DATEDIFF(),比较"当期日期"和"出生日期+30年",其中使用 DATEADD()实现将出生日期加 30 年,使用参数 “DD” 比较 Day 的差。
select 姓名,出生日期,DATEDIFF(YY,出生日期,GETDATE()) AS 年龄,DATEDIFF(DD,GETDATE(),DATEADD(YY,30,出生日期)) AS 距离30岁天数
from [工资表]
where DATEDIFF(YY,出生日期,GETDATE())<=30 and 姓名!='王五'
ORDER BY 出生日期

2. 将结果用字符串拼接
- 使用系统函数 CONVERT(varchar(10),出生日期,111)将 DATETIME 类型转换为字符型,定义长度 10 的目的是不显示 10 个字符串以后的内容,“111” 是参数 style 的类型值,参数 style 代表日期格式,有很多种,“111” 代表的 style 格式是 “YYYY/MM/DD” 。
- 使用系统函数 CAST()将年龄和天数转化为字符串。
select
'员工 '+姓名+
' 的生日是'+CONVERT(varchar(10),出生日期,111)+
',现在年龄是 '+CAST(DATEDIFF(YY,出生日期,GETDATE()) AS varchar(10))+'岁'+
',距离30岁生日还有 '+
CAST(DATEDIFF(DD,GETDATE(),DATEADD(YY,30,出生日期)) AS varchar(10))+'天'
from [工资表]
where DATEDIFF(YY,出生日期,GETDATE())<=30 and 姓名!='王五'
ORDER BY 出生日期

二、使用 T-SQL 实现多表查询
如果一个查询需要对多个表进行操作,就称为联接查询,联接查询的结果集或结果称为表之间的联接。联接查询实际上是通过各个表之间共同列的关联性来查询数据的,它是关系数据库查询最主要的特征。
先创建两个表:
create table A
(
姓名 nvarchar(10) not null,
学校 nvarchar(20) not null,
)
create table B
(
姓名 nvarchar(10) not null,
职业 nvarchar(20) not null,
)

往 A 表中写入数据:
insert into A (姓名,学校) values ('张三','清华大学')
insert into A (姓名,学校) values ('李四','北京大学')
insert into A (姓名,学校) values ('王五','武汉大学')
insert into A (姓名,学校) values ('孙七','985大学')
insert into A (姓名,学校) values ('老八','211大学')
往 B 表 写入 数据:
insert into B (姓名,职业) values ('张三','咨询师')
insert into B (姓名,职业) values ('李四','律师')
insert into B (姓名,职业) values ('老八','作家')
insert into B (姓名,职业) values ('小明','明星')
insert into B (姓名,职业) values ('小黑','保安')
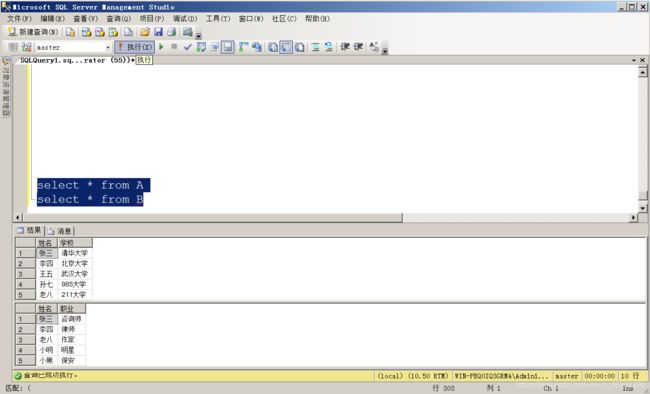
查询 A 表 和 B 表:
1.表联接类型
表联接类型可以分为内联接、外联接和交叉联接等。
1)内联接
内联接(inner join)是最常用的一种联接方式,只返回两个数据集合之间匹配关系的行,将位于两个互相交叉的数据集合中重叠部分以内的数据行联接起来。内联接使用比较运算符进行表间某(些)列数据的比较操作,并列出这些表中联接相匹配的数据行。
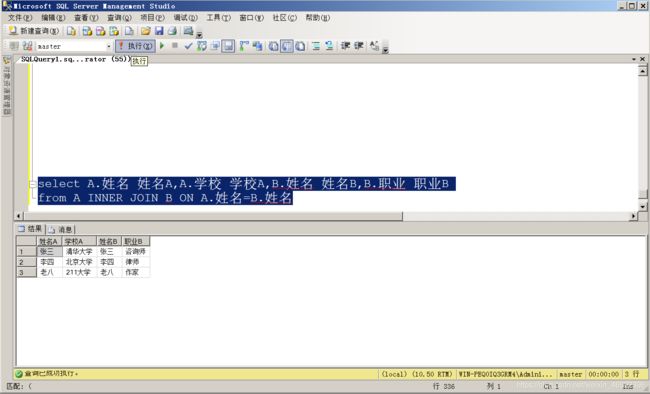
在表 A 和表 B 种使用内联接查询学生姓名、学校和职业:
- 实现方式一:在 where 子句中指定联接条件。
select A.姓名 姓名A,A.学校 学校A,B.姓名 姓名B,B.职业 职业B
from A,B
where A.姓名=B.姓名

- 实现方式二:在 from 子句中使用 INNER JOIN ON子句来实现。
select A.姓名 姓名A,A.学校 学校A,B.姓名 姓名B,B.职业 职业B
from A INNER JOIN B ON A.姓名=B.姓名
2)外链接
外联接(outer join)是对内联接的扩充,除了将两个数据集合中重复部分以内的数据行联接起来之外,还可以根据要求返回左侧或右侧表中非匹配的数据或全部的数据。
外联接分为以下几种:
- 左外联接(left join 或 left outer join):左外联接的结果集包括做左表的所有行。如果左表的某一行在右表中没有匹配行,则右侧返回空值,否则返回相应值。
- 右外联接(right join 或 full outer join):右外联接是左外联接的反向联接,将返回右表的所有行。如果右表的某一行在左表中没有匹配行,则左表返回空值,否则返回相应值。
- 全联接/完整外联接(full join 或 full outer join):将返回左表和右表中所有行。将某一行在另一个表中没有匹配行时,另一个表返回空值,否则返回相应值。
1.左外联接
在表 A 和表 B 中使用左外联接查询学生姓名、学校和职业:
select A.姓名 姓名A,A.学校 学校A,B.姓名 姓名B,B.职业 职业B
from A LEFT JOIN B ON A.姓名=B.姓名

2.右外联接
在 表 A 和表 B 中使用右外联接查询学生姓名、学校和职业:
select A.姓名 姓名A,A.学校 学校A,B.姓名 姓名B,B.职业 职业B
from A RIGHT JOIN B ON A.姓名=B.姓名

3.完整外联接
在 表 A 和表 B 中使用完整外联接查询学生姓名、学校和职业:
select A.姓名 姓名A,A.学校 学校A,B.姓名 姓名B,B.职业 职业B
from A FULL JOIN B ON A.姓名=B.姓名

总结:
- 在外联接中参入联接的表有主从之分,以主表的每行数据去匹配从表的数据列,符合联接条件的数据将直接返回结果集中;
- 对于那些不符合联接条件的列,将被填上 NULL 值后再返回结果集中。
3)交叉链接
交叉联接就是表之间没有任何关联条件,查询将返回左表与右表挨个联接的所有行,就是左表中的每行与右表中的所有行再一一组合,相当于两个表"相乘"。