面试官:MVCC是如何实现的?

MVCC有啥作用?
mvcc即多版本并发控制,通过读取指定版本的历史记录,并通过一些手段保证读取的记录值符合事务所处的隔离级别,在不加锁的情况下解决读写冲突
如果小伙伴对mvcc不熟,估计看了这句话会有点懵,没事,等看完这篇文章你就能看懂这句话了
对于使用InnoDB存储引擎的表来说,聚集索引记录中都包含下面2个必要的隐藏列
trx_id:一个事务每次对某条聚集索引记录进行改动时,都会把该事务的事务id赋值给trx_id隐藏列
roll_pointer:每次对某条聚集索引记录进行改动时,都会把旧的版本写入undo日志中。这个隐藏列就相当于一个指针,通过他找到该记录修改前的信息
如果一个记录的name从貂蝉被依次改为王昭君,西施,会有如下的记录,多个记录构成了一个版本链

先回顾一下隔离级别的概念,这样看后面的内容不至于发懵
√ 为会发生,×为不会发生
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| read uncommitted(未提交读) | √ | √ | √ |
| read committed(提交读) | × | √ | √ |
| repeatable read(可重复读) | × | × | √ |
| serializable (可串行化) | × | × | × |
读已提交
建立如下表
CREATE TABLE `account` (
`id` int(2) NOT NULL AUTO_INCREMENT,
`name` varchar(10) DEFAULT NULL,
`balance` int(3) DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4;
表中的数据如下,设置隔离级别为读已提交
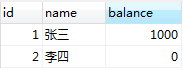
| 时间 | 客户端A(Tab A) | 客户端B(Tab B) |
|---|---|---|
| T1 | set session transaction isolation level read committed; start transaction; select * from account where id = 2; 查询余额输出为0 |
|
| T2 | set session transaction isolation level read committed; start transaction; update account set balance = balance + 1000 where id = 2; select * from account where id = 2; commit; 查询余额输出1000 |
|
| T3 | select * from account where id = 2; commit; 查询余额输出1000 |
不可重复读是指在事务1内,读取了一个数据,事务1还没有结束时,事务2也访问了这个数据,修改了这个数据,并提交。紧接着,事务1又读这个数据。由于事务2的修改,那么事务1两次读到的的数据可能是不一样的,因此称为是不可重复读。
可重复读
表中的数据如下,设置隔离级别为可重复读
| 时间 | 客户端A(Tab A) | 客户端B(Tab B) |
|---|---|---|
| T1 | set session transaction isolation level repeatable read; start transaction; select * from account where id = 2; 查询余额输出为0 |
|
| T2 | set session transaction isolation level repeatable read; start transaction; update account set balance = balance + 1000 where id = 2; select * from account where id = 2; commit; 查询余额输出1000 |
|
| T3 | select * from account where id = 2; commit; 查询余额输出0 |
仔细看这个例子和上面的例子在T3时间段的输出,理解了什么叫可重复读了吧?当我们将当前会话的隔离级别设置为可重复读的时候,当前会话可以重复读,就是每次读取的结果集都相同,而不管其他事务有没有提交。
我当初做完这个实验的时候,我都蒙蔽了,MySQL是如何支持这两种隔离级别的?我们接着往下看
MVCC是如何实现的?
为了判断版本链中哪个版本对当前事务是可见的,MySQL设计出了ReadView的概念。4个重要的内容如下
m_ids:在生成ReadView时,当前系统中活跃的事务id列表
min_trx_id:在生成ReadView时,当前系统中活跃的最小的事务id,也就是m_ids中的最小值
max_trx_id:在生成ReadView时,系统应该分配给下一个事务的事务id值
creator_trx_id:生成该ReadView的事务的事务id
当对表中的记录进行改动时,执行insert,delete,update这些语句时,才会为事务分配唯一的事务id,否则一个事务的事务id值默认为0。
max_trx_id并不是m_ids中的最大值,事务id是递增分配的。比如现在有事务id为1,2,3这三个事务,之后事务id为3的事务提交了,当有一个新的事务生成ReadView时,m_ids的值就包括1和2,min_trx_id的值就是1,max_trx_id的值就是4
mvcc判断版本链中哪个版本对当前事务是可见的过程如下
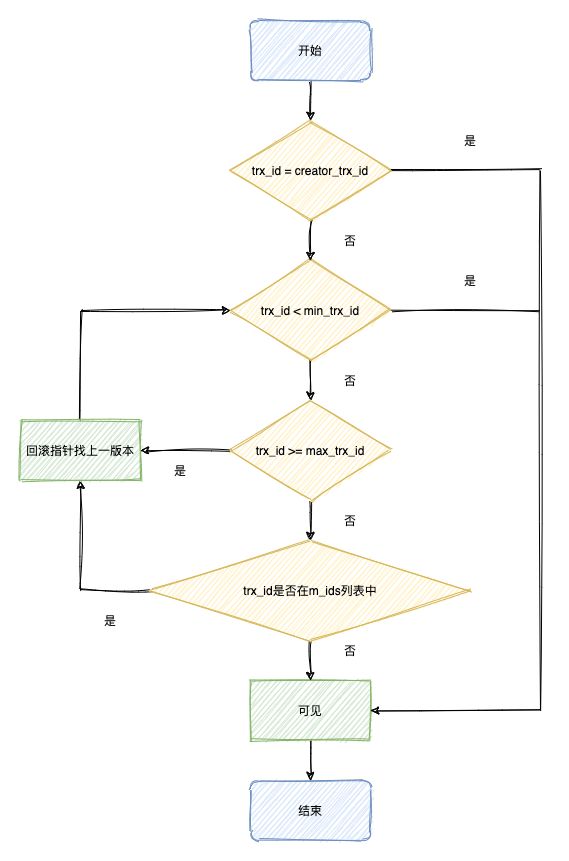
执行过程如下:
- 如果被访问版本的trx_id=creator_id,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问
- 如果被访问版本的trx_id
- 被访问版本的trx_id>=max_trx_id,表明生成该版本的事务在当前事务生成ReadView后才开启,该版本不可以被当前事务访问
- 被访问版本的trx_id是否在m_ids列表中
4.1 是,创建ReadView时,该版本还是活跃的,该版本不可以被访问。顺着版本链找下一个版本的数据,继续执行上面的步骤判断可见性,如果最后一个版本还不可见,意味着记录对当前事务完全不可见
4.2 否,创建ReadView时,生成该版本的事务已经被提交,该版本可以被访问
看着图有点懵?是时候来个例子了
建立如下表
CREATE TABLE `girl` (
`id` int(11) NOT NULL,
`name` varchar(255),
`age` int(11),
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Read Committed
Read Committed(读已提交),每次读取数据前都生成一个ReadView
下面是3个事务执行的过程,一行代表一个时间点
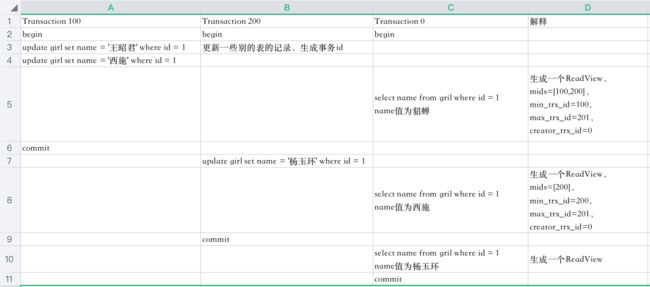
先分析一下5这个时间点select的执行过程
- 系统中有两个事务id分别为100,200的事务正在执行
- 执行select语句时生成一个ReadView,mids=[100,200],min_trx_id=100,max_trx_id=201,creator_trx_id=0(select这个事务没有执行更改操作,事务id默认为0)
- 最新版本的name列为西施,该版本trx_id值为100,在mids列表中,不符合可见性要求,根据roll_pointer跳到下一个版本
- 下一个版本的name列王昭君,该版本的trx_id值为100,也在mids列表内,因此也不符合要求,继续跳到下一个版本
- 下一个版本的name列为貂蝉,该版本的trx_id值为10,小于min_trx_id,因此最后返回的name值为貂蝉

再分析一下8这个时间点select的执行过程
- 系统中有一个事务id为200的事务正在执行(事务id为100的事务已经提交)
- 执行select语句时生成一个ReadView,mids=[200],min_trx_id=200,max_trx_id=201,creator_trx_id=0
- 最新版本的name列为杨玉环,该版本trx_id值为200,在mids列表中,不符合可见性要求,根据roll_pointer跳到下一个版本
- 下一个版本的name列为西施,该版本的trx_id值为100,小于min_trx_id,因此最后返回的name值为西施
当事务id为200的事务提交时,查询得到的name列为杨玉环。
Repeatable Read
Repeatable Read(可重复读),在第一次读取数据时生成一个ReadView

可重复读因为只在第一次读取数据的时候生成ReadView,所以每次读到的是相同的版本,即name值一直为貂蝉,具体的过程上面已经演示了两遍了,我这里就不重复演示了,相信你一定会自己分析了。
参考博客
《MySQL 是怎样运行的:从根儿上理解 MySQL》
[1]https://blog.csdn.net/qq_35190492/article/details/106915564