python CNKI知网论文数据爬取
标题)
- 目的
- 网页入口
- 爬取思路
- 代码
- 总结
目的
爬选定种类(如硕博论文,期刊论文)的标题,作者,发表时间,摘要等信息并存入数据库。
网页入口
使用旧版cnki知网的入口:https://search.cnki.com.cn/Search
过去前人已经做过一部分工作,但由于参数改变,所以爬虫不能再用,本人把这个项目进行了更新,并将爬取数据存到sql数据库中。你可以通过修改数据库存储模块来达到存入csv文件或mysql数据库的功能。
!这个项目不需要模拟登陆,旧版知网也没有速度限制,所以爬取速度很快
爬取思路
以卷积神经网络为例,搜索结果为
搜索结果页:

点开链接后可查看具体内容
详细页面:

于此产生思路:
- 获取搜索结果页所有的链接,全部存入
- 根据链接的url,去获取详细页面
举例,第一个任务获取的数据结果是:

第二个任务获取的数据(包含完整摘要)结果是:
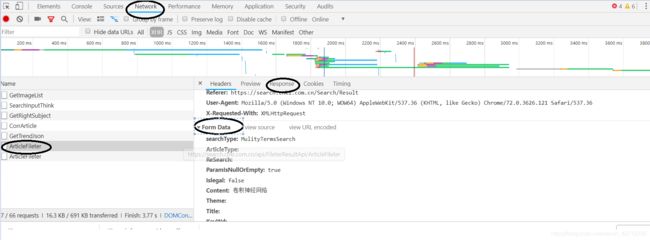
第一个任务可以从网页源代码获取信息,因此之直接使用xpath语法即可。下一步需要分析其post时的参数:
画圈的地方是重点,具体解释可参看我之前写的文章
代码
因此有如下代码(我的代码爬取的是摘要含有“舆情”的硕博论文)
参数修改在这一句里面
def __init__(self , url ='http://search.cnki.com.cn/Search/ListResult' , param = {
'searchType': 'MulityTermsSearch', 'ArticleType':ArticleType, 'ParamIsNullOrEmpty':'true','Islegal':'false', 'Summary':'舆情', 'Type':ArticleType, 'Order':'2', 'Page':'1'})
可以使用上面的代码搜索下面的程序,再参照上面的抓包分析截图,即可知道在哪儿修改自己需求的参数。(为爱发电嘛,主要整理下思路方便自己以后复习,我也不做便利的接口了)
# -*- coding:utf-8 -*-
import sys
import requests
import math
import io
import time
import os
from lxml import etree
import sql_conn
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8')
record = 'CNKI'
articleType = "博士"
if articleType == "博士":
ArticleType = 3
Type = 3
else:
ArticleType = 4
Type = 4
page_url = 20 #每页显示21篇论文
class POST:
"获得url返回信息"
def __init__(self , url ='http://search.cnki.com.cn/Search/ListResult' , param = {
'searchType': 'MulityTermsSearch', 'ArticleType':ArticleType, 'ParamIsNullOrEmpty':'true','Islegal':'false', 'Summary':'舆情', 'Type':ArticleType, 'Order':'2', 'Page':'1'}):
self.url = url
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
}
self.param = param
def response(self):
html = requests.post(url=self.url,data=self.param,headers=self.header)
return html.text
def get_pages(html): #获取总页数
tree = etree.HTML(html)
papers = tree.xpath('//input[@id="hidTotalCount"]/@value')[0]
print(papers)
pages = math.ceil(int(papers) / page_url)
return pages
def get_paper_url(pages,post_form):
conn = sql_conn.conn_sql()
sql_conn.create_tab(conn)
cursor = conn.cursor()
for i in range(1, pages+1):
post_form['Page'] = str(i)
try:
emp2 = POST(param = post_form) #使用默认参数
response = emp2.response()
tree = etree.HTML(response)
except:
print("出错跳过")
continue
for num in range(1,page_url+2): #每页有20个herf,,xpath从1起始
try:
url = (tree.xpath('//div[@class="lplist"]/div['+str(num)+']/p/a/@href')[0])
title = (tree.xpath('//div[@class="lplist"]/div['+str(num)+']/p/a/@title')[0])
#放在数组里面,然后每页存进txt文档一下
author = (tree.xpath('//div[@class="lplist"]/div['+str(num)+']/p[3]/span[1]/@title')[0])
dt = {
'PaperName':title,'PaperUrl': url,'Author':author} #字典
sql_conn.store_to_sql(dt,conn,cursor) #每条写入一次
except:
continue
print(url)
print(title)
print(author)
#获取结束时间
end=time.clock()
print('获取文章详情页链接共用时:%s Seconds'%(end-start))
if __name__ == '__main__':
#获取开始时间
start=time.clock()
# 避免之前的内容重复爬取
if os.path.exists('data-detail.txt'):
print("存在输出文件,删除文件")
os.remove('data-detail.txt')
# 获取页数,可以根据搜索关键词进行url修改,这里是“大数据”
index_url = 'http://search.cnki.com.cn/Search/ListResult'
page = '1'
form = {
'searchType': 'MulityTermsSearch', 'ArticleType':ArticleType, 'ParamIsNullOrEmpty':'true','Islegal':'false', 'Summary':'舆情', 'Type':Type, 'Order':'1', 'Page':page}
emp1 = POST(index_url,form) #创建第一个类对象,用于获得返回数据
html1 = emp1.response()
maxpage = get_pages(html1) #最大页数
print('The total page is:', maxpage)
get_paper_url(maxpage,form)# 获取各检索结果文章链接
上面的文件要调用sql_conn.py文件,下面是sql_conn.py文件,存入数据库。可修改为存入csv文件(需要自己改)
import pymssql
DataBase = 'CNKI'
def conn_sql():
server = "127.0.0.1"
user = "sa"
password = "123456"
conn = pymssql.connect(server, user, password, DataBase)
return conn
def create_tab(conn): #create table(if not exists)
table_name = 'url_title' #表的名字
cursor = conn.cursor()
#sql语句一定要注意,中文要用单引号
sentence = 'USE \"'+DataBase+'\"\
if not exists (select * from sysobjects where id = object_id(\''+table_name+'\')and OBJECTPROPERTY(id, \'IsUserTable\') = 1) \
CREATE TABLE \"'+table_name+'\"\
(NUM int IDENTITY(1,1),\
PaperName VARCHAR(100) NOT NULL,\
PaperUrl VARCHAR(100) NOT NULL,\
Author VARCHAR(100) NOT NULL\
) '
cursor.execute(sentence)
conn.commit()
cursor.close()
def create_detail_tab(table): #创建详细信息表,表的名字由调用文件传入
conn = conn_sql()
cursor = conn.cursor()
sentence = 'USE \"'+DataBase+'\"\
if not exists (select * from sysobjects where id = object_id(\''+table+'\')and OBJECTPROPERTY(id, \'IsUserTable\') = 1) \
CREATE TABLE \"'+table+'\"\
(NUM int IDENTITY(1,1),\
PaperName VARCHAR(100) NOT NULL,\
PaperUrl VARCHAR(100) NOT NULL,\
Author VARCHAR(100) NOT NULL,\
School VARCHAR(50) NOT NULL,\
Year VARCHAR(20) NOT NULL,\
Degree VARCHAR(50) NOT NULL,\
Abstracts VARCHAR(8000) NOT NULL\
) '
cursor.execute(sentence)
conn.commit()
cursor.close()
def store_to_detial(tbname,dt):
try:
conn = conn_sql()
cursor = conn.cursor()
tbname = '['+tbname+']'
ls = [(k,v) for k,v in dt.items() if k is not None]
sentence = 'IF NOT EXISTS ( SELECT * FROM '+tbname+' WHERE PaperName =\''+str(ls[0][1])+'\') \
INSERT INTO %s (' % tbname +','.join([i[0] for i in ls]) +') VALUES (' + ','.join(repr(i[1]) for i in ls) + ');'
cursor.execute(sentence)
conn.commit()
cursor.close()
except Exception as e:
print('Error: ', e)
def store_to_sql(dt,connect,cursor): #insert or just change the information
print("1")
tbname = '['+table_name+']'
ls = [(k,v) for k,v in dt.items() if k is not None]
sentence = 'IF NOT EXISTS ( SELECT * FROM '+tbname+' WHERE PaperName =\''+str(ls[0][1])+'\') \
INSERT INTO %s (' % tbname +','.join([i[0] for i in ls]) +') VALUES (' + ','.join(repr(i[1]) for i in ls) + ');'
print(sentence)
cursor.execute(sentence)
connect.commit()
return ""
def read_sql(conn,sentence):
cursor = conn.cursor()
cursor.execute(sentence)
result = cursor.fetchall()
conn.commit()
cursor.close()
return result #返回为字典形式
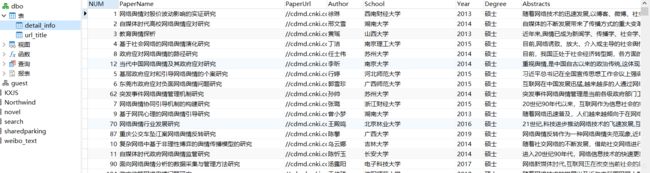
数据库存储完了结果,第二次循环得到的url,即下图,以图得到详细数据

第二次循环还需要调用一个名叫spider_paper的文件:
import requests
def response_get(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
html = requests.get(url=url, headers = headers)
return html.text
下面是第二次循环爬取论文详细数据,调用上面已经给出的sql_conn.py把爬取的数据存储数据库内
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import time
import sql_conn
import spider
import str
def get_visit_url_list(cols,table_name):
str = ','
cols = str.join(cols)
connection = sql_conn.conn_sql()
sql_cmd = 'select '+cols+' from ' +table_name
result = sql_conn.read_sql(connection,sql_cmd)
return result
def find_str(begain,text):
result_find = ""
flag = 0 #用于控制提取’:‘后的文字
for k in range(begain, len(text)):
if text[k] == ':':
flag = 1
continue
if flag == 1:
if text[k] == '\n' or text[k] == '\t' or text[k] == '\r' or \
text[k] == '】':
continue
if text[k] == ' ' and text[k + 1] == ' ':
continue
if text[k] != '【':
result_find = result_find + text[k]
if text[k] == '【' and k != begain:
break
return result_find
def get_detail_url(table_name): #获得数据库中detail表里已有数据,并返回list
connection = sql_conn.conn_sql()
sql_cmd = 'select PaperUrl from ' + table_name #读取detail表
detail_url_list = sql_conn.read_sql(connection,sql_cmd)
result_list = []
for record in detail_url_list:
result_list.append(record[0])
return result_list
def spider_paper():
start = time.clock() #开始计时,统计总共花的时间
sql_conn.create_detail_tab('detail_info')
Aimist = ['PaperName','Author','PaperUrl']
AimTable = 'url_title'
lines = get_visit_url_list(Aimist,AimTable)
txt_num = 1
lin_num = 1
detail_url_list = get_detail_url('detail_info')
print(detail_url_list[1:10])
process = 0 #统计第多少次循环。方便显示运行进度
for line in lines:
process+= 1
print("当前进度:{}%".format(process / len(lines) * 100))
try:
#sleep(random.randint(1,3))
paper_url = line[2] #每个tuple的第三个存储url
if paper_url in detail_url_list:
print("跳过")
continue
print(line[0])
detail_url_list.append(paper_url)
attempts = 0
success = False
html = spider.response_get("http:"+paper_url)
soup = BeautifulSoup(html, 'html.parser')
success = True
title = soup.find_all('div', style="text-align:center; width:740px; font-size: 28px;color: #0000a0; font-weight:bold; font-family:'宋体';")
abstract = soup.find_all('div', style='text-align:left;word-break:break-all')
author = soup.find_all('div', style='text-align:center; width:740px; height:30px;')
#获取作者名字
for item in author:
author = item.get_text()
# print(item)
#获取摘要信息
tmp = ''
for thing in abstract:
a = thing.strings
for string in a:
tmp = tmp + string
txt_num += 1
result = tmp.split(' ')
tstr = ''
for t in result:
test = t.split('\n')
# print(test)
if test != '\t' and test != '\n' and test != '\r' and test != '':
for i in test:
if len(i) > 1:
item = i.split('\r')
for j in item:
object = j.split('\t')
for k in object:
tstr += k
ifreferen = soup.find_all('td', class_='b14', rowspan='2')
# 获取作者单位,处理字符串匹配
authorUnitScope = soup.find('div', style='text-align:left;', class_='xx_font')
author_unit = ''
author_unit_text = authorUnitScope.get_text()
# print(author_unit_text)
if '【作者单位】:' in author_unit_text:
auindex = author_unit_text.find('【作者单位】:', 0)
else:
auindex = author_unit_text.find('【学位授予单位】:', 0)
author_unit = find_str(auindex,author_unit_text)
# 获取关键字
if '【学位级别】:' in author_unit_text:
degreedex = author_unit_text.find('【学位级别】:', 0)
degree = find_str(degreedex,author_unit_text)
else:
degree = "非学位论文"
if '【关键词】:' in author_unit_text:
kwindex = author_unit_text.find('【关键词】:', 0)
key_word = find_str(kwindex,author_unit_text)
else:
key_word = "未提供关键词"
if '【学位授予年份】:' in author_unit_text:
yeardex = author_unit_text.find('【学位授予年份】:', 0)
year = find_str(yeardex,author_unit_text)
else:
year = "未提供硕士论文发表年份"
tstr = tstr.replace("【摘要】:", "")
"""
print(author)
print(author_unit)
print(tstr)
print(degree)
print(year)
"""
data = dict(PaperName = line[0], PaperUrl = line[2], Author = str.delet(author),School = str.delet(author_unit),Abstracts = str.delet(tstr),\
Degree = str.delet(degree), Year = str.delet(year))
sql_conn.store_to_detial('detail_info',data)
except Exception as e:
print('Error: ', e)
end = time.clock()
print('Running time: %s Seconds' % (end - start))
if __name__ == '__main__':
spider_paper()
总结
如此,爬取完成。有问题欢迎评论区留言,看的人多以后也许会细化这个project,解释一些控制参数是如何设置的。