ElasticSearch原理篇
一、基本信息
1.简介
介绍ElasticSearch前我们先预热一些常识,提到非结构化数据的检索的时候,经常听到Lucene、Solr、ElasticSearch,那他们的区别是什么呢?
Apache Lucene不是搜索引擎,而是一个开源的搜索引擎工具包,他提供了查询和检索能力。Lucene是为了给开发人员提供一个简单易用的搜索工具包,以方便开发人员的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Solr是一个基于Apache Lucene的高性能企业级搜索引擎,它具有高可用、易扩展、可容错特性,提供分布式的索引存储、多副本、基于负载均衡的查询、中心化配置等能力。
ElasticSearch是一个基于Apache Lucene的分布式搜索引擎,它还可以作为实时文档存储系统,并且文档中的每一个内容都可以被检索,能够处理PB级别的结构化或非结构化数据。
Elasticsearch本身就具有分布式的特性和易安装使用的特点,目前已经是最受欢迎的企业搜索引擎; Solr 的分布式需要借助第三方来实现,例如通过使用 ZooKeeper 来达到分布式协调管理。
2.名词解释
为了方便理解,在接下来的介绍中,将Index、Type、Document、Field和关系数据库中的概念做了一个类比,注意这里仅仅是类比,方便第一次接触搜索引擎的小伙伴理解,实际上他们还是有较大的差异。
1)索引(Index)
索引指的是包含一堆有相似结构的文档数据(Document)。例如:商品索引、订单索引。在商品索引中我们可以存放成千上万的商品信息;在订单索引中我们可以存放成千上万的订单信息。
这个角度上看,Index和关系型数据库中的数据库类似。
2)类型(Type)
类型是索引内部的逻辑分区(category/partition),每个Index里都可以有一个或多个type,type是Index中的一个逻辑数据分类,一个type下的document有相同的field。比如:在商品索引中,服装和旅游路线,虽然都是可售卖的商品,但因为有很多属性都不同,就可以为他们定义两种Type;另外,也可以为类目定义一个Type。示例如下:
服装商品的Type:商品名字、价格、描述
旅游路线商品的Type:商品名字、价格、描述、行程信息
这个角度上看,Type和关系型数据库中的表类似。
3)文档&属性(Document&Field
一个document是一条实例数据,例如一个商品,一个订单,通常使用JSON数据结构表示。一个document里面有多个field,每个field就是一个数据字段。
从这个角度上看,Document和关系型数据库中的一行记录类似,Field和关系型数据库中的字段类似。
这就是一个简单的Document示例:
{
_Index: "twitter",
_type: "_doc",
_id: "1",
_version: 1,
_seq_no: 0,
_primary_term: 1,
found: true,
_source: {
user: "kimchy",
post_date: "2009-11-15T13:12:00",
message: "Trying out Elasticsearch, so far so good?"
}
}
4)词条(Term)
索引里面最小的存储和查询单元,对于英文来说是一个单词,对于中文来说一般指分词后的一个词。
5)词典(Term Dictionary)
也称字典,是词条Term 的集合。搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
6)正排数据
搜索引擎的通用叫法,即原始数据,可以理解为一个doc list。
7)倒排索引(inverted index)
lucene索引的通用叫法,即实现了term到doc list的映射。倒排索引建立的是分词(Term)和文档(Document)之间的映射关系,在倒排索引中,数据是面向词(Term)而不是面向文档的。
8)倒排表(Post list)
一个文档通常由多个词组成,倒排表记录的是某个词在哪些文档里出现过以及出现的位置。
每条记录称为一个倒排项(Posting)。倒排表记录的不单是文档编号,还存储了词频等信息。
9)倒排文件(Inverted File)
所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
二、索引原理
1.倒排索引的结构
假如现有三份数据文档,文档的内容如下:
Doc1: I love China。
Doc2: I love work。
Doc3: I love coding。
为了创建倒排索引,首先通过分词器将每个文档的内容域拆分成单独的词(我们称它为词条或Term),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。结果如下:
| Term | Doc1 | Doc2 | Doc3 |
|---|---|---|---|
| I | Y | Y | Y |
| China | Y | ||
| coding | Y | ||
| love | Y | Y | Y |
| work | Y |
如上表格所示,这种结构由文档中所有不重复词的列表构成,对于其中每个词都有一个Doc与之关联。这种由属性值来确定记录的位置的结构就是倒排索引(Post Index)。带有倒排索引的文件我们称为倒排文件(Inverted File)。
根据以上内容,倒排文件的结构如下所示:
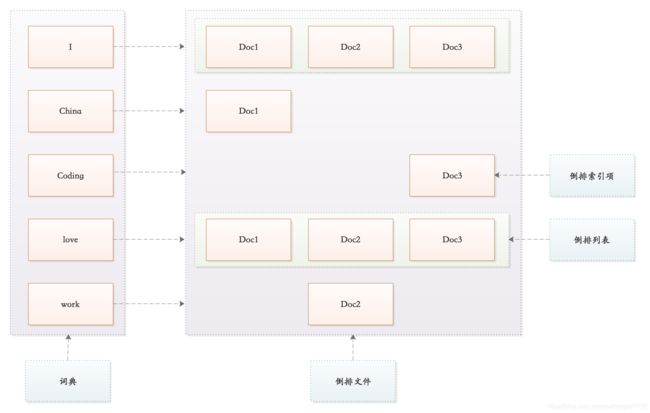
词典和倒排表是 Lucene 中很重要的两种数据结构,是实现快速检索的重要基石。
2.搜索
1)创建倒排索引
上面简单介绍了倒排索引的结构,接下来以一个示例讲述倒排索引是如何做到高效搜索的。假设有一张学生成绩表,数据如下所示:
| id | name | gender | score |
|---|---|---|---|
| 1 | Fern | female | 80 |
| 2 | Alice | female | 70 |
| 3 | Bunny | male | 90 |
| 4 | Aimee | female | 70 |
| 5 | Amy | female | 80 |
| 6 | tracy | female | 90 |
数据存储到ES中后,会建立以下倒排索引:
Name
| Term | Posting List |
|---|---|
| Aimee | 4 |
| Alice | 2 |
| Amy | 5 |
| Bunny | 3 |
| Fern | 1 |
| tracy | 6 |
Gender
| Term | Posting List |
|---|---|
| female | [1,2,4,5,6] |
| male | 3 |
Score
| Term | Posting List |
|---|---|
| 70 | [2,4] |
| 80 | [1,5] |
| 90 | [3,6] |
以上为词条和倒排索引的关系,即当我们搜索score=70的记录的时候,通过倒排索引能直接找到[2,4]记录,然后返回对应的记录。
2)词典
词典是词条的集合,当词条很多的时候,ES是如何保证高效查询的呢?
在Mysql数据库中也有类似的问题,当记录数很多的时候,如何快速找到需要的记录呢?Mysql的做法是创建索引,Mysql的索引是使用B+数来实现的,如果查询条件能使用上索引,那么就直接将查询条件和索引进行匹配,因为索引是B+数,所以查询效率将会非常高。ES的做法也是类似的,即:对所有的词条进行排序,然后通过二分法查找,时间复杂度降低为lgN。
假设name的取值如下:
Fern,Alice,Bunny,Aimee,Amy,tracy
经过排序后的:
Aimee,Alice,Amy,Bunny,Fern,tracy
Mysql的索引存储在磁盘上,ES的词典存储在内存中,上面这种做法,ES虽然可以解决查询效率问题,但是它会引起另外一个问题:当Term(词条)很多时,内存必定无法容纳这些词条,那ES是如何处理这个问题的呢?ES的做法是创建Term Index。
上面的示例中Term都是英文字符,但是实际的情况是,term可以是任意的byte数组;另外,很多时候Term数量对应的内容未必均衡,如上所示:C字符开头的term一个都没有,而A开头的term又特别多。Lucene 内部的Term Index是用的变种的trie树(前缀树/字典树/单词查找树),即FST(finite-state transducer),trie树只共享了前缀,而 FST 既共享前缀也共享后缀,更加的节省空间。
关于FST的原理比较复杂,这里主要了解它在这里起的核心作用:高效的查找到词条(Term)。
通过Term Index可以快速地定位到Term Dictionary 的某个 offset,然后从这个位置再往后顺序查找。再加上一些压缩技术(搜索 Lucene Finite State Transducers)Term Index的尺寸可以只有所有Term 的尺寸的几十分之一,使得用内存缓存整个Term Index变成可能。整体上来说就是这样的效果:
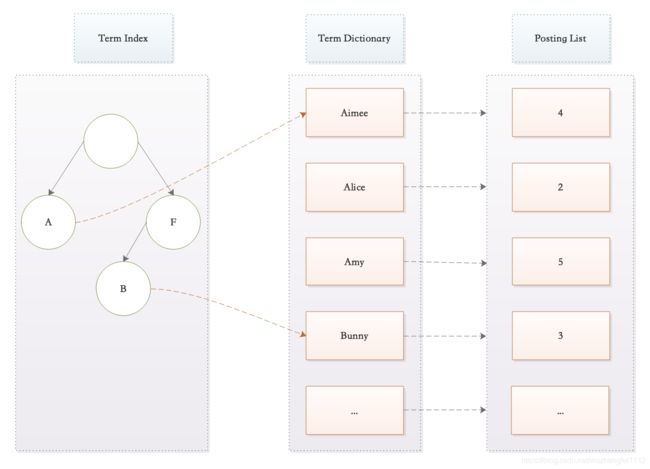
如上图所示,Term Index主要解决的是快速定位到Term,和我们用的字典或者通讯录比较类似,例如:我们可以直接通过字母W快速找到所有以W开始的汉子或者姓氏,然后再找到对应的汉字或名字。
从上面的分析我们看到,因为ES的Term Index的原因,ES在检索上面,有的时候表现的比Mysql更快,Mysql只有Term Dictionary,而且这一层是以B+树的方式存储在磁盘上的。检索一个Term 需要若干次的 random access 的磁盘操作。而 Lucene 在Term Dictionary 的基础上添加了Term Index来加速检索,Term Index以树的形式缓存在内存中,从Term Index查到对应的Term dictionary 的 block 位置之后,再去磁盘上找Term,大大减少了磁盘的 random access 次数。
三、集群
1.索引
Elasticsearch的index和Mysql的数据库比较类似,用户的所有操作都是基于index完成的,每个index由若干个shard组成,如下图所示: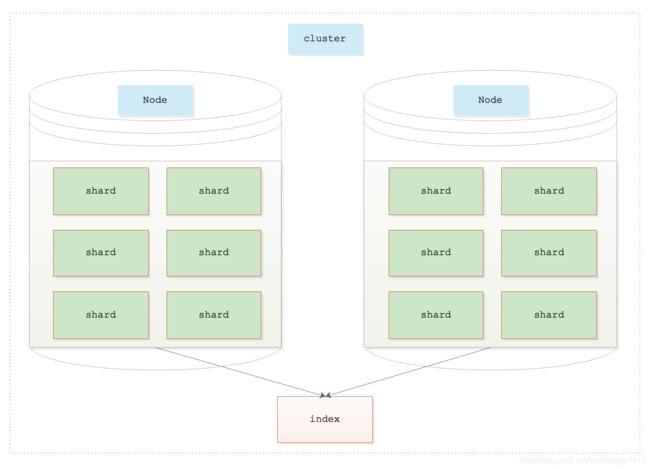
shard是Elasticsearch数据存储的最小单位,index的存储容量为所有shard的存储容量之和。Elasticsearch集群的存储容量则为所有index存储容量之和。
2.节点(Node)
ES本身就具备集群能力,只需让每个节点设置相同的cluster.name即可加入同一个集群;它们共同承担整个集群的数据和负载压力。ES中一个节点即一个运行中的 Elasticsearch 实例。节点通过 node.name 来设置节点名称,如果不设置则在启动时给节点分配一个随机通用唯一标识符作为名称。ES集群中的节点有三种不同的类型:主节点、数据节点、协调节点。
1)主节点
负责管理集群的所有变更,主要责任例如:创建或删除索引;跟踪管理那些节点属于集群的一部分,例如增加、删除节点等;决定那些分片给相关的节点。
可以通过属性node.master进行设置。node.master=true表示此节点具有被选举为主节点的资格。
2)数据节点
数据节点负责数据的存储和相关的操作,例如对数据进行增、删、改、查和聚合等操作,数据节点对机器配置要求比较高,对 CPU、内存和 I/O 的消耗很大。默认每一个节点都是数据节点(包括主节点),可以通过node.data属性进行设置。
node.data=true表示此节点为数据节点,用于存储数据。
3)协调节点(或client节点)
如果node.master和node.data属性均为false,则此节点称为协调节点。协调节点只能处理路由请求,处理搜索、分发索引操作等。此节点的意义是在海量请求的时候可以进行负载均衡。
注意,每一个节点都具有node.master、node.data属性,默认情况下node.master=true且node.data=true,即默认一个节点同时是数据节点和主节点。
4)最佳实践
master节点:普通服务器即可(CPU、内存消耗一般)
data 节点:主要消耗磁盘,内存
client | ingest 节点:普通服务器即可(如果要进行分组聚合操作的话,建议这个节点内存也分配多一点)
3.分片(Shard)
分片是一种让集群支持水平扩展能力的方案,即ES是通过分片来实现分布式。每一个分片都是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。集群中我们的文档被存储和索引到分片内,不过对于客户端来说分片是透明的,他们感知不到分片的存在。当集群规模扩大或者缩小时, ES会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里。
ES中有两种类型的分片:主分片(primary shard)、副本分片(replicas)。索引内任意一个文档都归属于一个主分片,所以主分片的数目直接决定着集群中能够保存的最大数据量。一个副本分片只是一个主分片的拷贝,副本分片主要是用来实现高可用、高并发的,例如:硬件故障时保护数据不丢失,提供读服务等。
1)集群模型
下图描述的是一个具有是3个节点(Node1、Node2、Node3)的ES集群,其中Node1为主节点,Node1、Node2、Node3都是数据节点。此集群有9个分片,其中3个主分片(P0、P1、P2)和6个从分片(R0、R1、R2),每一个主分片都有两个从分片。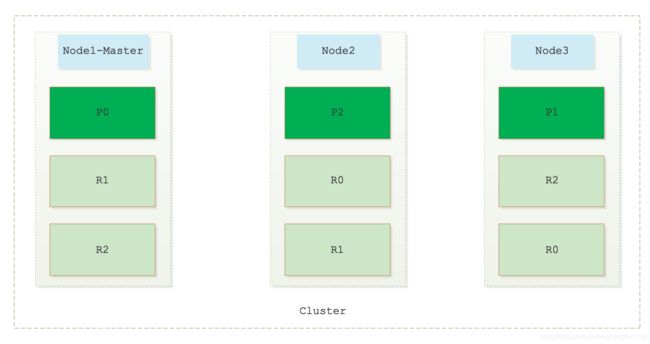
2)路由
所有数据都要先写到主分片上,只有主分片处理成功后,才能拷贝至其对应的副本分片上。默认情况下主分片等待所有备份完成索引更新后才返回客户端。
当一个集群中存在多个主分片时,ES是根据什么样的规定来将数据写到某一个分片上的呢?ES的数据路由策略由以下公式决定:
shard = hash(routing) % number_of_primary_shards
Routing是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。稍有Java开发经验的人应该对这种处理方式都很熟悉,例如:HashMap、Redis、分库分表等等场景都会使用类似的策略。
注意:通常而言,我们需要在创建索引的时候就确定好主分片的数量,并且不会改变这个数量,因为如果number_of_primary_shards变化了,那么上面公式计算出来的值就会发生变化,在迁移数据完成前,数据将会完全错乱。其实我们日常使用的中间件都有这个问题,例如Redis。如果真的需要进行调整集群容量(增加或者减少节点数目),那么必须迁移数据。Redis的常用集群采用的是一致性hash策略,让这种情况发生时数据迁移量尽可能小。
ES通过shard = hash(routing) % number_of_primary_shards公式决定路由策略,可见任何一个节点都可以计算出集群中的文档的存放位置,所以每个节点都有处理读写请求的能力。
3)写操作
在一个写请求被发送到某个节点后,节点会根据路由公式计算出需要写到哪个分片上,再将请求转发到该分片的主分片节点上,主分片处理成功以后会将请求转发给副本分片。图解如下所示: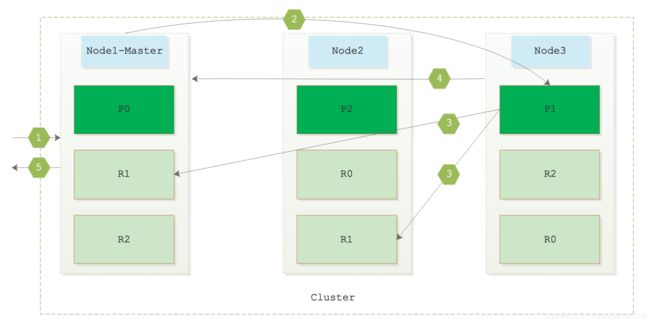
具体过程如下:
- 假设Node1收到一个创建索引的请求。
- Node1根据shard=hash(routing)% number_of_primary_shards计算数据落到哪一个分片上。假设计算出来的shard=1。
- 因为shard=1的主分片P1在Node3上,所以Node1将写请求转发到Node3节点。
- Node3如果处理成功,因为P1的两个副本R1在Node1、Node2上,所以Node3会将写请求转发到Node1、Node2上。
- 当所有的副本R1报告处理成功后,Node3向请求的Node1返回成功信息,Node1最后返回客户端索引创建成功。
4)读操作
在一个读请求被发送到某个节点后,节点会根据路由公式计算出数据存储在哪个分片上,节点会以负载均衡的方式选择一个节点,然后将读请求转发到该分片节点上。过程如下所示:
具体过程如下:
- 假设Node1节点收到一个读请求。
- Node1节点通过shard=hash(routing)% number_of_primary_shards计算数据落到哪一个分片上。假设计算出来的shard=1。
- Shard=1的分片有三个,其中主分片P1在Node1上,副分片R1在Node2、Node3上,此时Node1根据负载均衡的方式来选择一个副本。图中选择的是Node2节点的R1副本。Node1将请求转发给Node2处理此次读操作。
- Node2处理完成以后,将结果返回给Node1节点,Node1节点将数据返回给客户端。
5)更新操作
ES的更新是结合删除和新增来实现的,具体见后文。
4.集群健康
在索引建立的时候就已经确定了主分片数,但是副本分片数可以随时修改。默认情况下,一个索引会有5个主分片,而其副本可以有任意数量。
主分片和副本分片的状态决定了集群的健康状态。
每一个节点上都只会保存主分片或者其对应的一个副本分片,相同的副本分片不会存在于同一个节点中。如果集群中只有一个节点,则副本分片将不会被分配,此时集群健康状态为yellow,存在丢失数据的风险。
四、存储
1.存储位置
ES的索引都会落到磁盘上,这样在断电或重启的时候也不会丢失数据。ES数据存储路径在elasticsearch.yml 中配置。
path.data: /path/to/data //索引数据
path.logs: /path/to/logs //日志记录
默认存储在安装目录的 Data 文件夹下。建议不要使用默认值,因为若 ES 进行了升级,则有可能导致数据全部丢失。
2.分段存储
1)Segment
索引文档以段(Segment)的形式存储在磁盘上,每一个段上都存储的是倒排索引信息。Lucene在底层采用了分段的存储模式,读写时几乎完全避免了锁的出现,大大提升了读写性能。
写入lucene的数据并不直接落盘,而是先写在内存中,经过了refresh间隔,lucene才将该时间段写入的全部数据refresh成一个segment,segment多了之后会进行合并操作,合并成更大的segment。lucene查询时会遍历每个segment完成。
2)段的不变性
段具有不变性,一旦索引的数据被写入硬盘,就不可再修改。段被写入到磁盘后会生成一个提交点,一个段一旦拥有了提交点,就说明这个段只有读的权限,失去了写的权限。相反,当数据在内存中时,就只有写的权限,而不具备读数据的权限,意味着不能被检索。
按照上面的规则,新增文档很好处理,指定时间后会refresh到磁盘中,以一个新段来存储,那更新、删除文档需要如何处理呢?
由于Segment不可修改,所以删除时不会把文档从旧的段中移除,而是通过新增一个.del文件,文件中会列出这些被删除文档的段信息。被标记删除的文档仍然可以被查询匹配到,但它会在最终结果被返回前从结果集中移除。(这一点和Redis数据的被动过期策略很类似。)
由于Segment不可修改,更新被看成是删除+新增两个操作。即会将旧的文档在.del文件中标记删除,然后文档的新版本被保存到一个新的Segment中。
3)段不可改变性的优缺点
- 优点:
不需要锁,设计简单,读写性能高。
因为段文件不会变化,一旦索引文件进入文件系统缓存,只要文件系统缓存有足够空间,基本上都会命中,性能高。相比于会变化的数据文件,当数据变化后需要保持索引内容和数据一致性,不变性的段不用考虑此问题。 - 缺点:
.del是对文档进行标记,如果这种数据很多,会造成大量空间浪费。
每隔一段时间(由refresh_interval决定)会生成一个新Segment,Segment过多的时候,对大量消耗服务器资源消耗。
修改、删除的文档依然会出现在查询的结果集中,虽然不会返回给客户端,但是这会增加查询负担。
新的数据刷新到Segment中之前不能被检索到,有一定的实效性问题。
3.延迟写策略
为了提升写的性能,ES采用延迟写的策略,即每当有新增的数据时,就将其先写入到内存(ES的JVM内存)中,当达到指定时间(由refresh_interval指定,默认是1 秒钟)或达到一定数量时,会触发一次刷新(Refresh),将内存中的数据刷新到一个新的Segment上并缓存到文件缓存中,稍后再被刷新到磁盘中并生成提交点。另外,需要注意的是数据未被刷新到Segment中之前,不是以段的形式存储的, 所以也就不能被检索到。这也是ES是准实时搜索的原因。
我们也可以手动触发 Refresh, /_refresh 刷新所有索引,/「index-A」/_refresh 刷新指定的索引。注意,尽管刷新是比提交轻量很多的操作,它还是会有性能开销。手动刷新适合测试的时候,在生产环境中不要每次更新一个文档都去手动刷新;另外,每秒刷新并不是适合所有的场景,还是要根据具体的情况考虑。
设置refresh_interval 的时候注意要带上单位,例如refresh_interval = “10s”,否则单位是毫秒;当 refresh_interval=-1 时表示关闭索引的自动刷新。通过延时写的策略可以减少数据往磁盘上写的次数,从而提升了整体的写入能力,但是文件缓存属于操作系统的内存,只要是内存都存在断电或异常情况下丢失数据的危险。为了避免丢失数据,Elasticsearch 添加了事务日志(Translog),事务日志记录了所有还没有持久化到磁盘的数据。
4.索引持久化过程
通过上面的部分,我们大概了解了ES的数据持久化过程,接下来我们通过图文的方式详细介绍一下持久化的过程。
1)写入数据
当有数据写入ES时,为了提升写入的速度,并没有数据直接写在磁盘上,而是先写入到内存中,但是为了防止数据的丢失,会追加一份数据到事务日志里。如下所示:
2)Refresh
当达到默认的时间(1 秒钟)或者内存的数据达到一定量时,会触发一次刷新(Refresh)。刷新的主要步骤如下:
将内存中的数据刷新到一个新的段中(S3)。注意S3目前处于操作系统的文件的缓存系统中,而不是磁盘上。
打开段(S3),使其可被搜索。
清空内存,准备接收新的数据,事务日志不清空。
注意:此时S3虽然没有持久化到磁盘中,但S3中的数据是可以被检索到的.
3)Flush
当日志数据的大小超过 512MB 或者时间超过 30 分钟时,需要触发一次Flush,此Flush会进行如下操作:
将文件系统缓存中的数据S3刷新到硬盘中。
生成提交点。
删除旧的事务日志(Translog),创建一个空的事务日志(Translog)。
5.段合并策略
1)策略
在「分段存储」部分我们知道随着时间的累积,会导致索引中存在大量的Segment。而ES检索的大概过程是:查询所有Segment中满足查询条件的数据,然后对每个Segment里查询的结果集进行合并。这里就有一个问题,每一个段都会消耗文件句柄、内存和cpu运行周期,更重要的是,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢,所以为了控制索引里段的数量,必须定期进行Segment合并操作。
简单来说Elasticsearch通过以下方式解决这个问题:Elasticsearch通过在后台进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。段合并的时候会将那些旧的已删除文档从文件系统中清除。被删除的文档(或被更新文档的旧版本)不会被拷贝到新的大段中。启动段合并不需要你做任何事,进行索引和搜索时会自动进行。如果每次合并全部的Segment,则会造成很大的资源浪费,特别是“大Segment”的合并。
Lucene的合并思路是:根据Segment的大小将段进行分组,再将属于同一组的Segment进行合并。另外,由于对于超级大的Segment的合并需要消耗更多的资源,所以 Lucene 会在Segment的大小达到一定规模,或者Segment里面的数据量达到一定条数时,不会再进行合并。
由此可以看出Lucene 的段合并主要集中在对中小Segment的合并上,这样既可以避免对大段进行合并时消耗过多的服务器资源,也可以很好地控制索引中段的数量。
2)段合并参数
mergeFactor:每次合并时参与合并的最少数量,当同一组的段的数量达到此值时开始合并,如果小于此值则不合并,这样做可以减少段合并的频率,其默认值为 10。
SegmentSize:指段的实际大小,单位为字节。
minMergeSize:小于这个值的段会被分到一组,这样可以加速小片段的合并。
maxMergeSize:若有一段的文本数量大于此值,就不再参与合并,因为大段合并会消耗更多的资源。
3)段合并
ES对段的生成和合并采用下面这个过程进行:
当索引的时候,刷新(refresh)操作会创建新的段并将段打开以供搜索使用。
合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中。此时不会对检索产生任何影响。
此图来自ElasticSearch官网中Elasticsearch: 权威指南 » 基础入门 » 分片内部原理 » 段合并
新的段被刷新(flush)到了磁盘,并打开用来搜索,老的段被删除,合并结束。
此图来自ElasticSearch官网中Elasticsearch: 权威指南 » 基础入门 » 分片内部原理 » 段合并
6.Refresh策略
ES的index、Update、Delete、Bulk等都支持通过api refresh属性来控制文档是否可以被检索到。
1)refresh=false
refresh的默认值,更新数据之后不立刻刷新,由系统自行调度refresh的控制逻辑。
2)refresh=true或者refresh= (空)
实时刷新,即数据更新以后,立即将此数据刷新到相关的主分片和副本分片(注意不是刷新整个索引),待执行成功后,数据将会被检索到。频繁执行刷新这样的操作,会导出生成很多很多小的段文件,这也会给后期段文件的合并增加处理时间。
实时刷新主要的不足:
- 生成过多的、小的段文件;
- 搜索会由于过多的小的段文件存在,影响搜索效率;
- 后期段文件的合并,也会增加处理时间;
3)reresh=wati_for
不会立刻刷新,而是等待一段时间才刷新。使用refresh=wait_for的注意事项:
refresh=wait_for会等到刷新发生后才会响应,过多的使用会导致索引的操作效率被降低,直接的体现就是TPS上不去;
不要同时发起过多的refresh=wait_for请求,可将其通过将多个请求合并为单个bulk请求,Elasticsearch会并行处理这些请求,直到所有的请求都执行成功且等到被刷新后,再统一返回;
refresh=wait_for的监听队列是有长度限制,其受限于系统中参数index.max_refresh_listeners的配置值的影响,默认是1000,如果由于过多的refresh=wait_for请求导致该除列满了,则新的wait_for请求不能够放在该监听队列中,就只能够立即返回。由于Elasticsearch对wait_for的设计理念是只要返回了就表示已经刷新了,因而此时就会在返回前立即触发刷新操作,在响应的字段中会增加““forced_refresh”: true”这样的内容。
具体见ES7.8的官方文档:
- The more changes being made to the index the more work wait_for saves compared to true. In the case that the index is only changed once every index.refresh_interval then it saves no work.
- true creates less efficient indexes constructs (tiny segments) that must later be merged into more efficient index constructs (larger segments). Meaning that the cost of true is paid at index time to create the tiny segment, at search time to search the tiny segment, and at merge time to make the larger segments.
- Never start multiple refresh=wait_for requests in a row. Instead batch them into a single bulk request with refresh=wait_for and Elasticsearch will start them all in parallel and return only when they have all finished.
- If the refresh interval is set to -1, disabling the automatic refreshes, then requests with refresh=wait_for will wait indefinitely until some action causes a refresh. Conversely, setting index.refresh_interval to something shorter than the default like 200ms will make refresh=wait_for come back faster, but it’ll still generate inefficient segments.
- refresh=wait_for only affects the request that it is on, but, by forcing a refresh immediately, refresh=true will affect other ongoing request. In general, if you have a running system you don’t wish to disturb then refresh=wait_for is a smaller modification.
7.Segment结构
lucene包的文件是由很多segment文件组成的,segments xxx文件记录了lucene包下面的segment文件数量。每个segment会包含如下的文件。
| Name | Extension | Brief Description |
|---|---|---|
| Segment Info | .si | segment的元数据文件 |
| Compound File | .cfs, .cfe | 一个segment包含了如下表的各个文件,为减少打开文件的数量,在segment小的时候,segment的所有文件内容都保存在cfs文件中,cfe文件保存了lucene各文件在cfs文件的位置信息 |
| Fields | .fnm | 保存了fields的相关信息 |
| Field Index | .fdx | 正排存储文件的元数据信息 |
| Field Data | .fdt | 存储了正排存储数据,写入的原文存储在这 |
| Term Dictionary | .tim | 倒排索引的元数据信息 |
| Term Index | .tip | 倒排索引文件,存储了所有的倒排索引数据 |
| Frequencies | .doc | 保存了每个term的doc id列表和term在doc中的词频 |
| Positions | .pos | 全文索引的字段,会有该文件,保存了term在doc中的位置 |
| Payloads | .pay | 全文索引的字段,使用了一些像payloads的高级特性会有该文件,保存了term在doc中的一些高级特性 |
| Norms | .nvd, .nvm | 文件保存索引字段加权数据 |
| Per-Document Values | .dvd, .dvm | lucene的docvalues文件,即数据的列式存储,用作聚合和排序 |
| Term Vector Data | .tvx, .tvd, .tvf | 保存索引字段的矢量信息,用在对term进行高亮,计算文本相关性中使用 |
| Live Documents | .liv | 记录了segment中删除的doc |
五、参考文章
看完这篇还不会 Elasticsearch,我跪搓衣板!
https://mp.weixin.qq.com/s/y8DNnj4fjiS3Gqz2DFik8w
时间序列数据库的秘密 (2)——索引
https://www.infoq.cn/article/database-timestamp-02
ES索引存储原理
https://blog.csdn.net/guoyuguang0/article/details/76769184
ElasticSearch入门 第八篇:存储
https://www.cnblogs.com/ljhdo/p/5016852.html
docs-refresh
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-refresh.html
Elasticsearch详解
https://www.jianshu.com/p/28fb017be7a7
Elasticsearch: 权威指南
https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html