KDD Cup 2020多模态召回比赛季军方案与广告业务应用
ACM SIGKDD(ACM SIGKDD Conference on Knowledge Discovery and Data Mining)是世界数据挖掘领域的顶级国际会议。今年,KDD Cup共设置四个赛道共五道赛题,涉及数据偏差问题(Debiasing)、多模态召回(Multimodalities Recall)、自动化图学习(AutoGraph)、对抗学习问题和强化学习问题。
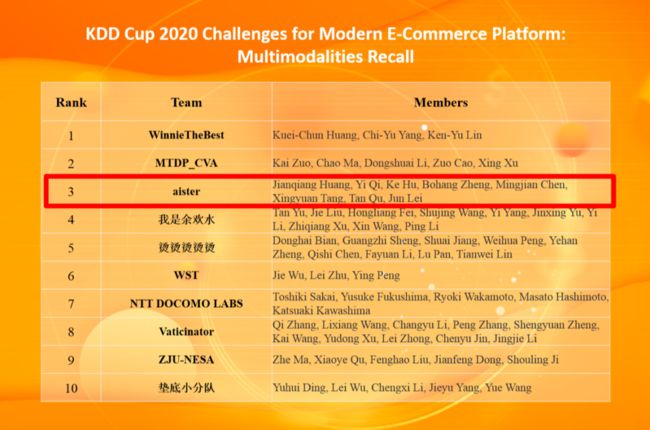
美团搜索广告算法团队最终在Debiasing赛道中获得冠军(1/1895),在AutoGraph赛道中也获得了冠军(1/149)。在Multimodalities Recall赛道中,亚军被美团搜索与NLP团队摘得(2/1433),而季军被美团搜索广告算法团队收入囊中(3/1433)。
本文将介绍多模态召回赛道季军的技术解决方案,以及在美团搜索广告业务中的应用与实践。希望能给从事相关工作的同学带来一些帮助或者启发。
背景
美团到店广告平台搜索广告算法团队基于自身的业务场景,一直在不断进行前沿技术的深入优化与算法创新,团队在图学习、数据偏差、多模态学习三个前沿领域均有一定的算法研究与应用,并取得了不错的业务结果。
基于这三个领域的技术积累,团队在KDD Cup 2020比赛中选择了三道紧密联系的赛题,希望应用并提升这三个领域技术积累,带来技术与业务的进一步突破。团队的黄坚强、胡可、漆毅、曲檀、陈明健、郑博航、雷军与中科院大学唐兴元共同组建参赛队伍Aister,参加了AutoGraph、Debiasing、Multimodalities Recall三道赛题,最终在AutoGraph赛道中获得了冠军(1/149)(KDD Cup 2020 自动图学习比赛冠军技术方案及在美团广告的实践),在Debiasing赛道中获得冠军(1/1895)(KDD Cup 2020 Debiasing比赛冠军技术方案及在美团广告的实践),并在Multimodalities Recall赛道中获得了季军(3/1433)。

要处理自然界、生活中多种模态纠缠、互补着的信息,多模态学习是必由之路。随着互联网交互形态的不断演进,多模态内容如图文、视频等越发丰富;在美团的搜索广告系统中,也体现出同样的趋势。
搜索广告算法团队利用多模态学习相关技术,已在业务上取得了不错的效果,并在今年KDD Cup的Multimodalities Recall赛道获得了第三名。本文将介绍Multimodailites Recall赛题的技术方案,以及团队在广告业务中多模态学习相关技术的应用与研究,希望对从事相关研究的同学能够有所帮助或者启发。
赛题介绍与分析
题目概述
多模态召回赛题由阿里巴巴达摩院智能计算实验室发起并组织,关注电商行业中的多模信息学习问题。2019年,全世界线上电商营收额已经达到3530亿美元。据相关预测,到2022年,总营收将增长至6540亿美元。大规模的营收和高速增长同时预示着,消费者对于电商服务有着巨大的需求。跟随这一增长,电商行业中各种模态的信息越来越丰富,如直播、博客等等。怎样在传统的搜索引擎和推荐系统中引入这些多模信息,更好地服务消费者,值得相关从业者深入探讨。
本赛道提供了淘宝商城的真实数据,包括两部分,一是搜索短句(Query)相关,为原始数据;二是商品图片相关,考虑到知识产权等,提供的是使用Faster RCNN在图片上提取出的特征向量。两部分数据被组织为基于Query的图片召回问题,即有关文本模态和图片模态的召回问题。
为方便理解,本赛道提供了少量真实图片及其对应的原始数据,下面是一个例子。该图例是一个正样例,其Query为Sweet French Dress,图片主体部分是一名身着甜美裙装的女性,主体部分以外,则有大量杂乱信息,包括一个手提包、一些气球以及一些商标和促销文字信息。赛题本身不提供原始图片,而提供的是Faster RCNN在图片上提取出的特征向量,即图片中被框出的几个部分。可见,一方面Faster RCNN提取了图片中有明显语义的内容,有助于模型学习;另一方面,Faster RCNN的提取会包含较多的框,这些框体现不出语义的主次之分。怎样利用这些框和文本相匹配,是该赛题的核心内容。
本次赛题设置的评价指标为NDCG@5。具体来说,在给定的测试集里,每条Query会给出约30个样本,其中大约6条为正样本,其余为负样本。赛题需要选手设计匹配算法,召回出任意5条正样本,即可获得该Query的全部分数,否则,按照召回的正样本条数来计算NDCG指标作为该Query的分数。全部Query的分数进行平均,即为最终得分。

数据分析和理解
本赛道提供了三份数据集,分别称为训练集、验证集和测试集。各个数据集的基本信息如下:

为进一步探索数据特点,我们将验证集给出的原始图片和特征信息做了聚合展现,下表是一组示例。

表2 搜索短语与图片的匹配正负例
根据如上探索,我们总结了数据集的三个重要特点:
-
训练集和验证集/测试集的数据特点大不相同。训练集量级显著高于验证集/测试集,足有三百万条Query-Image对,是验证集/测试集的一百倍以上。同时,训练集的每条Query-Image对均被视为正样本,这和验证集给出的一条Query下挂多个有正有负的Image截然不同。而通过对验证集原始图片和Query进行可视化探索,可见验证集数据质量很高,应该为人工标注。考虑人工标注成本和负样本的缺失,训练集有极大可能描述的是点击关系,而非人工标注的语义匹配关系。我们的解决方案中必须要考虑到训练集分布和测试集分布并不匹配这一基本特点。
-
图片信息复杂,常常包含多个物体。这些物体均被框出,作为给定特征,但各个框之间语义信息并不平等;某些是噪音,如Query(men's high collar sweater)下的墨镜、围巾、相机等框图,某些又是因商品展示需要而重复,如Query(breathable and comfortable children's shoes)下的重复鞋的框图。平均来说,一张图片有4个框,怎么将这多个框包含的语义信息去噪、综合,得到图片的整体语义表达,是建模的一个重点。
-
Query作为给定的原始文本,有着与常用语料截然不同的构造和分布情况。从示例表可见,Query并非自然语句,而是一些属性和商品实体连缀成的短语。经过统计发现,90%的Query都由3-4个单词组成;训练集有约150万的不同Query,其词表大小在15000左右;通过最后一个单词,可将全部Query归约为大约2000类,每一类都是一个具体的商品名词。我们需要考虑文本数据的这些特质,进行针对性处理。
问题挑战
本竞赛是在电商的搜索数据上的一个多模信息匹配任务。从上述数据集的三个特点出发,我们总结了该竞赛的两大主要挑战:
第一,分布不一致问题。经典统计机器学习的基础假设是训练集和测试集分布一致,不一致的分布通常会导致模型学偏,训练集和验证集效果难以对齐。我们必须依赖于已有的大规模训练集中的点击信号和小规模的和测试集同分布的验证集,设计可行的数据构建方法和模型训练流程,采取诸如迁移学习等技术,以处理这一问题。
第二,复杂多模信息匹配问题。怎么进行多模信息融合是多模态学习中的基础性问题,而怎么对复杂的多模信息进行语义匹配,是本竞赛特有的挑战。从数据看,一方面商品图片多框,信息含量大、噪点多;另一方面,用户搜索Query一般具有多个细粒度属性词,且各个词均在语义匹配中发挥作用。这就要求我们在模型设计上针对性处理图和Query两方面的复杂性,并做好细粒度的匹配。
针对这两大挑战,下面将详述搜索广告团队的解决方案。
竞赛方案
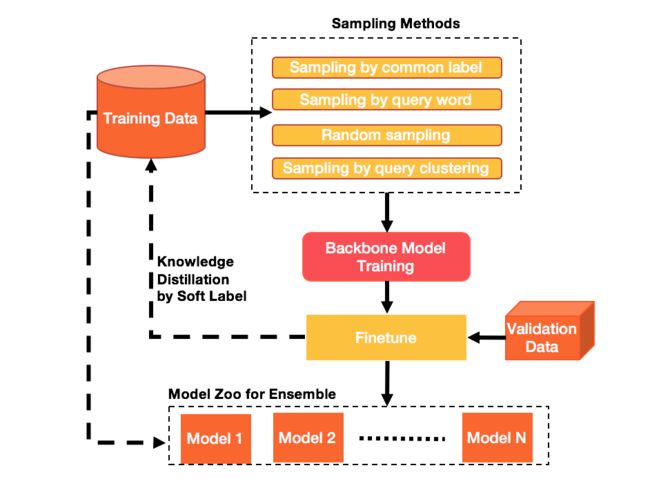
我们的方案直接回应了上述两个挑战,其主体部分包含两方面的内容,一是通过联合多样化的负采样策略和蒸馏学习以桥接训练数据和测试集的分布,处理分布不一致问题;二是采取细粒度的文本-图片匹配网络,进行多模信息融合,处理复杂多模信息匹配问题。最后,通过两阶段训练和多模融合,我们进一步提升了模型表现,整个方案的流程如下图所示。下面详述方案的各个部分。
多样负采样策略和预训练
训练集和测试集分布不一致。最直观的不一致是,训练集中只有正样本,没有负样本。我们需要设计负采样策略来构造负样本,并尽可能使得采样出的负样本靠近测试集真实分布。最直观的想法是随机采样。随机采样简单易行,但和验证集区别较大。
但分析验证集发现,对同一Query下的候选图片,通常有着紧密的语义关联。如“甜美法式长裙”这一Query下,待选的图片全是裙装,只是在款式上有不同。这说明,这一多模匹配赛题需要在较细的属性粒度上对文本和图片进行匹配。从图片标签和Query词两个角度出发, 我们可以通过相应的聚类算法,使得待采样的空间从全局细化为相似语义条目,从而达到负采样更贴近测试集分布的目的。
基于如上分析,我们设计了如下表所示的四种采样策略来构建样本集。这四种策略中,随机采样得到的正负样本最容易被区分,按Query最后一词采样得到的正负样本最难被区分;在训练中,我们从基准模型出发,先在最简单的随机采样上训练基准模型,然后在更困难的按图片标签采样、按Query的聚类采样的样本集上基于先前的模型继续训练,最后在最难的按Query最后一词采样的样本集上训练。这样由易到难、由远到近的训练方式,有助于模型收敛到验证集分布上,在测试集上取得了更好的效果。

蒸馏学习
尽管使用多种采样策略,可从不同角度去逼近测试集的真实分布,但由于未直接利用测试集信息指导负采样,这些采样策略仍有不足。因而,我们采用蒸馏学习的办法,来进一步优化负采样逻辑,以求拿到更贴近测试集的样本集分布。
如下图所示,在通过训练集负采样得到的样本集上预训练以后(第1步),我们将该模型在验证集上进一步Finetune,得到微调模型(第2步)。利用微调模型,我们反过去在训练集上打伪标签,作为Soft Label,并把Soft Label引入Loss,跟原始的0-1 Hard Label联合学习(第3步)。这样,训练集的训练上,即直接引入了验证集的分布信息,进一步贴近了验证集分布,提升了预训练模型的表现。

细粒度匹配网络
多模态学习方兴未艾,各类任务、模型层出不穷。针对我们面临的复杂图片和搜索Query匹配的问题,参照CVPR 2017的VQA竞赛的冠军方案,我们设计了如下的神经网络模型作为主模型。
该模型的设计主要考虑了如下三点:
-
利用带门全连接网络做语义映射。图片和Query处于不同语义层级,需利用函数映射到相同的语义空间,我们采取了两个全连接层的方式达到该目的。实验发现,全连接层的隐层大小是比较敏感的参数,适当增大隐层,可在不过分增加计算复杂度的情况下,显著提升模型效果。此外,如文献所述,使用带门的全连接层可进一步提升语义映射网络的效果。
-
采用双向Attention机制。图片和Query均由更细粒度的子语义单元组成。具体来说,一张图片上可能有多个框,每个框均有独立的语义信息;一个Query分为多个词,每个词也蕴含独立的语义信息。这一数据特点是由电商搜索场景决定的。因而,在模型设计时,需考虑到单个子语义单元之间的匹配。我们采用单个词和全部框、单个框和全部词双方向的注意力机制,去捕捉这些子单元的匹配关系和重要程度。
-
使用多样化多模融合策略。多模信息融合有很多手段,大部分最终归结为图片向量和Query向量之间的数学操作符。考虑到不同融合方式各有特点,多样融合能够更全面地刻画匹配关系,我们采用了Kronecker Product、Vector Concatenation和Self-Attention 三种融合方式,将经过语义空间转化和Attention机制映射后的图片向量和Query向量进行信息融合,并最终送入全连接神经网络,得到匹配与否的概率值。
此外,我们采用在训练集样本上预训练词向量的方式得到原始Query的表示,而非使用BERT模型等流行的预训练模型。这里的主要考虑是,数据分析指出,Query和常见的自然语句很不同,而更像是一组特定属性/品类名词组合在一起的短语,这和BERT等预训练模型所使用的语料有明显差异。事实上,我们初步尝试引入Glove预训练词向量等,和直接在Query文本上预训练相比,并无明显收益。再考虑到BERT模型比较笨重,不利于快速迭代,我们最终没有使用相关的语言模型技术。

多模融合
在上述技术手段的处理下,我们得到了多个基础模型。这些模型均可在验证集上进行Finetune,从而使其效果更贴近真实分布。一方面,Finetune阶段可继续使用前述的神经网络匹配模型。另一方面,前述神经网络可作为特征提取器,将其在规模较小的验证集上的输出,放入树模型重新训练。这一好处是树模型和神经网络模型异质性大,融合效果更好。最终,我们提交的结果是多个神经网络模型和树模型融合的结果。
评估结果
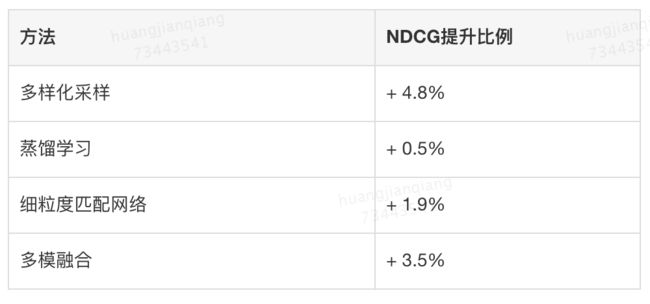
我们以随机采样训练的粗粒度(图片表示为所有框的平均,Query表示为所有词的平均)匹配网络为基准模型。下表列出了我们解决方案的各个部分在基准模型上的提升效果。
广告业务应用
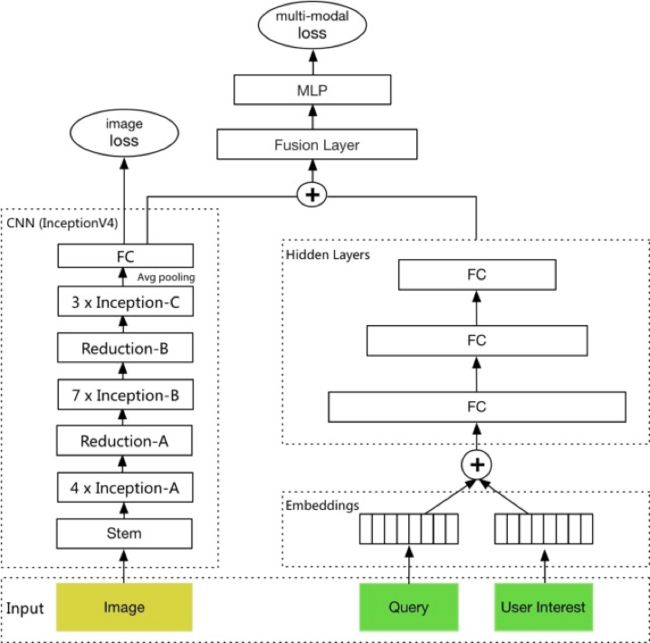
搜索广告算法团队负责美团与点评双平台的搜索广告与筛选列表广告业务,业务类型涉及餐饮、休闲娱乐、丽人、酒店等,丰富的业务类型为算法优化带来很大空间与挑战。搜索广告中的创意优选阶段,目的在通过当前搜索词或者筛选意图,为用户的每一个广告展示结果选择高质量的图片。用户的搜索词与图片在维度,表达粒度均有较大差异,我们采用多模态学习来解决这一问题,将跨模表达进行同空间映射。
如下图所示,在多模态网络中,将广告特征、请求特征、用户偏好连同图片特征作为输入,其中图片特征通过CNN网络提取图片向量表示,其他特征通过多层MLP进行交叉得到稠密向量表示,最终通过图片Loss和多模Loss两个损失函数约束模型训练。通过这样的建模方式,创意优选模型可以根据查询为不同用户的广告结果呈现最合适的图像。
搜索广告系统分为广告触发、创意优选,点击率预估(广告粒度)等模块。其中,创意优选阶段对于每个广告结果有超过十张的图片候选,线上服务的计算量是点击率预估(广告粒度)的十倍以上,对性能有更高的要求。而为了缩短耗时而减少模型复杂度又必然导致模型精度的的下降。
为了平衡模型的性能和效果,我们借鉴了知识蒸馏的思路来处理这一难题,借用了高表达能力的广告粒度预估模型。如上图7所示,左侧模型为复杂的广告粒度点击率预估模型,可以作为教师网络;右侧为简单的创意粒度优选模型,作为学生网络。学生网络的目标损失函数中,除学生网络自身输出Logit的Logloss以外,还加入了其Logit和老师网络输出Logit之间的平方误差。这一辅助Loss能够迫使学生模型的输出和老师模型的输出更接近。因此,学生模型可以学得与老师模型更接近,从而达到保持相对简单网络规模的同时、提升精度的目的。
除此以外,底层共享Embedding的设计,也使得学生模型的底层参数可得到老师模型的训练。并且,在提升精度的同时,多模块之间的一致性(例如CTR预估与创意优选)也是系统精度提高的一个关键,在目标与表达学习的Teacher-Student联合训练有利于多阶段的目标统一。基于精度提升与多阶段目标的一致性,我们取得线上业务效果较为显著的提升。

总结与展望
KDD Cup是同工业界联接非常紧密的比赛,每年赛题紧扣业界热点问题与实际问题,其中历年产出的Winning Solution对工业界有很大影响。例如,KDD Cup 2012产出了FFM (Feild-Aware Factorization Machine)与XGBoost的原型,在工业界取得广泛应用。
今年的KDD Cup主要关注在自动化图表示学习以及推荐系统等领域上。自然界的信息常常是多种模态混合的,对多模信息的处理和处理是近年来的一大研究热点。同时在工业界的搜索引擎或推荐系统中,涉及到的多模信息处理等,正变得越来越重要。特别是随着直播、短视频等业务形态的兴起,多模态学习已变得不可或缺。
本文主要介绍了KDD CUP 2020的多模态竞赛情况以及美团搜索广告算法团队的解决方案。对数据进行充分探索后,我们分析出竞赛数据的三大特点,同时定位了赛题有两大挑战,即训练集和测试集分布不一致和复杂多模信息匹配。我们通过多样化负采样策略、蒸馏学习和预训练与Finetune等技术处理了分布不一致问题,并通过细粒度匹配网络处理复杂多模信息匹配问题,两方面思路均取得了效果的显著提升。
同时,本文还介绍了多模态学习相关技术在搜索广告业务中的实际应用情况,包括创意优选模型中的图片和用户偏好联合学习、蒸馏学习在创意模型中的应用等。通过比赛高强度、快频率的迭代,团队在多模态学习方面有了更深的理解。在未来的工作中我们会基于本次比赛取得的经验,深入更多的多模态业务场景中进行分析和建模,发挥数据的价值。
参考文献
[1] Teney, Damien, et al. "Tips and tricks for visual question answering: Learnings from the 2017 challenge." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[2] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 (2015).
[3] Pennington, Jeffrey, Richard Socher, and Christopher D. Manning. "Glove: Global vectors for word representation." Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014.
[4] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[5] Zhou, Bolei, et al. "Simple baseline for visual question answering." arXiv preprint arXiv:1512.02167 (2015).
[6] Yu, Zhou, et al. "Deep modular co-attention networks for visual question answering." Proceedings of the IEEE conference on computer vision and pattern recognition. 2019.
作者简介
漆毅,坚强,胡可,雷军等,均来自美团广告平台搜索广告算法团队。
关于美团AI
美团AI以“帮人们吃得更好,生活更好”为核心目标,致力于在实际业务场景需求上探索前沿的人工智能技术,并将之迅速落地在实际生活服务场景中,完成线下经济的数字化。
美团AI诞生于美团丰富的生活服务场景需求之上,具有场景驱动技术的独特性与优势。以业务场景与丰富数据为基础,通过图像识别、语音交互、自然语言处理、配送调度技术,落地于无人配送、无人微仓、智慧门店等真实场景下,覆盖人们生活的方方面面,用科技助力用户生活质量提升,产业智能化升级乃至整个社会的生活服务新基建建设。
更多信息请访问:https://ai.meituan.com/
---------- END ----------
招聘信息
美团广告平台搜索广告算法团队立足搜索广告场景,探索深度学习、强化学习、人工智能、大数据、知识图谱、NLP和计算机视觉最前沿的技术发展,探索本地生活服务电商的价值。主要工作方向包括:
触发策略:用户意图识别、广告商家数据理解,Query改写,深度匹配,相关性建模。
质量预估:广告质量度建模。点击率、转化率、客单价、交易额预估。
机制设计:广告排序机制、竞价机制、出价建议、流量预估、预算分配。
创意优化:智能创意设计。广告图片、文字、团单、优惠信息等展示创意的优化。
岗位要求:
-
有三年以上相关工作经验,对CTR/CVR预估,NLP,图像理解,机制设计至少一方面有应用经验。
-
熟悉常用的机器学习、深度学习、强化学习模型。
-
具有优秀的逻辑思维能力,对解决挑战性问题充满热情,对数据敏感,善于分析/解决问题。
-
计算机、数学相关专业硕士及以上学历。
具备以下条件优先:
-
有广告/搜索/推荐等相关业务经验。
-
有大规模机器学习相关经验。
感兴趣的同学可投递简历至:[email protected](邮件标题请注明:广平搜索团队)。
也许你还想看
| KDD Cup 2020 Debiasing比赛冠军技术方案及在美团广告的实践
| KDD Cup 2020 自动图学习比赛冠军技术方案及在美团广告的实践
| MT-BERT在文本检索任务中的实践
