Keepalived双机热备实现nginx高可用
在我们的架构体系中,后端服务器经常会前置一台Nginx服务器做反向代理,把请求分发到后端服务器,也就是常见的负载均衡,如下

但是这里存在一个单点故障的问题,如果前置的Nginx挂掉了,请求便无法到达后端服务器,整个后端服务便不可用了

我们的解决思路是加多一台前置的nginx(nginx-2)来做负载均衡,在平时不对外提供服务。当nginx-1不可用的时,nginx-2 瞬间把nginx-1的任务接管过来,保证对外的服务不间断

那在这里我们遇到了两个问题
Q1 : nginx-1 和 nginx-2都有各自的ip地址,那我们对外服务的ip地址应该是哪一个?两台nginx之间进行切换的时候,对外的IP怎么做到固定不变?
Q2 : nginx-2 要怎么知道nginx-1是否可用?他们之间怎么去建立一套沟通机制?
Keepalived可以帮助我们解决这两个问题
什么是Keepalived
Keepalived起初是为负载均衡设计的,用于管理集群中的各个节点。
后来加入了VRRP(虚拟路由冗余协议)可以用来实现多种服务的高可用。
我们先把每个nginx节点都安装上Keepalived,再来看看它是怎么工作的。
Keepalived安装配置
1 下载源码包
cd /usr/local/src
wget https://www.keepalived.org/software/keepalived-2.0.20.tar.gz
2 解压
tar -zxvf keepalived-2.0.20
3 配置
cd keepalived-2.0.20
手动指定安装目录,不然默认会安装到/usr/local目录下,文件太零散,这里我们手动指定一下
./configure --prefix /usr/local/keepalived
4 安装
make && make install
5 为配置文件创建软链接
keepalived 启动时默认读取的配置文件是/etc/keepalived/keepalived.conf
ln -s /usr/local/keepalived/etc/keepalived /etc/keepalived
6 keepalived配置
vi /etc/keepalived/keepalived.conf
配置如下:
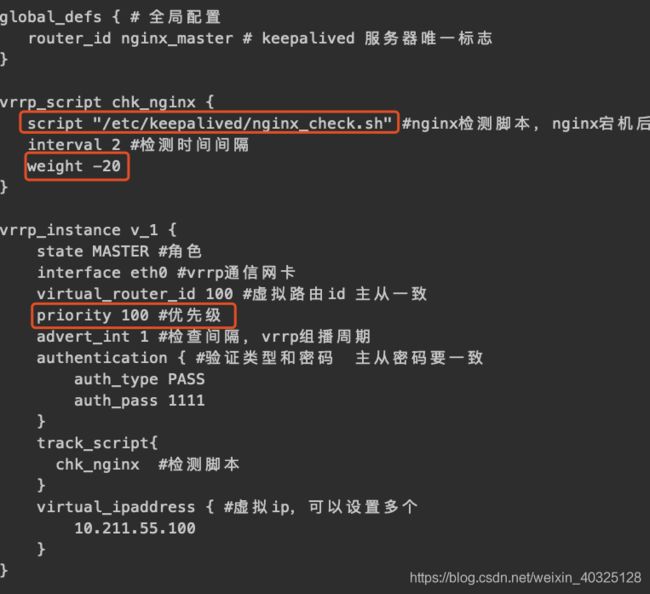
global_defs { # 全局配置
router_id nginx_master # keepalived 服务器唯一标志
}
vrrp_script chk_nginx {
script "/etc/keepalived/nginx_check.sh" #nginx检测脚本,nginx宕机后自动重启
interval 2 #检测时间间隔
weight -20
}
vrrp_instance v_1 {
state MASTER #状态,只有MASTER跟BACKUP两种,需要大写,会自动切换状态
interface eth0 #通信网卡
mcast_src_ip 10.211.55.15 #本机ip
virtual_router_id 100 #虚拟路由id 主从一致 可以用虚拟ip的最后一段
priority 100 #优先级
advert_int 1 #MASTER跟BACKUP之间健康检查间隔(vrrp组播周期)
authentication { #验证类型和密码 主从密码要一致
auth_type PASS
auth_pass 1111
}
track_script{
chk_nginx #检测脚本
}
virtual_ipaddress {
10.211.55.100 #虚拟ip,可以设置多个
}
}
这里我们对参数做一下解释:
global_defs: 全局配置
router_id: 标记该keepalived服务器
vrrp_script: vrrp脚本定义
script:脚本路径
interval:脚本运行间隔
weight:权重变化的幅度,这个在后面选举过程会用到
vrrp_instance:vrrp实例定义
state :标记该机器在整个vrrp实例中,处于什么样的角色。是MASTER(主)还是BACKUP(备),但是这只是初始化时理想的角色分配,该机器的角色是变化的,不是固定的。另外一点是,机器加入vrrp虚拟路由组时,初始角色都是BACKUP,再根据实际情况判断是是否需要调整。
virtual_router_id:虚拟路由的id ,这个需要主备保持一致,否则不生效
priority:优先级,MASTER的初始优先级应当比BACKUP要高,在选举过程中,优先级高的充当MASTER的的角色
advert_int:VRRP的组播周期,在同一个虚拟路由中,MASTER会定期向BACKUP设备发送VRRP包,告知BACKUP当前MASTER的优先级,BACKUP自行判断是否需要选举为MASTER,advert_int就是指定这个组播间隔
authentication:指定验证类型和验证密码,主备需要保持一致
track_script:指定健康监测需要运行的脚本,这里我们指定nginx的健康监测脚本
virtual_ipaddress:虚拟路由地址,这里可以根据需要指定多个
7 添加nginx检查健康脚本
vi /etc/keepalived/nginx_check.sh
内容如下
#!/bin/bash
A=`ps -C nginx --no-header|wc -l`
if [ $A -eq 0 ];then
exit 1
#/usr/local/nginx/sbin/nginx
#sleep 2
#if [ `ps -C nginx --no-header|wc -l` -eq 0 ];then
#systemctl stop keepalived
#fi
else
exit 0
fi
大意就是检查nginx进程是否还存在,不存在的话状态码为1,keepliaved会用到这个状态码
用#注释掉的部分是尝试将nginx进程启动,如果重启失败杀死keepalived进程。为了方便演示,先把重启nginx这部分注释掉
8 把keepalived 加入到开机启动项
systemctl enable keepalived
9启动keepalived
systemctl start keepalived
检查是否启动成功
ps -ef | grep keepalived
这么一来,keepalibved 我们就安装配置好了
当我们把两台nginx服务器上安装的keepalived启动后,会产生一个虚拟的ip(VIP)10.211.55.100,此时作为MASTER的nginx-1拥有这个vip,外部通过这个虚拟IP来访问,不在使用10.211.55.15

请求是怎么到达nginx-1这台机器上的
请求经过路由,路由如果发现没有10.211.55.100这个IP的arp映射,向局域网内机器发送arp包等待返回,nginx-1返回10.211.55.100和mac地址的映射,路由将其缓存,方便下次访问,并将请求指向nginx-1
keepalived故障转移是怎么实现的
我们一起来看看在整个生命周期中,keepalived是怎么工作的。
我们分别将两台机器 15、16上的nginx启动,再把keepalived分别启动起来
我们15这台的keepalibved的优先级配置的是100, 16这台优先级配置的是90
因此当我们两台的keepalived都启动之后,15这台就优先占有了10.211.55.100这个ip
我们看看启动keepalived时,都做了些什么操作
当我们先启动15这台的keepalived时
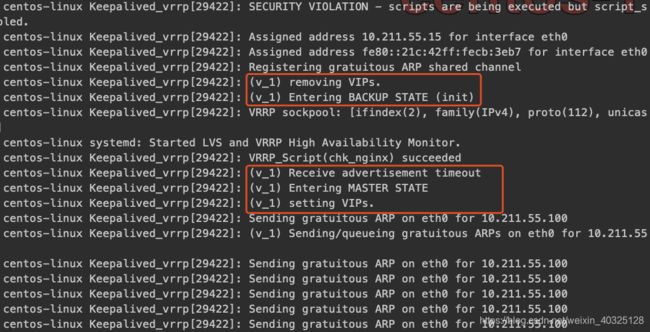
在keepalived启动时,默认会将自身先定义为BACKUP,等待MASTER节点的VRRP包,直到等待超时,才会进入MASTER状态,设置VIP,发起组播。
而16这台优先级有90的在启动过程中就没有转为MASTER,因为它收到的优先级比自己高

我们访问可以看到此时该IP被15占有

此时我们将15机器(MASTER)上的nginx进程杀掉
killall nginx
从keepalived的日志中可以看到,优先级由100降到80,并且收到路由组内一个更高的优先级90,MASTER进入BACKUP状态,移除VIP

不是只有MASTER能发组播吗?那15节点收到的组播包是哪来的?
我们来看16(原来的BACKUP)的日志
可以看到BACKUP收到MASTER的组播VRRP包,发现MASTER的优先级比自己低,立马进入MASTER状态,设置VIP,并开始组播,之前的MASTER收到组播,转为BACKUP
此时我们访问该IP,可以发现该IP被nginx-2占有
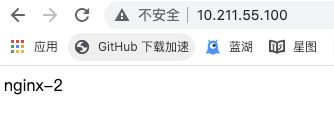
总结:
keepalived 同一个虚拟路由组内,MASTER通过VRRP协议向其他成员发送数据包,内容是自身优先级,其他BACKUP成员如果发现自身的优先级比MASTER高,就会转为MATSER,并设置VIP,向其他节点组播VRRP包,原来的MASTER节点接收到的优先级比自身高,就会转为BACKUP状态
优先级是怎么进行变动的?
每个keepalived实例都有一个初始化的优先级priority
根据服务健康状态检测脚本的不同状态值,动态改变当前实例的优先级,变动幅度是设置的weight权重值
具体的脚本上面安装过程中有
脚本的状态值,1代表失败,0代表成功,
当设置的weight > 0时,脚本返回值如果是0,优先级调整为priority = priority + weight
,脚本返回值如果是1,优先级不变
当设置的weight < 0时,脚本返回值如果是1,优先级调整为priority = priority + weight,脚本返回值如果是0,优先级不变
这里看起来有点绕,所以建议大家weight设置为负数,并且weight的绝对值要大于初始化时节点间的优先级差值。