电商双11美妆数据分析
电商双11美妆数据分析
1、数据初步了解
import numpy as np
import pandas as pd
df = pd.read_csv('双十一淘宝美妆数据.csv')
df.head() #查看数居前五行

df.info() #查看数据特征
df.shape #查看数据量
df.describe() #查看各数字类型特征的一些统计量

2.数据清洗
2.1 重复值处理
直接删除重复值。
data = df.drop_duplicates(inplace = False)##去重
data.reset_index(inplace = True,drop = True)##重置行索引
data.shape
可以得出有86条重复数据,删除后得到新的数据
2.2 缺失值处理
data.loc[data['sale_count'].isnull()].head()

data.loc[data['comment_count'].isnull()].tail()

##填补缺失值
data=data.fillna(0) #用0填补缺失值
data.isnull().any() #查看是否还有空值
2.3 数据挖掘寻找新的特征
##使用jieba包对title进行分词,进一步了解每一个商品的特征
import jieba
subtitle=[]
for each in data['title']:
k=jieba.lcut_for_search(each) ##搜索引擎模式
subtitle.append(k)
data['subtitle']=subtitle
data[['title','subtitle']].head()

# 给商品添加分类
sub_type = [] #子类别
main_type = [] #主类别
basic_data = """护肤品 乳液类 乳液 美白乳 润肤乳 凝乳 柔肤液 亮肤乳 菁华乳 修护乳
护肤品 眼部护理类 眼霜 眼部 眼膜
护肤品 面膜类 面膜
护肤品 清洁类 洗面 洁面 清洁 卸妆 洁颜 洗颜 去角质 磨砂
护肤品 化妆水 化妆水 爽肤水 柔肤水 补水露 凝露 柔肤液 精粹水 亮肤水 润肤水 保湿水 菁华水 保湿喷雾 舒缓喷雾
护肤品 面霜类 面霜 日霜 晚霜 柔肤霜 滋润霜 保湿霜 凝霜 日间霜 晚间霜 乳霜 修护霜 亮肤霜 底霜 菁华霜
护肤品 精华类 精华液 精华水 精华露 精华素 精华
护肤品 防晒类 防晒
护肤品 补水类 补水
化妆品 口红类 唇釉 口红 唇彩 唇膏
化妆品 底妆类 散粉 蜜粉 粉底液 定妆粉 气垫 粉饼 BB CC 遮瑕 粉霜 粉底膏 粉底霜
化妆品 眼部彩妆 眉粉 染眉膏 眼线 眼影 睫毛膏 眉笔
化妆品 修容类 鼻影 修容粉 高光 腮红"""
##主观的分类,不在这些类别里的并入其他类。第一列是大类,第二列是小类,后面都是关键词
dcatg={
}
catg=basic_data.split('\n')
for i in catg:
main_cat=i.strip().split('\t')[0]
sub_cat=i.strip().split('\t')[1]
o_cat=i.strip().split('\t')[2:len(catg)]
for j in o_cat:
dcatg[j]=(main_cat,sub_cat)
dcatg
##分类字典
给出各个关键词的分类类别
sub_type = [] #主类
main_type = [] #次类
for i in range(len(data)):
exist = False
for j in data['subtitle'][i]:
if j in dcatg:
sub_type.append(dcatg[j][1])
main_type.append(dcatg[j][0])
exist = True
break
if not exist :
sub_type.append('其他')
main_type.append('其他')
data['sub_type']=sub_type
data['main_type']=main_type
data.loc[data['sub_type'] == '其他'].count() ##查看分类为其他的有多少商品
由title新生成两列类别
对是否是男性专用进行分析并新增一列
sex=[]
for i in range(len(data)):
if '男士' in data['subtitle'][i] :
sex.append('是')
elif '男生' in data['subtitle'][i] :
sex.append('是')
elif '男' in data['subtitle'][i] and '女' not in data['subtitle'][i] and '斩男' not in data['subtitle'][i]:
sex.append('是')
else :
sex.append('否')
data['是否男士专用']=sex
data.loc[data['是否男士专用'] == '是'].head()
data['是否男士专用'].value_counts()
对每个产品总销量新增销售额这一列
data['销售额'] = data.price * data.sale_count
data.head()
3.数据分析及可视化
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif'] = [u'SimHei'] ##显示中文,设置字体
plt.rcParams['axes.unicode_minus'] = False ##显示符号
plt.figure(figsize = (12,10))
# 各店铺的商品数量
plt.subplot(2,2,1)
plt.tick_params(labelsize=15)
data['店名'].value_counts().sort_values().plot.bar()
plt.title('各品牌商品数',fontsize = 20)
plt.ylabel('商品数量',fontsize = 15)
plt.xlabel('店名')
# 各店铺的销量
plt.subplot(2,2,2)
plt.tick_params(labelsize=15)
data.groupby('店名').sale_count.sum().sort_values().plot.bar()
plt.title('各品牌所有商品的销量',fontsize = 20 )
plt.ylabel('商品总销量',fontsize = 15)
#各店铺总销售额
plt.subplot(2,2,3)
plt.tick_params(labelsize=15)
data.groupby('店名')['销售额'].sum().sort_values().plot.bar()
plt.title('各品牌总销售额', fontsize = 20)
plt.ylabel('商品总销售额' , fontsize = 15)
#旋转显示plt.xticks(rotation=45)
##补充绘图,挖掘数据,各品牌的平均每单单价,三个销量为0的品牌暂时不考虑
plt.subplot(2,2,4)
plt.tick_params(labelsize = 15)
avg_price=data.groupby('店名')['销售额'].sum()/data.groupby('店名').sale_count.sum() ###每个品牌售出的商品的平均单价
avg_price.sort_values().plot.bar()
plt.title('各品牌平均每单单价', fontsize = 20)
plt.ylabel('售出商品的平均单价' , fontsize = 15)
##自适应调整子图间距
plt.tight_layout()

通过图表不难看出以下几点:
悦诗风吟的商品数量遥遥领先,然而其商品销量只排在第三位,总销售额只排在第五位。
SKII,玉兰油,植村秀商品数量大概都在500-1500的范围,而销量为0。
相宜本草商品数量也只属于中游,但其销量销售额均排在第一位,由于其销量是第二名的大约两倍,而销售额远不到两倍,所以销售额/销量,也就是每一单的均价也是一个值得研究的新指标。
通过加入平均每单单价之后,观察销售额较高的几个品牌相宜本草,欧莱雅,佰草集,悦诗风吟,雅诗兰黛。其中相宜本草,悦诗风吟,欧莱雅都是平均单价200元以下的,佰草集为200-300元区间,雅诗兰黛为大于500元区间。是否能够判断价格亲民的品牌的销售额会相对来说更高?下面根据这里的数据先把平均单价分为几个区间,其中0-100元记为A类,100-200元记为B类,200-300元记为C类,300元及以上记为D类。
A=avg_price[(avg_price <= 100) & (avg_price > 0) ].index
B=avg_price[(avg_price <= 200) & (avg_price > 100) ].index
C=avg_price[(avg_price <= 300) & (avg_price > 200) ].index
D=avg_price[avg_price > 300 ].index
#四类ABCD分别代表0-100,100-200,200-300,300以上平均单价区间的各品牌
sum_sale=data.groupby('店名')['销售额'].sum()
plt.figure(figsize = (16,8))
plt.tick_params(labelsize=10)
###各类、各品牌的销售额占比
plt.subplot(1,2,1)
sum_sale_byprice=sum_sale[A].sort_values().append(sum_sale[B].sort_values()).append(sum_sale[C].sort_values()).append(sum_sale[D].sort_values())
plt.pie(x=sum_sale_byprice,labels =sum_sale_byprice.index ,colors = ['grey']*len(A)+['g']*len(B)+['y']*len(C)+['m']*len(D),autopct='%0f%%',pctdistance=0.9)
###各类的平均每个店销售额
plt.subplot(1,2,2)
plt.tick_params(labelsize = 15)
plt.bar('均价0-100元',np.mean(sum_sale[A]),color = 'grey')
plt.bar('均价100-200元',np.mean(sum_sale[B]),color = 'g')
plt.bar('均价200-300元',np.mean(sum_sale[C]),color = 'y')
plt.bar('均价300元以上',np.mean(sum_sale[D]),color = 'm')
plt.title('不同类别的平均每个店销售额',fontsize = 20)
plt.ylabel('平均销售额',fontsize = 20)
plt.tight_layout()
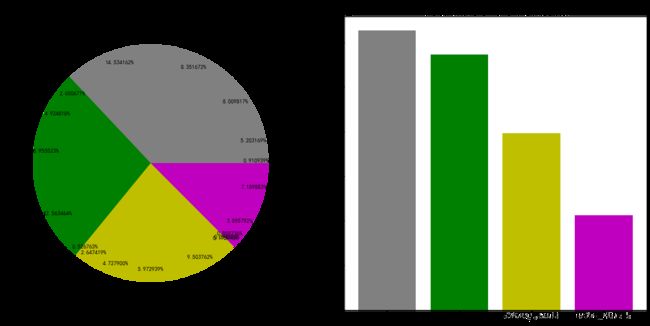
观察饼图,不难发现A类平均单价的品牌所占的销售额比例最高,D类最少,并且D类中的一半以上收入都来自于雅诗兰黛品牌,而最受欢迎的相宜本草由于其价格便宜,销售额也最高。综合分析来说,在价格方面,价格越高的一般来说销量就会越低,反之亦有所相似之处。销量前四的品牌都属于A类,而属于D类的五个品牌销量都在最后七名之中。但
收益来说也有很大的区别。从每个类中每个店的平均销售额也能看出,定价越低则平均销售额越高。
比如A类中的美加净,销售额很低,观察分析其是平均单价最低的品牌,而且销量也并不算高,所以可以考虑几点:1.商品质量问题,虽然便宜但是是否产品质量过低降低了用户使用体验?2.知名度问题,是否需要提高知名度获取更多点击率以提高销量?3.定价问题,在质量过关的前提下,是否因为定价过低而降低了收益?能否在不大幅影响销量的情况下涨价?
事实上,D类中,也就是高端商品中,雅诗兰黛占据了主要份额,一方面可能由于品牌效应,就个人主观的分析,雅诗兰黛为人熟知,在推广营销方面做的很好,所以销量尚可。另一方面,可能雅诗兰黛虽然相对价格较高,但是给使用者带来的使用体验非常好,所以很多消费者宁愿多花钱也要选择雅诗兰黛。这也可能是雅诗兰黛平均单价最高,然而销量却在D类中也最高的原因。
接下来考虑各个类别的销售情况
#大类销售量、销售额的占比
plt.figure(figsize = (12,12))
#销售量
plt.subplot(2,2,1)
data.groupby('main_type').sale_count.sum().plot.pie(autopct = '%0f%%',title = '各大类销售量占比')
#销售额
plt.subplot(2,2,2)
data.groupby('main_type')['销售额'].sum().plot.pie(autopct = '%0f%%',title = '各大类销售额占比')
#小类销售量、销售额的占比
plt.subplot(2,2,3)
data.groupby('sub_type').sale_count.sum().plot.pie(autopct = '%0f%%',title = '各小类销售量占比')
plt.subplot(2,2,4)
data.groupby('sub_type')['销售额'].sum().plot.pie(autopct = '%0f%%',title = '各小类销售额占比')
plt.tight_layout()

通过观察比较各个类销售量与销售额占比的关系,基本可以判断他们是正相关的。这也是符合常识的。
在大类中,护肤品的销量远胜化妆品以及其他商品。而在小类之中,清洁类的护肤品销量最高,其次是补水类的护肤品。
接下来用seaborn包给出每个店铺各个大类以及各个小类的销量销售额
##为了减少图形复杂度,先去掉总销量为0的店铺,分别为SKII,植村秀,玉兰油
data1 = data.drop(index = data[data['店名'].isin(data.groupby('店名').sale_count.sum()[data.groupby('店名').sale_count.sum() == 0].index)].index)
data1['店名'].value_counts()
import seaborn as sns
plt.figure(figsize = (16,12))
plt.subplot(2,1,1)
plt.tick_params(labelsize = 10)
sns.barplot(x = '店名', y = 'sale_count', hue = 'main_type' ,estimator=np.sum, data = data1 , ci = 0) ####estimator参数表示取该列的什么值
plt.title('各店铺中各大类的销售量',fontsize = 20)
plt.ylabel('销量',fontsize = 15)
plt.subplot(2,1,2)
plt.tick_params(labelsize = 10)
sns.barplot(x = '店名', y = '销售额', hue = 'main_type' ,estimator=np.sum, data = data1 , ci = 0)
plt.title('各店铺中各大类的销售额',fontsize = 20)
plt.ylabel('销售额',fontsize = 15)
plt.tight_layout()

plt.figure(figsize = (16,12))
plt.subplot(2,1,1)
plt.tick_params(labelsize = 10)
sns.barplot(x = '店名', y = 'sale_count', hue = 'sub_type' ,estimator=np.sum, data = data1 , ci = 0)####estimator参数取该列的什么值
plt.title('各店铺中各小类的销售量',fontsize = 20)
plt.ylabel('销量',fontsize = 15)
plt.subplot(2,1,2)
plt.tick_params(labelsize = 10)
sns.barplot(x = '店名', y = '销售额', hue = 'sub_type' ,estimator=np.sum, data = data1 , ci = 0)
plt.title('各店铺中各小类的销售额',fontsize = 20)
plt.ylabel('销售额',fontsize = 15)
plt.tight_layout()

先观察销量,各店小类中销量最高的是相宜本草的补水类商品以及妮维雅的清洁类商品,这两类销量很接近。而销售额上,相宜本草的补水类商品比妮维雅的清洁类商品要高得多,这显然是商品平均单价不同所导致的。由于不同的类别使用量也不同,销量自然也会有所区别,所以相对于比较每个店铺的不同类别的销售量,比较每个不同类别的各店铺的销售量应该更有价值。
plt.figure(figsize = (16,12))
plt.subplot(2,1,1)
plt.tick_params(labelsize = 10)
sns.barplot(x = 'sub_type', y = 'sale_count', hue = '店名' ,estimator=np.sum, data = data1 , ci = 0)####estimator参数取该列的什么值
plt.title('各小类中各店铺的销售量',fontsize = 20)
plt.ylabel('销量',fontsize = 15)
plt.subplot(2,1,2)
plt.tick_params(labelsize = 10)
sns.barplot(x = 'sub_type', y = '销售额', hue = '店名' ,estimator=np.sum, data = data1 , ci = 0)
plt.title('各小类中各店铺的销售额',fontsize = 20)
plt.ylabel('销售额',fontsize = 15)
plt.tight_layout()

事实上可以看出相宜本草在面霜、乳液、精华、补水、化妆水、眼部护理以及防晒类中都是销量最高的。美宝莲在口红、眼部彩妆也都是卖的最好的。而妮维雅在清洁类中一骑绝尘。在这里我们就可以用上之前提取出的新特征-是否男性专用。因为清洁类显然是有男性市场的。
关于性别
接下来考虑性别因素,了解各类产品在男性消费者中的销量占比
plt.figure(figsize = (16,16))
#男士专用中各类销量占比
plt.subplot(2,2,1)
data.loc[data['是否男士专用'] == '是'].groupby('sub_type').sale_count.sum().plot.pie(autopct = '%0f%%',title = '男士各小类销售量占比', pctdistance=0.8)
#非男士专用中各类销量占比
plt.subplot(2,2,2)
data.loc[data['是否男士专用'] == '否'].groupby('sub_type').sale_count.sum().plot.pie(autopct = '%0f%%',title = '非男士专用各小类销售量占比', pctdistance=0.8)
#男士专用销售量占总销售量
plt.subplot(2,2,3)
data.groupby('是否男士专用').sale_count.sum().plot.pie(autopct = '%0f%%',title = '男士专用销售量占比', pctdistance=0.8)
#男士专用销售额占总销售额
plt.subplot(2,2,4)
data.groupby('是否男士专用')['销售额'].sum().plot.pie(autopct = '%0f%%',title = '男士专用销售额占比', pctdistance=0.8)
plt.tight_layout()

与之前的饼图相比,能发现:
1:男士的销量基本来自于清洁类,其次是补水类。而这两类正是总销量中占比最高的两类。
2:非男士专用中,补水类成为了销量最高的类别,清洁类降到了第二位。
3:男士专用的销量以及销售额占比都比较低。
显然,在没有区分性别的情况下,由于清洁类是男性女性通用,所以占得销量最高是理所应当的。而非男士专用中,女性消费者较多,所以补水类一跃成为最高销量。尽管就整个销量而言,男士专用的占比不高,但是这也说明男性市场是一个值得发展急需拓宽的点。如果增加更多关于男性护肤品的推广,有可能会吸引更多的男性消费者从而增加销量。所以进一步分析,各个店铺的男性专用商品的销量。
male_data = data1.loc[data['是否男士专用'] == '是']
plt.figure(figsize = (12,8))
sns.barplot(x = '店名', y = 'sale_count', hue = 'main_type' ,estimator=np.sum, data = male_data , ci = 0)
plt.title('各店男士专用商品销量',fontsize = 15)
plt.ylabel('销量',fontsize = 10)
plt.tight_layout()

男士专用护肤品的销售量前三名分别是:妮维雅,欧莱雅,相宜本草。所有男士商品主要销量来自于护肤品。对于其他类这里暂时不进行分析,因为其产生大概率是basic_data也就是我们的分类集不完善导致的。观察一下男用化妆品的数据,如下:
male_data[male_data.main_type == '化妆品'].head()
可以看出基本都是男用唇膏。因为将唇膏归于了口红类,而口红类归于了化妆品类。接下来看看各个店铺的男士专用商品的总销量销售额是怎样的
plt.figure(figsize = (16,12))
plt.subplot(2,2,1)
plt.tick_params(labelsize = 15)
male_data.groupby('店名').sale_count.sum().sort_values(ascending = True).plot.bar()
plt.title('各店男士专用商品销量', fontsize = 15)
plt.ylabel('销量', fontsize = 15)
plt.subplot(2,2,2)
plt.tick_params(labelsize = 15)
male_data.groupby('店名')['销售额'].sum().sort_values(ascending = True).plot.bar()
plt.title('各店男士专用商品销售额', fontsize = 15)
plt.ylabel('销售额', fontsize = 15)
###非男性专用
fmale_data = data1.loc[data['是否男士专用'] == '否']
plt.subplot(2,2,3)
plt.tick_params(labelsize = 15)
fmale_data.groupby('店名').sale_count.sum().sort_values(ascending = True).plot.bar()
plt.title('各店非男士专用商品销量', fontsize = 15)
plt.ylabel('销售量', fontsize = 15)
plt.subplot(2,2,4)
plt.tick_params(labelsize = 15)
fmale_data.groupby('店名')['销售额'].sum().sort_values(ascending = True).plot.bar()
plt.title('各店非男士专用商品销售额', fontsize = 15)
plt.ylabel('销售额', fontsize = 15)
plt.tight_layout()

不难看出,欧莱雅和妮维雅占据了男性专用商品的绝大部分市场,不管是销量还是销售额。这一点在不区分是否男性专用的商品中是有所出入的。欧莱雅在无论在哪个方面都表现的很好,虽然销量在非男士专用商品里属于一般水平,但销售额都名列前茅。而妮维雅在非男士专用商品里的销售情况就很差了,这说明妮维雅主打的就是男士专用商品。而相宜本草在非男士专用商品的表现还是遥遥领先,其在男士专用商品中也排在第三位,虽然和前两名都有比较大的差距。
关于时间
from datetime import datetime
plt.figure(figsize = (12,12))
sale_day=data.groupby('update_time').sale_count.sum()
sale_day.index = [datetime.strptime(i, '%Y/%m/%d') for i in sale_day.index] ###将update_time转换为datetime数据否则plot函数无法识别排序
####每天的销量
plt.subplot(2,1,1)
plt.tick_params(labelsize = 15)
sale_day.plot()
plt.grid(linestyle = '-.')
plt.title('每日销售量',fontsize = 15)
plt.ylabel('销量', fontsize =10)
###每天的销售额
r_day=data.groupby('update_time')['销售额'].sum()
r_day.index = [datetime.strptime(i, '%Y/%m/%d') for i in r_day.index]
plt.subplot(2,1,2)
plt.tick_params(labelsize = 15)
r_day.plot()
plt.grid(linestyle = '-.')
plt.title('每日销售额',fontsize = 15)
plt.ylabel('销售额', fontsize =15)
plt.tight_layout()

观察两个折线图,其走势是相同的,因为整个销量与销售额应该是成正相关的。图形有如下特点:
在9日单日销售量达到峰值,而在11日达到最小
10日之前的波动趋势相对稳定,在11日有一个急剧的下降
11日过后又开始缓慢的增长。由于统计的日期有限,无法判断这种趋势是长期的还是短期的。
那么,双11活动反而在双11当天的销量有剧烈的下滑,其原因大概率是双11的预热、预售活动等等。在临近双11时,9日销量达到最高,因为更临近了,所以关注的人更多,购买的人更多。但是在10日有所下降,和双11下降有相同的理由,是人们都主观的认为双11当天的购买人数太多,可能会有网络、平台卡顿导致无法成功下单的忧虑,所以反而造成了双11当天销量急剧下滑。而双11过后又开始有了销量增长,有可能是店铺持续优惠,比如赠送满减卷,让许多已经消费过的消费者再次消费。
对评论数进行分析
plt.figure(figsize = (16,6))
plt.subplot(1,2,1)
data.groupby('店名').comment_count.sum().sort_values().plot.bar()
plt.title('每个店铺总评论数')
plt.subplot(1,2,2)
(data1.groupby('店名').sale_count.sum()/data1.groupby('店名').comment_count.sum()).sort_values().plot.bar()
plt.title('每个店铺平均多少单一条评论')
plt.tight_layout()

悦诗风吟的评论数远高于其他。而前面的分析中,悦诗风吟的所有商品数量是第一名,但其销量只在第三位。反观相宜本草,销量远高于其他,然而评论数相对销量却过低。所以我们考虑一个新的指标:每个店铺平均每多少单能得到一条评论。这个指标上,相宜本草和蜜丝佛陀最高。而理论上,销量与评论应该是一个正比的关系。这些平均多少单一条评论的指标能否反映店铺存在水军刷单的问题?相宜本草的该指标为28左右,而大多数品牌都在5-10左右,相宜本草是其他的大概4倍。所以是否可以推论,该指标过高的店铺存在刷单,刷销量的行为。如果能获得更详细的数据,例如好评率,好评格式等等,这也是一个可以探讨的问题。
总结分析
平均每单价格低的店铺的总销量、销售额都高于均价更高的。价格便宜是消费者考虑的最多的一个点。销量最高的相宜本草的均价就很低,同时它的销售额也是最高额的。而均价较高的类中,只有雅诗兰黛的销售额相对客观。对于一些中高端商品,可以考虑适当降价来吸引更多消费者。而一些低端商品可以考虑多推广来提高知名度获取销量。
所有大类中,护肤品类的销量最高,其次是化妆品类。所有小类中,清洁类、补水类分别是销量的前二名。
男士专用的商品中,护肤品销量最高,而化妆品类中主要是唇膏。并且妮维雅占据了男士专用的大部分市场。
平均每多少单一条评论这个指标,相宜本草过高了,是评论数最多的悦诗风吟的4倍。可能存在刷单等现象。
不同的日期销量也不同。在双11销量反而有一个剧烈的下滑。原因可能是预热活动导致了消费者提前消费,并且由于消费者往往会主观的考虑到双11当天的网络、平台会卡顿,一般都会提前下单来避免“高峰”,虽然这个高峰并不存在。而在双11之后销量又有了小幅度的增长,可能跟商家的持续优惠等各种活动有关。所以商家应该把目光放在双11之前,尽量的吸引消费者消费来增加销量,不要局限于双11当天。在双11之后可以通过类似双11购物返满减卷,来刺激二次消费。