第三周【任务1】学习支持向量机(打卡)
**任务标题:**学习花书5.7.2-5.7.3章,看LDA、SVM两个视频
**任务简介:**学习支持向量机,其他监督学习算法 (视频LDA,SVM)
详细说明:
1.支持向量机
- 对于一个线性可分的数据集,定义样本到分割超平面的最短距离为间隔。间隔越大,分割超平面对两个类别的划分越稳定,不容易受噪声影响。支持向量机的目标即寻找间隔最大的超平面。
- 寻找最大间隔分割超平面可写为一个凸优化问题,根据KKT条件求解。
- 支持向量机的最优决策函数可重写为输入向量与各支持向量的内积求和。用核函数代替内积,可隐式地将样本从原始特征空间映射到更高维的空间,解决原始特征空间中的线性不可分问题。
- 常见的核函数包括高斯核,又称radial basis function (RBF)核。
- LDA
- 理解类间方差和类内方差,LDA损失函数
学习目标:
a. 监督学习:SVM,LDA
b.了解支持向量机的动机
c. 掌握支持向量机算法
d.了解如何通过核函数解决线性不可分问题
e.理解LDA与PCA的不同
打卡内容:
问题一:
假设我们要学习一个硬间隔SVM, 其线性决策函数为 w ⊤ x + b = 0 \mathbf{w}^{\top} \mathbf{x}+b=0 w⊤x+b=0. 输入特征为 x 1 , x 2 x_1, x_2 x1,x2,标签 y ∈ { − 1 , + 1 } y \in\{-1,+1\} y∈{ −1,+1}
分别用 △ \triangle △和 ∘ \circ ∘表示。如图
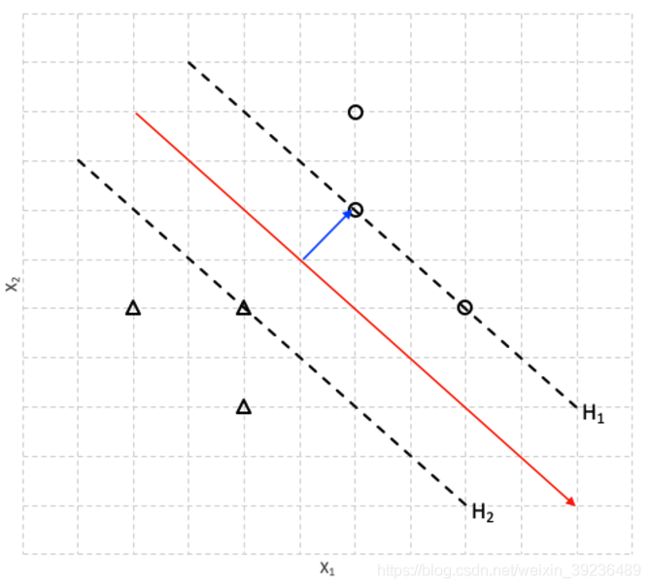
1. 根据最大间隔原则,在图中标出支持向量,并大致画出对应的分割超平面。
2. 若超平面 H 1 H_1 H1的表达式是 w ⊤ x + b = 1 \mathbf{w}^{\top} \mathbf{x}+b=1 w⊤x+b=1,写出超平面 H 2 H_2 H2表达式
w ⊤ x + b = − 1 \mathbf{w}^{\top} \mathbf{x}+b=-1 w⊤x+b=−1
3.线性硬间隔支持向量机的限制可以写作 y i ( w ⊤ x i + b ) ≥ 1 , ∀ i ∈ { 1 , … , N } y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{\mathbf{i}}+b\right) \geq 1, \forall i \in\{1, \ldots, N\} yi(w⊤xi+b)≥1,∀i∈{ 1,…,N},解释其原因
首先我们设点 x 0 x_0 x0到超平面的距离为 r r r,在超平面上的投影为 x 1 x_1 x1, 那么法向量 w w w一定与向量 x 1 x 0 → \overrightarrow{\boldsymbol{x_{1}} \boldsymbol{x_{0}}} x1x0平行,此时若考虑求两个向量内积的绝对值可得
∣ w T ⋅ x 1 x 0 → ∣ = ∥ w ∥ ⋅ ∣ ± 1 ∣ ⋅ ∥ x 1 x 0 → ∥ = ∥ w ∥ ⋅ r \left|\boldsymbol{w}^{\mathrm{T}} \cdot \overrightarrow{\boldsymbol{x}_{1} \boldsymbol{x}_{0}}\right|=\|\boldsymbol{w}\| \cdot|\pm 1| \cdot\left\|\overrightarrow{\boldsymbol{x}_{1} \boldsymbol{x}_{0}}\right\|=\|\boldsymbol{w}\| \cdot r ∣∣∣wT⋅x1x0∣∣∣=∥w∥⋅∣±1∣⋅∥∥∥x1x0∥∥∥=∥w∥⋅r
又因为
w T ⋅ x 1 x 0 → = w 1 ( x 0 1 − x 1 1 ) + w 2 ( x 0 2 − x 1 2 ) + … + w n ( x 0 n − x 1 n ) = w 1 x 0 1 + w 2 x 0 2 + … + w n x 0 n − ( w 1 x 1 1 + w 2 x 1 2 + … + w n x 1 n ) = w 1 x 0 1 + w 2 x 0 2 + … + w n x 0 n − ( − b ) = w 1 x 0 1 + w 2 x 0 2 + … + w n x 0 n + b = w T x 0 + b \begin{aligned} \boldsymbol{w}^{\mathrm{T}} \cdot \overrightarrow{\boldsymbol{x}_{1} \boldsymbol{x}_{0}} &=w_{1}\left(x_{0}^{1}-x_{1}^{1}\right)+w_{2}\left(x_{0}^{2}-x_{1}^{2}\right)+\ldots+w_{n}\left(x_{0}^{n}-x_{1}^{n}\right) \\ &=w_{1} x_{0}^{1}+w_{2} x_{0}^{2}+\ldots+w_{n} x_{0}^{n}-\left(w_{1} x_{1}^{1}+w_{2} x_{1}^{2}+\ldots+w_{n} x_{1}^{n}\right) \\ &=w_{1} x_{0}^{1}+w_{2} x_{0}^{2}+\ldots+w_{n} x_{0}^{n}-(-b) \\ &=w_{1} x_{0}^{1}+w_{2} x_{0}^{2}+\ldots+w_{n} x_{0}^{n}+b=\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{0}+b \end{aligned} wT⋅x1x0=w1(x01−x11)+w2(x02−x12)+…+wn(x0n−x1n)=w1x01+w2x02+…+wnx0n−(w1x11+w2x12+…+wnx1n)=w1x01+w2x02+…+wnx0n−(−b)=w1x01+w2x02+…+wnx0n+b=wTx0+b
【可以理解 x 0 \boldsymbol{x_0} x0这个从坐标原点为起点的向量先投影在法向量 w \boldsymbol{w} w上,然后减去 b b b这个原点到超平面的距离,就得到了 x 1 x 0 → \overrightarrow{\boldsymbol{x_{1}} \boldsymbol{x_{0}}} x1x0在法向量上的投影长度】
所以
∣ w T ⋅ x 1 x 0 ‾ ∣ = ∣ w T x 0 + b ∣ = ∥ w ∥ ⋅ r ⇒ r = ∣ w T x + b ∣ ∥ w ∥ \left|\boldsymbol{w}^{\mathrm{T}} \cdot \overline{\boldsymbol{x}_{1} \boldsymbol{x}_{0}}\right|=\left|\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{0}+b\right|=\|\boldsymbol{w}\| \cdot r\\ \Rightarrow r=\frac{\left|\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b\right|}{\|\boldsymbol{w}\|} ∣∣wT⋅x1x0∣∣=∣∣wTx0+b∣∣=∥w∥⋅r⇒r=∥w∥∣∣wTx+b∣∣
我们又定义函数间隔:给定数据集 D = { ( x 1 , y 1 ) ⋅ ( x 2 , y 2 ) … ( x m ⋅ y m ) } , y i ∈ { − 1 , + 1 } D=\left\{\left(\boldsymbol{x}_{1}, y_{1}\right) \cdot\left(\boldsymbol{x}_{2}, y_{2}\right) \ldots\left(\boldsymbol{x}_{m} \cdot y_{m}\right)\right\}, y_{i} \in\{-1,+1\} D={ (x1,y1)⋅(x2,y2)…(xm⋅ym)},yi∈{ −1,+1}和超平面 w T x + b = 0 \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b=0 wTx+b=0,定义超平面关于样本 ( x i , y i ) \left(\boldsymbol{x}_{i}, y_{i}\right) (xi,yi)的函数间隔为
γ ^ i = y i ( w T x i + b ) \hat{\gamma}_{i}=y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right) γ^i=yi(wTxi+b)
定义超平面关于数据集的间隔函数为超平面关于数据集中所有样本的函数间隔最小值,也就是
γ ^ = min 1 , 2 , … , m γ ^ i \hat{\gamma}=\min _{1,2, \ldots, m} \hat{\gamma}_{i} γ^=1,2,…,mminγ^i
定义几何间隔:定义超平面关于样本 ( x i , y i ) \left(\boldsymbol{x}_{i}, y_{i}\right) (xi,yi)的几何间隔为
γ i = γ ^ i ∥ w ∥ \gamma_{i}=\frac{\hat{\gamma}_{i}}{\|\boldsymbol{w}\|} γi=∥w∥γ^i
同样,定义超平面关于数据集的几何间隔为超平面关于数据集中所有样本的几何间隔最小值,也就是
γ = min 1 , 2 , … , m γ i = γ ^ ∥ w ∥ \gamma=\min _{1,2, \ldots, m} \gamma_{i}=\frac{\hat{\gamma}}{\|\boldsymbol{w}\|} γ=1,2,…,mminγi=∥w∥γ^
SVM的核心思想:求一个与已知数据集几何间隔最大的那个超平面,也就是
min γ s.t. γ i ≥ γ , i = 1 , 2 , … , m min γ ^ ∥ w ∥ s.t. γ i ∥ w ∥ ≥ γ ^ ∥ w ∥ , i = 1 , 2 , … , m min γ ^ ∥ w ∥ s.t. y i ( w x i + b ) ≥ γ ^ , i = 1 , 2 , … , m min 1 ∥ w ∥ s.t. y i ( w x i + b ) ≥ 1 , i = 1 , 2 , … , m min w , b 1 2 ∥ w ∥ 2 s.t. 1 − y i ( w T x i + b ) ⩽ 0 , i = 1 , 2 , … , m \begin{array}{ll} \min & \gamma \\ \text { s.t. } & \gamma_{i} \geq \gamma, \quad i=1,2, \ldots, m \\ \min & \frac{\hat{\gamma}}{\|\boldsymbol{w}\|} \\ \text { s.t. } & \frac{\gamma_{i}}{\|\boldsymbol{w}\|} \geq \frac{\hat{\gamma}}{\|\boldsymbol{w}\|}, \quad i=1,2, \ldots, m \\ \min & \frac{\hat{\gamma}}{\|\boldsymbol{w}\|} \\ \text { s.t. } & y_{i}\left(\boldsymbol{w} \boldsymbol{x}_{i}+b\right) \geq \hat{\gamma}, \quad i=1,2, \ldots, m \\ \min & \frac{1}{\|\boldsymbol{w}\|} \\ \text { s.t. } & y_{i}\left(\boldsymbol{w} \boldsymbol{x}_{i}+b\right) \geq 1, \quad i=1,2, \ldots, m\\ \min _{\boldsymbol{w}, b} & \frac{1}{2}\|\boldsymbol{w}\|^{2} \\ \text { s.t. } & 1-y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right) \leqslant 0, \quad i=1,2, \ldots, m \end{array} min s.t. min s.t. min s.t. min s.t. minw,b s.t. γγi≥γ,i=1,2,…,m∥w∥γ^∥w∥γi≥∥w∥γ^,i=1,2,…,m∥w∥γ^yi(wxi+b)≥γ^,i=1,2,…,m∥w∥1yi(wxi+b)≥1,i=1,2,…,m21∥w∥21−yi(wTxi+b)⩽0,i=1,2,…,m
这就是可以写作 y i ( w ⊤ x i + b ) ≥ 1 y_{i}\left(\mathbf{w}^{\top} \mathbf{x}_{\mathbf{i}}+b\right) \geq 1 yi(w⊤xi+b)≥1的原因, y i y_i yi为样本类别 { − 1 , 1 } \{-1,1\} { −1,1},对于分类正确的正样本$\left(w^{T} x_{i}+b\right) \geq 1 且 且 且 y_{i}=1 , 对 于 分 类 正 确 的 负 样 本 ,对于分类正确的负样本 ,对于分类正确的负样本\left(w^{T} x_{i}+b\right) \leq-1 且 且 且y_i=-1$.
4.当训练集数据满足什么要求时,存在一个可行的 w \boldsymbol{w} w?
能够正确划分训练数据集并且几何间隔最大。间隔最大化:不仅将正负实例点分开,而且对最难分离的实例点也有足够大的确信度将他们分开
5.推导超平面 H 1 H_1 H1和 H 2 H_2 H2间距离(间隔)的表达式
如果两个点 x 1 x_1 x1和 x 2 x_2 x2分别在 H 1 H_1 H1和 H 2 H_2 H2上,那么两个点到超平面的距离为
r 1 = ∣ w T x 1 + b ∣ ∥ w ∥ = 1 ∥ w ∥ r 2 = ∣ w T x 2 + b ∣ ∥ w ∥ = 1 ∥ w ∥ r_1=\frac{\left|\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x_1}+b\right|}{\|\boldsymbol{w}\|} = \frac{1}{\|\boldsymbol{w}\|}\\ r_2=\frac{\left|\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x_2}+b\right|}{\|\boldsymbol{w}\|} = \frac{1}{\|\boldsymbol{w}\|} r1=∥w∥∣∣wTx1+b∣∣=∥w∥1r2=∥w∥∣∣wTx2+b∣∣=∥w∥1
所以两个超平面间的距离间隔表达式是
2 ∥ w ∥ \frac{2}{\|\boldsymbol{w}\|} ∥w∥2
6.根据以上问题的答案,写出对应硬间隔支持向量机的优化问题的表达式
满足硬约束条件
min w , b 1 2 ∥ w ∥ 2 s.t. 1 − y i ( w T x i + b ) ⩽ 0 , i = 1 , 2 , … , m \begin{array}{ll} \min _{\boldsymbol{w}, b} & \frac{1}{2}\|\boldsymbol{w}\|^{2} \\ \text { s.t. } & 1-y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right) \leqslant 0, \quad i=1,2, \ldots, m \end{array} minw,b s.t. 21∥w∥21−yi(wTxi+b)⩽0,i=1,2,…,m
7.对于以下数据点 x 1 = ( 1 , 2 , 3 ) , x 2 = ( 4 , 1 , 2 ) , x 3 = ( − 1 , 2 , − 1 ) \mathbf{x}_{\mathbf{1}}=(1,2,3), \mathbf{x}_{\mathbf{2}}=(4,1,2), \mathbf{x}_{\mathbf{3}}=(-1,2,-1) x1=(1,2,3),x2=(4,1,2),x3=(−1,2,−1)及其对应标签 = y 1 = + 1 , y 2 = + 1 , y 3 = − 1 =y_{1}=+1, y_{2}=+1, y_{3}=-1 =y1=+1,y2=+1,y3=−1,正确的SVM决策函数 w ⊤ x + b = 0 \mathbf{w}^{\top} \mathbf{x}+b=0 w⊤x+b=0为以下某一选项。找出该选项
1. w = [ 0.3 , 0 , 0.4 ] ⊤ , b = − 0.4 2. w = [ 0.2 , 0 , 0.4 ] ⊤ , b = − 0.4 3. w = [ 0.1 , 0 , 0.4 ] ⊤ , b = − 0.4 4. w = [ 0.4 , 0 , 0.2 ] ⊤ , b = − 0.4 \begin{array}{l} \text { 1. } \mathbf{w}=[0.3,0,0.4]^{\top}, b=-0.4 \\ \text { 2. } \mathbf{w}=[0.2,0,0.4]^{\top}, b=-0.4 \\ \text { 3. } \mathbf{w}=[0.1,0,0.4]^{\top}, b=-0.4 \\ \text { 4. } \mathbf{w}=[0.4,0,0.2]^{\top}, b=-0.4 \end{array} 1. w=[0.3,0,0.4]⊤,b=−0.4 2. w=[0.2,0,0.4]⊤,b=−0.4 3. w=[0.1,0,0.4]⊤,b=−0.4 4. w=[0.4,0,0.2]⊤,b=−0.4
正确的是选项2,因为选项2的w与三个点相乘的结果是[1, 1.2, -1]正分类最小值1,负分类最大值-1,且 w 2 w^{2} w2相加值最小。
问题二: 从最优化理论的角度解释为什么存在支持向量
在满足KKT条件的情况下,对于任意训练样本 ( x i , y i ) \left(\boldsymbol{x}_{i}, y_{i}\right) (xi,yi), 总有 α i = 0 \alpha_i=0 αi=0或者 y i f ( x i ) = 1 y_{i} f\left(\boldsymbol{x}_{i}\right)=1 yif(xi)=1.如果 α i = 0 \alpha_i=0 αi=0,则该样本将不会在 f ( x ) f(\boldsymbol{x}) f(x)中的求和出现,也就不会对 f ( x ) f(\boldsymbol{x}) f(x)有任何影响。如果 α i > 0 \alpha_i>0 αi>0,则必有 f ( x ) f(\boldsymbol{x}) f(x),所对应的样本点位于最大间隔边界上,是一个支持向量。因此KKT条件保证了支持向量的存在
问题三:为什么svm核函数不需要知道核函数的具体形式,只要知道内积的表达式
因为特征空间维数可能很高,甚至无穷维,因此直接计算 ϕ ( x i ) T ϕ ( x j ) \phi\left(\boldsymbol{x}_{i}\right)^{\mathrm{T}} \phi\left(\boldsymbol{x}_{j}\right) ϕ(xi)Tϕ(xj)非常困难,我们有了核函数 κ ( x i , x j ) = ⟨ ϕ ( x i ) , ϕ ( x j ) ⟩ = ϕ ( x i ) T ϕ ( x j ) \kappa\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)=\left\langle\phi\left(\boldsymbol{x}_{i}\right), \phi\left(\boldsymbol{x}_{j}\right)\right\rangle=\phi\left(\boldsymbol{x}_{i}\right)^{\mathrm{T}} \phi\left(\boldsymbol{x}_{j}\right) κ(xi,xj)=⟨ϕ(xi),ϕ(xj)⟩=ϕ(xi)Tϕ(xj)后, x i \boldsymbol{x_i} xi与 x j \boldsymbol{x_{j}} xj在特征空间的内积等于他们在原始样本空间中通过函数 κ ( ⋅ , ⋅ ) \kappa(\cdot, \cdot) κ(⋅,⋅)计算的结果。这样,我们就不必直接计算高位特征空间中的内积。
如果我们回顾XOR异或问题,我们知道,不可能找到一个线性表达式超平面 y = w x + b y=wx+b y=wx+b进行划分。我们会把x做一个非线性变换 x → ϕ ( x ) x\rightarrow \phi(x) x→ϕ(x),我们不需要知道变换函数的表达式。但是对任意两个样本 x 1 , x 2 \boldsymbol{x_1}, \boldsymbol{x_2} x1,x2,我们需要知道他们的内积 κ ( x i , x j ) = ⟨ ϕ ( x i ) , ϕ ( x j ) ⟩ \kappa\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)=\left\langle\phi\left(\boldsymbol{x}_{i}\right), \phi\left(\boldsymbol{x}_{j}\right)\right\rangle κ(xi,xj)=⟨ϕ(xi),ϕ(xj)⟩. 我们试想有另外一个样本 x 3 \boldsymbol{x_3} x3, 那么做了非线性变换后 ϕ ( x 3 ) \phi(\boldsymbol{x_3}) ϕ(x3), 有 w ϕ ( x 3 ) + b w\phi(\boldsymbol{x_3})+b wϕ(x3)+b. 看上去似乎要继续知道 ϕ \phi ϕ的表达式才行.
我们通过拉格朗日对偶的方法,可以让权重变成 ω = ∑ i λ i x i y i \omega=\sum_{i} \lambda_{i} \boldsymbol{x_{i}} y_{i} ω=∑iλixiyi, 这里 i i i是遍历训练中的所有样本, λ \lambda λ就是拉格朗日系数。加了核函数之后 ω = ∑ i λ i ϕ ( x i ) y i \omega=\sum_{i} \lambda_{i} \phi(\boldsymbol{x_{i}}) y_{i} ω=∑iλiϕ(xi)yi. 然后把系数矩阵代回去,就有 f = ∑ i λ i ϕ ( x i ) ϕ ( x 3 ) y i + b f=\sum_i \lambda_{i} \phi\left(\boldsymbol{x_{i}}\right) \phi\left(\boldsymbol{x_{3}}\right) y_{i} + b f=∑iλiϕ(xi)ϕ(x3)yi+b . 显然,我们只要知道任意两个样本做非线性变换后做的内积结果就足够了。
问题四:自己独立推导svm算法
问题五:查资料说明svm的优缺点
优点
- 可以解决高维问题,即大型特征空间;
- 能解决小样本下机器学习问题;
- 能够处理非线性特征的相互作用;
- 无局部极小值问题;(相对于神经网络等算法)
- 无需依赖整个数据;
- 泛化能力比较强;
缺点
- 时间复杂度高,当观测样本很多时,效率并不是很高;
- 对非线性问题没有通用解决方案,有时候很难找到一个合适的核函数;
- 对于核函数的高维映射解释力不强,尤其是径向基函数;
- 常规SVM只支持二分类;
- 对缺失数据敏感;
问题六:说出LDA与PCA的区别
- PCA最小重构误差,使得投影后的值和原来的值尽量接近,属于非监督学习
- LDA最大化类间距离,最小化类内距离,使得投影后的不同类别的样本分的更开, 属于监督学习