阿里天池赛之用Pandas揭秘美国选民的总统喜好
今天,参加了阿里云的一项天池赛–“用Pandas揭秘美国选民的总统喜好”。在这里,复盘一下整个的代码。
先给出赛事地址趴^_~
点我哦
接着,我们一起来瞅瞅代码。
# 安装词云处理包wordcloud
!pip install wordcloud --user
# 导入相关处理包
import pandas as pd
# 读取候选人信息,由于原始数据没有表头,需要添加表头,names后面跟的就是自己加的表头
candidates = pd.read_csv("weball20.txt", sep = '|',names=['CAND_ID','CAND_NAME','CAND_ICI','PTY_CD','CAND_PTY_AFFILIATION','TTL_RECEIPTS',
'TRANS_FROM_AUTH','TTL_DISB','TRANS_TO_AUTH','COH_BOP','COH_COP','CAND_CONTRIB',
'CAND_LOANS','OTHER_LOANS','CAND_LOAN_REPAY','OTHER_LOAN_REPAY','DEBTS_OWED_BY',
'TTL_INDIV_CONTRIB','CAND_OFFICE_ST','CAND_OFFICE_DISTRICT','SPEC_ELECTION','PRIM_ELECTION','RUN_ELECTION'
,'GEN_ELECTION','GEN_ELECTION_PRECENT','OTHER_POL_CMTE_CONTRIB','POL_PTY_CONTRIB',
'CVG_END_DT','INDIV_REFUNDS','CMTE_REFUNDS'])
# 读取候选人和委员会的联系信息
ccl = pd.read_csv("ccl.txt", sep = '|',names=['CAND_ID','CAND_ELECTION_YR','FEC_ELECTION_YR','CMTE_ID','CMTE_TP','CMTE_DSGN','LINKAGE_ID'])
# 关联两个表数据,这里使用.merge()将两个表关联起来,我觉得就像数据库里面的关联表关系一样
ccl = pd.merge(ccl,candidates)
# 提取出所需要的列
ccl = pd.DataFrame(ccl, columns=[ 'CMTE_ID','CAND_ID', 'CAND_NAME','CAND_PTY_AFFILIATION'])
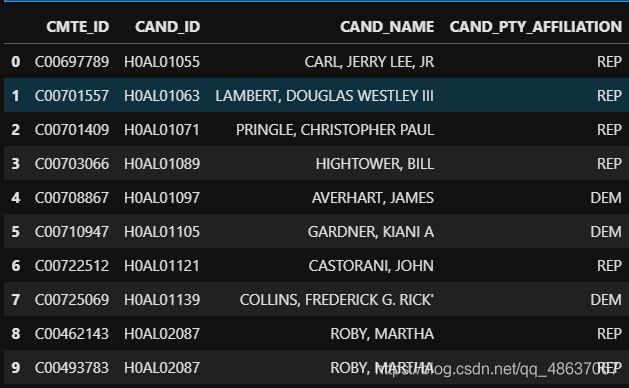
# 查看目前ccl数据前10行
ccl.head(10)
# 读取个人捐赠数据,由于原始数据没有表头,需要添加表头
# 提示:读取本文件大概需要5-10s
itcont = pd.read_csv('itcont_2020_20200722_20200820.txt', sep='|',names=['CMTE_ID','AMNDT_IND','RPT_TP','TRANSACTION_PGI',
'IMAGE_NUM','TRANSACTION_TP','ENTITY_TP','NAME','CITY',
'STATE','ZIP_CODE','EMPLOYER','OCCUPATION','TRANSACTION_DT',
'TRANSACTION_AMT','OTHER_ID','TRAN_ID','FILE_NUM','MEMO_CD',
'MEMO_TEXT','SUB_ID'])
# 将候选人与委员会关系表ccl和个人捐赠数据表itcont合并,通过 CMTE_ID
c_itcont = pd.merge(ccl,itcont)
# 提取需要的数据列
c_itcont = pd.DataFrame(c_itcont, columns=[ 'CAND_NAME','NAME', 'STATE','EMPLOYER','OCCUPATION',
'TRANSACTION_AMT', 'TRANSACTION_DT','CAND_PTY_AFFILIATION'])
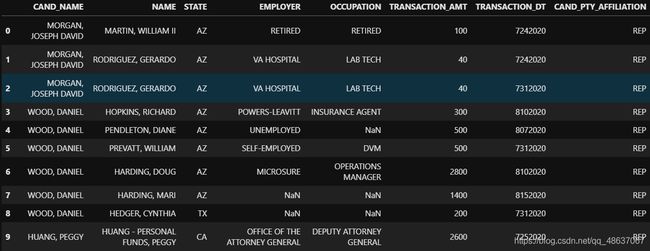
# 查看目前数据前10行
c_itcont.head(10)
# 查看数据规模 多少行 多少列
c_itcont.shape
# 查看整体数据信息,包括每个字段的名称、非空数量、字段的数据类型
c_itcont.info()
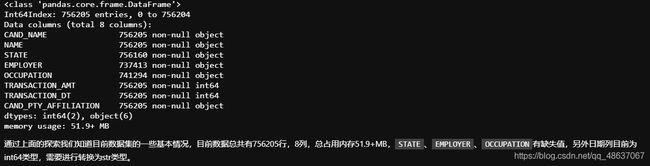 在这里,我们可以明显发现,数据有缺失值,那么我们需要将缺失值填上。
在这里,我们可以明显发现,数据有缺失值,那么我们需要将缺失值填上。
同时,日期列目前为int64类型,需要进行转换为str类型。
#空值处理,统一填充 NOT PROVIDED,inplace=True代表要替换的意思
c_itcont['STATE'].fillna('NOT PROVIDED',inplace=True)
c_itcont['EMPLOYER'].fillna('NOT PROVIDED',inplace=True)
c_itcont['OCCUPATION'].fillna('NOT PROVIDED',inplace=True)
# 对日期TRANSACTION_DT列进行处理
c_itcont['TRANSACTION_DT'] = c_itcont['TRANSACTION_DT'] .astype(str)
# 将日期格式改为年月日 7242020
c_itcont['TRANSACTION_DT'] = [i[3:7]+i[0]+i[1:3] for i in c_itcont['TRANSACTION_DT'] ]
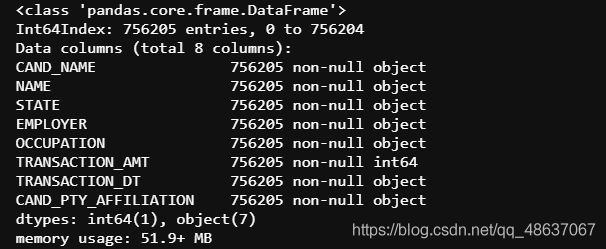
# 再次查看数据信息
c_itcont.info()
 欧克,数据方面算是完成了。我们可以看一些数据情况了,比如:
欧克,数据方面算是完成了。我们可以看一些数据情况了,比如:
# 查看数据前3行
c_itcont.head(3)
# 查看数据表中数据类型的列的数据分布情况
c_itcont.describe()
# 查看单列的数据发布情况
c_itcont['CAND_NAME'].describe()
还可以进行一些数据分析,如:
# 计算每个党派的所获得的捐款总额,然后排序,取前十位,ascending=False代表的是降序排序
c_itcont.groupby("CAND_PTY_AFFILIATION").sum().sort_values("TRANSACTION_AMT",ascending=False).head(10)
# 计算每个总统候选人所获得的捐款总额,然后排序,取前十位
c_itcont.groupby("CAND_NAME").sum().sort_values("TRANSACTION_AMT",ascending=False).head(10)
# 查看不同职业的人捐款的总额,然后排序,取前十位
c_itcont.groupby('OCCUPATION').sum().sort_values("TRANSACTION_AMT",ascending=False).head(10)
# 查看每个职业捐款人的数量
c_itcont['OCCUPATION'].value_counts().head(10)
# 每个州获捐款的总额,然后排序,取前五位
c_itcont.groupby('STATE').sum().sort_values("TRANSACTION_AMT",ascending=False).head(5)
# 查看每个州捐款人的数量
c_itcont['STATE'].value_counts().head(5)
接下来,可以做一些数据可视化的工作了。
# 导入matplotlib中的pyplot
import matplotlib.pyplot as plt
# 为了使matplotlib图形能够内联显示
%matplotlib inline
# 导入词云库
from wordcloud import WordCloud,ImageColorGenerator
绘制按州总捐款数和总捐款人数柱状图
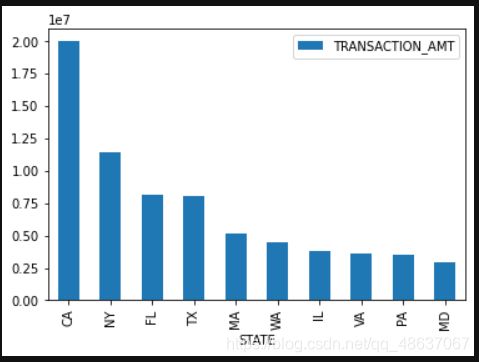
# 各州总捐款数可视化
st_amt = c_itcont.groupby('STATE').sum().sort_values("TRANSACTION_AMT",ascending=False)[:10]
st_amt=pd.DataFrame(st_amt, columns=['TRANSACTION_AMT'])
st_amt.plot(kind='bar')
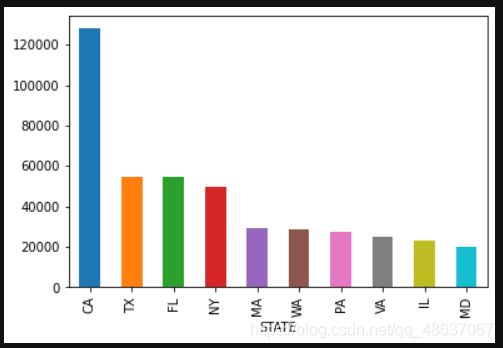
各州捐款总人数可视化
# 各州捐款总人数可视化,取前10个州的数据
st_amt = c_itcont.groupby('STATE').size().sort_values(ascending=False).head(10)
st_amt.plot(kind='bar')
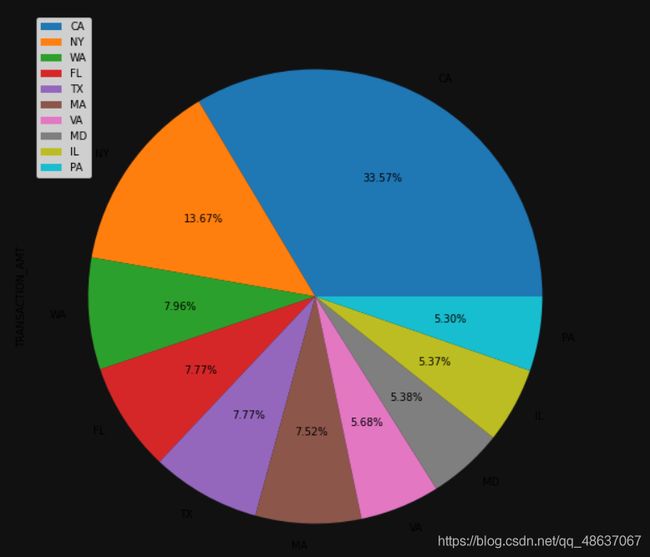
热门候选人拜登在各州的获得的捐赠占比
# 从所有数据中取出支持拜登的数据
biden = c_itcont[c_itcont['CAND_NAME']=='BIDEN, JOSEPH R JR']
# 统计各州对拜登的捐款总数
biden_state = biden.groupby('STATE').sum().sort_values("TRANSACTION_AMT", ascending=False).head(10)
# 饼图可视化各州捐款数据占比
biden_state.plot.pie(figsize=(10, 10),autopct='%0.2f%%',subplots=True)
接下来,是词云的绘制。
# 首先下载图片模型,这里提供的是已经处理好的图片,有兴趣的选手可以自己写代码进行图片处理
# 处理结果:需要将人图像和背景颜色分离,并纯色填充,词云才会只显示在人图像区域
# 拜登原图:https://img.alicdn.com/tfs/TB1pUcwmZVl614jSZKPXXaGjpXa-689-390.jpg
# 拜登处理后图片:https://img.alicdn.com/tfs/TB10Jx4pBBh1e4jSZFhXXcC9VXa-689-390.jpg
# 特朗普原图:https://img.alicdn.com/tfs/TB1D0l4pBBh1e4jSZFhXXcC9VXa-298-169.jpg
# 特朗普处理后图片:https://img.alicdn.com/tfs/TB1BoowmZVl614jSZKPXXaGjpXa-298-169.jpg
# 这里我们先下载处理后的图片
!wget https://img.alicdn.com/tfs/TB10Jx4pBBh1e4jSZFhXXcC9VXa-689-390.jpg
# 由于下载图片文件名过长,我们对文件名进行重命名
import os
os.rename('TB10Jx4pBBh1e4jSZFhXXcC9VXa-689-390.jpg', 'biden.jpg')
# 在4.2 热门候选人拜登在各州的获得的捐赠占比 中我们已经取出了所有支持拜登的人的数据,存在变量:biden中
# 将所有捐赠者姓名连接成一个字符串
data = ' '.join(biden["NAME"].tolist())
# 读取图片文件
bg = plt.imread("biden.jpg")
# 生成
wc = WordCloud(# FFFAE3
background_color="white", # 设置背景为白色,默认为黑色
width=890, # 设置图片的宽度
height=600, # 设置图片的高度
mask=bg, # 画布
margin=10, # 设置图片的边缘
max_font_size=100, # 显示的最大的字体大小
random_state=20, # 为每个单词返回一个PIL颜色
).generate_from_text(data)
# 图片背景
bg_color = ImageColorGenerator(bg)
# 开始画图
plt.imshow(wc.recolor(color_func=bg_color))
# 为云图去掉坐标轴
plt.axis("off")
# 画云图,显示
# 保存云图
wc.to_file("biden_wordcloud.png")

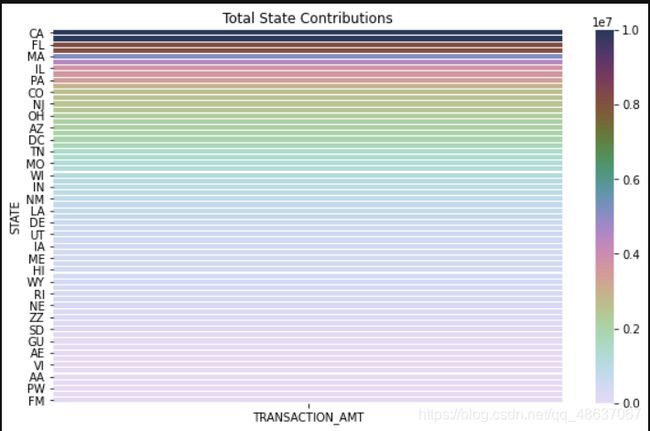
接下来,是让选手自己画热力图。
# 按州总捐款热力地图
'''
参赛选手自由发挥、补充
第一个补充热力地图的参赛选手可以获得天池杯子一个
'''
#调用相关包
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#设置画布大小
f, ax = plt.subplots(figsize = (10,6))
#cmap是从数字到色彩空间的映射,取值是matplotlib包里的colormap名称或颜色对象,或者表示颜色的列表;改参数默认值:根据center参数设定
cmap = sns.cubehelix_palette(start = 1.5, rot = 3, gamma = 0.8, as_cmap = True)
#把每州的捐款总数进行排序
money = c_itcont.groupby('STATE').sum().sort_values("TRANSACTION_AMT",ascending=False)
#转化为dataframe形式
st_amt1 = pd.DataFrame(money)
#绘制热力图,设置相关参数
sns.heatmap(data = st_amt1, linewidths = 0.05, ax = ax, vmax = 10000000, vmin = 0, cmap = cmap)
#设置标题
ax.set_title('Total State Contributions')
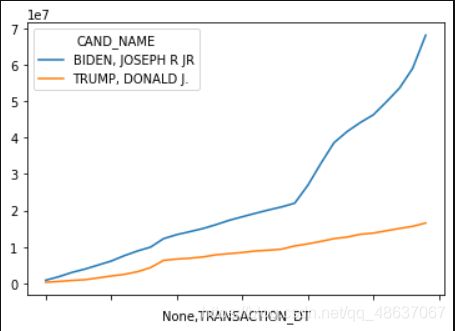
# 收到捐赠额最多的两位候选人的总捐赠额变化趋势
'''
参赛选手自由发挥、补充
第一个补充捐赠额变化趋势图的参赛选手可以获得天池杯子一个
'''
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
fig = plt.figure(figsize=(10,6))
c_itcont = pd.DataFrame(c_itcont, columns=[ 'CAND_NAME', 'TRANSACTION_AMT', 'TRANSACTION_DT'])
c_itcont1 = c_itcont[c_itcont['CAND_NAME'].isin(['BIDEN, JOSEPH R JR', 'TRUMP, DONALD J.'])]
c_itcont2 = c_itcont1.groupby(['CAND_NAME', 'TRANSACTION_DT']).sum()
c_itcont3 = c_itcont2.groupby(['CAND_NAME', ]).cumsum()
c_itcont4 = c_itcont3.unstack().T
c_itcont4.plot()
比赛写到这里就算是结束了。