selenium的8大元素定位法
Web自动化测试就是在web页面中找到一个元素,然后进行操作。由人工操作转换为代码操作,那么第一件事情,就是告诉代码如何找到对应的元素。在selenium中提供了8种元素的定位方法,这篇文章就此8个方面进行阐述。
1.通过标签的id属性进行定位
优点:id属性是唯一的,可以唯一定义,如果有属性id的话,那么就是一找一个准了。具体代码如下:
# @Author:ChenSuoZhang
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.get("http://www.baidu.com")
driver.find_element_by_id("kw").send_keys("Selenium") # 找到百度首页的输入框,并输入selenium进行查找
driver.find_element_by_id("su").click() # 单击百度一下按钮
time.sleep(2)
driver.quit()
2.通过标签的name属性进行查找。
driver.find_element_by_name("wd").send_keys("Selenium") # 通过name属性进行定位元素
driver.find_element_by_class_name("s_btn").click() # 通过class_name属性进行定位按钮并进行点击3.通过元素的link_text定位元素
# 定位页面上的链接时,可以通过链接的文件进行定位,下面是使用整个链接文本
driver.find_element_by_link_text('新闻').click()4.通过标签的partial_link_text定位元素
# 下面使用部分链接文件
driver.find_element_by_partial_link_text('新').click()
5.通过标签的tag_name进行定位
# 实际执行失败,因为页面上有太多的input标签了,因为仅仅从标签名称进行定位,会出现很大问题,故此种方法应用不大
driver.find_element_by_tag_name('input').send_keys('selenium')
driver.find_element_by_class_name("s_btn").click()6.通过标签的class_name进行定位
# 通过标签的class_name进行定位查找原色
driver.find_element_by_class_name('s_ipt').send_keys('selenium')
7.通过css_selector进行定位
8.通过xpath进行定位
8.1xpath简介:xpath是一门在XML文件中的信息查找语句。xpath是使用路径表达式来来选取xml中的节点或者节点集。
8.2基本语法:
①nodename:选取nodename下的所有子节点
driver.find_element_by_xpath('//input').send_keys('selenium')② / :从根节点选取
③// :从匹配选择当前节点的选择文档中的子节点,而不考虑其实际位置
④. :选取当前结单
⑤.. :选取当前节点的父节点,或者是返回上一层节点
⑥@ :选取属性
8.3定位方法:
绝对路径定位:根据实际的路径,逐层写路径信息。
相对路径定位:首先看目录元素是否有“精准元素”即能唯一通过标识的属性,找到,即用此属性定位;
8.3.1通过唯一的属性进行定位
(1)通过唯一的ID进行定位
# 找到所有的input标签,然后从中找到id为'pc2-1'的标签
browser.find_element_by_xpath("//input[@id='pc2-1']").send_keys('iphone')(2)通过唯一的name进行定位
8.3.2 通过唯一的上级元素进行定位,这种方法适用于,当前要查找的属性不是唯一值,或者没有属性值,此时可先找到其上级,然后再定位这个元素。
# 先找到上级,然后再找其下级的a标签
browser.find_element_by_xpath("//*[@id='pc1-0']/a").click()8.3.3 xpath路径做布尔逻辑运算
find_element_by_xpath("//div[@id='hd' or @name='q']")8.3.4 目录元素存在层级关系
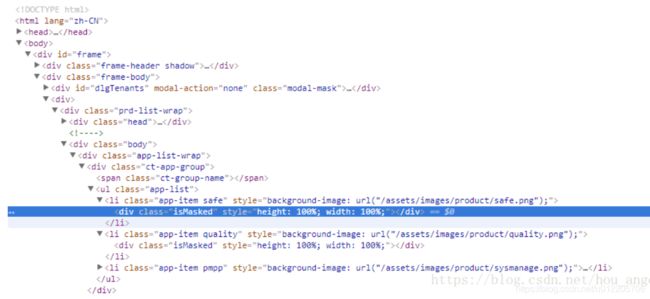
# 先找ul标签,通过class='app-list'筛选,然后找它下面的li标签,这个标签的class要包含safe,然后再找下面的div标签
find_element_by_xpath("//ul[@class='app-list']/li[contains(@class,'safe')]/div")8.3.5 模糊定位
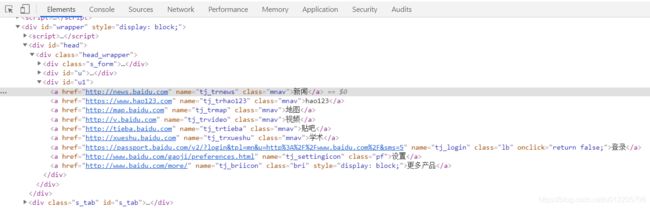
contains 方法(包含):
browser.find_element_by_xpath("//a[contains(@name,'trnews')]")startwith方法(以XX开头):
find_element_by_xpath("//a[start-with(@href,'http')]") text方法(文本内容含):
browser.find_element_by_xpath("//a[contains(text(),'新闻')]") # 查找超链接元素的文本内容
browser.find_element_by_xpath("//*[text()='新闻']") # 查找所有内容为退出二字的元素元素属性值有空格时,尽量不使用带空格,可用contains等其他方法,避开空格。
<仅供参考,欢迎沟通交流>
QQ:312019088