Python批量转mat为csv
文章目录
- 前言
- 一、处理需求
- 二、处理结果
- 二、处理代码
- 总结
前言
MATLAB和Python同时处理一批数据,MATLAB可以生成很实用的mat文件,Python可以进一步处理分析,并画出漂亮的数据图。
一、处理需求
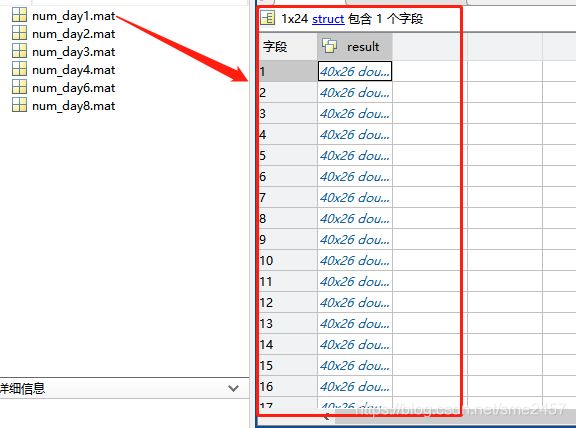
本人用MATLAB生成多个mat文件,每个mat文件中又包含struct字段,
需要读取每个struct中的每一个数据,并分别在不同的文件夹下保存为csv,数据如下图
二、处理结果
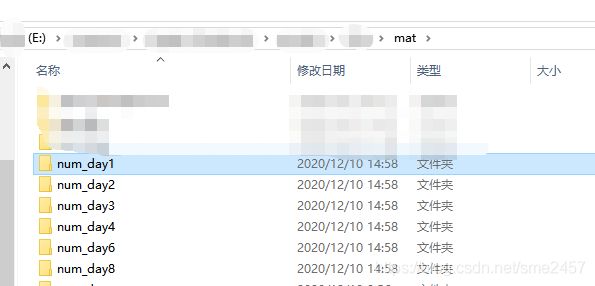
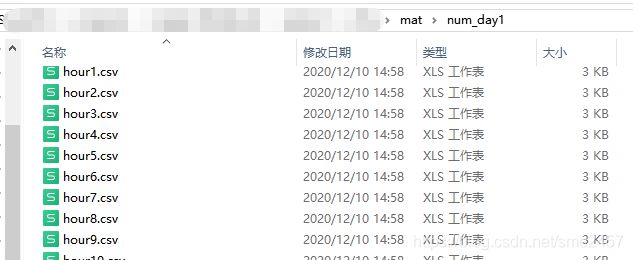
生成的csv分别保存在不同的文件夹下
二、处理代码
代码如下(示例):
import pandas as pd
import scipy.io as sio
import os
import re
import numpy as np
if __name__ == '__main__':
filenames_in = 'E://...//mat//num_day' # 输入文件的文件地址(自行调整)
# filenames_out = 'E://program//mat//num_day1' # 新文件的地址(如果在这里读取保存地址,会只有一个地址,只显示最后一次处理的数据,亲测)
pathDir = os.listdir(filenames_in)
for allDir in pathDir:
child = re.findall(r"(.+?).mat", allDir) # 正则的方式读取文件名,去扩展名
if len(child) >= 0: # 去掉没用的系统文件
newfile = ''
needdate = child #### 这个就是所要的文件名
domain1 = os.path.abspath(filenames_in) # 待处理文件位置
info = os.path.join(domain1, allDir) # 拼接出待处理文件名字
out = needdate # 获取循环保存的新文件夹名,这里是读到的是第一个mat文件名,也就是希望保存的文件夹名
filenames_out = 'E://...//mat//' + out[0] #新文件夹地址=主目录+最后一个新文件夹名(E://...//mat//num_day1)
mat = sio.loadmat(info) # 读取第一个mat文件
num = mat['num'] # 读取struct
for i in range(24):
print(info, "开始处理")
name = 'hour' + str(i+1)
domain2 = os.path.abspath(filenames_out) # 处理完文件保存地址
outfo = os.path.join(domain2, name + '.csv') # 拼接出新文件名字
# 在此先拼接出新的文件名,否则下条语句会重置name值
name = num[0, i]
# result = pd.DataFrame(name["result"], index=None, header=None)
# result = pd.DataFrame(name["result"], index=False)
# result = pd.DataFrame(name["result"], index=0)
# result = pd.DataFrame(name["result"], index_col=0)
# 以上四条是想在读取结果的时候就保存成没有行列索引的dataframe,均失败
result = pd.DataFrame(name["result"]) # “result”MATLAB中的结果字段,请自行根据mat文件更改
# domain2 = os.path.abspath(filenames_out) # 处理完文件保存地址
# outfo = os.path.join(domain2, name+'.csv') # 拼接出新文件名字
# 不能在此出现保存地址
result.to_csv(outfo, header=None, index=None, encoding='utf-8') # 保存文件时没有行列索引(注:不能存在同名文件,最好空文件夹可运行)
# result.to_csv(outfo, header=False, index=False, encoding='utf-8')
# result.to_csv(outfo, index_col='Unnamed: 0', encoding='utf-8')
# result.to_csv(outfo, index_col=0, encoding='utf-8')
# result.to_csv(outfo, encoding='utf-8') # 如无索引需求,可运行此句
print(info, "处理完")
print('=====') # 第一个mat处理完成,跳出本循环,处理第二个mat文件
总结
本篇是在上篇 Python批量处理csv文件(筛选列)基础上的改良,不仅可以循环处理文件,还循环保存在新的不同的文件夹。
本文的文件夹均是提前建立好的,并没有检测和自动创建功能,生成的csv也没有检测和覆盖功能,故需新的空文件夹(可以包含非同名csv文件)。
简单的代码解决简单问题。
如果大家觉得代码或者注释有什么问题,欢迎批评指正,大家相互探讨学习。
每天进步一点点!!!