一起学爬虫(Python) — 19 年轻人,进来学自动化
前言

Hello,大家好,今天是早起的小泽!
![]()
早上10点相信对大家来说都还没有起来吧,当然有工作的除外,要上学的除外,相信还是有很多可以天天在家里待着的富婆鸭,会来这里偷偷地学习。
那么今天咱们是要搞什么呢?
相信通过标题你也是知道了,自动化!

那么话不多说,直接带大家起飞,好好学,好好问,你也可以成为大神!
什么是自动化
今天我们说到的自动化,不是你们可能听过很多的无人驾驶,机器人鸭什么的,就是没有那么高级哈。
这个自动化呢,在python里面用一个模块来实现:selenium

如果缺少这个东西呢,大家是有可能得抑郁症的,所以也可以看出来自动化对大家来说是多么的重要,还不赶紧学起来!
什么,你老抑郁了?

还没12点呢。
当然想只通过上面毫无关联的翻译来了解自动化,不太现实。
所以再给大家科普一下:
Selenium
是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9,10, 11),Mozilla Firefox,Safari,Google,Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成
.Net、Java、Perl等不同语言的测试脚本。
如果你还是看的不太明白,就可以这么理解:
selenium就是能帮我们自动浏览网页,自动获取那些我们能看到的数据。
总之呢,requests是属于黑暗里的一道光,而selenium就是光明正大的搞你,就是要搞你。
虽然上面说支持的浏览器有很多,但是还是推荐大家统一使用谷歌浏览器哈。
怎么安装selenium
又到了熟悉的教小白环节,小泽发现有很多人是直接学爬虫的诶,然后很多基础方面的,或者前端方面的知识鸭,就不太懂,这里可以花点时间把需要掌握的知识,系统的学一遍,毕竟不能急嘛,比的就是基本功。

直接开始教程,很快啊。
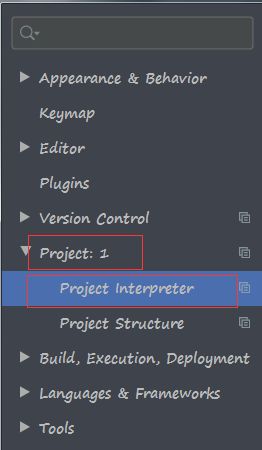
上面那个Project:1有的人可能找不到哦,因为你的项目名字不是1,找你的项目名字就好了,项目名字是最外层那个文件夹的名字哦。

找加号,有的人的加号可能在下面。
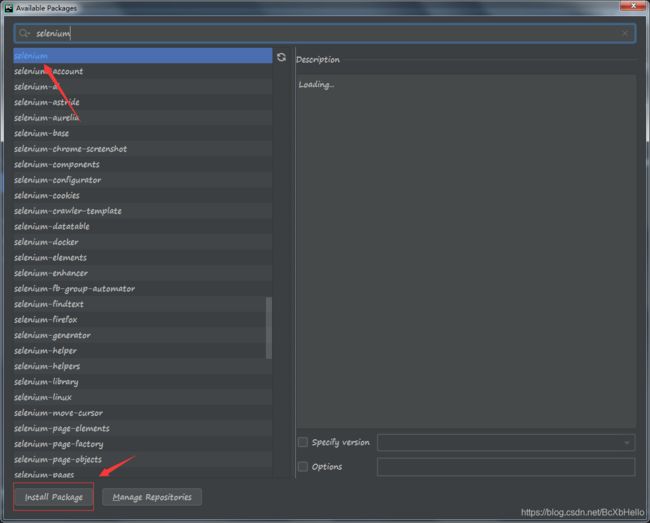
搜索selenium,然后点击左下方的下载,等你变绿了,就说明没毛病了嗷。
当然有的小伙伴可能会出现红色,下载失败,解决方法呢,在 一起学爬虫(Python) — 07 里面是有介绍的,在中间往下的部分,可以去找一找。

神奇の传送门1号
然后,模块我们就安装完成啦!
接下来就是重头戏了,要一起安装谷歌浏览器的引擎!
神奇の传送门2号
打开这个网址之前呢,大家先跟着小泽一起看一下自己谷歌浏览器的版本:
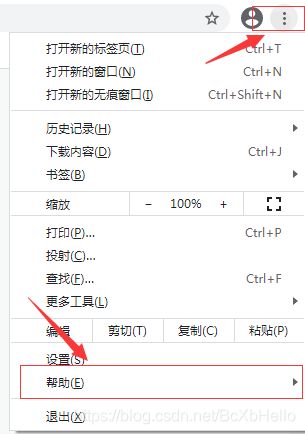
在帮助里面呢,有个关于Google Chrome,点进去。

你就能看到你的版本啦。
然后打开上面的传送门2号:
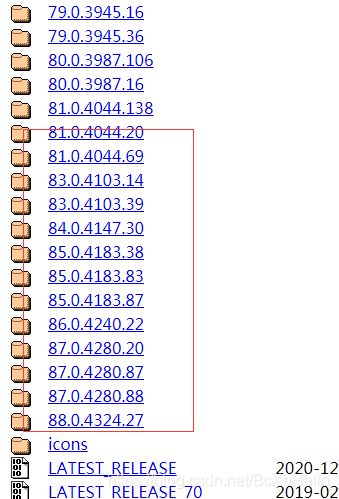
找到你对应的版本号的文件,然后点进去:

再根据自己的系统进行下载哈。
下载完了把里面的:

放在你能找得到的地方。
如果这些你都准备好了,那我们就可以开始了!
开冲!
最近小泽看到淘宝上有代冲的哦,10块钱一次,能让老板代替我们冲,如果大家实在忍不住可以去光顾一下,关爱自己,人人有责。

# 导入模块
from selenium import webdriver
第一步当然不用说啦,导入模块。对了,上面那个引擎,可以放在py文件的当前目录下哦,用的时候也方便!
# 这里指定自己的谷歌引擎目录
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
今天,我们都是老司机!
上面那句是每次都要这样写的,所以不用纠结是为什么哦,Chrome就是谷歌的意思嘛~
from time import sleep
# 打开csdn的登录界面
driver.get('https://passport.csdn.net/login?code=public')
print('正在打开指定网页…')
sleep(1)
这里sleep1秒呢,是因为怕还没加载出来就继续下一步了,就有问题了。
先不要问代码为什么这么写,试试效果鸭!
# 找到那个输入账号密码的按钮
dl = driver.find_element_by_xpath('//*[@id="app"]/div/div/div[1]/div[2]/div[5]/ul/li[2]')
# 模拟点击
dl.click()
sleep(1)
先照样子复制,find_element_by_xpath就是根据xpath去找标签的位置哦,你也可以根据class,id等等…

刚进来的时候,我们是需要点一下这个账号密码登录的,所以就点击了这个标签对应的xpath。

第一步:输入账号
第二步:输入密码
第三步:点击登录
清楚了步骤,就让我们开始复制代码吧!
# 循环判断是否登陆成功
while True:
user_number = input('输入你滴账号:')
pass_word = input('输入你滴密码:')
# 找到账号框
input_num = driver.find_element_by_xpath('//*[@id="all"]')
# 找到密码框
password = driver.find_element_by_id('password-number')
# 清空输入框
input_num.clear()
password.clear()
# 把账号放进账号框
input_num.send_keys(user_number)
# 把密码放进密码框
password.send_keys(pass_word)
# 找到登录按钮
btn = driver.find_element_by_xpath('//*[@id="app"]/div/div/div[1]/div[2]/div[5]/div/div[6]/div/button')
# 点击登录按钮
btn.click()
sleep(1)
# 取的目前的url
now_url = driver.current_url
# 判断是否登陆成功
if now_url == 'https://www.csdn.net/':
print('登陆成功!')
sleep(1)
break
else:
print('登陆失败!')
choice = input('小可爱看一下你的账号是不是有风险了,需要验证码,是的话扣1,如果是密码错了就扣2:')
if choice == '1':
print('给你一分钟时间进行验证码的验证,你也可以手动把这个时间调的短一点!')
sleep(60)
elif choice == '2':
print('好好输入密码!')
continue
else:
print('你在玩呢?')
相信聪明的你,一定能自己消化掉上面的代码,如果不能,没关系,下一期我们详细到每根毛孔都讲的清清楚楚! 先复制哈~
print('正在获取所有文章……')
# 前往存有所有博客url的那篇博客
driver.get('https://blog.csdn.net/BcXbHello/article/details/111560584')
sleep(1)
# 获取博客文本
data = driver.find_element_by_xpath('//*[@id="content_views"]/p').text
print('成功获取所有文章!')
sleep(1)
# 判断是否点赞
is_like = driver.find_element_by_xpath('//*[@id="is-like-span"]')
if is_like.text == '点赞':
is_like.click()
sleep(1)
# 处理url
data = data.split('|')[:-2]
for url in data:
driver.get(url)
is_like = driver.find_element_by_xpath('//*[@id="is-like-span"]')
if is_like.text == '点赞':
title = driver.find_element_by_xpath('//*[@id="articleContentId"]').text
is_like.click()
print(title+'点赞完毕!')
sleep(1)
print('已经全部点赞完毕!坚决不做白嫖党,我爱小泽!!!')
# 退出调试
driver.quit()
注释呢,尽量的都写上去了,这一篇就先带着大家感受一下selenium的魅力~
结尾
也许聪明的你已经发现,这是一个防止白嫖的帖子,但是真的很有意思对不对~
点了赞,就是我的人了,好好听话,好好学习,下一篇给你看个大宝贝。

当然,有些懒家伙,不喜欢一个一个复制,这里也直接把所有代码都打出来好了:
from time import sleep
from selenium import webdriver
# 这里指定自己的谷歌引擎目录
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
# 打开csdn的登录界面
driver.get('https://passport.csdn.net/login?code=public')
print('正在打开指定网页…')
sleep(1)
# 找到那个输入账号密码的按钮
dl = driver.find_element_by_xpath('//*[@id="app"]/div/div/div[1]/div[2]/div[5]/ul/li[2]')
# 点击
dl.click()
sleep(1)
# 循环判断是否登陆成功
while True:
user_number = input('输入你滴账号:')
pass_word = input('输入你滴密码:')
# 找到账号框
input_num = driver.find_element_by_xpath('//*[@id="all"]')
# 找到密码框
password = driver.find_element_by_id('password-number')
# 清空输入框
input_num.clear()
password.clear()
# 把账号放进账号框
input_num.send_keys(user_number)
# 把密码放进密码框
password.send_keys(pass_word)
# 找到登录按钮
btn = driver.find_element_by_xpath('//*[@id="app"]/div/div/div[1]/div[2]/div[5]/div/div[6]/div/button')
# 点击登录按钮
btn.click()
sleep(1)
# 取的目前的url
now_url = driver.current_url
# 判断是否登陆成功
if now_url == 'https://www.csdn.net/':
print('登陆成功!')
sleep(1)
break
else:
print('登陆失败!')
choice = input('小可爱看一下你的账号是不是有风险了,需要验证码,是的话扣1,如果是密码错了就扣2:')
if choice == '1':
print('给你一分钟时间进行验证码的验证,你也可以手动把这个时间调的短一点!')
sleep(60)
elif choice == '2':
print('好好输入密码!')
continue
else:
print('你在玩呢?')
print('正在获取所有文章……')
# 前往存有所有博客url的那篇博客
driver.get('https://blog.csdn.net/BcXbHello/article/details/111560584')
sleep(1)
# 获取博客文本
data = driver.find_element_by_xpath('//*[@id="content_views"]/p').text
print('成功获取所有文章!')
sleep(1)
# 判断是否点赞
is_like = driver.find_element_by_xpath('//*[@id="is-like-span"]')
if is_like.text == '点赞':
is_like.click()
sleep(1)
# 处理url
data = data.split('|')[:-2]
print(data)
for url in data:
driver.get(url)
is_like = driver.find_element_by_xpath('//*[@id="is-like-span"]')
if is_like.text == '点赞':
title = driver.find_element_by_xpath('//*[@id="articleContentId"]').text
is_like.click()
print(title+'点赞完毕!')
sleep(1)
print('已经全部点赞完毕!坚决不做白嫖党,我爱小泽!!!')
# 退出调试
driver.quit()