【Java】手动写一个非常简易的web server(四)
写在前面的话:
- 版权声明:本文为博主原创文章,转载请注明出处!
- 博主是一个小菜鸟,并且非常玻璃心!如果文中有什么问题,请友好地指出来,博主查证后会进行更正,啾咪~~
- 每篇文章都是博主现阶段的理解,如果理解的更深入的话,博主会不定时更新文章。
- 本文初次更新时间:2020.12.28,最后更新时间:2020.12.28
文章目录
- 正文开始
-
- 1. 支持传递用户输入的数据
-
- 1.1 准备注册页面
- 1.2 重构 HttpRequest 类
- 2. 支持注册业务
-
- 2.1 创建 RegServlet 类
- 2.2 修改 ClientHandler 类
- 2.3 创建注册成功页面
- 2.4 RegServlet 处理注册业务
-
- 2.4.1 处理注册业务
- 2.4.1 验证是否为重复用户
- 3. 实现登录功能
-
- 3.1 新建相关页面
-
- 3.1.1 登录页面
- 3.1.2 登录成功提示页面
- 3.1.3 登录失败提示页面
- 3.2 定义 LoginServlet 类
- 3.3 修改 ClientHandler 类
- 4. 解决地址栏传递中文问题
- 参考
- 相关文章
正文开始
1. 支持传递用户输入的数据
我们日常上网,经常会在页面上输入信息,比如注册操作,输入后点击按钮提交给服务端。这个过程的实现如下:
- 首先要想让用户可以输入内容,需要在页面中添加一个
表单,然后在表单中添加若干个输入框,当用户输入信息后点击提交按钮,然后将这个表单内容提交。 - 当表单提交后,服务端应当在解析请求时,将用户提交的这些数据解析出来,以便做后续对应的操作。
1.1 准备注册页面
准备一个注册页面reg.html,用于表单的提交。
需要了解的是:
- 数据要想提交给服务端,输入框必须要包含在表单里,表单是专门的标签
,只有表单里的输入框输入的内容,才会最终被提交到服务器。表单标签只对输入框敏感,只会提交的内容。在form外面的是不会被提交的。 - 表单上的按钮类型不能是
button,有专门用来提交表单的按钮submit(提交按钮),提交按钮也必须被包含在form表单中。 - 每个
都必须有名字name。
在webapps/myweb/下新建页面reg.html:
<html lang="zh">
<head>
<meta charset="UTF-8">
<title>用户注册title>
head>
<body>
<h1 align="center">欢迎注册h1>
<form action="reg" method="get">
<table align="center">
<tr>
<td>用户名:td>
<td><input type="text" name="username">td>
tr>
<tr>
<td>密码:td>
<td><input type="text" name="password">td>
tr>
<tr>
<td>昵称:td>
<td><input type="text" name="nickname">td>
tr>
<tr>
<td>年龄:td>
<td><input type="text" name="age">td>
tr>
<tr>
<td colspan="2" align="center">
<input type="submit" value="注册">
td>
tr>
table>
form>
body>
html>
页面如下:

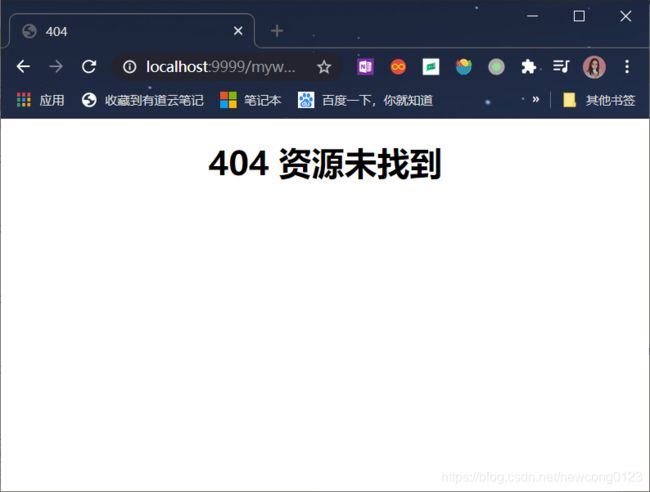
这个时候如果启动服务器,输入地址http://localhost:9999/myweb/reg.html,然后填写表单并提交,会得到404页面:
1.2 重构 HttpRequest 类
由于请求可能会传递参数过来,所以当我们解析请求时要对参数进行解析。
在上面我们提交表单之后,关于请求行的结果如下:
开始解析请求行...
请求行:GET /myweb/reg?username=zhangsan&password=123456&nickname=sansan&age=18 HTTP/1.1
method: GET
url: /myweb/reg?username=zhangsan&password=123456&nickname=sansan&age=18
protocol: HTTP/1.1
请求行解析完毕!
开始解析消息头...
当一个页面中的form表单以GET形式提交时,所有form表单中的输入域内容会被拼接在地址栏中"?"右侧。这时我们在解析请求行中的url部分时会得到类似如下内容:
/myweb/reg?username=xxx&password=xxx&.....
url中"?"右侧为参数部分,每个参数以"&"进行分割,每个参数由name=value组成,其中:
- name 是表单输入域的名字
- value 是该输入域输入的内容
我们在HttpRequest中定义三个参数:
- private String requestURI:保存url中的请求路径部分
- private String queryString:保存url中的参数部分
- private Map
以之前的结果为例:
开始解析请求行...
请求行:GET /myweb/reg?username=zhangsan&password=123456&nickname=sansan&age=18 HTTP/1.1
method: GET
url: /myweb/reg?username=zhangsan&password=123456&nickname=sansan&age=18
protocol: HTTP/1.1
请求行解析完毕!
开始解析消息头...
- requestURI:/myweb/reg
- queryString:username=zhangsan&password=123456&nickname=sansan&age=18
- parameter:
| key | value |
|---|---|
| username | zhangsan |
| password | 123456 |
| nickname | sansan |
| age | 18 |
定义参数,并添加get方法,因为是读取过来的,所以不需要添加set方法:
private String requestURI;
private String queryString;
private Map<String, String> parameter = new HashMap<String, String>();
public String getRequestURI() {
return requestURI;
}
public String getQueryString() {
return queryString;
}
/**
* 根据给定的参数名获取对应的参数值
* @param name
* @return
*/
public String getParameter(String name) {
return parameter.get(name);
}
url可能存在两种情况:带参数或不带参数。是否带参数可以通过查看当前url中是否含有"?"来得知。
如果该url不含有参数,那么直接将url赋值给属性requestURI即可;若含有参数,那么就按照"?"将url拆分为两部分:
- "?"左侧内容:赋值给requestURI属性
- "?"右侧内容:赋值给queryString属性
然后还要对参数部分进行进一步解析。因为参数部分的格式是固定的:name=value&name=value&.....,所以我们可以将参数部分首先按照"&"拆分为若干段,每一段的内容应当为一个"name=value",然后我们将每一个参数再按照"="拆分为参数名与参数值,分别将他们当做key与value存入到属性parameter中完成解析参数的工作。
接下来定义一个用来进一步解析url的方法:parseUrl,并在解析请求行parseRequestLine方法中解析出url后调用该方法,对url进一步解析:
private void parseUrl() {
System.out.println("进一步解析url......");
//判断请求路径中是否含有"?"
if (url.indexOf("?") != -1) {
//按照"?"将url拆分为两部分
String[] data = url.split("\\?");
requestURI = data[0];
//看url的"?"后面是否有内容
if (data.length > 1) {
queryString = data[1];
//拆分每个参数
data = queryString.split("&");
for (String paraLine : data) {
//按照"="将参数拆分为两部分
String[] paraArr = paraLine.split("=");
//判断该参数是否有值
if (paraArr.length > 1) {
parameter.put(paraArr[0], paraArr[1]);
} else {
parameter.put(paraArr[0], null);
}
}
}
} else {
requestURI = url;
}
System.out.println("requestURI: " + requestURI);
System.out.println("queryString: " + queryString);
System.out.println("parameter: " + parameter);
System.out.println("解析url完毕!");
}
记得在parseRequestLine方法中解析出url后调用parseUrl方法,最终代码:
package com.webserver.http;
import java.io.IOException;
import java.io.InputStream;
import java.net.Socket;
import java.util.HashMap;
import java.util.Map;
/**
* 请求对象
* 每个实例表示客户端发送过来的一个具体请求
* @author returnzc
*
*/
public class HttpRequest {
/*
* 请求行相关信息定义
*/
private String method; //请求方式
private String url; //资源路径
private String protocol; //协议版本
private String requestURI;
private String queryString;
private Map<String, String> parameter = new HashMap<String, String>();
/*
* 消息头相关信息定义
*/
private Map<String, String> headers = new HashMap<String, String>();
/*
* 消息正文相关信息定义
*/
/*
* 客户端连接相关信息
*/
private Socket socket;
private InputStream in;
public HttpRequest(Socket socket) throws EmptyRequestException {
try {
this.socket = socket;
this.in = socket.getInputStream();
/*
* 解析请求的过程:
* 1. 解析请求行
* 2. 解析消息头
* 3. 解析消息正文
*/
parseRequestLine();
parseHeaders();
parseContent();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 解析请求行
* @throws EmptyRequestException
*/
private void parseRequestLine() throws EmptyRequestException {
System.out.println("开始解析请求行...");
try {
String line = readLine();
System.out.println("请求行:" + line);
//若请求行内容是一个空串,则是空请求
if ("".equals(line)) {
throw new EmptyRequestException();
}
//将请求行进行拆分,将每部分内容对应的设置到属性上
String[] data = line.split("\\s");
this.method = data[0];
this.url = data[1];
this.protocol = data[2];
parseUrl(); //进一步解析url
System.out.println("method: " + method);
System.out.println("url: " + url);
System.out.println("protocol: " + protocol);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("请求行解析完毕!");
}
private void parseUrl() {
System.out.println("进一步解析url......");
//判断请求路径中是否含有"?"
if (url.indexOf("?") != -1) {
//按照"?"将url拆分为两部分
String[] data = url.split("\\?");
requestURI = data[0];
//看url的"?"后面是否有内容
if (data.length > 1) {
queryString = data[1];
//拆分每个参数
data = queryString.split("&");
for (String paraLine : data) {
//按照"="将参数拆分为两部分
String[] paraArr = paraLine.split("=");
//判断该参数是否有值
if (paraArr.length > 1) {
parameter.put(paraArr[0], paraArr[1]);
} else {
parameter.put(paraArr[0], null);
}
}
}
} else {
requestURI = url;
}
System.out.println("requestURI: " + requestURI);
System.out.println("queryString: " + queryString);
System.out.println("parameter: " + parameter);
System.out.println("解析url完毕!");
}
/**
* 解析消息头
*/
private void parseHeaders() {
System.out.println("开始解析消息头...");
try {
while (true) {
String line = readLine();
if ("".equals(line)) {
break;
}
String[] data = line.split(":\\s");
headers.put(data[0], data[1]);
}
System.out.println("Headers: " + headers);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("消息头解析完毕!");
}
/**
* 解析消息正文
*/
private void parseContent() {
System.out.println("开始解析消息正文...");
System.out.println("消息正文解析完毕!");
}
/**
* 读取一行字符串,返回的字符串不含最后的CRLF
* @param in
* @return
* @throws IOException
*/
public String readLine() throws IOException {
StringBuilder builder = new StringBuilder();
int d = -1; //本次读取到的字节
char c1 = 'a'; //上次读取的字符
char c2 = 'a'; //本次读取的字符
while ((d = in.read()) != -1) {
c2 = (char)d;
if (c1 == 13 && c2 == 10) {
break;
}
builder.append(c2); //本次的拼接到字符串里
c1 = c2; //本次的给上次
}
return builder.toString().trim();
}
public String getMethod() {
return method;
}
public String getUrl() {
return url;
}
public String getProtocol() {
return protocol;
}
/**
* 根据给定的消息头的名字获取对应消息头的值
* @param name
* @return
*/
public String getHeader(String name) {
return headers.get(name);
}
public String getRequestURI() {
return requestURI;
}
public String getQueryString() {
return queryString;
}
/**
* 根据给定的参数名获取对应的参数值
* @param name
* @return
*/
public String getParameter(String name) {
return parameter.get(name);
}
}
截取结果的进一步解析 url 部分如下:
进一步解析url......
requestURI: /myweb/reg
queryString: username=zhangsan&password=123456&nickname=sansan&age=18
parameter: {password=123456, nickname=sansan, age=18, username=zhangsan}
解析url完毕!
看到我们成功按照需求解析好了哦。
2. 支持注册业务
当用户通过reg.html注册页面输入注册信息,并点击注册按钮提交注册表单信息后,服务端在解析该请求并在处理请求中添加分支判断,若该请求路径为请求注册业务,那么就应当实例化处理注册业务的逻辑类来完成该操作。
实现:
- 在
com.webserver包中新建一个包:servlets,在这个包中我们定义将来服务端所支持的所有业务处理类。 - 在
servlets包中定义处理注册业务的类:RegServlet,并定义一个service方法,用来处理注册业务。 - 在
ClientHandler处理请求的阶段添加一个分支判断,先根据请求路径requestURI来分析是否处理注册业务,若是,则实例化对应的业务类RegServlet,并调用其service方法来处理。
注: 我们不再使用HttpRequest中的url来判断请求了,因为 url 可能含有参数,而requestURI这个属性是请求的部分。 - 在
webapps/myweb目录中添加提示注册成功的页面reg_success.html,当RegServlet处理注册业务成功后,设置response响应此页面。
2.1 创建 RegServlet 类
在com.webserver包中新建一个包servlets,在这个包中我们定义将来服务端所支持的所有业务处理类:
在servlets包中定义处理注册业务的类RegServlet:

定义一个service方法,用来处理注册业务:
package com.webserver.servlets;
import com.webserver.http.HttpRequest;
import com.webserver.http.HttpResponse;
/**
* 处理注册业务
* @author returnzc
*
*/
public class RegServlet {
/**
* 处理具体业务操作的方法
* @param request
* @param response
*/
public void service(HttpRequest request, HttpResponse response) {
}
}
2.2 修改 ClientHandler 类
我们在请求注册页面的路径为/myweb/reg.html,而在页面上表单提交只写了action="reg",这时候浏览器会认为要提交的reg在当前目录下,即./reg,而当前目录是/myweb/,所以表单的提交路径是/myweb/reg。
在ClientHandler处理请求的阶段添加一个分支判断,先根据请求路径requestURI来分析是否处理注册业务,若是,则实例化对应的业务类RegServlet,并调用其service方法来处理。
注: 我们不再使用HttpRequest中的url来判断请求了,因为 url 可能含有参数,而requestURI这个属性是请求的部分。
首先修改如下(暂时还没有写处理注册业务的具体内容):
//String url = request.getUrl();
//上句修改为
String uri = request.getRequestURI();
//添加判断
if ("/myweb/reg".equals(uri)) {
System.out.println("处理注册!!");
}
目前 ClientHandler 的 run() 代码为:
public void run() {
try {
//解析请求
HttpRequest request = new HttpRequest(socket);
//创建响应
HttpResponse response = new HttpResponse(socket);
//处理请求
//String url = request.getUrl();
String uri = request.getRequestURI();
if ("/myweb/reg".equals(uri)) {
System.out.println("处理注册!!");
} else {
File file = new File("webapps" + uri);
if (file.exists()) {
System.out.println("该资源已找到!");
//将该资源响应给客户端
response.setEntity(file);
} else {
System.out.println("该资源不存在!");
response.setStatusCode(404);
response.setEntity(new File("webapps/root/404.html"));
}
}
//响应客户端
response.flush();
} catch (EmptyRequestException e) {
System.out.println("空请求");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
//响应完毕后与客户端断开连接
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
我们来运行一下,截取部分结果如下:
开始解析请求行...
请求行:GET /myweb/reg?username=zhangsan&password=123456&nickname=sansan&age=18 HTTP/1.1
进一步解析url......
requestURI: /myweb/reg
queryString: username=zhangsan&password=123456&nickname=sansan&age=18
parameter: {password=123456, nickname=sansan, age=18, username=zhangsan}
解析url完毕!
method: GET
url: /myweb/reg?username=zhangsan&password=123456&nickname=sansan&age=18
protocol: HTTP/1.1
请求行解析完毕!
开始解析消息头...
Headers: {Accept=text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9, Upgrade-Insecure-Requests=1, Connection=keep-alive, User-Agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36, Referer=http://localhost:9999/myweb/reg.html, Sec-Fetch-Site=same-origin, Sec-Fetch-Dest=document, Host=localhost:9999, Sec-Fetch-User=?1, Accept-Encoding=gzip, deflate, br, Accept-Language=zh-CN,zh-TW;q=0.9,zh;q=0.8,en-US;q=0.7,en;q=0.6, Sec-Fetch-Mode=navigate}
消息头解析完毕!
开始解析消息正文...
消息正文解析完毕!
处理注册!!
java.lang.NullPointerException
at java.base/java.io.FileInputStream.(FileInputStream.java:146)
at com.webserver.http.HttpResponse.sendContent(HttpResponse.java:88)
at com.webserver.http.HttpResponse.flush(HttpResponse.java:58)
at com.webserver.core.ClientHandler.run(ClientHandler.java:54)
at java.base/java.lang.Thread.run(Thread.java:832)
可以看到,我们的 requestURI 为 /myweb/reg,然后成功执行处理注册!!,然而,接下来会报NullPointerException(空指针异常),这是因为在走完注册部分之后,执行了response.flush();,而在这个方法中,我们会进行发送状态行、发送响应头、发送响应正文的操作,然鹅这时我们并没有响应正文,也没有通过response.setEntity(file);设置响应文件,所以这时HttpResponse的entity为null,我们需要对发送响应正文部分做一些修改,以避免NullPointerException。
很简单,只需要提前判断entity是否为null:
/**
* 发送响应正文
*/
public void sendContent() {
if (entity != null) {
try (
FileInputStream fis = new FileInputStream(entity);
) {
int len = -1;
byte[] data = new byte[1024*1024];
while ((len = fis.read(data)) != -1) {
out.write(data, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
再次运行,已经没有NullPointerException了。
接下来,在处理注册业务部分,实例化对应的业务类RegServlet,并调用其service方法来处理:
RegServlet servlet = new RegServlet();
servlet.service(request, response);
目前 ClientHandler 代码如下:
package com.webserver.core;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
import com.webserver.http.EmptyRequestException;
import com.webserver.http.HttpRequest;
import com.webserver.http.HttpResponse;
import com.webserver.servlets.RegServlet;
/**
* 处理客户端请求
* @author returnzc
*
*/
public class ClientHandler implements Runnable {
private Socket socket;
public ClientHandler(Socket socket) {
this.socket = socket;
}
public void run() {
try {
//解析请求
HttpRequest request = new HttpRequest(socket);
//创建响应
HttpResponse response = new HttpResponse(socket);
//处理请求
//String url = request.getUrl();
String uri = request.getRequestURI();
if ("/myweb/reg".equals(uri)) {
//System.out.println("处理注册!!");
RegServlet servlet = new RegServlet();
servlet.service(request, response);
} else {
File file = new File("webapps" + uri);
if (file.exists()) {
System.out.println("该资源已找到!");
//将该资源响应给客户端
response.setEntity(file);
} else {
System.out.println("该资源不存在!");
response.setStatusCode(404);
response.setEntity(new File("webapps/root/404.html"));
}
}
//响应客户端
response.flush();
} catch (EmptyRequestException e) {
System.out.println("空请求");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
//响应完毕后与客户端断开连接
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
2.3 创建注册成功页面
在webapps/myweb目录中添加提示注册成功的页面reg_success.html:
<html lang="zh">
<head>
<meta charset="UTF-8">
<title>注册成功title>
head>
<body>
<h1 align="center">恭喜您,注册成功!h1>
body>
html>
页面如下:

2.4 RegServlet 处理注册业务
注册业务流程:
- 通过 HttpRequest 获取用户提交的表单信息。
通过request.getParameter获取表单提交的数据,这里传递的参数应当与reg.html页面表单中对应输入框的名字一致,即name="xxxx"中 name 属性的值。 - 将该信息写入文件保存。
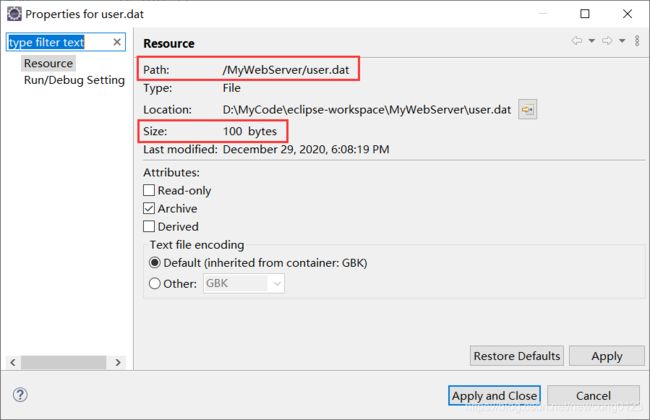
将该用户信息写入文件user.dat中,每条记录占用100字节,其中 username、password、nickname 为字符串,各占用 32 字节,age 为 int 值占用 4 字节。 - 响应客户端注册结果的页面。
2.4.1 处理注册业务
RegServlet处理注册业务,处理过程写在service方法中,当RegServlet处理注册业务成功后,设置response响应此页面:
package com.webserver.servlets;
import java.io.File;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.util.Arrays;
import com.webserver.http.HttpRequest;
import com.webserver.http.HttpResponse;
/**
* 处理注册业务
* @author returnzc
*
*/
public class RegServlet {
/**
* 处理具体业务操作的方法
* @param request
* @param response
*/
public void service(HttpRequest request, HttpResponse response) {
try (
RandomAccessFile raf = new RandomAccessFile("user.dat", "rw");
) {
System.out.println("RegServlet:开始处理注册");
//通过request.getParameter获取表单提交的数据
String username = request.getParameter("username");
String password = request.getParameter("password");
String nickname = request.getParameter("nickname");
int age = Integer.parseInt(request.getParameter("age"));
//先将指针移动到文件末尾
raf.seek(raf.length());
//写用户名
byte[] data = username.getBytes("UTF-8");
data = Arrays.copyOf(data, 32);
raf.write(data);
//写密码
data = password.getBytes("UTF-8");
data = Arrays.copyOf(data, 32);
raf.write(data);
//写昵称
data = nickname.getBytes("UTF-8");
data = Arrays.copyOf(data, 32);
raf.write(data);
//写年龄
raf.writeInt(age);
//响应客户端注册成功的页面
response.setEntity(new File("webapps/myweb/reg_success.html"));
System.out.println("RegServlet:处理注册完毕");
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行程序,进行注册,选取部分结果如下:
请求行:GET /myweb/reg?username=zhangsan&password=123456&nickname=sansan&age=18 HTTP/1.1
进一步解析url......
requestURI: /myweb/reg
queryString: username=zhangsan&password=123456&nickname=sansan&age=18
parameter: {password=123456, nickname=sansan, age=18, username=zhangsan}
解析url完毕!
method: GET
url: /myweb/reg?username=zhangsan&password=123456&nickname=sansan&age=18
protocol: HTTP/1.1
请求行解析完毕!
开始解析消息头...
Headers: {Accept=text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9, Upgrade-Insecure-Requests=1, Connection=keep-alive, User-Agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36, Referer=http://localhost:9999/myweb/reg.html, Sec-Fetch-Site=same-origin, Sec-Fetch-Dest=document, Host=localhost:9999, Sec-Fetch-User=?1, Accept-Encoding=gzip, deflate, br, Accept-Language=zh-CN,zh-TW;q=0.9,zh;q=0.8,en-US;q=0.7,en;q=0.6, Sec-Fetch-Mode=navigate}
消息头解析完毕!
开始解析消息正文...
消息正文解析完毕!
RegServlet:开始处理注册
RegServlet:处理注册完毕
从结果可以看到我们已经注册完毕,并弹出了 “恭喜您,注册成功!” 的页面。再看会发现,此时我们的项目目录下多出了一个user.dat文件,该文件为100字节:
2.4.1 验证是否为重复用户
我们注意到,正常上网用户名是不允许重复的,如果输入重复的用户名,会提示该用户已存在,这种提示是使用AJAX实现的,我们可以先在RegServlet中验证是否为重复用户。
首先我们先在webapps/myweb/下新建一个注册失败的页面reg_fail.html,并且可以加入重新注册的超链接:
<html lang="zh">
<head>
<meta charset="UTF-8">
<title>注册失败title>
head>
<body>
<h1 align="center">此用户已存在h1>
<a href="reg.html">重新注册a>
body>
html>
页面如下:

然后修改 RegServlet:
package com.webserver.servlets;
import java.io.File;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.util.Arrays;
import com.webserver.http.HttpRequest;
import com.webserver.http.HttpResponse;
/**
* 处理注册业务
* @author returnzc
*
*/
public class RegServlet {
/**
* 处理具体业务操作的方法
* @param request
* @param response
*/
public void service(HttpRequest request, HttpResponse response) {
try (
RandomAccessFile raf = new RandomAccessFile("user.dat", "rw");
) {
System.out.println("RegServlet:开始处理注册");
//通过request.getParameter获取表单提交的数据
String username = request.getParameter("username");
String password = request.getParameter("password");
String nickname = request.getParameter("nickname");
int age = Integer.parseInt(request.getParameter("age"));
//验证是否为重复用户,默认没这个人
boolean check = false;
//循环读取user.dat里的每一条记录(每条记录100字节)
for (int i = 0; i < raf.length() / 100; i++) {
raf.seek(i * 100);
byte[] arr = new byte[32];
raf.read(arr);
String name = new String(arr, "UTF-8").trim();
if (name.equals(username)) {
check = true; //有此用户了
break;
}
}
if (check) {
response.setEntity(new File("webapps/myweb/reg_fail.html"));
} else {
//先将指针移动到文件末尾
raf.seek(raf.length());
//写用户名
byte[] data = username.getBytes("UTF-8");
data = Arrays.copyOf(data, 32);
raf.write(data);
//写密码
data = password.getBytes("UTF-8");
data = Arrays.copyOf(data, 32);
raf.write(data);
//写昵称
data = nickname.getBytes("UTF-8");
data = Arrays.copyOf(data, 32);
raf.write(data);
//写年龄
raf.writeInt(age);
//响应客户端注册成功的页面
response.setEntity(new File("webapps/myweb/reg_success.html"));
}
System.out.println("RegServlet:处理注册完毕");
} catch (IOException e) {
e.printStackTrace();
}
}
}
用刚刚注册过的用户再注册一次,会发现成功跳出注册失败的页面,提醒此用户已存在,并且点击重新注册可以再次进入注册页面。
3. 实现登录功能
3.1 新建相关页面
3.1.1 登录页面
在webapps/myweb目录下新建登录页面login.html,该页面要求用户输入用户名及密码,form表单提交的action="login"。
<html lang="zh">
<head>
<meta charset="UTF-8">
<title>欢迎登陆title>
head>
<body>
<h1 align="center">欢迎登陆h1>
<form action="login" method="get">
<table align="center">
<tr>
<td>用户名:td>
<td><input type="text" name="username">td>
tr>
<tr>
<td>密码:td>
<td><input type="text" name="password">td>
tr>
<tr>
<td colspan="2" align="center">
<input type="submit" value="登陆">
td>
tr>
table>
form>
body>
html>
页面如下:
3.1.2 登录成功提示页面
在webapps/myweb目录下新建登录成功提示页面login_success.html:
<html lang="zh">
<head>
<meta charset="UTF-8">
<title>登陆成功title>
head>
<body>
<h1 align="center">恭喜您,登陆成功!h1>
body>
html>
页面如下:
3.1.3 登录失败提示页面
在webapps/myweb目录下新建登录成功提示页面login_fail.html:
<html lang="zh">
<head>
<meta charset="UTF-8">
<title>登陆失败title>
head>
<body>
<h1 align="center">登陆失败,请重新登陆h1>
<a href="login.html">返回登陆页面a>
body>
html>
页面如下:

3.2 定义 LoginServlet 类
在com.webserver.servlets包中添加一个类:LoginServlet:

在该类中定义service方法(同 RegServlet):
package com.webserver.servlets;
import com.webserver.http.HttpRequest;
import com.webserver.http.HttpResponse;
/**
* 登录业务
* @author returnzc
*
*/
public class LoginServlet {
public void service(HttpRequest request, HttpResponse response) {
System.out.println("开始处理登录");
System.out.println("处理登录完毕");
}
}
在service方法中首先通过request获取用户名、密码,然后通过RandomAccessFile读取user.dat文件,顺序读取每个用户的名字与该用户名比对,若找到则比对密码,若密码输入正确,则跳转登录成功页面;若密码输入错误,或该用户在user.dat文件中不存在,则跳转登录失败页面。
package com.webserver.servlets;
import java.io.File;
import java.io.IOException;
import java.io.RandomAccessFile;
import com.webserver.http.HttpRequest;
import com.webserver.http.HttpResponse;
/**
* 登录业务
* @author returnzc
*
*/
public class LoginServlet {
public void service(HttpRequest request, HttpResponse response) {
System.out.println("开始处理登录");
String username = request.getParameter("username");
String password = request.getParameter("password");
try ( RandomAccessFile raf = new RandomAccessFile("user.dat", "r") ) {
//默认是登录失败
boolean check = false;
for (int i = 0; i < raf.length() / 100; i++) {
raf.seek(i * 100);
byte[] data = new byte[32];
raf.read(data);
String name = new String(data, "UTF-8").trim();
if (name.equals(username)) {
//找到此用户,比对密码
raf.read(data);
String pwd = new String(data, "UTF-8").trim();
if (pwd.equals(password)) {
check = true; //验证成功
}
break; //找到这个用户就可以停了
}
}
if (check) {
//跳转登录成功页面
response.setEntity(new File("webapps/myweb/login_success.html"));
} else {
//跳转登录失败页面
response.setEntity(new File("webapps/myweb/login_fail.html"));
}
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("处理登录完毕");
}
}
3.3 修改 ClientHandler 类
在ClientHandler中再添加一个分支,判断请求路径是否为/myweb/login,若是,则实例化LoginServlet并调用其service方法处理登录。
具体如下:
package com.webserver.core;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
import com.webserver.http.EmptyRequestException;
import com.webserver.http.HttpRequest;
import com.webserver.http.HttpResponse;
import com.webserver.servlets.LoginServlet;
import com.webserver.servlets.RegServlet;
/**
* 处理客户端请求
* @author returnzc
*
*/
public class ClientHandler implements Runnable {
private Socket socket;
public ClientHandler(Socket socket) {
this.socket = socket;
}
public void run() {
try {
//解析请求
HttpRequest request = new HttpRequest(socket);
//创建响应
HttpResponse response = new HttpResponse(socket);
//处理请求
//String url = request.getUrl();
String uri = request.getRequestURI();
if ("/myweb/reg".equals(uri)) {
//System.out.println("处理注册!!");
RegServlet servlet = new RegServlet();
servlet.service(request, response);
} else if ("/myweb/login".equals(uri)) {
LoginServlet servlet = new LoginServlet();
servlet.service(request, response);
} else {
File file = new File("webapps" + uri);
if (file.exists()) {
System.out.println("该资源已找到!");
//将该资源响应给客户端
response.setEntity(file);
} else {
System.out.println("该资源不存在!");
response.setStatusCode(404);
response.setEntity(new File("webapps/root/404.html"));
}
}
//响应客户端
response.flush();
} catch (EmptyRequestException e) {
System.out.println("空请求");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
//响应完毕后与客户端断开连接
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
这部分可以自行运行测试。
4. 解决地址栏传递中文问题
由于HTTP协议要求,其协议内出现的字符串不允许使用中文,因为HTTP协议使用的是ISO8859-1编码,这是一个欧洲的编码集,不支持中文。
因此,我们常见的解决办法为将中文按照UTF-8编码转换为3个字节,然后每个字节以%XX的三个字符形式表示一个字节,然后将这些内容拼接在地址栏中传递。%XX这里的内容为2位16进制,2位16进制可以表示一个8位2进制,因此2位16进制表示1字节内容。
URL 中若出现中文,转换的过程为:
- 将该中文按照 UTF-8 编码转换为3个字节。
- 将每个字节以2位16进制形式表示,前面拼接一个
%。 - 将改变后的内容替换原中文部分。
java API 提供了对字符串中含有的%XX解析的类URLDecoder,我们直接使用即可对 url 中的中文进行还原。
修改 HttpRequest 类,在解析出参数部分后,对参数内容解码,将%XX这样的内容还原为对应文字,使得服务端能正确支持对应字符。
只需要修改 HttpRequest 类中的 parseUrl 方法,主要修改为:
try {
System.out.println("解码前queryString:" + queryString);
queryString = URLDecoder.decode(queryString, "UTF-8");
System.out.println("解码后queryString:" + queryString);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
此时 HttpRequest 代码如下:
package com.webserver.http;
import java.io.IOException;
import java.io.InputStream;
import java.io.UnsupportedEncodingException;
import java.net.Socket;
import java.net.URLDecoder;
import java.util.HashMap;
import java.util.Map;
/**
* 请求对象
* 每个实例表示客户端发送过来的一个具体请求
* @author returnzc
*
*/
public class HttpRequest {
/*
* 请求行相关信息定义
*/
private String method; //请求方式
private String url; //资源路径
private String protocol; //协议版本
private String requestURI;
private String queryString;
private Map<String, String> parameter = new HashMap<String, String>();
/*
* 消息头相关信息定义
*/
private Map<String, String> headers = new HashMap<String, String>();
/*
* 消息正文相关信息定义
*/
/*
* 客户端连接相关信息
*/
private Socket socket;
private InputStream in;
public HttpRequest(Socket socket) throws EmptyRequestException {
try {
this.socket = socket;
this.in = socket.getInputStream();
/*
* 解析请求的过程:
* 1. 解析请求行
* 2. 解析消息头
* 3. 解析消息正文
*/
parseRequestLine();
parseHeaders();
parseContent();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 解析请求行
* @throws EmptyRequestException
*/
private void parseRequestLine() throws EmptyRequestException {
System.out.println("开始解析请求行...");
try {
String line = readLine();
System.out.println("请求行:" + line);
//若请求行内容是一个空串,则是空请求
if ("".equals(line)) {
throw new EmptyRequestException();
}
//将请求行进行拆分,将每部分内容对应的设置到属性上
String[] data = line.split("\\s");
this.method = data[0];
this.url = data[1];
this.protocol = data[2];
parseUrl(); //进一步解析url
System.out.println("method: " + method);
System.out.println("url: " + url);
System.out.println("protocol: " + protocol);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("请求行解析完毕!");
}
private void parseUrl() {
System.out.println("进一步解析url......");
//判断请求路径中是否含有"?"
if (url.indexOf("?") != -1) {
//按照"?"将url拆分为两部分
String[] data = url.split("\\?");
requestURI = data[0];
//看url的"?"后面是否有内容
if (data.length > 1) {
queryString = data[1];
try {
System.out.println("解码前queryString:" + queryString);
queryString = URLDecoder.decode(queryString, "UTF-8");
System.out.println("解码后queryString:" + queryString);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
//拆分每个参数
data = queryString.split("&");
for (String paraLine : data) {
//按照"="将参数拆分为两部分
String[] paraArr = paraLine.split("=");
//判断该参数是否有值
if (paraArr.length > 1) {
parameter.put(paraArr[0], paraArr[1]);
} else {
parameter.put(paraArr[0], null);
}
}
}
} else {
requestURI = url;
}
System.out.println("requestURI: " + requestURI);
System.out.println("queryString: " + queryString);
System.out.println("parameter: " + parameter);
System.out.println("解析url完毕!");
}
/**
* 解析消息头
*/
private void parseHeaders() {
System.out.println("开始解析消息头...");
try {
while (true) {
String line = readLine();
if ("".equals(line)) {
break;
}
String[] data = line.split(":\\s");
headers.put(data[0], data[1]);
}
System.out.println("Headers: " + headers);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("消息头解析完毕!");
}
/**
* 解析消息正文
*/
private void parseContent() {
System.out.println("开始解析消息正文...");
System.out.println("消息正文解析完毕!");
}
/**
* 读取一行字符串,返回的字符串不含最后的CRLF
* @param in
* @return
* @throws IOException
*/
public String readLine() throws IOException {
StringBuilder builder = new StringBuilder();
int d = -1; //本次读取到的字节
char c1 = 'a'; //上次读取的字符
char c2 = 'a'; //本次读取的字符
while ((d = in.read()) != -1) {
c2 = (char)d;
if (c1 == 13 && c2 == 10) {
break;
}
builder.append(c2); //本次的拼接到字符串里
c1 = c2; //本次的给上次
}
return builder.toString().trim();
}
public String getMethod() {
return method;
}
public String getUrl() {
return url;
}
public String getProtocol() {
return protocol;
}
/**
* 根据给定的消息头的名字获取对应消息头的值
* @param name
* @return
*/
public String getHeader(String name) {
return headers.get(name);
}
public String getRequestURI() {
return requestURI;
}
public String getQueryString() {
return queryString;
}
/**
* 根据给定的参数名获取对应的参数值
* @param name
* @return
*/
public String getParameter(String name) {
return parameter.get(name);
}
}
运行服务端,输入中文注册信息,弹出显示注册成功页面,截取部分运行结果如下:
开始解析请求行...
请求行:GET /myweb/reg?username=%E5%BC%A0%E4%B8%89&password=123456&nickname=hello&age=22 HTTP/1.1
进一步解析url......
解码前queryString:username=%E5%BC%A0%E4%B8%89&password=123456&nickname=hello&age=22
解码后queryString:username=张三&password=123456&nickname=hello&age=22
requestURI: /myweb/reg
queryString: username=张三&password=123456&nickname=hello&age=22
parameter: {password=123456, nickname=hello, age=22, username=张三}
解析url完毕!
method: GET
url: /myweb/reg?username=%E5%BC%A0%E4%B8%89&password=123456&nickname=hello&age=22
protocol: HTTP/1.1
请求行解析完毕!
开始解析消息头...
Headers: {Accept=text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9, Upgrade-Insecure-Requests=1, Connection=keep-alive, User-Agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36, Referer=http://localhost:9999/myweb/reg.html, Sec-Fetch-Site=same-origin, Sec-Fetch-Dest=document, Host=localhost:9999, Sec-Fetch-User=?1, Accept-Encoding=gzip, deflate, br, Accept-Language=zh-CN,zh-TW;q=0.9,zh;q=0.8,en-US;q=0.7,en;q=0.6, Sec-Fetch-Mode=navigate}
消息头解析完毕!
开始解析消息正文...
消息正文解析完毕!
RegServlet:开始处理注册
RegServlet:处理注册完毕
用刚刚中文用户名进行登录,也可以成功登陆,截取部分结果如下:
开始解析请求行...
请求行:GET /myweb/login?username=%E5%BC%A0%E4%B8%89&password=123456 HTTP/1.1
进一步解析url......
解码前queryString:username=%E5%BC%A0%E4%B8%89&password=123456
解码后queryString:username=张三&password=123456
requestURI: /myweb/login
queryString: username=张三&password=123456
parameter: {password=123456, username=张三}
解析url完毕!
method: GET
url: /myweb/login?username=%E5%BC%A0%E4%B8%89&password=123456
protocol: HTTP/1.1
请求行解析完毕!
开始解析消息头...
Headers: {Accept=text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9, Upgrade-Insecure-Requests=1, Connection=keep-alive, User-Agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36, Referer=http://localhost:9999/myweb/login.html, Sec-Fetch-Site=same-origin, Sec-Fetch-Dest=document, Host=localhost:9999, Sec-Fetch-User=?1, Accept-Encoding=gzip, deflate, br, Accept-Language=zh-CN,zh-TW;q=0.9,zh;q=0.8,en-US;q=0.7,en;q=0.6, Sec-Fetch-Mode=navigate}
消息头解析完毕!
开始解析消息正文...
消息正文解析完毕!
开始处理登录
处理登录完毕
按照惯例,下篇见~

参考
《Java核心技术》(原书第10版)
相关文章
以后添加