基于前程无忧平台数据分析师岗位的薪资水平分析(一)
(Python小白,第一次整合)通过自学相关课程,计划通过实现从数据获取到具体分析的每一步,借整个过程来积累基础语法及常用库实战经验。
目录
- 1、数据爬取
- 2、数据清洗
-
- 2.1 缺失值处理
- 2.2 字段规整
- 2.3 文本处理
- 3、变量处理
-
- 3.1 城市地区划分修改
- 3.2 修改其他字段
- 3.3 设置哑变量
- 4、特征选择
-
- 4.1 过滤法
- 4.2 随机森林筛选变量
- 4.3 递归消除法筛选变量
- 5、模型比较及参数调参
-
- 5.1 划分数据集
- 5.2 多模型训练
- 5.3 模型比较
- 5.4 模型确定
- 6、预测
-
- 6.1 预测工资下限
- 6.2 预测工资上限
- 小结
1、数据爬取
import requests
from lxml import etree
import time
import re
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
start_time=time.time()
f=open('51job_list.csv','w',encoding='utf-8')
list=['职位名称','薪资水平','公司名称','所在地区','所需经验','学历要求','岗位描述']
for a in list:
f.write(a)
f.write(',')
f.write('\n')
for i in range(1,51):
print("正在爬取第" + str(i) + "页的数据")
url0 = "https://search.51job.com/list/****,2,"
url_end = ".html?"
url = url0 + str(i) + url_end
res = requests.get(url=url, headers=headers)
res.encoding = "gbk"
p=res.text
ex=r'job_href\":(.*?),'
p1=re.findall(ex,p) #找出对应职位详情页链接
for a in range(len(p1)):
url=p1[a][1:-1].replace("\\","")
page=requests.get(url=url,headers=headers)
page.encoding='gbk'
tree=etree.HTML(page.text) #解析
#获取岗位标题
title=tree.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/h1/text()')[0:1]
if len(title) !=0:
f.write(title[0])
else:
f.write('NULL')
f.write(',')
#获取薪资水平
salary=tree.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/strong/text()')[0:1]
#print(salary)
if len(salary) !=0:
f.write(salary[0])
else:
f.write('NULL')
f.write(',')
#获取公司名称
company=tree.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[1]/a[1]/text()')[0:1]
if len(company) !=0:
f.write(company[0])
else:
f.write('NULL')
f.write(',')
pos=tree.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/@title')
for a in pos:
if a is not None:
#获取位置
position=a.split(r'|')[0].replace(u'\xa0', u'')
f.write(position)
f.write(',')
#获取所需经验
year=a.split(r'|')[1].replace(u'\xa0', u'')
f.write(year)
f.write(',')
#获取学历要求
degree=a.split(r'|')[2].replace(u'\xa0', u'')
f.write(degree)
f.write(',')
#获取岗位描述与任职要求
lst1=tree.xpath('//div[@class="bmsg job_msg inbox"]//text()')
a=[]
for i in lst1:
de1=i.replace(u'\xa0',u"")
if len(de1) !=0:
a.append(de1)
work=",".join(a).replace(" ","").replace(u"\r\n",",").replace(",",",") #去掉空白、换行、英文逗号
f.write(work)
f.write('\n')
time.sleep(0.5)
f.close()
end_time=time.time()
print("爬取完毕!爬取时长%s秒"%(end_time-start_time))
2、数据清洗
2.1 缺失值处理
import pandas as pd
import numpy as np
da0=pd.read_csv('51job_list.csv',encoding='utf-8',error_bad_lines=False)
da1=da0.iloc[:,0:7]
da1=da1.dropna(how='all')
da1.count(axis=0) #计算每行非缺失值的个数
#loc 为缺失值所在行数,可以提取出来另做安排
for columname in da1.columns:
if da1[columname].count() != len(da1):
loc = da1[columname][da1[columname].isnull().values==True].index.tolist()
print('列名:"{}", 第{}行位置有缺失值'.format(columname,loc))
2.2 字段规整
(1) 所在城市
for b in da1.index:
da1['所在地区'][b]=da1['所在地区'][b].split('-')[0]
da1['所在地区'].value_counts()
(2) 学历与经验
(两个字段有交叉)
lst=['本科', '大专', '硕士', '中专', '高中', '中技', '博士']
e1=['3-4年经验','1年经验','2年经验','无需经验','在校生/应届生','5-7年经验','10年以上经验','8-9年经验']
for i in da1.index:
if (da1.loc[i,'所需经验'] in lst):
da1.loc[i,'学历要求']=da1.loc[i,'所需经验']
da1.loc[i,'所需经验']='未注明'
elif (da1.loc[i,'所需经验'] in e1):
pass
else:
da1.loc[i,'所需经验']='未注明'
for i in da1.index:
if (da1.loc[i,'学历要求'] in lst):
pass
else:
da1.loc[i,'学历要求']='未注明'
(3) 薪资水平
统一薪资水平单位,并拆分成上下限
import re
da1['工资上下限']=''
da1['工资单位']=''
da1['工资上限']=''
da1['工资下限']=''
#用到上面计算的loc确实行索引值
ls=['万/月 ','千/月','万/年','元/天']
for u in da1.index:
if u not in loc:
z=da1['薪资水平'][u]
da1['工资上下限'][u]=re.split(r'(.*?)([万,千,元]/[年,月,天])',z)[1]
da1['工资单位'][u]=re.split(r'(.*?)([万,千,元]/[年,月,天])',z)[2]
if "-" in da1['工资上下限'][u]:
t=da1['工资上下限'][u]
da1['工资下限'][u]=t.split('-')[0]
da1['工资上限'][u]=t.split('-')[1]
if da1['工资单位'][u]==ls[1]:
da1['工资下限'][u]=eval(t.split('-')[0])/10
da1['工资上限'][u]=eval(t.split('-')[1])/10
elif da1['工资单位'][u]==ls[2]:
da1['工资下限'][u]=eval(t.split('-')[0])/12
da1['工资上限'][u]=eval(t.split('-')[1])/12
elif da1['工资单位'][u]==ls[3]:
da1['工资下限'][u]=eval(t.split('-')[0])*30
da1['工资上限'][u]=eval(t.split('-')[1])*30
else:
pass
#剔除元/天的行
for i in da1.index:
if da1['工资单位'][i]=='元/天':
da1=da1[~(da1.index==i)]
(4) 更改列名
da1=da1.rename(columns={"工资上限":"薪资上限(万/月)","工资下限":"薪资下限(万/月)"})
da2=da1[['职位名称','所在地区','所需经验','薪资上限(万/月)','薪资下限(万/月)','学历要求','岗位描述']]
2.3 文本处理
很多企业对该岗位在任职要求及岗位描述两字段的描述比较相近,部分企业在二者中只选了其一进行概述,因此在数据爬取中将两个字段合并提取。
该部分主要处理步骤:
(1) 使用jieba库对文本内容进行分词,并分别绘制初步的中、英文词云图;
(2) 在前两步的基础上,使用停用词,并结合(1)词云图中出现选出无关岗位的词加入停用词中;
(3) 重新绘制中英文词云图;
(4) 分别对中英文字段进行词频统计,选出前10个高频词,中英文共计20个放入数据框中;
(5) 将这些词作为新变量拆分到新列中。
(1) 文本内容分词
import jieba
import wordcloud
from imageio import imread
import matplotlib.pyplot as plt
# 使用jieba库进行分词,生成字符串,如果不通过分词,无法直接生成正确的中文词云
lsa=jieba.lcut(wb) #列表
# 使用join()方法,将分词生成的字符串以空格进行分割。因为在生成词云时,字符串之间需要为空格
txt=' '.join(lsa) #字符串
w=wordcloud.WordCloud(font_path='SimSun.ttf',width=1600,height=1200,background_color='white',max_words = 200,max_font_size = 80)
plt.figure(figsize=(10,7))
plt.imshow(w.generate(txt))
plt.axis("off")
plt.show()
w.to_file('词云图前.png')
# 去掉英文,保留中文
resultword=re.sub("[0-9\u4e00-\u9fa5\[\`\~\!\@\#\$\^\&\*\(\)\=\|\{\}\'\:\;\'\,\[\]\.\<\>\/\?\~\。\@\#\\\&\*\%\-]", "",wb)
# 现在去掉了中文和标点符号
wordlist_after_jieba = jieba.cut(resultword)
wl_space_split = " ".join(wordlist_after_jieba)
my_wordcloud =wordcloud. WordCloud(font_path='/SimSun.ttf',scale=4,background_color='white',
max_words = 200,max_font_size = 60,random_state=20).generate(wl_space_split)
plt.figure(figsize=(10,7))
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
my_wordcloud.to_file('软件词云图前.jpg')

岗位描述高频词中文词云图

岗位描述英文词云图
(2) 加入停用词
# 读取停用词数据
stopwords = pd.read_csv('E:/pachong/stopwords.txt', encoding='gbk', names=['stopword'], index_col=False)
# 转化词列表
stop_list = stopwords['stopword'].tolist()
stop_bc=['微信','分享','职能','类别','公司','团队','岗位',
'相关','分析师','工作','岗位职责','优先','负责',
'关键字','年','以上学历','具备','行业','提供','数据']
for i in stop_bc:
stop_list.append(i)
# 去除停用词
word_lst= da2.iloc[:,-1].apply(lambda x : [i for i in jieba.lcut(x) if i not in stop_list]) #series
(3) 重新绘制中英文词云图
#中文
plt.figure(figsize=(10,7))
w1=wordcloud.WordCloud(font_path='SimSun.ttf',background_color='white',
scale=4,random_state=20,font_step=3,max_font_size = 50,max_words=150)
plt.imshow(w1.generate(" ".join(words)))
plt.axis("off")
plt.show()
#w.generate(txt)
w1.to_file('词云图后.png')
#英文
plt.figure(figsize=(10,7))
w2=wordcloud.WordCloud(font_path='SimSun.ttf',background_color='white',
scale=4,random_state=20,font_step=3,max_font_size = 50,max_words=100)
plt.imshow(w2.generate(" ".join(e_lst)))
plt.axis("off")
plt.show()
w2.to_file('软件词云图后.jpg')

规范后中文词云图

规范后英文词云图
(4) 词频统计
#中文
# 将所有的分词合并
words = []
for i in word_lst:
content=" ".join(i) #da_st[i]是个列表
line = re.sub(r"[0-9\s+\.\!\/_,$%^*()?;;:-【】+\"\']+|[+——!,;:。?、~@#¥%……&*()]+"," ",content)
lst=re.split(" ",line)
lst1 = [x for x in lst if x != '']
words.extend(lst1)
#print(lst1)
# 创建分词数据框
corpus = pd.DataFrame(words, columns=['word'])
corpus['cnt'] = 1
# 分组统计
g = corpus.groupby(['word']).agg({'cnt': 'count'}).sort_values('cnt', ascending=False)
g.head(10)
#英文
# 去掉英文,保留中文
resultword=re.sub("[0-9\u4e00-\u9fa5\[\`\~\!\@\#\$\^\&\*\(\)\=\|\{\}\'\:\;\'\,\[\]\.\<\>\/\?\~\。\@\#\\\&\*\%\-]", "",wb)
wordlist_after_jieba = jieba.cut(resultword)
wl_space_split = " ".join(wordlist_after_jieba) #字符串
e_lst=re.sub('[^a-zA-Z]',' ',wl_space_split).split() #匹配字符串后以空格分割
e_lst=[s.capitalize() for s in e_lst] #为避免工具的大小写导致分开计算,将所有英文规范,capitalize() 开头大写,low()全部小写,upper()大写
# 创建分词数据框
eng = pd.DataFrame(e_lst, columns=['tool'])
eng['cnt'] = 1
# 分组统计
h= eng.groupby(['tool']).agg({'cnt': 'count'}).sort_values('cnt', ascending=False)
h.head(10)
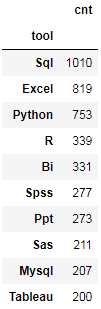 英文高频词
英文高频词
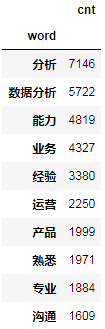
中文高频词
(5) 拆分放入列表
#放入表中
dp=word_lst.values
da3=da2.reset_index()
da3['JD']=''
for i in range(len(da3)):
con=" ".join(dp[i])
li = re.sub(r"[0-9\s+\.\!\/_,$%^*()?;;:-【】+\"\']+|[+——!,;:。?、~@#¥%……&*()]+"," ",con)
lt=re.split(" ",li)
lt1 = ",".join([x for x in lt if x != ''])
da3['JD'][i]=lt1
da3=da3.set_index('index')
#拆分
Chi=g.index[0:10] #中文前十个
Eng=h.index[0:10] #英文前十个
for i in range(0,10):
n=Chi[i]
da3[n]=''
for j in da3.index:
if Chi[i] in da3.JD[j]:
da3[n][j]='T'
else:
da3[n][j]='F'
for i in range(0,10):
m=Eng[i]
da3[m]=''
for j in da3.index:
if Chi[i] in da3.JD[j]:
da3[m][j]='T'
else:
da3[m][j]='F'
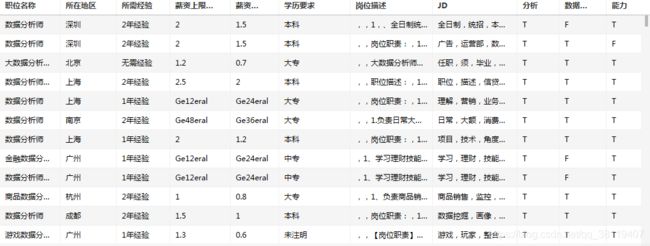
拆分后的数据表
3、变量处理
#重新读取数据删除部分字段,更改列顺序
data=df.drop(columns={'职位名称','岗位描述','JD','数据分析','专业','熟悉','经验','能力'}).iloc[:,:-5]
df_1 = data['薪资上限(万/月)']
df_2 = data['薪资下限(万/月)']
df_3 = data.drop(columns={'薪资下限(万/月)','薪资上限(万/月)'},axis=1)
df_3['薪资下限(万/月)']=df_2
df_3['薪资上限(万/月)']=df_1
#提取缺失数据行作为待测数据集
qs_loc=[]
for j in df_3.columns:
if df_3[j].count()!=len(df_3):
qs_loc=df_3[j][df_3[j].isnull().values==True].index.tolist()
#df_3[j][df_3[j].isnull().values==True].index.tolist() 找出每列缺失值的索引,存为list
#qs_loc
pre=df_3[df_3.index.isin(qs_loc)] #将缺失行提取出来
tra_tes=df_3[~df_3.index.isin(qs_loc)] #完整数据
# 批量替换变量值
for i in tra_tes.columns[3:13]:
tra_tes[i]=tra_tes[i].map(lambda x: 1 if x=='T' else 0)
print(tra_tes)
3.1 城市地区划分修改
根据第一部分中,数据清理后得到的城市名称比较冗杂(有些岗位城市为区县,且出现较少),因此对所有城市的名称统一规划到省域。为便于后续的计算,进一步将省域划分为:东北、华北、华东、中南、西南、西北。
(1) 对城市作词云图
city=tra_tes['所在地区'].values.tolist()
plt.figure(figsize=(8,7))
w3=wordcloud.WordCloud(font_path='SimSun.ttf',background_color='gray',
scale=4,random_state=20,font_step=4,max_font_size = 50,max_words=100)
plt.imshow(w3.generate(" ".join(city)))
plt.axis("off")
plt.show()
w3.to_file('城市词云图.jpg')

城市词云图
(2) 城市匹配
tra_tes['所在省份']=''
if __name__ == '__main__':
area_data = {
'北京': ['北京市','朝阳区', '海淀区', '通州区', '房山区', '丰台区', '昌平区', '大兴区', '顺义区', '西城区', '延庆县', '石景山区', '宣武区', '怀柔区', '崇文区', '密云县',
'东城区', '门头沟区', '平谷区'],
'广东':['广东省', '东莞市', '广州市', '中山市', '深圳市', '惠州市', '江门市', '珠海市', '汕头市', '佛山市', '湛江市', '河源市', '肇庆市','潮州市', '清远市', '韶关市', '揭阳市', '阳江市', '云浮市', '茂名市', '梅州市', '汕尾市'],
'山东':['山东省', '济南市', '青岛市', '临沂市', '济宁市', '菏泽市', '烟台市','泰安市', '淄博市', '潍坊市', '日照市', '威海市', '滨州市', '东营市', '聊城市', '德州市', '莱芜市', '枣庄市'],
'江苏':['江苏省', '苏州市', '徐州市', '盐城市', '无锡市','南京市', '南通市', '连云港市', '常州市', '扬州市', '镇江市', '淮安市', '泰州市', '宿迁市','常熟市','张家港市','丹阳'],
'河南':['河南省', '郑州市', '南阳市', '新乡市', '安阳市', '洛阳市', '信阳市','平顶山市', '周口市', '商丘市', '开封市', '焦作市', '驻马店市', '濮阳市', '三门峡市', '漯河市', '许昌市', '鹤壁市', '济源市'],
'上海':['上海市', '松江区', '宝山区', '金山区','嘉定区', '南汇区', '青浦区', '浦东新区', '奉贤区', '闵行区', '徐汇区', '静安区', '黄浦区', '普陀区', '杨浦区', '虹口区', '闸北区', '长宁区', '崇明县', '卢湾区'],
'河北':[ '河北省', '石家庄市', '唐山市', '保定市', '邯郸市', '邢台市', '河北区', '沧州市', '秦皇岛市', '张家口市', '衡水市', '廊坊市', '承德市','雄安新区'],
'浙江':['浙江省', '温州市', '宁波市','杭州市', '台州市', '嘉兴市', '金华市', '湖州市', '绍兴市', '舟山市', '丽水市', '衢州市','义乌市','昆山'],
'陕西':['陕西省', '西安市', '咸阳市', '宝鸡市', '汉中市', '渭南市','安康市', '榆林市', '商洛市', '延安市', '铜川市'],
'湖南':[ '湖南省', '长沙市', '邵阳市', '常德市', '衡阳市', '株洲市', '湘潭市', '永州市', '岳阳市', '怀化市', '郴州市','娄底市', '益阳市', '张家界市', '湘西州'],
'重庆':[ '重庆市', '江北区', '渝北区', '沙坪坝区', '九龙坡区', '万州区', '永川市', '南岸区', '酉阳县', '北碚区', '涪陵区', '秀山县', '巴南区', '渝中区', '石柱县', '忠县', '合川市', '大渡口区', '开县', '长寿区', '荣昌县', '云阳县', '梁平县', '潼南县', '江津市', '彭水县', '璧山县', '綦江县',
'大足县', '黔江区', '巫溪县', '巫山县', '垫江县', '丰都县', '武隆县', '万盛区', '铜梁县', '南川市', '奉节县', '双桥区', '城口县'],
'福建':['福建省', '漳州市', '泉州市','厦门市', '福州市', '莆田市', '宁德市', '三明市', '南平市', '龙岩市'],
'天津':['天津市', '和平区', '北辰区', '河北区', '河西区', '西青区', '津南区', '东丽区', '武清区','宝坻区', '红桥区', '大港区', '汉沽区', '静海县', '宁河县', '塘沽区', '蓟县', '南开区', '河东区'],
'云南':[ '云南省', '昆明市', '红河州', '大理州', '文山州', '德宏州', '曲靖市', '昭通市', '楚雄州', '保山市', '玉溪市', '丽江地区', '临沧地区', '思茅地区', '西双版纳州', '怒江州', '迪庆州'],
'四川':['四川省', '成都市', '绵阳市', '广元市','达州市', '南充市', '德阳市', '广安市', '阿坝州', '巴中市', '遂宁市', '内江市', '凉山州', '攀枝花市', '乐山市', '自贡市', '泸州市', '雅安市', '宜宾市', '资阳市','眉山市', '甘孜州'],
'广西':['广西壮族自治区', '贵港市', '玉林市', '北海市', '南宁市', '柳州市', '桂林市', '梧州市', '钦州市', '来宾市', '河池市', '百色市', '贺州市', '崇左市', '防城港市'],
'安徽':['安徽省', '芜湖市', '合肥市', '六安市', '宿州市', '阜阳市','安庆市', '马鞍山市', '蚌埠市', '淮北市', '淮南市', '宣城市', '黄山市', '铜陵市', '亳州市','池州市', '巢湖市', '滁州市'],
'海南':['海南省', '三亚市', '海口市', '琼海市', '文昌市', '东方市', '昌江县', '陵水县', '乐东县', '五指山市', '保亭县', '澄迈县', '万宁市','儋州市', '临高县', '白沙县', '定安县', '琼中县', '屯昌县'],
'江西':['江西省', '南昌市', '赣州市', '上饶市', '吉安市', '九江市', '新余市', '抚州市', '宜春市', '景德镇市', '萍乡市', '鹰潭市'],
'湖北':['湖北省', '武汉市', '宜昌市', '襄阳市', '荆州市', '恩施州', '孝感市', '黄冈市', '十堰市', '咸宁市', '黄石市', '仙桃市', '随州市', '天门市', '荆门市', '潜江市', '鄂州市', '神农架林区'],
'山西':['山西省', '太原市', '大同市', '运城市', '长治市', '晋城市', '忻州市', '临汾市', '吕梁市', '晋中市', '阳泉市', '朔州市'],
'辽宁':['辽宁省', '大连市', '沈阳市', '丹东市', '辽阳市', '葫芦岛市', '锦州市', '朝阳市', '营口市', '鞍山市', '抚顺市', '阜新市', '本溪市', '盘锦市', '铁岭市'],
'台湾':['台湾省','台北市', '高雄市', '台中市', '新竹市', '基隆市', '台南市', '嘉义市'],
'黑龙江':['黑龙江', '齐齐哈尔市', '哈尔滨市', '大庆市', '佳木斯市', '双鸭山市', '牡丹江市', '鸡西市','黑河市', '绥化市', '鹤岗市', '伊春市', '大兴安岭地区', '七台河市'],
'内蒙古':['内蒙古自治区', '赤峰市', '包头市', '通辽市', '呼和浩特市', '乌海市', '鄂尔多斯市', '呼伦贝尔市','兴安盟', '巴彦淖尔盟', '乌兰察布盟', '锡林郭勒盟', '阿拉善盟'],
'香港':["香港","香港特别行政区"],
'澳门':['澳门','澳门特别行政区'],
'贵州':['贵州省', '贵阳市', '黔东南州', '黔南州', '遵义市', '黔西南州', '毕节地区', '铜仁地区','安顺市', '六盘水市'],
'甘肃':['甘肃省', '兰州市', '天水市', '庆阳市', '武威市', '酒泉市', '张掖市', '陇南地区', '白银市', '定西地区', '平凉市', '嘉峪关市', '临夏回族自治州','金昌市', '甘南州'],
'青海':['青海省', '西宁市', '海西州', '海东地区', '海北州', '果洛州', '玉树州', '黄南藏族自治州'],
'新疆':['新疆','新疆维吾尔自治区', '乌鲁木齐市', '伊犁州', '昌吉州','石河子市', '哈密地区', '阿克苏地区', '巴音郭楞州', '喀什地区', '塔城地区', '克拉玛依市', '和田地区', '阿勒泰州', '吐鲁番地区', '阿拉尔市', '博尔塔拉州', '五家渠市',
'克孜勒苏州', '图木舒克市'],
'西藏':['西藏区', '拉萨市', '山南地区', '林芝地区', '日喀则地区', '阿里地区', '昌都地区', '那曲地区'],
'吉林':['吉林省', '吉林市', '长春市', '白山市', '白城市','延边州', '松原市', '辽源市', '通化市', '四平市'],
'宁夏':['宁夏回族自治区', '银川市', '吴忠市', '中卫市', '石嘴山市', '固原市']
}
for k,v in area_data.items():
for i in v:
for m in tra_tes.index:
if tra_tes['所在地区'][m] in i:
tra_tes['所在省份'][m]=k
(3) 对省市作词云图
province=tra_tes['所在省份'].values.tolist()
plt.figure(figsize=(7,6))
w5=wordcloud.WordCloud(font_path='SimSun.ttf',background_color='black',
scale=4,random_state=20,font_step=4,max_font_size = 50,max_words=100)
plt.imshow(w5.generate(" ".join(province)))
plt.axis("off")
plt.show()
w5.to_file('省份词云图.jpg')

省域词云图
(4) 进一步划分到六大区域
tra_tes['地理区域']=''
if __name__ == '__main__':
area_dict = {
'华北': ['北京','天津','河北','山西','内蒙古'],
'东北':['辽宁','吉林','黑龙江'],
'华东':['上海','江苏','浙江','安徽','福建','江西','山东'],
'中南':['河南','湖北','湖南','广东','广西','海南'],
'西南':['重庆','四川','贵州','云南','西藏'],
'西北':['陕西','甘肃','青海','宁夏','新疆']
}
for k,v in area_dict.items():
for i in v:
for m in tra_tes.index:
if tra_tes['所在省份'][m] in i:
tra_tes['地理区域'][m]=k
3.2 修改其他字段
一些分类字段个别分类数量较少,为减少分类字段的分类数以便数据有效,将所需经验需要5年以上的都归于5-7年经验中;将学历要求硕士及以上的都归于硕士及以上。
tra_tes['所需经验'].value_counts()
tra_tes['经验']=''
for i in tra_tes.index:
if tra_tes['所需经验'][i]=='10年以上经验' or tra_tes['所需经验'][i]=='8-9年经验':
tra_tes['经验'][i]='5-7年经验'
else:
tra_tes['经验'][i]=tra_tes['所需经验'][i]
tra_tes['学历']=''
for i in tra_tes.index:
if tra_tes['学历要求'][i]=='博士' or tra_tes['学历要求'][i]=='硕士':
tra_tes['学历'][i]='硕士及以上'
elif tra_tes['学历要求'][i]=='未注明':
tra_tes['学历'][i]='未注明学历要求'
elif tra_tes['学历要求'][i]=='本科':
tra_tes['学历'][i]='本科'
else:
tra_tes['学历'][i]='专科及以下'
3.3 设置哑变量
注:便于特征筛选与模型建立,对多分类变量作哑变量处理。
#选取最终需要的字段
train_test=tra_tes[['地理区域','经验','学历','分析','业务','运营','产品','沟通','Sql','Excel','Python','R','Bi','薪资上限(万/月)','薪资下限(万/月)']]
#分类变量哑变量处理
train_test_data=pd.get_dummies(train_test['地理区域'],prefix='地理区域').join(pd.get_dummies(train_test['经验'],prefix='经验')).join(pd.get_dummies(train_test['学历'],prefix='学历'))
#合并字段
train_test_data=train_test_data.join(tra_tes[['分析','业务','运营','产品','沟通','Sql','Excel','Python','R','Bi','薪资上限(万/月)','薪资下限(万/月)']])
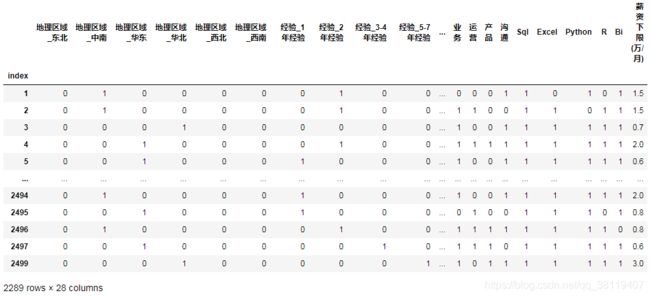
经处理后的原始数据表
4、特征选择
#将数据根据薪资上下限分为两个量表
train_test_low=train_test_data.drop(columns={'薪资下限(万/月)'})
train_test_up=train_test_data.drop(columns={'薪资上限(万/月)'})
import copy
train_test_low1=copy.deepcopy(train_test_low)
#将每个字段设置不同数值,便于方差过滤后返回查找对应字段变量
m=1
for i in train_test_low1.columns:
h=train_test_low1[i]
for j in train_test_low1.index:
if h[j]==1:
h[j]=m
else:
h[j]=m-1
m+=1
4.1 过滤法
#方差过滤
from sklearn.feature_selection import VarianceThreshold
#方差过滤后,得到list
x_fsvar=VarianceThreshold(0.8*(1-0.8)).fit_transform(train_test_low1.iloc[:,:-1])
#找出剩余变量每列最大值与相符合的字段
pre_var_id=train_test_low1.max(axis = 0)
max_var_id=pd.DataFrame(x_fsvar).max()
max_var=[]
for i in pre_var_id.index:
if pre_var_id[i] in max_var_id.values.tolist():
max_var.append(i)
max_var
#F检验
from sklearn.feature_selection import f_regression
F,pvalue_f=f_regression(train_test_low[max_var],train_test_low.iloc[:,-1])
b=np.where(pvalue_f>0.05)
a=[] #p不显著的位置
for i in range(len(b)):
for j in range(len(b[i])):
a.append(b[i][j])
var2=[]
for k in a:
j=max_var_id[k]
for i in pre_var_id.index:
if pre_var_id[i]==j:
var2.append(i)
var2
#互信息法
from sklearn.feature_selection import mutual_info_regression
mutual_info_regression(train_test_low[max_var],train_test_low.iloc[:,-1], discrete_features='auto', n_neighbors=3, copy=True, random_state=None)
经过方差过滤后剩余13个变量,F检验剔除2个变量,互信息法结果显示值均大于0.
4.2 随机森林筛选变量
from sklearn.ensemble import RandomForestRegressor
#分别加入方差过滤前、后以及互信息法后的变量进行筛选,代码一样,只放一段
rf2 = RandomForestRegressor()
rf2.fit(train_test_low[max_var], train_test_low.iloc[:,-1])
print ("Features sorted by their score:")
p3=pd.DataFrame(sorted(zip(map(lambda x: round(x, 4), rf2.feature_importances_), train_test_low[max_var].columns), reverse=True))
print (sorted(zip(map(lambda x: round(x, 4), rf2.feature_importances_), train_test_low[max_var].columns), reverse=True))
4.3 递归消除法筛选变量
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
#分别加入方差过滤前、后以及互信息法后的变量进行筛选,代码一样,只放一段
lr2 = LinearRegression()
rfe2 = RFE(lr2, n_features_to_select=1)
rfe2.fit(train_test_low[max_var],train_test_low.iloc[:,-1])
print ("Features sorted by their rank:")
print (sorted(zip(map(lambda x: round(x, 4), rfe2.ranking_), train_test_low[max_var].columns)))
pp3=pd.DataFrame(sorted(zip(map(lambda x: round(x, 4), rfe2.ranking_), train_test_low[max_var].columns)))
结合上述多种方法筛选结果,确定10个自变量与1个因变量,如下:
var2=['地理区域_华东','经验_1年经验','经验_2年经验','经验_3-4年经验','学历_专科及以下','学历_本科','业务','产品','R','Bi','薪资下限(万/月)']
5、模型比较及参数调参
5.1 划分数据集
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X_train,X_test,y_train,y_test=train_test_split(low_data.iloc[:,:-1],low_data.iloc[:,-1]*10000,test_size=0.3,random_state=5)
#标准化
ss_X = StandardScaler()
ss_y = StandardScaler()
X_train=ss_X.fit_transform(X_train)
X_test=ss_X.fit_transform(X_test)
y_train=ss_y.fit_transform(y_train.values.reshape(-1,1)) #将y变量压缩
y_test=ss_y.fit_transform(y_test.values.reshape(-1,1))
5.2 多模型训练
模型训练过程中采用了两种核函数支持向量回归、决策回归树及Adaboost、KNN回归、线性回归以及Lasso回归。
# 1-支持向量回归
from sklearn.svm import SVR
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
# 线性核函数配置支持向量机
linear_svr = SVR(kernel="linear")
linear_svr.fit(X_train, y_train)
# 预测 保存预测结果
linear_svr_y_predict = linear_svr.predict(X_test)
# 多项式核函数配置支持向量机
poly_svr = SVR(kernel="poly")
poly_svr.fit(X_train, y_train)
# 预测 保存预测结果
poly_svr_y_predict = linear_svr.predict(X_test)
#计算得分及MSE、MAE
#线性核
line_score0=linear_svr.score(X_train, y_train)
line_score=linear_svr.score(X_test, y_test)
line_r2_score=r2_score(y_test, linear_svr_y_predict)
line_mse= mean_squared_error(y_test,linear_svr_y_predict)
line_mae=mean_absolute_error(y_test,linear_svr_y_predict)
print(line_score,line_r2_score,line_mse,line_mae)
# 多项式核
poly_score0=poly_svr.score(X_train, y_train)
poly_score=poly_svr.score(X_test, y_test)
poly_r2_score=r2_score(y_test, poly_svr_y_predict)
poly_mse= mean_squared_error(y_test,poly_svr_y_predict)
poly_mae=mean_absolute_error(y_test,poly_svr_y_predict)
print(poly_score0,poly_score,poly_r2_score,poly_mse,poly_mae)
# 2-决策树回归与Adabost
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import AdaBoostRegressor
import matplotlib.pyplot as plt
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error,explained_variance_score
rng = np.random.RandomState(1)
regr_1 = DecisionTreeRegressor(max_depth=5)
regr_2 = AdaBoostRegressor(DecisionTreeRegressor(max_depth=5),n_estimators=300, random_state=rng)
regr_1.fit(X_train, y_train)
regr_2.fit(X_train, y_train)
# 预测
y_1 = regr_1.predict(X_train)
y_2 = regr_2.predict(X_train)
#查看决策树回归的训练结果
y_pred_dt=regr_1.predict(X_test)
mse1 = mean_squared_error(y_test,y_pred_dt)
evs1 = explained_variance_score(y_test,y_pred_dt)
regr1_score0=regr_1.score(X_train, y_train)
regr1_score=regr_1.score(X_test, y_test) #默认得分score
regr1_r2_score=r2_score(y_test, y_pred_dt) #r方
print(regr1_score,mse1)
#查看对AdaBoost进行改进之后的算法
y_pred_ab=regr_2.predict(X_test)
mse2=mean_squared_error(y_test,y_pred_ab)
evs2=explained_variance_score(y_test,y_pred_ab)
regr2_score0=regr_2.score(X_train, y_train)
regr2_score=regr_2.score(X_test, y_test) #默认得分score
regr2_r2_score=r2_score(y_test, y_pred_ab) #r方
print(regr2_score,mse2)
# 3-KNN回归
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import median_absolute_error
#拟合预测
knn = KNeighborsRegressor()
knn.fit(X_train,y_train)
y_pre_knn = knn.predict(X_test)
#计算得分
knn_score0=knn.score(X_train,y_train)
knn_score=knn.score(X_test,y_test)
knn_r2_score = r2_score(y_test,y_pre_knn)
knn_MAE=mean_absolute_error(y_test, y_pre_knn)
knn_MSE=mean_squared_error(y_test, y_pre_knn)
print(knn_score,knn_r2_score,knn_MSE,knn_MAE)
# 4线性、Lasso回归
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
#线性
lr=LinearRegression(normalize=True)
lr.fit(X_train,y_train)
lr_score0=lr.score(X_train,y_train)#训练集R方
lr_score=lr.score(X_test,y_test)#测试集
#Lasso
la=Lasso(max_iter=10000000,alpha=50)
la.fit(X_train,y_train)
la_score0=la.score(X_train,y_train)
la_score=la.score(X_test,y_test)
5.3 模型比较
对比上述模型中对训练集以及测试集的学习得分
#防止出现中英文乱码
plt.rcParams['font.sans-serif'] =['FangSong']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10,6))
x1=[line_score,poly_score,regr1_score,regr2_score,knn_score,lr_score,la_score] #测试集得分
x2=[line_score0,poly_score0,regr1_score0,regr2_score0,knn_score0,lr_score0,la_score0] #训练集得分
names=['SVR_线性核','SVR_多项式','决策树','AdaBoost','Knn','线性回归','Lasso']
plt.plot(names,x1,label='测试集得分',marker='o',markersize=12,linestyle='--',color='pink')
plt.plot(names,x2,label='训练集得分',marker='*',markersize=12,color='grey')
plt.legend(fontsize=11)
plt.xlabel("模型名称",fontsize=18)
plt.ylabel("score",fontsize=20)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.show()
5.4 模型确定
结合上述模型训练得分,效果都不是很好,综合选择决策树作为预测模型。
#对决策树模型进行参数搜索
from sklearn.model_selection import GridSearchCV
gini_thresholds = np.linspace(0,0.5,20)
parameters = {'splitter':('best','random'),"max_depth":[*range(1,10)],'min_samples_leaf':[*range(1,50,5)],'min_impurity_decrease':[*np.linspace(0,0.5,20)]}
grid = GridSearchCV(DecisionTreeRegressor(),param_grid=parameters,cv=8)
grid.fit(X_train,y_train)
print('最优分类器:',grid.best_params_,'最优分数:', grid.best_score_)
#模型确定
jc=DecisionTreeRegressor(max_depth= 8,min_impurity_decrease= 0.0,min_samples_leaf= 31,splitter ='best')
jc.fit(X_train,y_train)
pre=jc.predict(X_test)
print(jc.score(X_train,y_train))
print(jc.score(X_test,y_test))
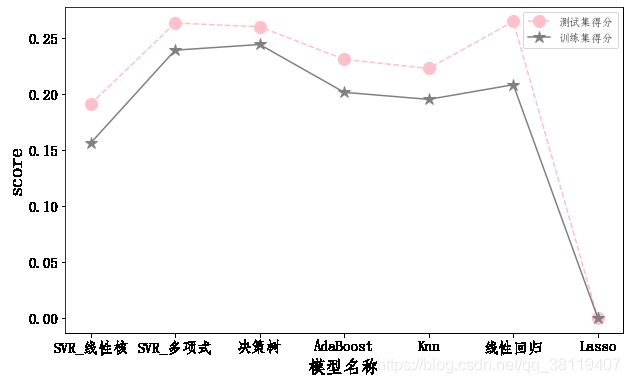
从上面模型折线图可以看出,决策回归树模型相对于其他模型在训练集与测试集的得分差异较小,拟合效果相差不大,综合起来得分高于其他,因而确定决策树模型为最终预测模型。
6、预测
6.1 预测工资下限
将待测集变量参照训练数据处理,进行预测。
pre_data['薪资下限(万/月)预测']=jc.predict(ss_X.fit_transform(pre_data1[var2[:-1]]))
pre_data['薪资下限(万/月)预测']=ss_y.inverse_transform(pre_data.iloc[:,-1])/10000
pre_data['薪资下限(万/月)预测']=round(pre_data.iloc[:,-1],2)
6.2 预测工资上限
对于工资上限预测模型,作上述相同特征选择及多模型训练,不再赘述,最终也建立决策树模型,进行预测。
pre_data['薪资上限(万/月)预测']=jc1.predict(ss1_X.fit_transform(pre_data1[var2[:-1]]))
pre_data['薪资上限(万/月)预测']=ss1_y.inverse_transform(pre_data1.iloc[:,-1])/10000
pre_data['薪资上限(万/月)预测']=round(pre_data.iloc[:,-1],2)
小结
第一部分主要包含根据爬取到的数据,通过数据清理并整合为以学历、经验、城市、技能等为自变量,薪资水平为因变量的量表。
(1)数据清理部分,缺失值处理时,删除了少量全部字段都空缺的样本;其余整体确实部分都在“薪资部分”当中,并利用缺失部分当作此次项目的待测集;针对字段信息错位的作相应调整,并把自身详情数据缺失的部分单独作一类处理;
(2)变量处理中,对分类变量中单一分类较少的样本合并该变量;并对地区特征进行分类;最后整理好的多分类变量作哑变量处理;
(3)特征选择中,采用了过滤法中的方差过滤剔除掉经哑变量处理后得到的二分类特征中某一分类占比80%上的二分类特征,并以F检验作补充;采用互信息法找出任意关系,剔除返回值为0的特征;同时以随机森林筛选、递归特征消除法作对照,最终确定10个特征变量;
(4)模型选择中,选择了多种回归模型对数据集进行训练及拟合,最后选择决策树为最终预测模型;在本次模型训练中,多种模型效果均不太好,可能原因有数据本身特征不充分,比如未考虑到企业的规模,企业的性质等等。
结合第一部分数据的处理、预测得到结果,进一步作相应的具体因素分析,将在第二部分进行补充。