MySQL 数据库集群-PXC 方案(三)
什么是基准测试
基准测试是针对系统的一种压力测试,但基准测试不关心业务逻辑,更加简单、直接、易于测试,不要求数据的真实性和逻辑关系。
基准测试的指标

Sysbench 简介

Sysbench 是一个模块化的、跨平台、多线程基准测试工具,主要用于测试系统及数据库的性能。它主要包括以下几种方式的测试:
- CPU 性能(系统级别)
- 磁盘 IO 性能(系统级别)
- 调度程序性能(系统级别)
- 内存分配及传输速度(系统级别)
- POSIX 线程性能(系统级别)
- 数据库性能(OLTP 基准测试)
目前 Sysbench 主要支持 MySQL,pgsql,oracle 这 3 种数据库。
安装 Sysbench
curl -s https://packagecloud.io/install/repositories/akopytov/sysbench/script.rpm.sh | sudo bash
yum -y install sysbench安装完成后查看是否安装成功
sysbench --version
Sysbench 基本语法
sysbench script [option] [command]option 连接信息参数
| 参数名称 | 功能意义 |
|---|---|
| --mysql-host | IP 地址 |
| --mysql-port | 端口号 |
| --mysql-user | 用户名 |
| --mysql-password | 密码 |
option 执行参数
| 参数名称 | 功能意义 |
|---|---|
| --oltp-test-mode | 执行模式(simple、nontrx、complex) |
| --oltp-tables-count | 测试表的数量 |
| --oltp-table-size | 测试表的记录数 |
| --threads | 并发连接数 |
| --time | 测试执行时间(秒) |
| --report-interval | 生成报告单的间隔时间(秒) |
执行模式:
- simple: 测试查询 不测试写入
- nontrx:测试无事务的增删改查
- complex:测试有事务的增删改查
command 命令
| 命令名称 | 功能意义 |
|---|---|
| prepare | 准备测试数据 |
| run | 执行测试 |
| cleanup | 清除测试数据 |
准备测试数据
在准备之前我们先修改一下haproxy.cfg文件,之前我们配置的是 MyCat 集群的负载均衡,现在改为某一个分片的 PXC 集群即可。
vim /etc/haproxy/haproxy.cfgserver mysql_1 192.168.3.137:3306 check port 3306 weight 1 maxconn 2000
server mysql_1 192.168.3.138:3306 check port 3306 weight 1 maxconn 2000
server mysql_1 192.168.3.139:3306 check port 3306 weight 1 maxconn 2000保存之后执行命令重启
service haproxy restart可以看到下图没有问题:
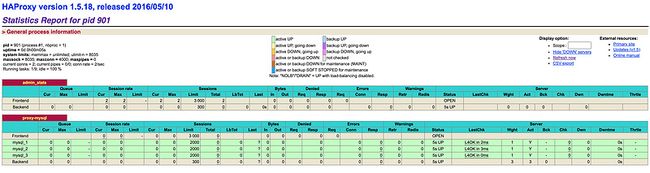
之后我们新建一个测试逻辑库sbtest
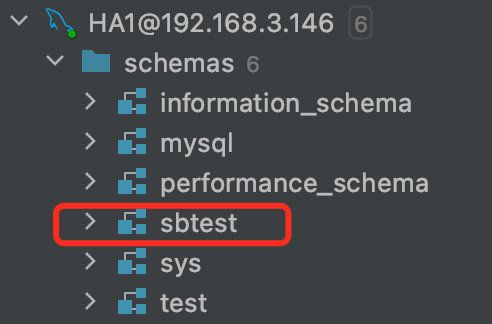
接着我们创建测试数据
sysbench /usr/share/sysbench/tests/include/oltp_legacy/oltp.lua --mysql-host=192.168.3.146 --mysql-port=3306 --mysql-user=admin --mysql-password=Abc_123456 --oltp-tables-count=10 --oltp-table-size=100000 prepare- /usr/share/sysbench/tests/include/oltp_legacy/oltp.lua : 生成测试数据的脚本 sysbench 自带
- --mysql-host :数据库连接地址
- --mysql-port : 端口
- --mysql-user:用户名
- --mysql-password:密码
- --oltp-tables-count:测试 10 个数据表
- --oltp-table-size:每张表 10 万条数据
- prepare:准备测试数据
创建完成后我们执行测试
sysbench /usr/share/sysbench/tests/include/oltp_legacy/oltp.lua --mysql-host=192.168.3.146 --mysql-port=3306 --mysql-user=admin --mysql-password=Abc_123456 --oltp-test-mode=complex --threads=10 --time=300 --report-interval=10 run >> /home/mysysbench.log- --oltp-test-mode=complex:测试有事务的增删改查
- --threads:并发连接数
- --time:测试时长,测试的时长更长一些,比如 24 小时,测试的结果会更加准确
- --report-interval=10 :每隔 10 秒回报一次数据
- run >> /home/mysysbench.log:输入测试日志报告文件位置
等待 5 分钟执行完成后,我们查看 /home/mysysbench.log。
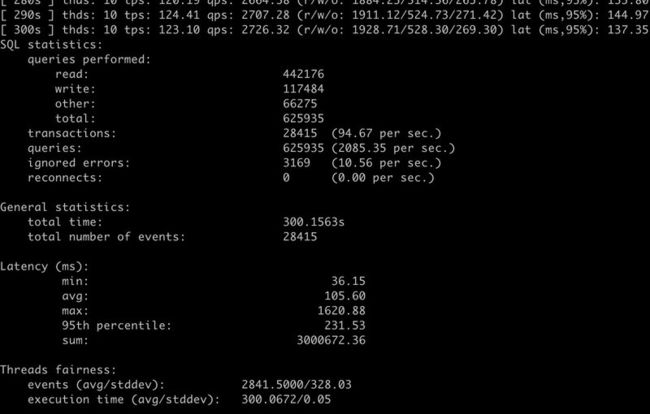
- queries performed : 执行测试的次数
- read : 读操作执行了 442176 次
- write : 写操作执行了 117484 次
- other:其他操作执行了 66275 次
- total:总共执行了 625935 次
- transcations(TPS):执行的事务次数 28415 次,PXC 集群每秒可以执行的事务操作 94.67 次
- queries(QPS):处理的请求书 625935,PXC 集群每秒钟可以执行 2085.35 次增删改查操作
- ignored errors: 忽略的错误数量 3169,每秒钟平均错误数量 10.56 次,可能是节点之间冲突造成
- reconnects:数据库重新连接的次数,0 代表没有发生数据库连接断开的情况
清理测试数据:
sysbench /usr/share/sysbench/tests/include/oltp_legacy/oltp.lua --mysql-host=192.168.3.146 --mysql-port=3306 --mysql-user=admin --mysql-password=Abc_123456 --oltp-tables-count=10 cleanup小结
基准测试是对单张表进行的读写测试,因为不涉及表连接外键约束,索引等操作,所以单纯体现的是数据库硬件性能。如果想知道数据库集群在真实业务中的实际性能,需要使用压力测试。
tpcc-mysql 简介
tpcc-mysql 是 percona 基于 tpcc 规范衍生出来的产品,专门用于 mysql 压力测试 。
tpcc 是一种测试标准,明确规定了数据模型和检测是指标,而且检测的标准对数据库集群来说很苛刻,tpcc-mysql 的测试库能覆盖大多数的业务场景,测试的结果也能反映出真实业务中数据库的实际性能。
tpcc 测试问题
tpcc 的检测标准是针对单节点的 mysql 数据库,对 sql 的执行时间有严格的规定,我们要测试的 PXC 集群是以牺牲插入速度为代价换取的同步强一致性,假如 tpcc 要执行一个 insert 语句不能超过 100ms,但是 PXC 集群只是写入速度慢,插入执行了 300ms。这个检测点就没有通过,所以拿 tpcc 测试 PXC 集群不太适合,检测的标准太苛刻了一些,但是因为数据库集群在真实业务下实际的读写性能,每秒钟能执行多少次读操作,多少次写操作。至于由于插入速度慢测试报告中测试没有通过,可以不予理会。
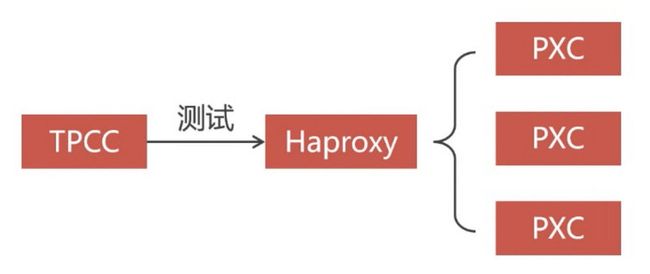
测试方案
我们还是以 haproxy+三个 mysql 节点的 PXC 集群来进行测试。
准备工作(一)
关闭我们的 PXC 集群。对应关闭操作在第二篇文章中写的很清楚。
然后打开 vim /etc/my.cnf
把 PXC_strict_mode 的值改成 DISABLED
原来默认的参数值是不允许我们执行不符合规范的操作,比如创建出没有主键的数据表,tpcc 数据库脚本里边有一个表没有主键,所以为了 tpcc 测试能进行下去我们要修改 PXC_strict_mode 的值。
三个 PXC 节点都需要修改
修改完 my.cnf 文件之后再重新启动 PXC 集群。
准备工作(二)
Haproxy 对应的文件进行修改,由于我们之前已经修改过了这里就不用再修改了。
server mysql_1 192.168.3.137:3306 check port 3306 weight 1 maxconn 2000
server mysql_1 192.168.3.138:3306 check port 3306 weight 1 maxconn 2000
server mysql_1 192.168.3.139:3306 check port 3306 weight 1 maxconn 2000准备工作(三)
安装环境包。
yum install -y gcc
yum install -y mysql-devel安装 tpcc-mysql
下载安装包。
https://codeload.github.com/Percona-Lab/tpcc-mysql/zip/master解压然后上传到服务器。
进入 src 目录,再使用 make 命令编译。
cd src
make
创建测试库
到 PXC 集群的节点上创建数据库tpcc,我们在 Haproxy 的节点上创建,那么 PXC 集群的 mysql 库也会自动同步。
然后我们进入 tpcc-mysql-master 目录下执行:
ls *.sql
- create_table.sql 是创建表的 sql 文件
- add_fkey_idx.sql 是索引等约束文件
我们将这两个文件复制出来,然后在我们新建的 tpcc 库中运行。

准备测试数据
./tpcc_load -h 192.168.3.146 -d tpcc -u admin -p Abc_123456 -w 1- -h 192.168.3.146 数据库 ip 地址
- -d tpcc 数据库名字
- -u admin 用户名
- -p Abc_123456 密码
- -w 1 仓库数量,由于数量庞大,插入时间较长,所以这里使用 1 个仓库数量,如果使用多个仓库,耗时很长。

执行测试
./tpcc_start -h 192.168.3.146 -d tpcc -u admin -p Abc_123456 -w 1 -c 5 -r 300 -l 600 - >tpcc-outpit.log- -h 192.168.3.146 数据库 ip 地址
- -d tpcc 数据库名字
- -u admin 用户名
- -p Abc_123456 密码
- -w 1 仓库数量
- -c 5 并发线程数
- -r 300 数据库预热时间 单位秒
- -l 600 测试时间单位秒
- tpcc-outpit.log 测试结果输出到文件
为了真实性可以将-r 和-l 时间设置长一些,比如预热 1 个小时,测试 24 小时。
查看日志日志出现了大量的死锁异常,执行压力测试的时候,事务执行的时间太久,没有及时提交事务,于是出现了锁冲突。让 PXC 集群的锁冲突降到最低,将并发的线程数改为 1。

./tpcc_start -h 192.168.3.146 -d tpcc -u admin -p Abc_123456 -w 1 -c 1 -r 300 -l 600 - >tpcc-outpit.log
查看测试结果

- sc: 成功执行的次数
- lt: 超时执行的次数
- rt: 重试执行的次数
- fl: 失败执行的次数
第一行是新订单执行的测试结果,tpcc 在规定时间内成功执行了 0 条记录,由于 tpcc 测试指标是非常苛刻的,虽然我们执行了操作,但是执行时间没有达到 tpcc 的要求,所以不能算为执行成功,只能算做是超时执行。PXC 集群是以牺牲速度为代价换取数据同步的强一致性。虽热增删改成都能执行,但是达不到 tpcc 的指标。rt(重试执行的次数)和 fl(失败执行的次数)是 0 次。
第二行是支付业务的测试结果。成功执行了 0 次,超时执行了 3587 次,重试执行 0 次,失败 0 次。
第三行是订单状态的测试结果。成功执行了 195 次,超时执行了 163 次,重试执行 0 次,失败 0 次。
第四行是发货业务的测试结果。成功执行了 0 次,超时执行了 358 次,重试执行 0 次,失败 0 次
第五行是库存业务的测试结果。成功执行了 0 次,超时执行了 359 次,重试执行 0 次,失败 0 次。
尽管达不到 tpcc 的测试指标,但是没有失败执行的。以上是各种业务下的增删改查操作。
下面这个是事务的操作状态,测试报告也是通过的。

响应时间的一个测试,NG 代表没有通过,OK 代表的是测试通过。用 tpcc 测试 PXC 集群有些不合理,tpcc 测试是按照单节点 mysql 读写速度和响应时间来制定的指标。所以 PXC 集群很难能达到 tpcc 的指标,所以这里很多响应时间的指标都是 NG 没通过的。

最后的 TpmC 是,每分钟 PXC 集群执行的事务数量。

binlog 简介

MySQL 的二进制日志 binlog 可以说是 MySQL 最重要的日志,它记录了所有的 DDL 和 DML 语句(除了数据查询语句 select、show 等),以事件形式记录,还包含语句所执行的消耗的时间,MySQL 的二进制日志是事务安全型的。binlog 的主要目的是复制和恢复。
binlog 日志的两个最重要的使用场景:
- MySQL 主从复制
- 数据恢复
binlog 文件种类

- 二进制日志索引文件(文件名后缀为.index)用于记录所有有效的的二进制文件
- 二进制日志文件(文件名后缀为.00000\*)记录数据库所有的 DDL 和 DML 语句事件
binlog 是一个二进制文件集合,每个 binlog 文件以一个 4 字节的魔数开头,接着是一组 Events:
- 魔数:0xfe62696e 对应的是 0xfebin;
- Event:每个 Event 包含 header 和 data 两个部分;header 提供了 Event 的创建时间,哪个服务器等信息,data 部分提供的是针对该 Event 的具体信息,如具体数据的修改;
- 第一个 Event 用于描述 binlog 文件的格式版本,这个格式就是 event 写入 binlog 文件的格式;
- 其余的 Event 按照第一个 Event 的格式版本写入;
- 最后一个 Event 用于说明下一个 binlog 文件;
- binlog 的索引文件是一个文本文件,其中内容为当前的 binlog 文件列表
当遇到以下 3 种情况时,MySQL 会重新生成一个新的日志文件,文件序号递增:
- MySQL 服务器停止或重启时
- 使用
flush logs命令 - 当 binlog 文件大小超过
max_binlog_size变量的值时
max_binlog_size 的最小值是 4096 字节,最大值和默认值是 1GB (1073741824 字节)。事务被写入到 binlog 的一个块中,所以它不会在几个二进制日志之间被拆分。因此,如果你有很大的事务,为了保证事务的完整性,不可能做切换日志的动作,只能将该事务的日志都记录到当前日志文件中,直到事务结束,你可能会看到 binlog 文件大于 max_binlog_size 的情况。
Binlog 的日志格式
记录在二进制日志中的事件的格式取决于二进制记录格式。支持三种格式类型:
STATEMENT:基于 SQL 语句的复制(statement-based replication, SBR)ROW:基于行的复制(row-based replication, RBR)MIXED:混合模式复制(mixed-based replication, MBR)
在 MySQL 5.7.7 之前,默认的格式是 STATEMENT,在 MySQL 5.7.7 及更高版本中,默认值是 ROW。日志格式通过 binlog-format 指定,如 binlog-format=STATEMENT、binlog-format=ROW、binlog-format=MIXED。
ROW 模式
注:我是在本地环境下测试。
输入命令打开我们的 mysql 配置文件
vim /etc/my.cnf增加如下配置:
binlog_format = row
log_bin=mysql_bin重启服务后可以看到如下:

接着我在本地表中增加了两条测试数据:

打开 mysql_bin.index可以看到内容很简单就是记录了有哪些文件:
./mysql_bin.000001
./mysql_bin.000002在 mysql 中使用下面命令去查看都有哪些日志文件。
show master logs;
之后我们挑选一个文件来进行查看:
show binlog events in 'mysql_bin.000001';这里记录的不是 sql 语句,我们可以看到开启了一个 session 然后开启事务然后写入操作最后提交事务。

每条记录的变化都会写入到日志中。
5.1.5 版本的 MySQL 才开始支持 row level 的复制,它不记录 sql 语句上下文相关信息,仅保存哪条记录被修改。
PXC 节点默认的日志模式就是 row 模式
优点:
- 清晰的记录了每条记录的细节
- 数据同步安全可靠
- 同步时出现行锁的更少
缺点:
- 日志体积太大,浪费存储空间
- 数据同步频繁速度慢
注:将二进制日志格式设置为 ROW 时,有些更改仍然使用基于语句的格式,包括所有 DDL 语句,例如 CREATE TABLE, ALTER TABLE,或 DROP TABLE。
STATEMENT 模式
每一条会修改数据的 sql 都会记录在 binlog 中
我把 /etc/my.cnf修改成 statement 模式,然后删除mysql_bin.index和mysql_bin_00000相关文件最后重启 mysql。
binlog_format = statement之后我们新建一条数据后查看我们的日志:
show master logs;
show binlog events in 'mysql_bin.000001';可以看到在事务中是记录的 sql 语句。

优点:
- 日志文件体积小
- 节省 I/O 和存储资源
- 集群节点同步速度快
缺点:
- 某些函数和主键自增长会出现同步数据不一致
- 另外 mysql 的复制,像一些特定函数的功能,slave 与 master 要保持一致会有很多相关问题。
MIXED 模式
从 5.1.8 版本开始,MySQL 提供了 Mixed 格式,实际上就是 Statement 与 Row 的结合。
在 Mixed 模式下,一般的语句修改使用 statment 格式保存 binlog,如一些函数,statement 无法完成主从复制的操作,则采用 row 格式保存 binlog,MySQL 会根据执行的每一条具体的 sql 语句来区分对待记录的日志形式,也就是在 Statement 和 Row 之间选择一种。
还是之前的步骤,我们修改 binlog_format = mixed
再增加两条数据,普通插入一条和使用函数增加一条。
insert into student(id,name) values (5,UUID());
之后我们查看日志:
show master logs;
show binlog events in 'mysql_bin.000001';可以看到在事务中是记录有 row 模式和 statement 模式。

MySQL 的 5 种特殊设计
1.MySQL+分布式 Proxy 扩展
MySQL+分布式 Proxy 扩展分好多种情况:
PXC 集群
PXC 集群牺牲读写速度的代价保证数据的强一致性,在保证数据强一致性的业务中才推荐使用 PXC 集群,比如与钱相关的业务必须使用 PXC 集群,数据不一致导致的后果很难承担。由于 PXC 集群是牺牲写入速度保证数据的强一致性,增强 PXC 集群性能可以使用数据分片,比如使用 MyCat 分片,通过 MyCat 分发之后每个分片写入的压力就减少了很多,性能就能提升不少。另外在业务设计上也要避免瞬时写入的压力。

Replication 集群
说完了数据强一致性的 PXC 集群,我们再说一下弱一致性的 Replication 集群。用 Replication 搭建集群之后也可以使用数据分片,也可以使用 MyCat 来进行管理,也可以使用 Haproxy 和 Keepalived。

PXC 集群+Replication 集群
面对复杂的业务,系统会同时面对强一致性和弱一致性。我们可以将两种集群整合在一起,我们根据水平拆分的原则,把需要强一致性的数据表建立在 PXC 集群,不需要强一致性的数据表建立在 Replication 集群里。关键性的数据写在 PXC,非关键性的数据写在 RP 里。这就兼顾了强一致性,弱一致性,读写速度的矛盾。
在 CRUD 语句里边最复杂的是查询语句,单表查询还好,表连接要是查询不同集群中的数据表这就会很复杂。应对这种查询方式有两种,第一种是由于 Replication 集群写入速度比 PXC 集群速度更快,我们可以使用同步中间件将 PXC 集群中的数据同步到 Replication 集群。然后在 Replication 集群里边查询表连接操作。这样就能查到你想要的数据结果。另一种方案是ETL 中间件,先把数据从不同的集群中抽取出来,然后再做表连接去查询,比如知名的 ETL 中间件Kettle。

PXC 集群+Replication 集群+缓存集群
说完了 PXC 集群和 Replication 集群的混合方案,如果系统对读写速度要求更高,我们还可以引入 mongodb,redis 等 NoSQL 缓存数据库。
这里就要关注一下数据库集群的事务,有些人会想到 XA 事务,但是 PXC 集群不支持 XA 事务,所以这个方案并不可行。阿里巴巴有一个 GTS 的中间件,他可以把各种数据库纳入到一个事务之下,但是 GTS 只能运行在阿里云上。还有一种方案是利用消息中间件,去模拟分布式的事务,把 PXC 集群、Replication 集群、缓存集群纳入到事务之内。

2.数据归档,冷热数据分离
随着是数据的增加,无论是单节点的 mysql 还是 mysql 的集群,都要做冷热数据分离,冷数据可以存放到归档表,可以使用 MongoDB,也可以使用 TokuDB 来保存归档数据。mongodb 大家都熟悉,这里主要讲解一下 TokuDB。TokuDB 是 mysql 的一种存储引擎,可以高速的写入数据,写入速度是 innodb 引擎的 9 倍,压缩比是 innodb 的 14 倍,跟 mongdb 相比丝毫不逊色,TokuDB 的写入性能是 MongoDB 的 4 倍,而且还是带事务的写入。

3.MySQL+缓存(Redis)高并发架构
比如以发红包的案例,用户 A 发红包,把红包数据存入缓存,用户 B,C,D 抢完红包之后,再把红包数据写入到数据库中。

4.MySQL+小文件系统
我们可以将一些用户的图片上传到服务器,在数据库中只存储图片路径。而并非在数据库中存储 blog 类型的数据。

5.MySQL+Inforbright 统计分析架构
这一种 mysql 设计方案跟数据分析有关,对于数据库而言,通常是第二天之后才会有结果汇总统计分析的需求, 这类 OLAP 执行频率较低,但是每次统计的信息太多,消耗的资源很大,如果在 OLTP 系统上运行会造成两大业务的相互影响,所以我们应该把 OLAP 给独立出去,通过数据流转把 OLTP 的数据传输个 OLAP 系统,有很多成熟的 OLAP 系统比如 Inforbright 系统,在几百万到几十亿数据的规模下查询速度是 mysql 的 5-60 倍。相对而言 Inforbright 是轻量级的,而分布式的 mpp 数据仓库可以支撑更大海量数据的统计分析,所以有数据分析的系统不防试一试这种架构。

向集群导入大量数据
如果我们使用的 sql 文件我们可以使用 source test.sql 命令进行导入数据,在数据量不多的时候我们可以使用,如果数据量过大时间就会很长。
如果要导入 100 万次的数据。mysql 要进行多少次词法分析和优化。所以说是非常的耗时。
如果数据量过大,我们可以使用 LOAD DATA 来进行导入,30 万的数据大概只需要 5 秒就可以导入。
因为 LOAD DATA 是从文本文档里导入纯数据,没有词法分析和优化,只需要解析每条记录的格式,数据就直接写入到表里了。
比如有几十个 G 的数据,由于 LOAD DATA 是单线程写入,我们可以将文件切分成多个文件,然后交给多线程来执行,速度大大提高。
导入测试数据
说完了使用什么来导入数据,但是我们数据从哪里来呢,我们可以使用 Java 来生成数据。
我们生成 1000 万条数据:
public class Test {
public static void main(String[] args) throws IOException {
FileWriter writer = new FileWriter("/Users/jack/Downloads/data.txt");
BufferedWriter bufferedWriter = new BufferedWriter(writer);
for (int i = 0; i < 10000000; i++) {
bufferedWriter.write(i + ",测试数据\n");
}
bufferedWriter.close();
writer.close();
}
}配置数据文件
之后将文件上传到 linux。上传完成之后我们查看一下:

然后我们使用下面命令进行切分成十份,按 100 万一份切割。
split -l 1000000 -d data.txt- -l :按行切分
- -d:文件名名带排序
执行成功之后我们就可以看到下图这样:

接着我们在每个 PXC 分片只开启一个节点,这样就不会同步,引发数据限流。
修改 PXC 节点文件,然后重启 PXC 服务
vim /etc/my.cnfinnodb_flush_log_at_trx_commit = 0
innodb_flush_method = O_DIRECT
innodb_buffer_pool_size = 200M接着我们在两个 PXC 节点中创建表:
CREATE TABLE t_test(
id INT UNSIGNED PRIMARY KEY,
name VARCHAR(200) NOT NULL
);
修改 MyCat 配置文件
我们先关闭 MyCat。
vim schema.xml增加我们新建的表:
由于我们现在只开启了两个分片中的一个节点,所以删除掉别的节点的配置信息,balance = 0 关闭读写分离。
select user()
select user()
保存启动 MyCat
./mycat start写入 MySQL
之后我们编写 Java 代码
/**
* @author 又坏又迷人
* 公众号: Java菜鸟程序员
* @date 2020/11/26
* @Description: LoadData
*/
public class LoadData {
private static int num = 0;
private static int end = 0;
private static ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(1,
5, 60, TimeUnit.SECONDS, new LinkedBlockingQueue(200));
public static void main(String[] args) throws SQLException {
DriverManager.registerDriver(new Driver());
File folder = new File("/home/data");
File[] files = folder.listFiles();
end = files.length;
for (File file : files) {
Task task = new Task();
task.file = file;
poolExecutor.execute(task);
}
}
public static synchronized void updateNum() {
num++;
if (num == end) {
poolExecutor.shutdown();
System.out.println("执行结束");
}
}
}/**
* @author 又坏又迷人
* 公众号: Java菜鸟程序员
* @date 2020/11/26
* @Description: Task
*/
public class Task implements Runnable {
File file;
@Override
public void run() {
String url = "jdbc:mysql://192.168.3.146:8066/test";
String username = "admin";
String password = "Abc_123456";
try {
Connection connection = DriverManager.getConnection(url, username, password);
String sql = " load data local infile '/home/data/" + file.getName() + "' ignore into table t_test \n" +
" character set 'utf8' \n" +
" fields terminated by ',' optionally enclosed by '\\\"' \n" +
" lines terminated by '\\n' (id,name); ";
PreparedStatement pst = connection.prepareStatement(sql);
pst.execute();
connection.close();
LoadData.updateNum();
} catch (SQLException e) {
e.printStackTrace();
}
}
}完成后打包拷贝到服务器上,执行命令运行 Java 代码
java -jar 名字.jar
成功后,我们执行 SQL 查看一下:
select count(*) from t_test;
写入完成后,我们停止两个 PXC 节点,将刚才添加语句的删除掉。
systemctl stop [email protected]vim /etc/my.cnf删除下面配置:
innodb_flush_log_at_trx_commit = 0
innodb_flush_method = O_DIRECT
innodb_buffer_pool_size = 200M然后我们把其他的 PXC 节点启动,会自动进行全量同步。
service mysql start接着把我们刚才在 MyCat 配置文件中删除的其他 PXC 节点信息加回去,进入 conf 目录下:
vim schema.xml
select user()
select user()
启动 MyCat,进入 bin 目录下
./mycat start启动之后我们查询一下别的 PXC 分片,看看数据是否同步过去:
select count(*) from t_test可以看到 500 万条数据,没问题。

MySQL 数据库设计
核心原则
- 不在数据库做运算
- CPU 计算必须在业务层执行
- 控制字段数量
- 平衡范式与冗余
- 拒绝大 SQL 语句、拒绝大事务、拒绝大批量
- 用恰当的数据类型
- 字符转化为数字(节约空间,提高查询性能)
- 避免使用 NULL 字段(NULL 很难查询优化,索引需要额外的空间,而且复合索引无效)
- 避免使用 text 类型
索引设计原则
- 合理使用索引
- 长字符串必须建前缀索引
- 不在索引列做运算
- 不用外键(使用逻辑外键)
SQL 设计原则
- SQL 语句尽可能简单
- 尽可能使用简单的事务
- 避免使用触发器和存储过程
- OR 改写为 IN
- OR 改写为 UNION