INTERSPEECH 2020 | 腾讯AI Lab解读语音识别与合成方向及入选论文
感谢阅读腾讯AI Lab微信号第107篇文章。本文将分组介绍语音领域顶级会议 INTERSPEECH 2020 中腾讯 AI Lab 的重点研究方向和入选论文。
语音技术顶级会议 INTERSPEECH 今年将于 10 月 25 - 29 日在线上举行。根据主办方发布的数据,INTERSPEECH 2020共接收到有效论文投稿 2140 篇,其中 1022 篇被接收。而由于今年的会议不再受物理场地的限制,原本展示方式不同的 oral 和 poster 论文也不再区分,每篇接收论文都能进行视频展示并拥有充分的 QA 时间。
今年,腾讯 AI Lab 共有14 篇论文入选 INTERSPEECH 2020,总体而言分为语音识别和语音合成两大方向,其中既有在语音前沿技术方向的进一步探索,也包含一些理论研究和分析,同时还有在科技向善与文化遗产保护等方面的应用成果。
下面将分语音识别和语音合成两大版块解读腾讯 AI Lab 的入选论文。
语音识别
语音识别的主要研究课题包括语音转文本、语音分离、语音表征、语音信号处理等,其最终目标是让机器能够理解人的声音,进而结合自然语言处理和常识理解等技术实现人与机器的自然互动。
高质量语音的识别问题已经基本得到了解决。同时,语音识别技术在日常生产生活中的实际应用已经开始,你也已经能在智能家居、智能车载、智能客服系统、同声传译等地方看见它的身影。
不过,自然条件下的语音往往存在噪声和语音重叠的「鸡尾酒会问题」以及口语多变的问题,因此如何有效且高效地解决这些问题是目前语音识别领域的主要研究方向。
语音识别也是腾讯 AI Lab 重点投入的研究和工程落地方向之一。今年,腾讯 AI Lab 共有 10 篇相关论文被 INTERSPEECH 2020 接收,涵盖语音唤醒、识别、增强、分离、转换、预训练和端到端识别等主题。
1.通过更强的干扰来学习更好的表征
Learning Better Speech Representations by Worsening Interference
本文由腾讯 AI Lab 独立完成,提出了一个学习鲁棒的语音表征的新思路,即不使用清晰明确的语音数据,而是使用带强干扰的声源数据来进行学习。
在嘈杂的强干扰的声学环境中能学到好的语音表征吗?为了验证这个看似矛盾的观点,本研究提出了一种新颖的架构,将传统互相独立的语音分离和说话人识别的任务联合起来进行学习。在这个框架中,通用预训练与微调结合的学习方式来试图模仿人类鸡尾酒会效应中的自下而上和自上而下的过程。同时,本方法调研了如何避免模型「偷懒」学习相对容易的任务,从而「迫使」模型能在非常糟糕的干扰条件下学习到足够具有区分和泛化性能的表征。实验结果显示,这些学习到的表征,对下游的说话人识别任务具备更鲁棒的表现;同时,对下游的语音分离任务,SI-SNRi性能在不同的测试条件下均一致地超过了当前最先进的DPRNN系统。

本方案可在复杂的具有高度可变性的真实声学环境中显著地改善人类听觉的可懂度以及机器自动语音识别系统的准确率,从而提升用户体验,能应用到包括音视频会议系统、智能语音交互、智能语音助手、在线语音识别系统、车载语音交互系统等多种项目和产品中。
2.端到端多方向语音唤醒
End-to-End Multi-Look Keyword Spotting
本文由腾讯 AI Lab 独立完成,提出了一种新的端到端多方向唤醒方案,能在未知声源方向的情况下执行语音增强,从而提升唤醒性能。
语音唤醒在远场复杂声学环境下的性能会受到很大影响。本文提出了一种基于神经网络模型的多方向语音增强方法,可以同时增强多个方向的声源。然后,再对多方向语音增强模型与语音唤醒模型进行联合优化,研究者构建了一个端到端的多方向语音唤醒模型。在远场带噪声数据集上验证实验表明:相比于传统唤醒模型和之前提出的基于波束形成的多方向语音唤醒方法,新提出的方法具有显著更优的唤醒性能。

新提出的多方向增强和端到端多方向 KWS 模型模块示意图
3.基于神经网络空间-时间波束形成的目标人语音分离
Neural Spatio-Temporal Beamformer for Target Speech Separation
本文由腾讯 AI Lab 独立完成,提出了一种可同时利用时间和空间信息的目标人语音分离方案。该方案既可克服纯神经网络方法的失真问题,也能克服传统MVDR的残存噪声大的问题。
纯神经网络的语音增强或分离都会有谱失真的问题,而基于普通MVDR波束形成的方法都会有残留噪声大的问题。针对目标人语音分离任务,本文提出了一种新的基于神经网络的空间-时间波束形成方法(简称Multi-tap MVDR)。文中还提出在联合训练的框架下,利用复值掩码(mask)去更新 MVDR 的统计量。Multi-tap MVDR既利用了空间相关性,又利用了时间帧之间的相关性,进而可以同时克服谱失真和残留噪声大的问题。在评估实验中,新方法取得了最佳 PESQ 并实现了语音识别率的大幅提升。
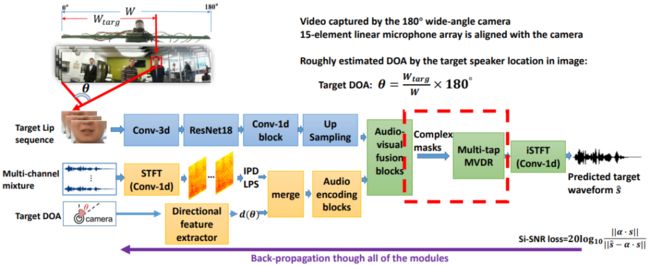
Multi-tap MVDR 与复制掩码的联合训练
4.利用跨域视觉生成特征辅助障碍语音识别
Exploiting Cross-Domain Visual Feature Generation for Disordered Speech Recognition
本文由腾讯 AI Lab 与香港中文大学合作完成,提出了一种用于识别障碍发音的当前最佳方法。这也是腾讯 AI Lab 科技向善研究的一部分。
音视频语音识别技术已经在大量任务上得到成功应用。在障碍语音识别中,语音质量往往有严重下降,并且与正常语音有很大差别,很难收集到大量高质量的语音视觉数据来开发这类语音的音视频语音识别系统。本文提出了一种跨域视觉特征的生成方法:基于深度神经网络构建的语音-视觉信息逆向生成系统。利用大量域外的音频-视觉数据进行训练,来为那些只有有限或者没有视觉数据的障碍发音的说话人生成视觉特征。

在障碍语音公开数据集 UASpeech 上的实验表明,本文提出的基于跨域视觉特征生成方法的音视频语音识别系统总是优于单语音识别基线系统和音视频语音识别基线系统。相较于之前公开的在 8 个UASpeech障碍发音说话人上的最好系统,本文方法在词识别错误率上降低了 3.6 个绝对百分点(14 个相对百分点)。
5.音视频多通道混叠语音识别
Audio-visual Multi-channel Recognition of Overlapped Speech
本文由香港中文大学与腾讯 AI Lab 合作完成,提出了一种分离和识别混叠语音的新方案。
混叠声识别是目前语音识别中一个有挑战性的任务。针对这种场景,基于麦克风阵列的语音分离技术被应用在现在的语音识别系统中。基于视觉模态的信息不会受到环境噪声干扰,本文提出了一种同时利用音视频和多通道信息来实现语音分离和识别的系统,搭建了一系列音视频的多通道语音分离前端,包括时频掩码、滤波叠加和基于掩码的MVDR波束形成。该框架还采用了联合优化分离前端和识别后端的方法,从而可减小语音分离和语音识别中的损失函数不匹配问题。实验结果表明,相较于只用语音模态的模型,本文提出的模型在合成数据和实录测试集上分别将错误率降低了6.81% 和 22.22%。
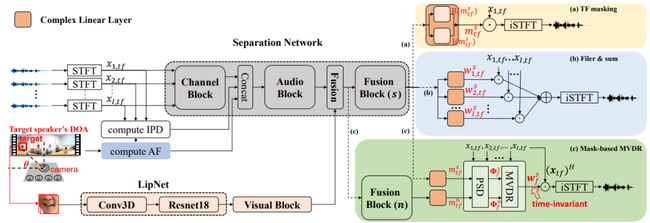
新提出的音视频多通道语音分离网络
6.基于自注意力机制的声学模型无监督预训练方法
Speech-XLNet: Unsupervised Acoustic Model Pretraining For Self-Attention Networks
本文由清华大学与腾讯 AI Lab 合作完成,提出了一种实现声学模型无监督预训练的新方法,为语音识别性能提升提供了新的思路和参考方向。
通过 BERT 和 XLNet 等无监督学习范式,双向表征学习能为自注意力网络(SAN)带来显著助益。受自然语言处理领域的大规模无标注文本预训练的启发,本文提出了一种通过预测被打乱的语音帧来实现声学模型无监督预训练的方法。这是一种类似 XLNet 的预训练方案:Speech-XLNet,可使用自注意力网络来学习语音表征。

Speech-XLNet 系统概况,其中红色箭头表示梯度的反向传播路径
首先,研究者发现通过混洗打乱语音的帧顺序,可将 Speech-XLNet 用作强大的正则化器,这能鼓励自注意力网络通过其注意力权重来关注全局结构,进而执行推理。其次,Speech-XLNet 还允许模型探索双向上下文信息,同时维持自回归的训练方式。研究结果表明,该方法可以提高混合语音识别模型和端到端语音识别模型的鲁棒性和识别准确率。
7.一种基于语谱图的端到端语音识别数据增强方法
SpecSwap: A Simple Data Augmentation Method for End-to-End Speech Recognition
本文同样由清华大学与腾讯 AI Lab 合作完成,研究了对语音数据层面进行正则化的方法对语音识别效果的提升,进一步改进和补充了谷歌的 SpecAugment 方法,对语音识别数据层面正则化类型的方法进行了有意义的探索。
虽然近来端到端模型已在自动语音识别任务上取得了当前最佳表现,但在这些大规模的深度模型内部,过拟合仍旧是一个会严重影响模型性能的重要问题。为此,本文提出通过交换语谱图的特征块来为端到端语音识别系统的输入引入一定程度的「扰动」,可以部分缓解端到端模型的过拟合问题。实验结果证明了该方法的有效性。

log-mel 频谱图,自上而下分别为基础输入(无增强)、时间交换增强、频率交换增强以及同时应用所有增强策略
8.在非平行语音转换中进行源风格转换
Transferring Source Style in Non-Parallel Voice Conversion
本文由香港中文大学与腾讯 AI Lab 合作完成,提出了一种在语音转换中保留源语句中的说话风格的解决方案。
语音转换(VC)技术旨在保留语言信息的同时修改话语的说话者身份。大多数VC方法都忽略了说话风格的建模(例如情绪和重音),其中可能包含说话者故意添加的因素。而这些因素应在转换过程中予以保留。本文提出了一种基于序列到序列的非并行VC方法,能通过明确建模将说话风格从源语音转换为转换语音。客观评估和主观听力测试表明,所提出的VC方法在语音自然度和转换后语音的说话人相似性方面具有优势。实验还表明了该方法的源代码风格可移植性。

转换过程方案示例图

语音生成器的模型架构
9.用于端到端语音识别的RNN Transducer最小贝叶斯风险训练
Minimum Bayes Risk Training of RNN-Transducer for End-to-End Speech Recognition
本文由腾讯 AI Lab 独立完成,本文首先为端到端语音识别 RNN-T 模型提出了最小贝叶斯风险训练方法,在提供了详细数学推导的同时也取得了显著的性能提升。
本文为端到端语音识别模型RNN-Transducer(RNN-T)提出最小贝叶斯风险训练(MBR)。具体而言,本文使用以 RNN-T 准则训练的模型作为初始化,通过最小化标注序列与在线生成 N-best 假设之间的期望 Levenshtein 距离来进行MBR训练。同时,本文还提出了一种可将外部神经网络语言模型(NNLM)引入 RNN-T beam-search 解码中的方法,并探索了使用外部 NNLM 进行 MBR 训练的方法。

本文采用的基于卷积和 Transformer 的 RNN-T 架构
实验结果表明,MBR 训练的模型显著优于 RNN-T 训练的模型,在使用外部 NNLM 进行训练后可以实现进一步的性能提升。结果还表明最佳的 MBR 受训系统在经过约 21,000 小时的语音训练后,与一个基于卷积和 Transformer 的RNN-T基线系统相比,在阅读和口语普通话上的字符错误率(CER)分别降低了1.2%和0.5%。
10.探究对抗样本检测方法在说话人认证问题中的鲁棒性
Investigating Robustness of Adversarial Samples Detection for Automatic Speaker Verification
本文由香港中文大学与腾讯 AI Lab 合作完成,提出了一种基于 VGG 的二分类对抗样本检测器,并实验证实了它在检测对抗样本方面的有效性,该模型可以用来保护声纹识别系统(ASV)不被恶意攻击。此外,本文还探究了该检测器在不同攻击配置下的鲁棒性,为构建更加强大检测器的提供了一个重要方向。
近期,基于声纹识别 (ASV) 系统的对抗样本攻击因为其严重的破坏性受到了广泛的关注。然而,对于该攻击的防御方法的研究目前极其有限。已有的方法主要集中在将生成的对抗样本加入训练集(数据增强)重新训练声纹识别系统。此外,在域外攻击 (out-of-domain/unseen attack) 的情况下,防御模型的鲁棒性并没有得到充分的研究。本工作从另外一个角度出发,提出了基于检测网络训练的方法来防御对抗样本的攻击,而不是用对抗样本做数据增强重新训练声纹识别模型。本工作提出了基于VGG的变体二分类检测器,并证明了其在检测对抗样本方面的有效性。
在实际应用场景下,用于攻击的对抗样本的生成配置可能存在与训练数据不匹配的情况。为了进一步探究该检测器对域外对抗样本检测的有效性,本文分析了不同的攻击配置。研究者观察到,检测器对于域外声纹识别系统是相对鲁棒的(最差情况下检测器的等错误率(EER)下降6.27%),而对于域外扰动方法的鲁棒性是很差的(最差情况下检测器的等错误率(EER)下降50.37%)。由此看来,如何提高对域外扰动方法的鲁棒性将是构建更加强大防御模型的一个重要方向。

语音合成
为了实现人与机器的自然互动,机器不仅要学会听懂人话,还要学会自己说话。因此,语音合成是人机交互未来的重要组成部分。
自然流畅的合成语音具有广阔的应用空间,比如智能家居、车载系统、语言教育等,同时还能极大丰富内容生产的方式,比如配备到虚拟人中的进行直播娱乐、打造虚拟歌手、合成有声读物等。
语音合成是腾讯 AI Lab 的重要研究方向之一,同时也是腾讯 AI Lab 虚拟人研究的一大重要基础。今年腾讯 AI Lab 有 4 篇相关论文入选 INTERSPEECH 2020,其中包括腾讯 AI Lab 在语音合成方面的重要研究成果 DurIAN 及其变体在歌声与京剧合成方面的应用,另外还有腾讯 CSIG 与腾讯 AI Lab 合作开发的高效语音合成系统 FeatherWave。
1.DurIAN: 基于时序注意力神经网络的语音合成系统
DurIAN : Duration Informed Attention Network For Speech Synthesis
项目:https://tencent-ailab.github.io/durian/
本文由腾讯 AI Lab 独立完成,提出了一种稳定且有效的语音合成系统,能生成高自然度和高质量的合成语音。DurIAN 是腾讯虚拟人项目的语音部分中的重要组成部分,通过后面几项研究也可以看到,DurIAN 是腾讯 AI Lab 语音合成研究方向的一大核心成果,基于此技术开发的儿歌合成应用也已在今年儿童节通过虚拟人 AI 艾灵进行了展示。
和时下流行的端到端的语音合成系统相比,本文通过引入时序注意力机制以及音素时长模型,解决了传统端到端语音合成模型中说话漏字、重复等一系列问题。本文还提出了一种基于多频带并行的WaveRNN系统,将运算复杂度从 9.8 降到了 3.6 GFLOPS。实验证明,不论从稳定性还是自然度以及效率上,该系统都达到了非常好的效果。

DurIAN 的模型架构

多频带 WaveRNN 的架构
2.DurIAN-SC: 基于时序注意力神经网络的歌声转换系统
DurIAN-SC: Duration Informed Attention Network based Singing Voice Conversion System
项目:
https://lukewys.github.io/files/Peking-Opera-Synthesis-2020.html本文由腾讯 AI Lab 主导,与北京工业大学和中国音乐学院合作完成,提出了一种新的歌声转换系统。
歌声转换指的是将一个人的歌声用另一个目标歌者的音色「唱」出来。由于和语音合成/转换的数据库相比,歌声的数据库不容易采集,而且数量稀少。而且如何利用非常少量的句子对训练集以外的目标说话人进行歌声转换是一个难题。本文在时序注意力神经网络的框架下做了一定的优化,将说话的语音数据和歌声数据放到统一的框架下训练。并且实验证明了在仅依靠目标说话人语音数据的情况下,也能够实现基于少数据量的集外说话人歌声转换。另外,和之前的基于训练得到的说话人表征向量相比,本文引入了一个独立的基于说话人识别的说话人向量提取模块。由于独立的基于说话人识别的说话人向量提取模块可以利用额外的说话人识别的语音数据进行训练,因此提取出来的说话人向量会更鲁棒。实验证明,新提出的系统能够很好地实现在没有目标说话人歌声数据情况下的歌声转换。
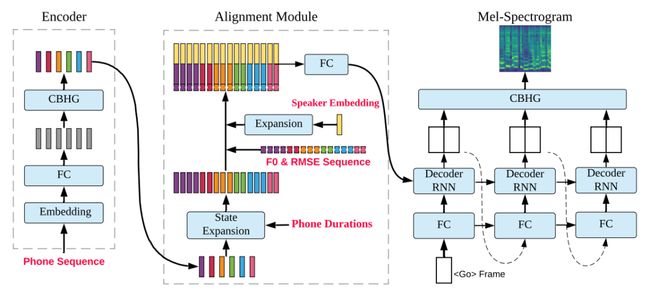
DurIAN-SC 的模型架构
3.基于时序注意力神经网络的京剧合成
Peking Opera Synthesis via Duration Informed Attention Network
项目:
https://lukewys.github.io/files/Peking-Opera-Synthesis-2020.html
本文由腾讯AI Lab 和北京邮电大学合作完成,提出了一种基于时序注意力神经网络的京剧合成系统。
京剧从200年前开始成为中国的主流戏剧形式。京剧表演融合了艺术家极大的个人特色,而且京剧演唱形式多种多样,包含生旦净丑等角。不同的角色演唱方式又不尽相同。本文从保护文化遗产的角度,从深度神经网络和机器学习的角度,提出了利用拉格朗日乘子的方法对歌声合成系统中生成时长和曲谱时长不一致的问题进行优化。并且利用基于时序注意力神经网络的模型结构对京剧语料进行建模。实验表明,新提出的算法能够有效的还原京剧的特色。京剧唱段生成的更惟妙惟肖。

新提出的系统的整体结构示意图
4.FeatherWave:一种高效的多频带并行式高质量语音合成器
FeatherWave: An efficient high-fidelity neural vocoder with multi-band linear prediction
项目:https://wavecoder.github.io/FeatherWave/
本文由腾讯云与智慧产业事业群(CSIG)智平团队主导,与腾讯 AI Lab 合作完成。
本文提出了一种基于多频带并行生成的 LPCNet 的网络结构 FeatherWave,这是基于 WaveRNN 声码器的又一种变体,并结合了多频带信号处理和线性预测编码。这一策略能让模型一站式地并行生成多个语音样本,从而可以极大提升语音合成的效率。实验表明,通过并行预测 4 个频带的特征,能把计算量降低到 1.6 GFLOPS。并且新提出的系统能达到 9倍实时,而且在音质上 FeatherWave 也优于 LPCNet 。

FeatherWave 声码器模块图示

* 欢迎转载,请注明来自腾讯AI Lab微信(tencent_ailab)