使用单层反向传播神经网络(感知机模型)预测男女
问题
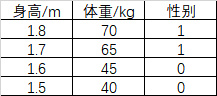
现在有某个地区,以下人口信息数据集作为训练集合测试集:
训练集:
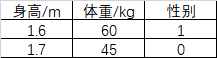
测试集:
我们需要建立一个单层神经网络感知机模型,通过反向传播的方法来对这个数据集建立预测模型,并且来预测一个1.8m,体重60kg的人是男还是女。这个模型包括正向传播计算梯度、反向传播更新梯度、测试集验证等部分组成,我们使用sigmoid函数作为输出层的激活函数。
分析
我们可以建立逻辑回归的感知机模型,根据以下公式更新公式,经过若干次迭代之后得到w,b,然后使用w,b作为权重和输入数据作用后激活进行预测。
![]()
代码
import numpy as np
from matplotlib import pyplot as plt
def sigmoid(x):
return 1/(1+np.exp(-x))
def dsigmoid(x):
return sigmoid(x)*(1-sigmoid(x))
def initialize_with_zeros(dim):
w = np.zeros((dim,1)) #注意这里w是dim行1列的列向量,如果只写dim的话则是行向量
b = 0.0
return w,b
def loss(w,b,X,Y):
m = X.shape[1]
A = sigmoid(np.dot(w.T,X)+b)
return (1/m) * np.sum(Y*np.log(A)+(1-Y)*np.log(1-A))
def propagate(w,b,X,Y):
m = X.shape[1]
A = sigmoid(np.dot(w.T,X)+b)
cost = loss(w,b,X,Y)
#注意np.dot,对于两个矩阵作为参数表示矩阵的乘法
dw = np.dot(X,(A-Y).T)/m
db = np.sum(A-Y)/m
#squeeze压缩维度,把单一的维度取消掉
cost = np.squeeze(cost)
grads = {
'dw' : dw,
'db' : db
}
return grads, cost
def back_propagation(w,b,X,Y,num_iterations,learning_rate,print_cost = False):
costs = []
for i in range(num_iterations):
grad, cost = propagate(w,b,X,Y)
dw = grad['dw']
db = grad['db']
w = w - learning_rate*dw
b = b - learning_rate*db
if i%10 == 0:
costs.append(cost)
if print_cost and i%10 == 0:
print("cost after iteration %i: %f" %(i,cost))
params = {
'w':w,
'b':b
}
grads = {
'dw':dw,
'db':db
}
return params,grads,costs
def predict(w,b,X):
m = X.shape[1]
Y_predict = np.zeros((1,m))
w = w.reshape(X.shape[0],1)
A = sigmoid(np.dot(w.T,X)+b)
for i in range(A.shape[1]):
if A[:,i] > 0.5:
Y_predict[:,i] = 1
else:
Y_predict[:,i] = 0
return Y_predict
def model(X_train,Y_train,X_text,Y_test,num_iterations,learning_rate,print_cost):
w,b = initialize_with_zeros(X_train.shape[0])
params,grads,costs = back_propagation(w,b,X_train,Y_train,num_iterations,learning_rate,print_cost)
w,b = params['w'],params['b']
Y_prediction_train = predict(w,b,X_train)
Y_prediction_test = predict(w,b,X_test)
if print_cost:
print(f"Train accuracy is {100- 100*np.mean(np.abs(Y_prediction_train-Y_train))}%")
print(f"Test accuracy is {100- 100*np.mean(np.abs(Y_prediction_test-Y_test))}%")
d = {
"costs":costs,
"Y_prediction_test":Y_prediction_test,
"Y_prediction_train-Y_train":Y_prediction_train,
"w":w,
"b":b,
"learning_rate":learning_rate,
"num_iterations":num_iterations
}
return d
##建立一个数据集,X中含有身高和体重两个维度,4个样本,y标签表示这个样本是否为男生,1表示是,0表示不是(即女生)
##这里我们的数据集中,和表格中的数据刚好是转置的关系,即一列表示一个样本,一行表示一个特征
X_train = np.array([
[1.8,70],
[1.7,65],
[1.6,45],
[1.5,40]
]).T
Y_train = np.array([1,1,0,0])
X_test = np.array([
[1.6,60],
[1.7,45],
]).T
Y_test = np.array([1,0])
d = model(X_train,Y_train,X_test,Y_test,num_iterations=10000,learning_rate=0.01,print_cost=True)
w,b = d['w'],d['b']
X = np.array([[1.8,60]]).T
Y = predict(w,b,X)
print(w,b)
print(Y)
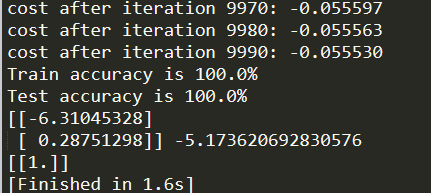
运行结果:
经过10000次权值迭代之后,我们得到了以下的结果,这说明,我们的拟合函数为 y = s i g m o i d ( − 0.631 ∗ x 1 + 0.288 ∗ x 2 − 5.17 ) y=sigmoid(-0.631*x1+0.288*x2-5.17) y=sigmoid(−0.631∗x1+0.288∗x2−5.17)如果y>0,判决为1(男性),反之,就判为女性,我们看到我们使用真实的数据集,准确率都为100%,也用这个模型预测了身高1.8m,体重60千克的是一位男性(这也太瘦了),还是比较符合认知的,当然,随着数据量的增大,这个模型就约能符合真实的场景。