python爬取无讼案例网,并对爬取结果进行多元回归分析
目录
- 无讼网站数据爬取
-
- 无讼网站爬取的主要步骤如下:
- 遇到的问题
- 代码如下
- 数据处理及多元回归分析
-
- 数据清洗
- 模型及第三方库的选择
- 爬取结果示例
- 爬取结果数字化
- 回归分析结果
- 代码如下
(求客官动动您的小指头,点个赞!!!)感谢感谢!!!
无讼网站数据爬取
(求客官动动您的小指头,点个赞!!!)
无讼网站爬取的主要步骤如下:
1.找到翻页后的url参数变化规律
2.从翻页后的页面中提取每个案例对应的参数值
3.将提取出来的参数值利用for循环构造1000个案例对应的url
4.使用requests库访问每个案例对应的url
5.利用json和re解析库提取所需要的信息
6.最后将数据保存在csv文件
遇到的问题
不能全部使用json来解析响应体,虽然网站返回的是json格式的数据,但是由于每个案例返回的json格式有一些不同,会很容易报错,若是用try-except异常处理跳过出错的案例,会使最后爬取的案例数量只有200多个,远远不能满足数量要求。所以本程序使用json配合re来提取所需信息,将格式比较统一的标题、案件类型、案例号、检察院名字、被告人姓名使用json库来获取。之后关于被告人的具体信息使用re正则表达式来获取,由于正则提取过程会导致一些数据提取不符合要求, 所以会对之后的多元线性回归的结果产生影响,这也是正则的缺点之一,提取的内容并不一定都能符合要求。
代码如下
# coding:utf-8
import re
import requests
import xlwt
import time
import numpy as np
import json
def get_pages(j):
"""
不断获取翻页后的源代码(每页源代码包含20案例url需要的参数值)
:param j: 翻页参数
:return: 每页的源代码
"""
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
"Cookie": "UM_distinctid=172ad1c13215a5-096f2b20b21719-5d462912-144000-172ad1c1322982;home_sessionId=true; subSiteCode=bj;cookie_allowed=true;reborn-userToken=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJhdWQiOiIxODk5NjA1MzI2NCJ9.UoDVvWzLxlyz_Qz6sJ6_FrW3EJWHRbvMCMJuuzcxglA;CNZZDATA1278721950=371480104-1592040232-https%253A%252F%252Fwww.baidu.com%252F%7C1592043421",
}
url = "https://www.itslaw.com/api/judgements?_timer=1592904610377&sortType=1&startIndex=" + str(
j) + "&countPerPage=20&conditions=searchWord%2B%E7%94%B5%E4%BF%A1%E7%BD%91%E7%BB%9C%E8%AF%88%E9%AA%97%2B1%2B%E7%94%B5%E4%BF%A1%E7%BD%91%E7%BB%9C%E8%AF%88%E9%AA%97&conditions=trialRound%2B1%2B8%2B%E4%B8%80%E5%AE%A1"
response = requests.get(url, headers=head).text
# print(response)
return response
def get_source():
'''
提取参数,拼接url,保存url到csv文件
:return: url列表
'''
# 构造每个案例的url
i = 0
url_list = []
for j in range(20, 5000, 20):
response = get_pages(j)
time.sleep(1)
parameters = re.findall('"temporarySearchReport":false}.*?{"id":"(.*?)","title":"(.*?)","caseType', response,
re.S) # 正则提取参数
for parameter in parameters:
i += 1
url = "https://www.itslaw.com/api/judgements/detail?_timer=1592057292299&judgementId=%s" % parameter[0]
print("第%s个url" % i, url)
url_list.append(url)
save_data("url.csv", url_list)
print("总共获取了%s个url" % len(url_list))
return url_list
def save_data(file_name, datas, rowx=0, colx=0):
"""
保存数据,只能保存一维列表或是二维列表。
:param file_name: 保存为的文件名,需要带后缀
:param datas: 以列表形式提供要保存的数据
:param rowx: 行号
:param colx: 列号
:return: None
"""
if np.ndim(datas) == 1:
# 纵向保存一位列表
writebook = xlwt.Workbook(file_name)
sheet = writebook.add_sheet("result", cell_overwrite_ok=True)
for data in datas:
# print(data)
sheet.col(0).width = 35000 # 设置列宽
sheet.write(rowx, colx, data)
rowx += 1
writebook.save(file_name)
print("数据保存完成!")
elif np.ndim(datas) == 2:
# 保存二维列表
writebook = xlwt.Workbook(file_name)
sheet = writebook.add_sheet("信息", cell_overwrite_ok=True)
rowx = 0
for a in datas:
rowx += 1
colx = 0
x = 0
y = [25000, 3500, 8000, 5000, 5000, 5500, 4000, 5000, 5000, 3000, 3000, 3000, 3000, 3000] # 列数变多,需要加数
for infor in a:
# print(data)
sheet.col(colx).width = y[x] # 设置不同的列宽
sheet.write(rowx, colx, infor)
colx += 1
x += 1
writebook.save(file_name)
print("数据保存完成!")
else:
print("保存的数据既不是一维列表,也不是二维列表,不能保存!")
def get_oneurl_response():
url_list = get_source()
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
"Cookie": "UM_distinctid=172ad1c13215a5-096f2b20b21719-5d462912-144000-172ad1c1322982;home_sessionId=true; subSiteCode=bj;cookie_allowed=true;reborn-userToken=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJhdWQiOiIxODk5NjA1MzI2NCJ9.UoDVvWzLxlyz_Qz6sJ6_FrW3EJWHRbvMCMJuuzcxglA;CNZZDATA1278721950=371480104-1592040232-https%253A%252F%252Fwww.baidu.com%252F%7C1592043421",
}
all = [] # 二维列表,子列表存储每个案例提取的信息
all.append(["标题", "案件类型", "案件号", "检察院名字", "被告人姓名",
"出生日期", "出生城市", "文化", "工作","判处年限","罚金"])
all.append(["", "", "", "", "", "", "", "", "", "", ""])
for url in url_list:
try:
print(url)
r = requests.get(url, headers=head).text
res = json.loads(r)
dict_data = res['data']
wenben = dict_data['fullJudgement']
# 标题
title = wenben['title']
# 案件类型
caseType = wenben['caseType']
# 案例号
caseNumber = wenben['caseNumber']
# 检察院名字
proponents = wenben['proponents']
proponents = proponents[0]
proponents_name = proponents['label']
# 被告人姓名
opponents = wenben['opponents']
opponents = opponents[0]
opponents_name = opponents['name']
#提取判决年限
time_re = re.findall('徒刑((\S{1,2}年\S{1,2}个月).*?)', r, re.S)
try:
if not time_re:
time = '无'
else:
time = time_re[0][0]
except:
time = "无"
#提取罚金
try:
money = re.findall('罚金人民币(.*?)元', r, re.S)[0]
except:
money = "无"
# print('---->',time,money)
# 提取出生日期
paragraphs = wenben['paragraphs'][0]
# print('提取判决结果---->',type(paragraphs))
subParagraphs = paragraphs['subParagraphs'][1]
text = subParagraphs['text'][0]
try:
date_of_birth = re.findall("\d{4}年\d{1,2}月\d{1,2}日", text, re.S)[0]
except:
date_of_birth = "无"
# 提取出生地
try:
if "自治区" not in text:
if "省" in text and "市" in text:
city_of_birth = re.findall("(\S{1,2}省\S{2,3}市)|(\S{1,2}省\S{1,3}县)", text, re.S)[0]
if "市" in str(city_of_birth):
city_of_birth = city_of_birth[0]
elif "县" in str(city_of_birth):
city_of_birth = city_of_birth[1]
elif "市" in text and "县" in text:
city_of_birth = re.findall("\S{1,2}市\S{1,2}县", text, re.S)[0]
elif "台湾" in text:
city_of_birth = "台湾"
else:
if "内蒙古自治区" in text:
city_of_birth = re.findall("(\S{3}自治区\S{2,3}市)|(\S{3}自治区\S{2,3}县)", text, re.S)
if "市" in str(city_of_birth):
city_of_birth = city_of_birth[0][0]
elif "县" in str(city_of_birth):
city_of_birth = city_of_birth[0][1]
elif "广西壮族自治区" in text:
city_of_birth = re.findall("(\S{4}自治区\S{2,3}市)|(\S{4}自治区\S{2,3}县)", text, re.S)
if "市" in str(city_of_birth):
city_of_birth = city_of_birth[0][0]
elif "县" in str(city_of_birth):
city_of_birth = city_of_birth[0][1]
elif "新疆维吾尔自治区" in text:
city_of_birth = re.findall("(\S{5}自治区\S{2,3}市)|(\S{5}自治区\S{2,3}县)", text, re.S)
if "市" in str(city_of_birth):
city_of_birth = city_of_birth[0][0]
elif "县" in str(city_of_birth):
city_of_birth = city_of_birth[0][1]
else:
city_of_birth = "无"
except:
city_of_birth = "无"
# 提取文化
try:
if '小学' in text:
culture = "小学"
elif '初中' in text:
culture = "初中"
elif '专科 ' or '中专' in text:
culture = "专职"
elif '高中' in text:
culture = "高中"
elif '大学' in text:
culture = "大学"
except:
culture = '小学'
#提取职业
try:
work = re.findall('文化,(.{1,2})', text, re.S)[0]
except:
work = "无业"
all_infor = [title, caseType, caseNumber, proponents_name, opponents_name,date_of_birth,
city_of_birth, culture, work,time,money]
print(all_infor)
except:
continue
all.append(all_infor)
save_data("案例爬取信息.csv", all)
get_oneurl_response()
数据处理及多元回归分析
数据清洗
我们拿到的数据可能包含了大量的缺失值,可能包含大量的噪音。数据清洗是检测和去除数据集中的噪声数据和无关数据,处理遗漏数据,去除空白数据域和知识背景下的白噪声。
空值数据的处理方法主要有:1.删除包含空值的记录,这种方式主要是针对包含空值的数据占总体比例较低,删除这些数据对于数据整体影响不大。2.自动补全,这种方法通过统计学原理,根据数据集中记录的取值分布情况来对一个空值进行自动填充,可以用平均值,最大值,最小值等基于统计学的客观知识来填充字段。
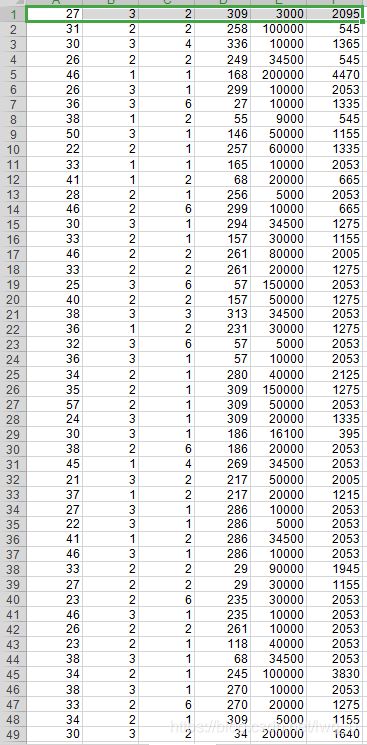
本程序对于残缺值主要使用的是自动补全法,对于有异常的数据进行替换。其次爬取的结果都是中文形式保存,所以需要对数据进行处理,将其进行数字化。虽然每个案例获取11个特征信息,但是在进行多元回归分析的时候,将判刑年限作为标签值,将与判刑年限有相关性的变量作为特征值,比如:年龄、户籍、工作、文化程度、罚款金额这5个变量。接下来利用pandas库将数据结构化,便于使用sklearn库进行多元回归分析。
模型及第三方库的选择
线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。其表达形式为y = w’x+e,e为误差服从均值为0的正态分布。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
此案例主要分析判刑年数和年龄、户籍、工作、文化程度、罚款金额这5个变量之间的关系,所以选择多元回归分析模型。用Python第三方库sklearn实现多元回归分析,利用其中的train_test_split方法进行训练和预测。
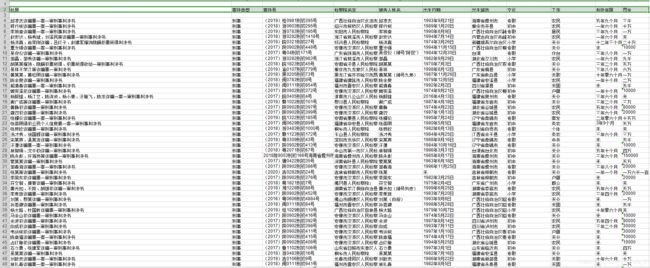
爬取结果示例
爬取结果数字化
回归分析结果
回归分析结果截图如下,由图中的截距和回归系数可以得出回归方程。由结果可知,与判处年限相关性最大的是罚款金额,其次是文化程度。就本案例来言,回归分析结果还不算理想,主要是由于数据获取和处理过程具有的较高难度造成的,爬取的数据噪点较多,有时还会出现空值,较好的数据对于回归分析结果是关键性的,所以要提升模型的精准度,还需要在数据获取和处理上加大功夫。

代码如下
# conding:utf-8
from pandas import DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import xlrd
import datetime
import re
def read_excel(file_name, colx, start_rowx=1, end_rowx=None):
'''
读取Excel单元格数据
:return: 列表返回列数据向量
'''
wb = xlrd.open_workbook(filename=file_name) # 打开文件
print("----------所有工作表的名称-------------")
sheet_name = wb.sheet_names()
print(sheet_name) # 获取所有工作表的名字
sheet = [wb.sheet_by_index(i) for i in range(len(sheet_name))] # 获取多个sheet,存在列表
cols = sheet[0].col_values(colx - 1, start_rowx - 1, end_rowx) # 获取列内容
print("数据向量---->", cols)
print(len(cols))
return cols
def calculation_age():
'''
计算年龄
:return: 年龄列表
'''
age_list = read_excel("案例爬取信息.csv", 6, 4)
now_time = datetime.date.today().year
oneage_list = []
for age in age_list:
if "无" not in age:
one_age = now_time - int(age[0:4])
if one_age < 18:
one_age = 30
oneage_list.append(one_age)
else:
one_age = 30
oneage_list.append(one_age)
print(oneage_list)
return oneage_list
# calculation_age()
def cal_culture():
'''
文化数字化
:return: 文化数字列表
'''
culture_list = read_excel("案例爬取信息.csv", 8, 4)
culturenum_list = []
for culture in culture_list:
if '小学' in culture:
culture_num = 1
elif '初中' in culture:
culture_num = 2
elif '专科 ' or '中专' in culture:
culture_num = 3
elif '高中' in culture:
culture_num = 4
elif '大学' in culture:
culture_num = 5
culturenum_list.append(culture_num)
print(len(culturenum_list), culturenum_list)
return culturenum_list
# cal_culture()
def cal_work():
"""
数字化工作
:return: 工作列表
"""
work_list = read_excel("案例爬取信息.csv", 9, 4)
worknum_list = []
# 创建一个字典
# 没工作:1;农民:2;个体:3;群众:4;公司经商非农劳务:5;工人进城在业务工:6;教师:7;厨师:8
work_dict = {
'居民': 4, '自由': 1, '在业': 6, '公司': 5, '个体': 3, '务工': 6, '劳务': 5, '在校': 7, '教师': 7, '非农': 5,
'务农': 2, '群众': 4, '幼师': 7, '无固': 1, '进城': 6, '村民': 2, '无业': 1, '无职': 1, '职员': 6, '工人': 6, '厨师': 8,
'经商': 5, '农民': 2}
for work in work_list:
if work in work_dict.keys():
# print("---->",work)
work_num = work_dict[work]
# print("---->",work_num)
worknum_list.append(work_num)
else:
work_num = 6
worknum_list.append(work_num)
print(worknum_list)
print(len(worknum_list))
return worknum_list
# cal_work()
def cal_days():
"""
数字化天数
:return: 数字化天数列表
"""
day_list = read_excel("案例爬取信息.csv", 10, 4)
daynum_list = []
day_dict = {
'一': 1, '二': 2, '三': 3, '四': 4, '五': 5, '六': 6, '七': 7, '八': 8, '九': 9, '十': 10,
'十一': 11, '十二': 12, '十三': 13, '十四': 14, '十五': 15, '十六': 16}
for day in day_list:
day_re = re.findall("(\S{1,2})年(\S{1})个月", day)
# print(day_re)
try:
if day_re[0][0] in day_dict.keys():
daymun_1 = day_dict[day_re[0][0]] * 365
if day_re[0][1] in day_dict.keys():
daymun_2 = day_dict[day_re[0][1]] * 30
daynum = daymun_1 + daymun_2
daynum_list.append(daynum)
except:
daynum_list.append(2053)
print(daynum_list)
return daynum_list
# cal_days()
def cal_money():
"""
数字化钱
:return: 数字化钱的列表
"""
money_list = read_excel("案例爬取信息.csv", 11, 4)
moneynum_list = []
money_dict = {
'一': 1, '二': 2, '三': 3, '四': 4, '五': 5, '六': 6, '七': 7, '八': 8, '九': 9, '十': 10,
'十一': 11, '十二': 12, '十三': 13, '十四': 14, '十五': 15, '十六': 16, '十七': 17, '十八': 18,
'十九': 19, '二十': 20, '二十一': 21, '二十二': 22, '二十三': 23, '二十四': 24, '二十五': 25, '二十六': 26
, '二十七': 27, '二十八': 28, '二十九': 29, '三十': 30, '四十': 40, '五十': 50, '六十': 60}
for money in money_list:
try:
if "万" in money and "千" in money and "百" in money:
money_re = re.findall("(\S{1,2})万(\S{1})千(\S{1})百", money)
moneynum = money_dict[money_re[0][0]] * 10000 + money_dict[money_re[0][1]] * 1000 + money_dict[
money_re[0][2]] * 100
elif "万" in money and "千" in money:
money_re = re.findall("(\S{1,2})万(\S{1})千", money)
moneynum = money_dict[money_re[0][0]] * 10000 + money_dict[money_re[0][1]] * 1000
elif "万" in money:
money_re = re.findall("(\S{1,2})万", money)
moneynum = money_dict[money_re[0]] * 10000
elif "千" in money:
money_re = re.findall("(\S{1,2})千", money)
moneynum = money_dict[money_re[0]] * 1000
else:
if money == "无":
moneynum = 34500
# print(moneynum)
else:
moneynum = int(money)
# print(moneynum)
moneynum_list.append(moneynum)
except:
moneynum = 78000
moneynum_list.append(moneynum)
continue
print(moneynum_list)
print("--->", len(moneynum_list))
return moneynum_list
# cal_money()
def cal_home():
"""
数字化家乡
:return: 返回数字化家乡列表
"""
home_list = read_excel("案例爬取信息.csv", 7, 4)
print(home_list)
set_homelist = set(home_list)
print(len(set_homelist), set_homelist)
home_dict = {
}
i = 1
for home in set_homelist:
home_dict[home] = i
i += 1
print(home_dict.items())
homenum_list = []
for home in home_list:
if home in home_dict.keys():
home_num = home_dict[home]
homenum_list.append(home_num)
else:
home_num = 2
homenum_list.append(home_num)
print(len(homenum_list), homenum_list)
return homenum_list
# cal_home()
# 提取数据
ages = calculation_age()
cultures = cal_culture()
works = cal_work()
homes = cal_home()
moneys = cal_money()
days = cal_days()
examDict = {
'ages': ages, 'cultures': cultures, "works": works, "homes": homes, "moneys": moneys, "days": days}
# 转换为DataFrame的数据格式
examDf = DataFrame(examDict)
print(examDf)
# 数据描述
print(examDf.describe())
# 相关性系数
# 相关系数0~0.3弱相关0.3~0.6中等程度相关0.6~1强相关
rDf = examDf.corr()
print(rDf)
# 通过加入一个参数kind='reg',seaborn可以添加一条最佳拟合直线和95%的置信带。
sns.pairplot(examDf, x_vars=['ages', 'cultures', "works", "homes", "moneys"], y_vars="days", size=7, aspect=0.8,
kind='reg')
plt.savefig("pairplot.svg")
plt.show()
# 利用sklearn里面的包来对数据集进行划分,以此来创建训练集和测试集
# # train_size表示训练集所占总数据集的比例
# 特征值
X_train, X_test, Y_train, Y_test = train_test_split(examDf.iloc[:, [0, 1, 2, 3, 4]], examDf.days, train_size=.80)
print("原始数据特征:", examDf.iloc[:, [0, 1, 2, 3, 4]].shape,
",训练数据特征:", X_train.shape,
",测试数据特征:", X_test.shape)
# 标签值
print("原始数据标签:", examDf.days.shape,
",训练数据标签:", Y_train.shape,
",测试数据标签:", Y_test.shape)
model = LinearRegression()
model.fit(X_train, Y_train)
a = model.intercept_ # 截距
b = model.coef_ # 回归系数
print("最佳拟合线:截距", a, ",回归系数:", b)
# R方检测
# 决定系数r平方
# 对于评估模型的精确度
# y误差平方和 = Σ(y实际值 - y预测值)^2
# y的总波动 = Σ(y实际值 - y平均值)^2
# 有多少百分比的y波动没有被回归拟合线所描述 = SSE/总波动
# 有多少百分比的y波动被回归线描述 = 1 - SSE/总波动 = 决定系数R平方
# 对于决定系数R平方来说1) 回归线拟合程度:有多少百分比的y波动刻印有回归线来描述(x的波动变化)
# 2)值大小:R平方越高,回归模型越精确(取值范围0~1),1无误差,0无法完成拟合
score = model.score(X_test, Y_test)
print(score)
Y_pred = model.predict(X_test)
print(Y_pred)
plt.plot(range(len(Y_pred)), Y_pred, 'b', label="predict")
plt.show()
plt.figure()
plt.plot(range(len(Y_pred)), Y_pred, 'b', label="predict")
plt.plot(range(len(Y_pred)), Y_test, 'r', label="test")
plt.legend(loc="upper right") # 显示图中的标签
plt.xlabel("the number of days")
plt.ylabel('value of days')
plt.savefig("ROC.svg")
plt.show()
(求客官动动您的小指头,点个赞!!!)